小型企业低成本单证识别实战:单证识别(PaddleOCR+YOLOv8)
前言
小型企业在跨境业务等护照信息录入场景中,亟需低成本、纯开源、效果达标的单证识别方案,而当前行业内同时满足这三点的方案极少,文本区域精准检测、单证多角度倾斜的高精度矫正是核心技术难点,这两个环节直接决定了后续OCR识别的最终准确率。本文以护照识别为核心案例(提取姓名、护照号、有效期三大核心字段),基于PaddleOCR+YOLOv8打造轻量化专属方案,硬件仅需支持CUDA11及以上的消费级显卡(以RTX2060为例),通过创新的PaddleOCR轻量矫正方案解决行业核心痛点,搭配YOLOv8小样本目标检测实现低成本落地,完全适配小型企业的业务需求。
一、基础硬件与核心技术栈
1.1 硬件要求
仅需支持CUDA11.0及以上版本的NVIDIA计算卡/显卡,本次实战以RTX2060(6G)为例,满足小样本训练、实时推理与图像矫正的全流程算力需求,低成本且易获取。
1.2 核心技术栈
全程基于纯开源工具,无任何商业授权成本,核心技术栈围绕两大核心框架展开,各司其职且高效配合:
- PaddleOCR:仅使用官方基础模块,实现单证粗+精双阶段倾斜矫正、目标字段OCR文字提取;
- YOLOv8:采用轻量化模型,基于50张样本的水平边界框(HBB)小批量训练,实现护照核心字段的精准目标检测。
二、项目核心痛点与现有开源方案弊端
本次护照识别项目的核心技术难点集中在单证多角度倾斜的高精度矫正与核心文本区域的精准检测,二者直接影响后续识别链路的准确率,也是小型企业低成本方案落地的最大阻碍。目前行业内主流的开源单证处理方案各有明显弊端,均无法适配小型企业“低成本、低开发量、效果达标”的核心诉求,具体问题如下:
- 4关键点检测Pose方案:标注工作量极大,且检测精度较差;同时针对不同类型单证,需要单独做Pose标注适配,重复开发成本高,完全不适配小型企业的小样本场景。
- OBB旋转框检测方案:虽对单证整体角度的检测准确性较高,即便模型训练至95%以上的准确率,2-3度的微小角度偏差对护照这类制式证件的识别影响仍极大,会直接导致OCR漏字、错字,无法满足实际业务需求。
- OpenCV直接边缘检测方案:开发难度高,需要编写大量定制化逻辑,仅适用于高产能、高研发投入的大型项目,小型企业无足够的研发资源支撑落地。
三、护照识别核心流程
本方案的单证识别流程围绕**“精准矫正为核心、小样本检测提效率、针对性OCR出结果”**设计,贴合小型企业的实际拍摄场景(手机/扫描仪拍摄,存在背景干扰、多角度倾斜),整体流程简洁且高效,核心链路如下:
原始护照图片 → PaddleOCR双阶段精准矫正(粗调+精调)→ YOLOv8核心字段目标检测(50张HBB小样本)→ PaddleOCR针对性OCR识别 → 结构化输出结果
四、核心要点:基于PaddleOCR的轻量双阶段文本矫正方案
参考PaddleOCR官方文档:https://www.paddleocr.ai/main/version3.x/module_usage/doc_img_orientation_classification.html
本方案的矫正逻辑基于一个普遍事实:大部分制式单证的文本均为水平横向排列,以此为核心依据实现从“大体方向正确”到“精准角度矫正”的进阶,具体分两步执行:
4.1 第一阶段:文档图像方向分类模块——粗调整体方向
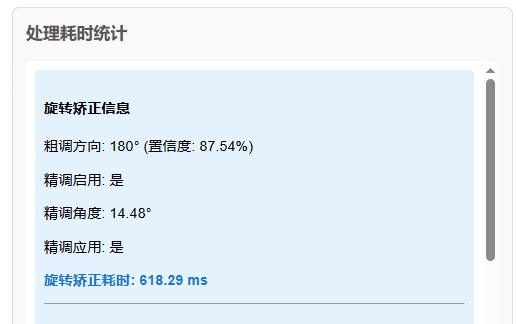
调用PaddleOCR的文档图像方向分类基础模块,对原始护照图片做0/90/180/270度的整体方向调整,确保单证的大体方向正确。
此阶段问题:可解决整倍数90度的方向偏差,但对**-45°~45°之间的小角度旋转**仍无法精准纠正,存在细微的角度偏差问题。
4.2 第二阶段:文本检测模块——精调小角度偏差
调用PaddleOCR的文本检测基础模块,检测经粗调后护照图片中的所有文本块的4个特征点;以“单证横向文本的横向边保持水平”为纠正目标,通过计算所有文本块4个点的坐标偏差,这4个点的小角度纠正目标就是横向边水平,基于这一点便可精确计算需要纠正的角度。精准求解出图片需要纠正的微小角度,并完成针对性旋转矫正。
实战效果:该步骤利用了制式单证的文本分布特征,无额外标注成本,对-45°~45°的小角度倾斜矫正精度极高,彻底解决了OBB旋转框检测的小角度偏差问题,是本方案能实现低成本高效果的关键。
五、低成本YOLOv8核心字段目标检测实现
针对护照核心字段的文本区域检测,本方案规避了复杂的检测方案,采用YOLOv8轻量化模型+50张样本HBB小批量训练的方式,完全适配小型企业的低成本诉求:
- 仅对护照姓名、护照号、有效期三大核心字段做水平边界框(HBB)标注,50张样本即可完成标注,人工成本极低;
- 选用YOLOv8n轻量化模型做迁移学习,基于yolov8s模型预训练模型微调,在RTX2060上训练耗时短、推理速度快;
- 模型训练完成后可精准框选三大核心字段的区域,实现针对性OCR识别,避免整页识别的无关文字干扰,进一步提升OCR准确率。
六、核心代码与检测效果展示
本章节附项目核心代码以模块提供,需要自己安装依赖,模块内部功能完整
#!/usr/bin/env python3
"""
图像方向旋转模块
基于PaddleOCR的文档图像方向分类功能
核心逻辑:先粗调整(90/180/270°) → 再精确调整(-45~45°轻微倾斜)
精调默认覆盖所有粗调后图像(包括0°),修复JSON序列化问题
"""
import os
import sys
import json
import base64
import argparse
import cv2
import numpy as np
from io import BytesIO
from collections import Counter
from PIL import Image
import math
from paddleocr import DocImgOrientationClassification, TextDetection
# ========== 新增:JSON序列化类型转换工具函数 ==========
def convert_numpy_types(obj):
"""
递归转换numpy类型为Python原生类型,解决JSON序列化问题
- numpy.float32/float64 → float
- numpy.int32/int64 → int
- numpy.ndarray → list
"""
if isinstance(obj, dict):
return {k: convert_numpy_types(v) for k, v in obj.items()}
elif isinstance(obj, list):
return [convert_numpy_types(item) for item in obj]
elif isinstance(obj, np.ndarray):
return obj.tolist()
elif isinstance(obj, (np.float32, np.float64)):
return float(obj)
elif isinstance(obj, (np.int32, np.int64)):
return int(obj)
elif isinstance(obj, np.bool_):
return bool(obj)
elif isinstance(obj, np.generic):
return obj.item()
else:
return obj
class ImageOrientationCorrector:
"""图像方向旋转矫正器:粗调(90/180/270°) + 精调(-45~45°),精调覆盖所有场景"""
def __init__(self, model_name="PP-LCNet_x1_0_doc_ori", model_dir=None,
device=None, enable_hpi=False, use_tensorrt=False,
precision="fp32", enable_mkldnn=True, mkldnn_cache_capacity=10,
cpu_threads=10, precise_adjustment=False):
"""
初始化:分别加载方向分类(粗调)和文本检测(精调)模型
:param precise_adjustment: 启用精调(默认对所有粗调后图像生效,包括0°)
"""
# 粗调整:方向分类模型,判断90/180/270/0度
self.ori_model = DocImgOrientationClassification(
model_name=model_name,
model_dir=model_dir,
device=device,
enable_hpi=enable_hpi,
use_tensorrt=use_tensorrt,
precision=precision,
enable_mkldnn=enable_mkldnn,
mkldnn_cache_capacity=mkldnn_cache_capacity,
cpu_threads=cpu_threads
)
# 精调整:文本检测模型,计算-45~45°倾斜角
self.precise_adjustment = precise_adjustment
self.text_det = None
if precise_adjustment:
self.text_det = TextDetection(
model_name="PP-OCRv5_server_det",
device=device,
cpu_threads=cpu_threads
)
# 粗调整方向映射:检测方向 → 逆时针旋转角度
self.ori_map = {'0':0, '90':90, '180':180, '270':270}
def _load_image(self, input_data, input_type):
"""统一加载图像为PIL格式,解决输入类型兼容问题"""
if input_type == 'base64':
if "base64," in input_data:
input_data = input_data.split("base64,")[-1]
img_data = base64.b64decode(input_data)
return Image.open(BytesIO(img_data)).convert('RGB')
elif input_type == 'file':
return Image.open(input_data).convert('RGB')
elif input_type == 'pil':
return input_data.convert('RGB')
else:
raise ValueError(f"不支持的输入类型: {input_type}")
def _coarse_rotate(self, image, orientation):
"""
粗调整:仅处理90/180/270°整数倍旋转
核心:将图像旋转至大致水平方向,为精调打基础
"""
if orientation == '0':
print("[粗调整] 图像已水平,无需旋转")
return image
rotate_angle = self.ori_map.get(orientation, 0)
print(f"[粗调整] 逆时针旋转 {rotate_angle}°")
# expand=True 保证旋转后图像完整,不裁剪
return image.rotate(rotate_angle, expand=True, fillcolor=(255,255,255))
def _get_majority_orientation(self, results):
"""获取粗调整的多数方向(兼容PaddleOCR Result对象)"""
if not results:
return {'orientation': '0', 'confidence': 0.0, 'all_predictions': []}
all_orientations = []
all_predictions = []
for res in results:
if hasattr(res, 'label_names'):
label = res.label_names[0] if res.label_names else '0'
score = res.scores[0] if hasattr(res, 'scores') else 0.0
elif isinstance(res, dict):
label = res.get('label_names', ['0'])[0]
score = res.get('scores', [0.0])[0]
else:
continue
# 确保score是Python原生float
all_orientations.append(label)
all_predictions.append({'orientation': label, 'confidence': float(score)})
counter = Counter(all_orientations)
majority_ori = counter.most_common(1)[0][0]
# 计算平均置信度,转换为Python原生float
conf_list = [p['confidence'] for p in all_predictions if p['orientation'] == majority_ori]
avg_conf = float(np.mean(conf_list)) if conf_list else 0.0
return {
'orientation': majority_ori,
'confidence': round(avg_conf, 4),
'all_predictions': all_predictions
}
def _calc_precise_angle(self, image):
"""
精调整:计算-45~45°的轻微倾斜角(针对所有粗调后图像,包括0°)
核心逻辑:
1. 粗调后图像已水平,文本框角度应在-45~45°内
2. 兼容文本框顶点顺序,找最长边计算角度
3. 过滤离群点,用中位数保证稳定性
"""
# PIL → OpenCV格式(BGR)
img_np = np.array(image)
img_np = cv2.cvtColor(img_np, cv2.COLOR_RGB2BGR)
# 文本检测:获取粗调后图像的文本框
try:
det_result = self.text_det.predict(img_np)
except Exception as e:
print(f"[精调整] 文本检测失败: {str(e)}")
return 0.0
if not det_result or len(det_result) == 0:
print("[精调整] 未检测到文本框,跳过微调")
return 0.0
valid_angles = []
for res in det_result:
# 兼容PaddleOCR TextDetection的输出格式
dt_polys = res.get('dt_polys', []) if isinstance(res, dict) else res
for poly in dt_polys:
if len(poly) != 4:
continue
# 计算文本框四条边,取最长边(大概率是水平边)
edges = [(poly[i], poly[(i+1)%4]) for i in range(4)]
edge_lengths = []
for (p1, p2) in edges:
dx = p2[0] - p1[0]
dy = p2[1] - p1[1]
length = math.hypot(dx, dy)
edge_lengths.append((length, dx, dy))
# 取最长边计算角度
edge_lengths.sort(reverse=True, key=lambda x: x[0])
max_len, dx, dy = edge_lengths[0]
if dx == 0:
continue # 跳过垂直边
# 计算角度并限制在-45~45°
angle = math.degrees(math.atan2(dy, dx))
if abs(angle) > 45:
continue
valid_angles.append(angle)
if not valid_angles:
return 0.0
# 过滤离群点(3σ原则)
mean = np.mean(valid_angles)
std = np.std(valid_angles)
filtered_angles = [a for a in valid_angles if abs(a-mean) < 3*std]
if not filtered_angles:
filtered_angles = valid_angles
# 用中位数替代平均值,抗离群点干扰,转换为Python原生float
precise_angle = float(np.median(filtered_angles))
print(f"[精调整] 有效角度数: {len(filtered_angles)} | 微调角度: {precise_angle:.2f}°")
return precise_angle
def _precise_rotate(self, image, angle):
"""
精调整:执行-45~45°的轻微旋转
角度符号:正值→逆时针旋转,负值→顺时针旋转(和粗调一致)
"""
if abs(angle) < 0.1:
return image # 倾斜太小,无需微调
# rotate的角度是逆时针,直接传入计算出的angle
rotated_img = image.rotate(angle, expand=True, fillcolor=(255,255,255))
print(f"[精调整] 执行旋转 {angle:.2f}°")
return rotated_img
def correct(self, input_data, input_type='file', output_type='file', output_path=None):
"""
主矫正流程:粗调 → 精调(默认覆盖所有粗调后图像,包括0°)
"""
try:
# 1. 加载图像
image = self._load_image(input_data, input_type)
input_size = f"{image.size[0]}x{image.size[1]}"
print(f"[总流程] 加载图像成功,尺寸: {input_size}")
# 2. 粗调整:方向检测 + 90/180/270°旋转
img_np = np.array(image)
ori_result = self.ori_model.predict(img_np)
ori_info = self._get_majority_orientation(ori_result)
coarse_img = self._coarse_rotate(image, ori_info['orientation'])
# 3. 精调整:自动对所有粗调后图像生效(包括0°)
precise_angle = 0.0
final_img = coarse_img
if self.precise_adjustment and self.text_det:
precise_angle = self._calc_precise_angle(coarse_img)
final_img = self._precise_rotate(coarse_img, precise_angle)
# 4. 输出处理
output_info = {}
if output_type == 'file':
if not output_path:
output_path = input_data.replace('.', '_corrected.') if input_type == 'file' else 'corrected.jpg'
final_img.save(output_path, quality=95)
output_info = {
'type': 'file',
'path': output_path,
'size': f"{final_img.size[0]}x{final_img.size[1]}"
}
elif output_type == 'base64':
buffer = BytesIO()
final_img.save(buffer, format='JPEG', quality=95)
output_data = base64.b64encode(buffer.getvalue()).decode()
output_info = {'type': 'base64', 'length': len(output_data), 'data': output_data}
# 5. 构建结果(先转换所有numpy类型)
result = {
'success': True,
'input_info': {'type': input_type, 'size': input_size},
'coarse_adjust': ori_info,
'precise_adjust': {
'enabled': self.precise_adjustment,
'angle': round(precise_angle, 2),
'applied': abs(precise_angle) >= 0.1
},
'output_info': output_info
}
# 关键:转换numpy类型为Python原生类型
result_converted = convert_numpy_types(result)
return json.dumps(result_converted, ensure_ascii=False, indent=2)
except Exception as e:
error_msg = f"矫正失败: {str(e)}"
print(error_msg)
# 确保错误信息也能正常序列化
error_result = convert_numpy_types({'success': False, 'error': error_msg})
return json.dumps(error_result, ensure_ascii=False)
# ========== 命令行入口 ==========
def main():
parser = argparse.ArgumentParser(description='粗调+精调 图像方向矫正工具(精调默认覆盖0°图像)')
parser.add_argument('-i', '--input', required=True, help='输入文件路径')
parser.add_argument('-o', '--output', help='输出文件路径')
parser.add_argument('--device', default='cpu', help='推理设备 cpu/gpu')
parser.add_argument('--precise', action='store_true', help='启用精调(对所有粗调后图像生效)')
args = parser.parse_args()
# 初始化矫正器
corrector = ImageOrientationCorrector(
device=args.device,
precise_adjustment=args.precise
)
# 执行矫正
result = corrector.correct(
input_data=args.input,
input_type='file',
output_type='file',
output_path=args.output
)
print(result)
if __name__ == "__main__":
main()
检测效果展示:
训练测试集(30张 ) 验证集(10张)注意训练参数
这里应该所有图像都由paddleOCR处理旋转角度,所以训练的时候注意关闭旋转参数,提升小模型训练效果分享训练参数:
import sys
import argparse
import os
from ultralytics import YOLO
def train_yolo(resume=False):
if resume:
model_path = 'run/yolov8n_custom3/weights/last.pt'
if not os.path.exists(model_path):
print(f"错误:找不到检查点文件 {model_path}")
sys.exit(1)
print(f"继续训练,从 {model_path} 加载模型")
else:
model_path = 'models/yolov8s.pt'
print(f"开始新训练,从 {model_path} 加载预训练模型")
data_yaml = 'data.yaml'
model = YOLO(model_path)
results = model.train(
data=data_yaml, # 数据集配置文件路径
epochs=300, # 训练轮数,默认100,范围50-500
batch=11, # 批次大小,默认16,范围4-64(取决于显存)
imgsz=1280, # 输入图像尺寸,默认640,范围320-1280(32的倍数)
device=0, # 训练设备,0表示GPU,'cpu'表示CPU
name='yolov8n_passport', # 实验名称,用于区分不同训练
project='run', # 项目目录,保存训练结果
pretrained=True, # 是否使用预训练权重
optimizer='SGD', # 优化器:SGD/Adam/AdamW
lr0=0.01, # 初始学习率,默认0.01,范围0.001-0.1
patience=50, # 早停耐心值,默认50,范围10-100
save=True, # 是否保存训练模型
plots=True, # 是否绘制训练曲线和结果图
val=True, # 是否在训练过程中进行验证
amp=True, # 是否使用自动混合精度训练
hsv_h=0.015, # HSV色相增强幅度,默认0.015,范围0.0-0.1
hsv_s=0.6, # HSV饱和度增强幅度,默认0.7,范围0.0-1.0
hsv_v=0.4, # HSV明度增强幅度,默认0.4,范围0.0-1.0
degrees=0, # 随机旋转角度范围,默认0.0,范围0.0-45.0
translate=0.1, # 随机平移比例,默认0.1,范围0.0-0.5
scale=0.6, # 随机缩放比例范围,默认0.5,范围0.0-1.0
shear=0.0, # 随机剪切角度,默认0.0,范围0.0-15.0
perspective=0.0, # 透视变换幅度,默认0.0,范围0.0-0.001
flipud=0.0, # 上下翻转概率,默认0.0,范围0.0-1.0
fliplr=0, # 左右翻转概率,默认0.5,范围0.0-1.0
mosaic=0.0, # 马赛克增强概率,默认1.0,范围0.0-1.0
mixup=0.0 # Mixup增强概率,默认0.0,范围0.0-1.0
)
print("训练完成!")
print(f"最佳模型保存在: {results.save_dir}/weights/best.pt")
print(f"最终模型保存在: {results.save_dir}/weights/last.pt")
return results
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='YOLO训练脚本')
parser.add_argument('--resume', action='store_true', help='是否继续上次的训练')
args = parser.parse_args()
if args.resume:
print(f"继续训练模式,训练 100 轮")
else:
print(f"新训练模式,训练 100 轮")
train_yolo(resume=args.resume)
总结
本方案基于PaddleOCR+YOLOv8打造,核心突破了小型企业单证识别的两大痛点:一是通过PaddleOCR基础模块设计的双阶段轻量矫正方案,解决了单证多角度倾斜的高精度矫正问题,规避了现有开源方案的标注量大、小角度偏差、开发难度高的弊端;二是搭配YOLOv8 50张样本小批量训练,实现核心字段的精准检测,全程纯开源、无商业授权成本,硬件仅需RTX2060这类消费级显卡。
方案以护照识别为案例,可直接迁移至发票、报关单等其他制式单证识别场景,仅需少量样本调整即可适配,真正实现了低成本、开源、效果达标的三重目标,完全贴合小型企业的单证识别业务需求。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)