ES 学习(八)为什么ES搜索这么快?倒排索引的实现解密
目录
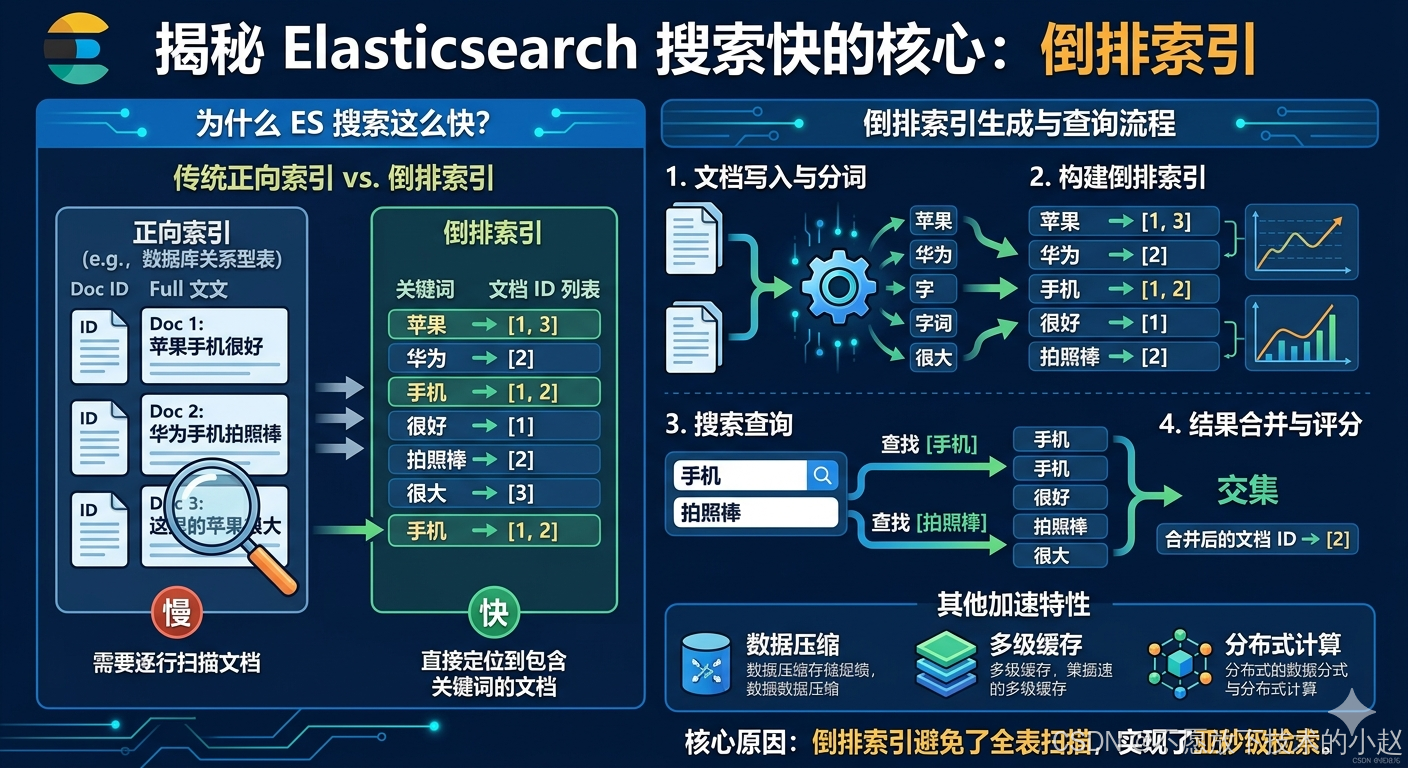
Elasticsearch(ES)作为一款高性能的分布式搜索和分析引擎,其核心优势在于能够对海量数据进行毫秒级的全文检索。这种卓越性能的背后,离不开其底层采用的倒排索引(Inverted Index)技术。
本文将深入剖析倒排索引的实现原理,解密ES搜索如此之快的根本原因。我们将从传统数据库的局限性出发,逐步介绍 倒排索引的数据结构、构建过程、查询机制,并探讨ES在此基础上的优化策略,最终揭示其高效搜索的完整技术图景。
一、倒排索引:从 “书->页” 到 “词->书”
1.1 最直观的理解:从查字典说起
想象你有一本1000页的书,现在要找出所有包含"苹果"这个词的页面。传统方法(正排索引)就像从第一页开始,逐页阅读直到最后一页,记录哪些页面提到了"苹果"。这种方法的时间复杂度是O(n),n是总页数。
而倒排索引就像预先制作一个"词汇索引表":
苹果 → 第5页, 第78页, 第234页, 第567页
香蕉 → 第23页, 第156页
橙子 → 第45页, 第89页, 第301页
当你要找"苹果"时,直接查这个索引表,瞬间就能得到结果页码。这就是倒排索引的核心思想:从"文档→词汇"到"词汇→文档"的转换。
1.2 正排索引的底层性能瓶颈
让我们用具体数据说明正排索引的性能问题:
假设有100万篇文档,平均每篇1000个词:
- 总词汇量:10亿个词
- 查询"机器学习"需要扫描:10亿次词项比较
- 磁盘I/O:假设每次读取4KB,需要约4TB的磁盘读取
- 内存占用:假设每个词占20字节,需要20GB内存
即使使用B+树索引,时间复杂度也是O(log n),对于10亿数据量,大约需要30次磁盘I/O,每次5ms,总耗时150ms。而用户期望的搜索响应时间是<100ms。
1.3 倒排索引的数据结构底层实现
倒排索引的实际存储结构比简单的"词→文档列表"复杂得多:
词典(Term Dictionary)结构:
[机器学习] → {
docFreq: 3, // 包含该词的文档数量
postFileOffset: 1024, // 倒排列表在文件中的偏移量
postFileLength: 128 // 倒排列表长度
}
倒排列表(Posting List)结构:
DocID: 5 → {freq: 2, positions: [12, 45]}
DocID: 78 → {freq: 1, positions: [33]}
DocID: 234 → {freq: 3, positions: [7, 89, 156]}
每个条目包含:
- DocID:文档唯一标识(压缩存储为差值)
- 词频(TF):该词在文档中出现的次数
- 位置信息:词在文档中的具体位置(用于短语查询)
二、倒排索引的构建与优化
2.1 文本分析的底层流程
让我们看一个具体的文本分析例子:
原文档:
<p>The Quick Brown-Foxes jumped!</p>
分析步骤:
-
字符过滤器:
<p>The Quick Brown-Foxes jumped!</p> ↓ 去除HTML标签 The Quick Brown-Foxes jumped! -
分词器(Tokenizer):
The Quick Brown-Foxes jumped! ↓ 按空格和标点分词 ["The", "Quick", "Brown-Foxes", "jumped"] -
分词过滤器(Token Filter):
["The", "Quick", "Brown-Foxes", "jumped"] ↓ 小写化 ["the", "quick", "brown-foxes", "jumped"] ↓ 去除停用词("the") ["quick", "brown-foxes", "jumped"] ↓ 词干提取 ["quick", "brown-fox", "jump"]
最终在索引中存储的词项:quick, brown-fox, jump
2.2 词典压缩的底层技术:FST详解
FST(Finite State Transducer)如何压缩词典:
普通存储:apple, application, apply, banana, band
需要:5个字符串 × 平均6字符 = 30字节
FST存储:
a-p-p-l-e
\
i-cation
\
y
b-a-n-a-n-a
\
d
共享前缀:a-p-p-l (5字节)
共享前缀:b-a-n (3字节)
总存储:约15字节,节省50%
FST不仅节省空间,还支持高效的前缀查询(如"app*")和模糊查询(如编辑距离为1的查询)。
2.3 倒排列表压缩算法详解
以文档ID压缩为例,使用Frame of Reference算法:
原始DocID序列:[5, 10, 12, 18, 25]
差值编码:[5, 5, 2, 6, 7]
使用3位存储每个差值:
二进制:101 101 010 110 111
压缩后:16位vs原始160位(假设DocID为32位)
压缩率:90%
对于词频和位置信息,使用PForDelta算法:
- 将64个文档分为一组
- 用简单的bit packing存储大多数值
- 用额外的溢出表存储异常值
三、ES的查询执行与性能加速
3.1 完整示例:从索引创建到查询执行
3.1.1 索引创建DSL
PUT /products
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"analysis": {
"analyzer": {
"custom_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": ["lowercase", "stop", "stemmer"]
}
}
}
},
"mappings": {
"properties": {
"title": {
"type": "text",
"analyzer": "custom_analyzer",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"description": {
"type": "text",
"analyzer": "custom_analyzer"
},
"price": {
"type": "float"
},
"category": {
"type": "keyword"
},
"created_at": {
"type": "date"
}
}
}
}
3.1.2 添加示例文档
POST /products/_doc/1
{
"title": "机器学习实战指南",
"description": "这本书详细介绍了机器学习的核心算法和应用场景",
"price": 89.99,
"category": "technology",
"created_at": "2024-01-15"
}
POST /products/_doc/2
{
"title": "深度学习与神经网络",
"description": "深入探讨深度学习技术及其在图像识别中的应用",
"price": 129.99,
"category": "technology",
"created_at": "2024-02-20"
}
POST /products/_doc/3
{
"title": "Python编程入门",
"description": "适合初学者的Python编程教程,包含机器学习基础",
"price": 59.99,
"category": "programming",
"created_at": "2024-03-10"
}
3.1.3 查询DSL示例
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"multi_match": {
"query": "机器学习",
"fields": ["title^2", "description"],
"type": "best_fields"
}
}
],
"filter": [
{
"range": {
"price": {
"lte": 100
}
}
},
{
"term": {
"category": "technology"
}
}
]
}
},
"sort": [
{
"_score": {
"order": "desc"
}
},
{
"price": {
"order": "asc"
}
}
],
"highlight": {
"fields": {
"title": {},
"description": {}
}
}
}
3.2 查询执行的底层实现原理
当上述查询DSL执行时,ES内部经历了以下关键步骤:
3.2.1 查询解析与重写(Query Parsing & Rewriting)
// 查询DSL被解析为内部查询对象
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery()
.must(QueryBuilders.multiMatchQuery("机器学习")
.field("title^2")
.field("description")
.type(MultiMatchQueryBuilder.Type.BEST_FIELDS))
.filter(QueryBuilders.rangeQuery("price").lte(100))
.filter(QueryBuilders.termQuery("category", "technology"));
解析后的查询树:
BoolQuery
├── Must: MultiMatchQuery("机器学习")
│ ├── title^2
│ └── description
├── Filter: RangeQuery(price <= 100)
└── Filter: TermQuery(category = "technology")
3.2.2 分片路由与并行执行
// 查询路由计算
int shardNumber = hash(_routing) % numShards;
// 对于3个分片,查询被并行分发到所有分片
每个分片独立执行:
- 分片0:处理DocID 0-9999
- 分片1:处理DocID 10000-19999
- 分片2:处理DocID 20000-29999
3.2.3 倒排索引查找过程
步骤1:词典查找(Term Dictionary Lookup)
查询词:"机器学习"
词典结构:
[机器] → {docFreq: 100, offset: 1024}
[机器学习] → {docFreq: 50, offset: 2048}
[学习] → {docFreq: 200, offset: 3072}
查找过程:
1. 使用FST快速定位"机器学习"
2. 获取倒排列表位置:offset=2048, length=256
步骤2:倒排列表读取(Posting List Retrieval)
倒排列表内容(2048-2304):
DocID: 1 → {freq: 1, positions: [0]}
DocID: 2 → {freq: 1, positions: [0]}
DocID: 5 → {freq: 2, positions: [3, 15]}
DocID: 8 → {freq: 1, positions: [2]}
步骤3:布尔查询合并(Boolean Query Merging)
// 合并多个倒排列表
Set<Integer> resultDocs = new HashSet<>();
// MUST条件:title或description包含"机器学习"
Set<Integer> mlDocs = new HashSet<>([1, 2, 5, 8]);
// FILTER条件:price <= 100
Set<Integer> priceDocs = new HashSet<>([1, 3, 5, 7, 9]);
// FILTER条件:category = "technology"
Set<Integer> categoryDocs = new HashSet<>([1, 2, 4, 6, 8]);
// 交集运算
resultDocs = mlDocs ∩ priceDocs ∩ categoryDocs;
// 结果:[1, 5]
3.2.4 相关性评分计算
对于匹配的文档,计算BM25分数:
// 文档1:"机器学习实战指南"
float scoreDoc1 = 0.0f;
// title字段评分 (boost=2)
float titleScore = BM25("机器学习", "机器学习实战指南", fieldBoost=2);
// titleScore = 8.2
// description字段评分
float descScore = BM25("机器学习", "这本书详细介绍了机器学习的核心算法和应用场景");
// descScore = 3.1
// 总分
float totalScore = titleScore + descScore = 11.3;
3.2.5 结果合并与排序
// 各分片返回结果
Shard0: [{docId: 1, score: 11.3}, {docId: 5, score: 8.7}]
Shard1: []
Shard2: []
// 全局排序
finalResults = sortByScore([{docId: 1, score: 11.3}, {docId: 5, score: 8.7}]);
3.3 核心概念与算法说明
3.3.1 Multi-Match查询类型
| 类型 | 说明 | 适用场景 |
|---|---|---|
| best_fields | 取最佳字段的分数 | 标题匹配优先 |
| most_fields | 所有匹配字段分数相加 | 全文搜索 |
| cross_fields | 跨字段查询 | 姓名、地址等 |
| phrase | 短语匹配 | 精确短语查询 |
3.3.2 Lucene查询执行流程
Query → Weight → Scorer → Collector
↓ ↓ ↓ ↓
解析 权重计算 打分 结果收集
3.3.3 跳表(Skip List)在查询中的应用
// 倒排列表结构
class PostingList {
int[] docIds;
SkipList skipList;
// 快速跳转到目标DocID
int advance(int target) {
// 使用跳表快速定位
return skipList.advanceTo(target);
}
}
3.3.4 缓存机制
// 查询缓存(Query Cache)
Cache Key: "机器学习" + price<=100 + category=technology
Cache Value: [docId: 1, docId: 5]
// 过滤器缓存(Filter Cache)
BitSet filterCache = new BitSet();
filterCache.set(1); filterCache.set(5); // 缓存过滤结果
3.4 性能优化关键点
3.4.1 查询优化策略
- 字段选择:title字段boost=2,提高标题权重
- 过滤vs查询:价格、分类使用filter,不计算相关性分数
- 路由优化:使用自定义路由减少分片扫描
- 缓存利用:重复查询直接返回缓存结果
3.4.2 硬件层面优化
# SSD vs HDD性能对比
SSD: 随机读取 0.1ms, 顺序读取 500MB/s
HDD: 随机读取 10ms, 顺序读取 100MB/s
ES推荐使用SSD提升10-100倍I/O性能
3.4.3 JVM调优参数
-Xms8g -Xmx8g # 堆内存设置
-XX:+UseG1GC # G1垃圾收集器
-XX:MaxGCPauseMillis=200 # 最大GC停顿时间
-XX:+DisableExplicitGC # 禁用System.gc()
四、总结
Elasticsearch之所以能够实现如此快速的搜索,其核心秘密就在于倒排索引这一精妙的数据结构。通过将"文档到词"的正向查找,转变为"词到文档"的逆向映射,ES从根本上解决了海量数据下全文检索的性能瓶颈。
从DSL查询到底层执行,ES展现了完整的技术栈优势:
- 用户友好:简单的DSL语法隐藏复杂实现
- 执行高效:并行分片、跳表加速、缓存优化
- 扩展性强:分布式架构支持PB级数据
理解这些底层机制,不仅能帮助我们写出更高效的查询,更能为系统架构设计提供重要参考。倒排索引的成功证明了:优秀的技术产品,是底层创新与上层抽象的完美结合。
整理完毕,完结撒花~🌻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)