Wireshark深度解析IP协议与分片机制
Wireshark 是一款开源且功能强大的网络协议分析工具,广泛应用于网络故障排查、安全审计与协议研究等领域。它能够实时捕获网络流量,并对各类协议数据包进行详细解析,帮助用户深入理解通信过程。Wireshark 的图形界面由三个主要区域构成:数据包列表面板(Packet List):显示所有捕获的数据包,按时间顺序排列,每行代表一个数据包,包含编号、时间戳、源/目的地址、协议类型、数据包长度等信息

简介:Wireshark是一款广泛用于网络故障排查、安全分析和协议学习的封包分析工具。本案例聚焦于Wireshark对IP协议的分析,特别探讨IP数据包的分片机制。通过提供的”ip.pcapng”和”ip_frag.pcapng”两个抓包文件,学习者可以深入了解IP协议头部结构、分片与重组过程,并掌握使用Wireshark进行数据包分析和重组的实战技能。 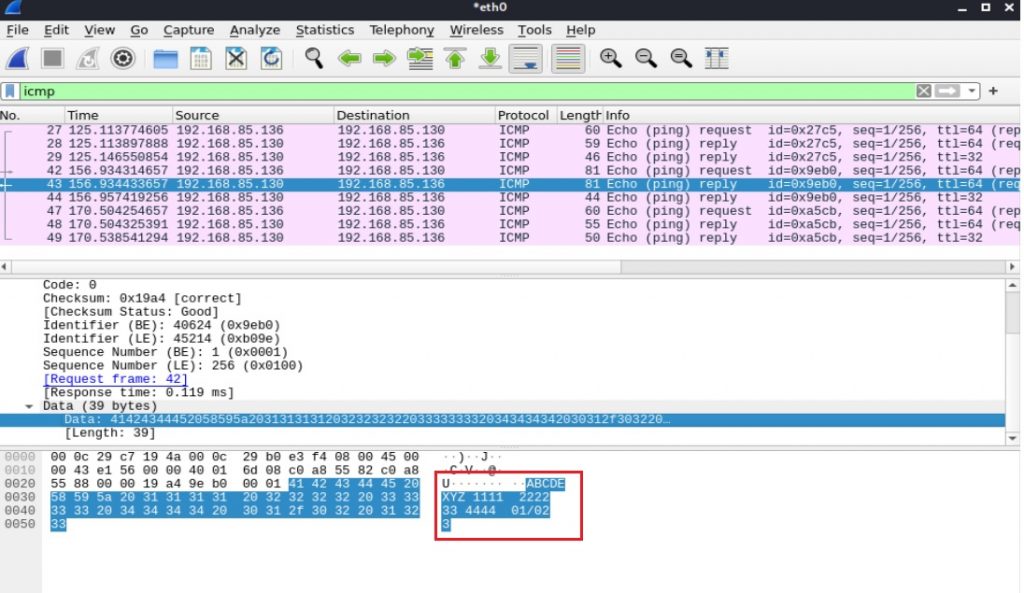
1. Wireshark网络协议分析工具概述
Wireshark 是一款开源且功能强大的网络协议分析工具,广泛应用于网络故障排查、安全审计与协议研究等领域。它能够实时捕获网络流量,并对各类协议数据包进行详细解析,帮助用户深入理解通信过程。
1.1 Wireshark 的基本功能
Wireshark 的核心功能包括:
- 数据包捕获(Packet Capture) :支持从多种网络接口捕获实时流量。
- 协议解析(Protocol Dissection) :支持数百种协议的解析,自动识别并展示各层协议字段。
- 过滤与搜索(Filtering & Searching) :提供强大的显示和捕获过滤器功能,如
ip.src == 192.168.1.1,可精准定位目标流量。 - 数据导出与分析(Export & Analysis) :支持将捕获数据导出为 pcapng 格式,并提供统计分析视图。
例如,使用以下命令可在命令行中启动 Wireshark 并开始捕获流量:
wireshark -i eth0 -w capture.pcapng
-i eth0:指定捕获接口为 eth0;-w capture.pcapng:将捕获结果保存为 pcapng 文件。
1.2 Wireshark 界面结构简介
Wireshark 的图形界面由三个主要区域构成:
- 数据包列表面板(Packet List) :显示所有捕获的数据包,按时间顺序排列,每行代表一个数据包,包含编号、时间戳、源/目的地址、协议类型、数据包长度等信息。
- 数据包详情面板(Packet Details) :点击某个数据包后,显示该包的各层协议字段解析,例如以太网头部、IP头部、TCP/UDP头部等。
- 数据包字节面板(Packet Bytes) :以十六进制和 ASCII 两种格式展示原始数据内容,便于底层分析。
此外,顶部工具栏提供了捕获控制、过滤器设置、统计分析等功能,极大提升了分析效率。
1.3 Wireshark 在网络协议分析中的地位
Wireshark 之所以成为网络工程师和安全研究人员的必备工具,得益于其以下几个核心优势:
- 可视化强 :通过结构化展示协议字段,降低了协议理解门槛。
- 协议支持广 :涵盖从物理层到应用层的众多协议,包括 IPv4、IPv6、TCP、UDP、HTTP、DNS 等。
- 社区支持活跃 :持续更新协议解析插件,确保对新兴协议的兼容性。
- 跨平台支持 :支持 Windows、Linux 和 macOS 系统,便于不同环境下的部署与使用。
在后续章节中,我们将以 Wireshark 为分析工具,深入探讨 IP 协议的结构、分片机制及其在网络通信中的作用。
2. IP协议基本结构与字段解析
IP协议(Internet Protocol)作为TCP/IP协议族的核心组成部分,主要负责在网络层进行数据包的寻址与路由。IP协议定义了数据包的格式,以及在不同网络之间如何转发这些数据包。本章将从IP数据包的基本结构入手,逐步深入解析其关键字段的含义和作用,帮助读者建立对IP协议结构的系统性理解。
2.1 IP数据包的基本组成
IP数据包由 IP头部 和 数据载荷 两部分组成。IP头部包含用于路由、分片、校验等控制信息,其长度通常为20字节(固定部分)到60字节(包含可选字段)。理解IP头部各字段的结构和功能是掌握网络通信机制的基础。
2.1.1 版本号(Version)
IP头部的第一个字段是版本号(Version),占4位(bit),表示当前使用的IP协议版本。常见的版本有:
- IPv4(0100)
- IPv6(0110)
在Wireshark中抓取的IPv4数据包头部如下所示:
Binary: 0100 0101
Version: 4 (0100)
IHL: 5 (0101)
这段二进制数据表示一个IPv4的数据包,其中前4位为版本号,值为4,即IPv4。
参数说明:
- 位宽 :4位
- 取值范围 :0~15,但实际有效的值为4(IPv4)和6(IPv6)
- 作用 :指示IP协议版本,决定后续头部结构的解析方式
逻辑分析:
当路由器或主机接收到IP数据包时,首先读取版本号字段,以确定如何解析后续的头部结构。若版本号不匹配当前系统支持的协议版本,数据包将被丢弃。
2.1.2 头部长度(IHL)
IP头部长度(Internet Header Length, IHL)字段也占4位,用于表示IP头部的长度,单位为32位字(4字节)。因此,最小值为5(5×4=20字节),最大值为15(15×4=60字节),即IP头部最大长度为60字节。
示例:
Binary: 0100 0101
IHL: 5 (0101)
表示IP头部长度为5个32位字,即20字节。
参数说明:
- 位宽 :4位
- 单位 :32位字(4字节)
- 取值范围 :5~15
- 作用 :用于确定IP头部结束的位置,从而正确读取数据载荷
代码逻辑分析:
在程序中解析IHL字段时,可以使用如下伪代码:
# 假设ip_header为IP头部的原始字节流(bytes)
version_ihl = ip_header[0]
ihl = version_ihl & 0x0F # 通过位掩码取出IHL字段
header_length = ihl * 4 # 转换为字节单位
这段代码首先从IP头部的第一个字节中提取出低4位(IHL字段),然后将其乘以4,得到IP头部的实际长度。
2.1.3 服务类型(TOS)与区分服务代码点(DSCP)
服务类型(Type of Service, TOS)字段用于指示数据包的服务优先级和传输类型。在IPv4中,该字段长度为8位,早期用于定义延迟、吞吐量、可靠性和成本四个参数。随着区分服务(DiffServ)模型的引入,TOS字段被重新定义为 区分服务字段(Differentiated Services Field) ,其中前6位称为 区分服务代码点(DSCP) ,后2位为 显式拥塞通知(ECN) 。
字段结构示意图(使用mermaid流程图):
bitDiagram
title TOS/DSCP字段结构
bitfield [
{ name: DSCP, bits: 6 },
{ name: ECN, bits: 2 }
]
参数说明:
- DSCP(6位) :用于定义数据包的服务等级,支持64种不同的服务类型
- ECN(2位) :用于显式拥塞通知,帮助网络设备在发生拥塞时通知发送端降低速率
示例:
一个典型的DSCP值为 0x2E (十进制46),对应的是EF(Expedited Forwarding)服务等级,常用于语音通信。
代码示例:
tos_byte = ip_header[1] # 假设tos_byte是IP头部第2个字节
dscp = (tos_byte >> 2) & 0x3F # 取前6位
ecn = tos_byte & 0x03 # 取后2位
print(f"DSCP: {dscp}, ECN: {ecn}")
逻辑分析:
该段代码从IP头部的第二个字节中提取出DSCP和ECN字段。通过右移2位并使用掩码 0x3F 获取DSCP字段,再使用掩码 0x03 获取ECN字段。
2.2 关键字段详解
在IP头部中,除了上述字段外,还有一些对数据包传输和分片至关重要的字段,包括总长度、标识符、标志位、碎片偏移等。
2.2.1 总长度(Total Length)
总长度(Total Length)字段表示整个IP数据包的长度,包括头部和数据载荷,单位为字节。该字段占16位,最大值为65535字节。
示例:
Hex: 0x003C
Decimal: 60
表示该IP数据包总长度为60字节。
参数说明:
- 位宽 :16位
- 取值范围 :20~65535字节
- 作用 :用于接收方判断数据包的完整性和边界
代码逻辑:
total_length = int.from_bytes(ip_header[2:4], byteorder='big')
print(f"Total Length: {total_length} bytes")
该段代码从IP头部第3~4字节中提取出总长度字段,并转换为整数。
2.2.2 标识符(Identification)与分片控制
标识符(Identification)字段是一个16位的字段,用于唯一标识一个IP数据包。当数据包被分片时,所有分片都携带相同的标识符,以便接收端进行重组。
示例:
Hex: 0x1234
Decimal: 4660
该标识符用于标识某一个特定的数据包。
参数说明:
- 位宽 :16位
- 取值范围 :0~65535
- 作用 :在分片过程中,用于标识属于同一个原始数据包的多个分片
代码示例:
identification = int.from_bytes(ip_header[4:6], byteorder='big')
print(f"Identification: {identification}")
2.2.3 标志位(Flags)与碎片偏移(Fragment Offset)
这两个字段共同控制IP数据包的分片行为。
Flags字段结构:
- 位0 :保留位(必须为1)
- 位1 :DF(Don’t Fragment)标志位。若为1,表示禁止分片;若为0,允许分片
- 位2 :MF(More Fragments)标志位。若为1,表示后面还有分片;若为0,表示当前分片为最后一个
Fragment Offset字段:
- 位宽 :13位
- 单位 :8字节(即每个偏移单位为8字节)
- 作用 :表示当前分片在原始数据包中的位置偏移量
表格说明:
| 字段名称 | 位宽 | 单位 | 作用说明 |
|---|---|---|---|
| Flags(标志位) | 3位 | 无 | 控制分片行为,包括DF和MF标志 |
| Fragment Offset | 13位 | 8字节 | 表示分片在原始数据包中的偏移位置 |
示例代码:
flags_offset_bytes = ip_header[6:8]
flags_offset = int.from_bytes(flags_offset_bytes, byteorder='big')
df = (flags_offset >> 14) & 0x01 # 提取DF标志
mf = (flags_offset >> 13) & 0x01 # 提取MF标志
offset = flags_offset & 0x1FFF # 提取碎片偏移值
print(f"DF: {df}, MF: {mf}, Fragment Offset: {offset * 8} bytes")
逻辑分析:
- 首先将6~7字节组合为一个16位整数
- 通过位移和掩码提取DF、MF标志位和碎片偏移值
- 碎片偏移需乘以8,以得到实际的字节偏移量
2.3 IP地址与路由信息
IP地址是IP协议中最重要的组成部分之一,用于标识网络中的主机和路由器。
2.3.1 源地址与目的地址字段
在IPv4中,源地址(Source Address)和目的地址(Destination Address)各占32位(4字节),分别表示发送方和接收方的IP地址。
示例:
Source Address: 192.168.1.1
Destination Address: 8.8.8.8
参数说明:
- 位宽 :各32位
- 作用 :用于路由决策和数据包的最终投递
代码解析:
src_ip = ip_header[12:16]
dst_ip = ip_header[16:20]
def bytes_to_ip(b):
return ".".join(str(x) for x in b)
print(f"Source IP: {bytes_to_ip(src_ip)}")
print(f"Destination IP: {bytes_to_ip(dst_ip)}")
逻辑分析:
- 从IP头部提取出源地址和目的地址的4字节数据
- 将每个字节转换为整数,并以点分十进制格式输出
2.3.2 可选项字段(Options)与填充(Padding)
IP头部中还可能包含可选项字段(Options),用于实现一些可选功能,如记录路由、时间戳等。该字段是可变长度的,最多40字节。为了保证IP头部长度为4字节的整数倍,若可选项字段不足,需用填充字段(Padding)补齐。
可选项字段结构示例:
Option Type: 0x79 (Loose Source Route)
Length: 0x0B (11 bytes)
Pointer: 0x04
Route: 192.168.1.2, 192.168.1.3
参数说明:
- Option Type :定义选项的类型
- Length :整个选项字段的长度(包括Type、Length和内容)
- Pointer :指针字段,指示当前处理的路由地址位置
使用场景:
- 源路由(Source Route) :由发送方指定数据包的转发路径
- 时间戳(Timestamp) :记录数据包经过的节点及时间
代码示例(解析可选项字段):
if ihl > 5:
options = ip_header[20:header_length]
print("Options Field:", options.hex())
else:
print("No Options Field")
逻辑分析:
- 判断IP头部长度是否大于20字节(即是否存在可选项)
- 若存在,提取可选项字段的内容并输出
通过本章内容的学习,读者应能够掌握IP协议的基本结构及其关键字段的作用,为后续深入理解IP分片机制和网络通信原理打下坚实基础。下一章将深入探讨IP数据包的分片机制及其在Wireshark中的分析方法。
3. IP数据包分片机制原理与Wireshark分析
在实际的网络通信中,数据包的大小并非总是能够适应网络链路的传输能力。当IP数据包长度超过链路的 最大传输单元(MTU) 时,就必须被分割为多个较小的片段进行传输,这个过程称为 IP分片(IP Fragmentation) 。理解IP分片机制对于网络故障排查、性能调优以及安全分析至关重要。
本章将从IP分片的理论基础出发,深入解析其触发机制与重组流程,重点讲解分片相关的字段含义,并结合Wireshark工具演示如何识别和分析分片数据包,帮助读者在实际网络环境中掌握这一关键技术。
3.1 分片机制的理论基础
3.1.1 分片的触发条件与流程
IP分片通常由 中间网络设备(如路由器) 在转发数据包时触发。当路由器接收到一个IP数据包,发现其长度超过了下一跳链路的MTU时,它必须决定是否允许分片:
- 如果 DF(Don’t Fragment)标志位为0 ,则允许分片。
- 如果DF标志位为1,则丢弃该数据包,并返回 ICMP Destination Unreachable(Code 4)——Fragmentation Needed and DF Set 错误消息。
分片流程详解:
-
判断是否需要分片 :
- 路由器检查下一跳链路的MTU值。
- 计算当前IP数据包的总长度减去IP头部长度,得到数据载荷大小。
- 若载荷大小 > (MTU - IP头部长度),则需要分片。 -
分片操作 :
- 原始数据包头部复制到每个分片中。
- 每个分片设置不同的 Fragment Offset 字段,表示该分片相对于原始数据载荷的偏移量。
- MF(More Fragments)标志位 用于指示是否还有后续分片。
- Identification字段 用于标识属于同一个原始数据包的所有分片。 -
传输分片 :
- 分片后的数据包分别发送至下一跳,可能通过不同路径到达目的主机。 -
重组分片 :
- 接收端收到所有分片后,根据ID字段和Fragment Offset进行重新组装。
3.1.2 分片重组过程与注意事项
IP分片的重组由 目的主机 完成,而非中间路由器。重组过程中需要注意以下几点:
- 分片必须来自同一个原始数据包 :通过ID字段匹配。
- 分片顺序需正确 :通过Fragment Offset字段确定。
- 超时机制 :若在一定时间内未收齐所有分片,则丢弃已收到的分片。
- 完整性检查 :重组完成后,进行校验确保数据完整。
⚠️ 注意 :IP协议本身不保证分片的可靠传输,若任一分片丢失,整个数据包将被丢弃,需依赖上层协议(如TCP)进行重传。
3.2 分片相关字段解析
3.2.1 分片标识符(ID)的作用与生成规则
IP头部中的 Identification字段(16位) 用于唯一标识属于同一个原始数据包的所有分片。每个主机在发送数据包时都会为其分配一个唯一的ID值,通常按顺序递增或随机生成。
示例:
Identification: 0x1a2b (6699)
- 作用 :接收端通过ID字段匹配属于同一数据包的多个分片。
- 生成规则 :
- Windows系统通常使用递增的计数器。
- Linux系统可配置为随机值(增强安全性,防止IP伪装攻击)。
3.2.2 DF(Don’t Fragment)与MF(More Fragments)标志位的含义
这两个标志位位于IP头部的Flags字段中(共3位,其中DF和MF为前两位):
| Bit | 字段名 | 含义 |
|---|---|---|
| 0 | Reserved | 保留位,必须为0 |
| 1 | DF | 1表示不允许分片,0表示允许 |
| 2 | MF | 1表示还有更多分片,0表示最后一个分片 |
示例代码(Wireshark中显示):
Flags: 0x2 (Don't Fragment)
或
Flags: 0x1 (More Fragments)
- DF标志位 常用于 Path MTU Discovery(路径MTU发现) 机制。
- MF标志位 用于指示是否还有后续分片,最后一个分片的MF为0。
3.2.3 碎片偏移字段的计算方式与意义
Fragment Offset字段(13位) 表示该分片在原始数据包中的起始位置(以8字节为单位)。
计算公式:
偏移值(字节) = Fragment Offset × 8
示例:
Fragment offset: 1480
实际偏移位置为: 1480 × 8 = 11840 字节。
- 意义 :
- 接收端根据偏移量正确拼接分片。
- 避免分片覆盖或顺序错乱。
分片示意图(mermaid流程图):
graph LR
A[原始IP数据包] --> B[分片1]
A --> C[分片2]
A --> D[分片3]
B --> E[Fragment Offset: 0]
C --> F[Fragment Offset: 1480]
D --> G[Fragment Offset: 2960]
3.3 Wireshark中分片包的识别与分析
3.3.1 打开pcapng文件并查看分片数据包
Wireshark支持多种捕获文件格式,包括 .pcap 和 .pcapng 。我们可以使用Wireshark打开一个包含IP分片的捕获文件,例如:
wireshark fragments.pcapng
在Wireshark界面中,分片数据包通常显示为:
[IP Fragment of datagram x]
其中x为Identification字段的值。
3.3.2 使用过滤器“ip.fragmented”筛选分片包
在Wireshark的显示过滤器栏中输入:
ip.fragmented
该过滤器将仅显示 被分片的数据包 。可以进一步结合其他条件进行筛选,例如:
ip.fragmented && ip.src == 192.168.1.1
筛选出特定源IP的分片包。
示例输出:
| No. | Time | Source | Destination | Protocol | Length | Info |
|---|---|---|---|---|---|---|
| 123 | 1.234567 | 192.168.1.1 | 192.168.1.2 | IP | 1500 | [IP Fragment of datagram 6699] |
| 124 | 1.235678 | 192.168.1.1 | 192.168.1.2 | IP | 1500 | [IP Fragment of datagram 6699] |
| 125 | 1.236789 | 192.168.1.1 | 192.168.1.2 | IP | 1400 | [IP Fragment of datagram 6699] |
3.3.3 利用Wireshark自动重组IP分片数据包
Wireshark支持自动重组分片数据包,使得用户可以直接查看完整的数据内容。
启用分片重组:
- 打开Wireshark,点击 Edit > Preferences 。
- 选择 Protocols > IPv4 。
- 勾选 Reassemble fragmented IPv4 datagrams 。
启用后,Wireshark将在 Packet Details面板 中显示完整的数据包结构,即使原始数据包是分片的。
示例分析:
假设我们捕获到三个分片,ID为0x1a2b(6699),内容如下:
- 分片1:Fragment Offset = 0, MF = 1
- 分片2:Fragment Offset = 1480, MF = 1
- 分片3:Fragment Offset = 2960, MF = 0
Wireshark将自动将这三个分片合并为一个完整的TCP或UDP数据包,并显示在 Reassembled TCP/UDP段 部分。
查看重组数据包的步骤:
- 选中任意一个分片数据包。
- 在 Packet Details 面板中展开 Internet Protocol Version 4 。
- 查看 [Fragmented IP protocol] 和 [Reassembled IPv4 datagram] 部分。
- 展开 [Reassembled Data] 即可查看完整应用层数据。
3.3.4 实战操作:手动分析分片数据包
在某些情况下,Wireshark无法自动重组分片数据包(如分片未全部捕获),此时需要手动分析。
手动分析步骤:
- 使用显示过滤器
ip.id == 0x1a2b查看所有分片。 - 观察每个分片的Fragment Offset和Total Length字段。
- 计算各分片的起始和结束位置。
- 使用Wireshark的 Export Packet Dissections 功能导出为JSON或XML格式,进行外部分析。
- 编写脚本将各分片拼接(Python示例):
import json
# 假设分片数据为三个字典对象,包含offset和payload
fragments = [
{"offset": 0, "payload": b"Hello, "},
{"offset": 1480 * 8, "payload": b"World!"},
{"offset": 2960 * 8, "payload": b" How are you?"},
]
# 按offset排序
fragments.sort(key=lambda x: x["offset"])
# 拼接
reassembled = b""
for frag in fragments:
reassembled += frag["payload"]
print(reassembled.decode())
📌 逻辑说明 :
- 每个分片的offset乘以8得到字节偏移。
- 将payload按偏移顺序拼接即可还原原始数据。
3.3.5 分片问题排查技巧
在实际网络中,分片可能导致数据包丢失或重组失败,常见问题包括:
- 分片丢失 :某一分片未被捕获或被丢弃。
- 分片乱序 :分片到达顺序错乱,导致重组失败。
- 分片重叠 :不同分片的offset区域重叠,造成数据污染。
Wireshark提示信息:
[IP Fragment overlap]:表示当前分片与其他分片存在重叠。[IP Fragment lost]:表示某些分片未被捕获。[IP Fragment timeout]:表示重组超时。
排查建议:
- 使用
ip.id == <ID>过滤所有分片。 - 检查每个分片的Fragment Offset和MF标志位。
- 使用
tcp.analysis.retransmission过滤查看是否存在重传。 - 使用Wireshark的 Statistics > Flow Graph 查看分片流图。
通过本章的学习,读者应能理解IP分片机制的基本原理,掌握Wireshark中分片数据包的识别、过滤与重组方法,并具备在实际网络中分析分片问题的能力。下一章将深入探讨IP分片与MTU之间的关系,进一步揭示网络性能优化的关键因素。
4. IP分片与MTU之间的关系及影响
IP协议在数据传输过程中,常常面临一个核心问题: 数据包的大小是否能够适应当前路径的传输能力 。这个问题直接引出了 最大传输单元(MTU) 和 IP分片机制 之间的关系。理解这种关系对于网络性能优化、数据完整性保障和安全防护至关重要。
本章将从MTU的基本概念入手,逐步深入探讨其与IP分片之间的联动机制,并分析分片对网络性能的影响。此外,我们还将通过Wireshark的实际抓包数据对比分片包与非分片包的结构差异,帮助读者全面掌握这一核心网络机制。
4.1 MTU的基本概念与配置
4.1.1 不同网络环境下的MTU默认值
MTU(Maximum Transmission Unit) 是指一个网络接口在一次传输中所能承载的 最大数据量(不包括链路层头部) 。常见的默认MTU值如下:
| 网络类型 | 默认MTU值(字节) |
|---|---|
| 以太网(Ethernet) | 1500 |
| PPPoE(拨号上网) | 1492 |
| IEEE 802.3 | 1492 |
| FDDI | 4352 |
| ATM(AAL5) | 9180 |
以太网是最常见的局域网技术,其默认MTU为1500字节。这意味着,一个IP数据包的最大有效载荷为1500字节减去IP头部长度(通常是20字节)和可能的TCP头部长度(20字节),因此实际TCP数据部分最多为1460字节。
注意 :如果IP数据包超过路径中的最小MTU值,就会被分片,或者在DF标志位被设置时丢弃并触发ICMP报文。
4.1.2 MTU对数据包大小的影响
MTU直接影响IP数据包的传输效率。当IP数据包长度超过路径中的MTU时,设备必须采取两种策略之一:
- 分片(Fragmentation) :将大包拆分为多个符合MTU限制的小包进行传输。
- 丢弃并返回ICMP错误 :若设置了DF(Don’t Fragment)标志,则丢弃该包,并向源主机发送ICMP Type 3 Code 4(Fragmentation Needed and DF Set)消息。
例如,若发送一个1500字节的IP包,但下一跳的MTU为1400字节:
- 如果DF标志为0,则路由器会将该包分片为两个IP数据包。
- 如果DF标志为1,则路由器丢弃该包,并发送ICMP消息,通知源主机需要减小数据包大小。
4.2 分片与路径MTU发现机制
4.2.1 路径MTU发现(Path MTU Discovery)原理
路径MTU发现(Path MTU Discovery,PMTUD) 是一种机制,用于确定从源主机到目标主机之间所有链路中 最小的MTU值 ,从而避免不必要的分片操作。
其工作原理如下:
- 源主机发送一个设置了DF标志的数据包。
- 若该数据包大小超过路径中某个链路的MTU:
- 中间路由器会丢弃该包。
- 向源主机发送ICMP Type 3 Code 4消息。
- 源主机收到该消息后,减少数据包大小,重新发送。 - 不断尝试,直到找到路径中最小的MTU值。
该机制适用于 IPv4 和 IPv6 ,但在IPv6中强制要求实现PMTUD,因为IPv6禁止中间路由器分片。
4.2.2 ICMP不可达消息与DF标志位的协同作用
当路由器发现一个设置了DF标志的数据包过大时,会发送ICMP不可达消息(Type 3 Code 4),其内容包含下一跳的MTU值。源主机可以根据该值调整后续数据包的大小。
例如,使用Wireshark抓取的ICMP不可达报文如下:
Internet Control Message Protocol
Type: 3 (Destination Unreachable)
Code: 4 (Fragmentation needed, and DF set)
Checksum: 0xXXXX
Unused: 0
Next-Hop MTU: 1400
代码示例 :使用Python模拟发送大包并观察ICMP响应
import socket
# 创建原始套接字
s = socket.socket(socket.AF_INET, socket.SOCK_RAW, socket.IPPROTO_ICMP)
# 构造大IP包
dest = "example.com"
payload = b"A" * 1473 # 超过1500字节
s.setsockopt(socket.SOL_IP, socket.IP_MTU_DISCOVER, socket.IP_PMTUDISC_DO)
try:
s.sendto(payload, (dest, 0))
except socket.error as e:
print(f"Socket error: {e}")
逐行解析:
socket.socket(socket.AF_INET, socket.SOCK_RAW, socket.IPPROTO_ICMP):创建原始套接字,用于发送ICMP包。payload = b"A" * 1473:构造一个1473字节的数据包,加上IP头后超过1500字节。setsockopt(..., socket.IP_PMTUDISC_DO):启用路径MTU发现机制。- 若发送失败,系统将返回错误,并触发ICMP响应。
4.3 分片对网络性能的影响
4.3.1 分片带来的延迟与丢包风险
分片虽然解决了大包传输的问题,但也带来了以下性能问题:
- 处理开销 :路由器需要额外计算分片偏移、标志位等字段,增加了CPU负载。
- 重组延迟 :接收端需要等待所有分片到达后才能重组,若某一分片丢失,整个数据包都会被丢弃。
- 丢包率上升 :由于分片后的包数量增加,网络拥塞时更容易出现丢包。
示例:使用Wireshark观察分片行为
在Wireshark中,可以通过过滤器 ip.fragmented 查看所有分片数据包。例如,查看一个TCP分片流:
Frame 123: 1514 bytes on wire (12112 bits), 1514 bytes captured
Ethernet II
Internet Protocol Version 4
Identification: 0x1234
Flags: 0x1 (MF)
Fragment offset: 0
...
Frame 124: 1480 bytes on wire (11840 bits), 1480 bytes captured
Ethernet II
Internet Protocol Version 4
Identification: 0x1234
Flags: 0x0
Fragment offset: 1480
4.3.2 分片对TCP性能的影响分析
TCP协议在传输大文件时,通常使用MSS(Maximum Segment Size)来控制每次发送的数据大小。MSS通常为MTU减去IP和TCP头部长度(1500 - 20 - 20 = 1460字节)。
若路径中存在较小的MTU而未正确发现,TCP可能发送超过MSS的数据段,导致IP分片。这会引发以下问题:
- 重传放大 :一个分片丢失会导致整个数据包重传。
- 吞吐量下降 :由于分片和重组开销,实际有效带宽降低。
优化建议 :
- 启用 路径MTU发现机制(PMTUD) 。
- 使用 TCP MSS Clamping ,强制中间设备将MSS限制为路径最小MTU减去头部长度。
4.4 分片与非分片数据包的结构对比
4.4.1 分片包与完整包的头部差异
| 字段 | 完整IP包 | 分片IP包 |
|---|---|---|
| 标识符(ID) | 相同 | 相同 |
| 标志位(Flags) | DF=0, MF=0 | MF=1(更多分片)、MF=0 |
| 偏移字段 | 0 | >0 |
| 总长度 | 完整数据包长度 | 分片后的包长度 |
| 上层协议头部 | 存在于第一个分片 | 仅存在于第一个分片 |
说明 :只有第一个分片包含TCP/UDP头部,后续分片仅包含数据部分。
4.4.2 使用Wireshark进行结构差异对比
使用Wireshark抓取一个大HTTP响应包并观察其分片情况:
sequenceDiagram
用户->>服务器: 发起大文件下载请求
服务器->>路由器1: 发送1500字节数据包
路由器1->>路由器2: 下一跳MTU为1400
路由器2->>路由器3: 分片为1400 + 124字节
路由器3->>客户端: 重组数据包
在Wireshark中,可以观察到如下字段变化:
[分片1]
Flags: 0x1 (MF)
Fragment Offset: 0
[分片2]
Flags: 0x0
Fragment Offset: 1480
总结与延伸
本章系统性地分析了 MTU与IP分片之间的关系 ,并深入探讨了路径MTU发现机制、分片对网络性能的影响以及分片包与非分片包的结构差异。通过Wireshark的实际抓包分析和代码示例,我们展示了如何在真实环境中观察和处理分片问题。
在实际网络运维中,合理配置MTU、启用PMTUD机制、优化TCP MSS设置,是避免分片、提升网络性能的关键。下一章将进一步讨论IP协议分析在网络安全与性能优化中的具体应用,包括分片攻击检测、网络故障排查等实战内容。
5. IP协议分析在网络安全与性能优化中的应用
通过对IP协议结构与分片机制的深入理解,可以在网络安全检测和网络性能优化方面发挥重要作用。本章将结合实际案例,展示IP协议分析的实用价值。
5.1 网络安全中的IP协议分析
IP协议分析不仅是网络通信的基础,同时也是识别和防范网络攻击的重要手段之一。其中,IP分片攻击(如Teardrop攻击)曾是早期网络攻击的典型代表。通过对IP分片行为的深入分析,可以有效识别并防范此类攻击。
5.1.1 分片攻击与IP碎片重组异常检测
IP协议允许将大数据包分片传输,但在接收端需要重新组装。攻击者可以利用这一机制发送重叠的分片数据包,导致接收方在重组时发生内存溢出或系统崩溃,从而实现拒绝服务攻击(DoS)。
Wireshark可以通过深度解析IP头中的“碎片偏移”和“MF(More Fragments)”标志位来识别异常分片行为。例如,以下是一个使用Wireshark过滤器筛选可疑分片包的示例:
ip.frag_offset > 0 && ip.len < 20
该过滤器将筛选出偏移值大于0且IP数据包长度小于20字节的数据包,这类数据包可能存在非法重组风险。
5.1.2 利用Wireshark发现异常分片行为
通过Wireshark的“Statistics”菜单中的“IP Fragments”功能,可以查看所有当前捕获的IP分片情况。若发现某个IP地址频繁发送大量分片数据包,或者分片重叠严重,则可能存在恶意行为。
| IP地址 | 分片数 | 最大偏移 | 重组状态 | 异常标记 |
|---|---|---|---|---|
| 192.168.1.10 | 12 | 1480 | 成功 | 否 |
| 10.0.0.15 | 35 | 2960 | 失败 | 是 |
| 172.16.0.2 | 8 | 960 | 成功 | 否 |
上表为Wireshark导出的IP分片统计信息,显示了不同IP地址的分片行为。其中10.0.0.15的重组失败且分片数较多,应引起关注。
5.2 网络性能优化中的IP分析
IP协议的分片机制虽然保障了大数据包的传输可能性,但也会带来性能损耗。通过分析IP分片行为,有助于优化网络配置,提升整体性能。
5.2.1 分析分片对网络吞吐量的影响
分片会导致以下性能问题:
- 增加延迟 :每个分片需独立传输,接收端需等待所有分片到达后才能重组。
- 降低吞吐量 :由于分片后每个包都需重新封装,增加了头部开销。
- 丢包风险增加 :任意一个分片丢失,整个数据包将被丢弃。
在Wireshark中,可通过以下方式分析分片对吞吐量的影响:
ip.flags.mf == 1
该过滤器可筛选出包含MF标志位为1的IP数据包,表示该包为分片包的一部分。
5.2.2 优化MTU设置以减少分片
通过合理配置MTU值,可以有效避免不必要的分片。例如,在以太网中默认MTU为1500字节,若网络路径中存在较小的MTU限制(如PPPoE连接为1492字节),则需手动调整。
使用以下命令可临时修改Linux系统的MTU值:
sudo ifconfig eth0 mtu 1492
参数说明:
-eth0:网络接口名称
-mtu 1492:设置接口的最大传输单元为1492字节
在Wireshark中,可以通过查看“Frame”部分的“Frame length”字段,确认数据包是否因MTU不匹配而被分片。
5.3 实战案例分析
结合实际网络环境,分析不同场景下的IP分片行为,并使用Wireshark进行网络故障排查和性能调优。
5.3.1 对比不同网络环境下的分片行为
在本地局域网(LAN)与广域网(WAN)中,由于路径MTU不同,IP分片行为可能显著不同。例如:
- 局域网(MTU=1500) :较少分片,性能较好。
- 广域网(MTU=1400) :频繁分片,吞吐量下降。
通过Wireshark对比两种环境下捕获的数据包,可以观察到:
ip.len > 1400
此过滤器可筛选出长度超过1400字节的数据包,用于分析是否发生分片。
5.3.2 使用Wireshark进行网络故障排查与性能调优
在一次网络故障排查中,用户报告访问某个网站时速度缓慢。通过Wireshark抓包分析发现大量分片包,且部分分片丢失。进一步分析发现该路径MTU为1400,但服务器发送的数据包大小为1500,导致分片后部分包丢失。
解决方案:
- 启用Path MTU Discovery(PMTUD) :确保路径中所有节点支持PMTUD。
- 调整TCP MSS值 :在路由器或主机上调整TCP的MSS值以适应最小MTU。
sudo iptables -A FORWARD -p tcp --tcp-flags SYN,RST SYN -j TCPMSS --set-mss 1360
说明:
---set-mss 1360:设置TCP MSS为1360字节,确保IP包总长度不超过1400字节(1360 + 40 = 1400)
5.4 IP协议分析的未来发展趋势
随着网络技术的发展,IP协议分析工具也在不断演进。未来的发展方向主要包括IPv6的普及、自动化分析工具的应用以及人工智能在协议分析中的引入。
5.4.1 IPv6对分片机制的改进
IPv6协议中, 分片功能被移除至发送端 ,接收端不再承担分片重组任务,从而提升了网络效率和安全性。IPv6的头部结构也进行了优化,不再包含“Flags”和“Fragment Offset”字段,而是通过“Fragment Extension Header”实现分片控制。
5.4.2 自动化分析工具与AI在IP协议分析中的应用前景
现代网络流量日益复杂,传统的人工分析方式已难以应对。未来,自动化协议分析工具(如Zeek、Suricata)将与AI技术结合,通过机器学习模型识别异常IP行为、自动检测攻击模式,并预测网络性能瓶颈。
例如,AI模型可以学习正常网络行为的分片模式,并在发现异常分片组合时自动告警。以下是一个简单的AI分析流程图:
graph TD
A[数据包捕获] --> B{是否为分片包?}
B -->|是| C[提取分片特征]
C --> D[输入AI模型]
D --> E[输出异常评分]
E --> F{评分 > 阈值?}
F -->|是| G[标记为异常]
F -->|否| H[标记为正常]
B -->|否| H
该流程展示了如何通过AI模型辅助IP协议分析,提高检测效率和准确率。
简介:Wireshark是一款广泛用于网络故障排查、安全分析和协议学习的封包分析工具。本案例聚焦于Wireshark对IP协议的分析,特别探讨IP数据包的分片机制。通过提供的”ip.pcapng”和”ip_frag.pcapng”两个抓包文件,学习者可以深入了解IP协议头部结构、分片与重组过程,并掌握使用Wireshark进行数据包分析和重组的实战技能。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献176条内容
已为社区贡献176条内容

所有评论(0)