告别复杂配置!FunASR语音识别WebUI一键部署,上传音频秒出文字
本文介绍了如何在星图GPU平台上自动化部署FunASR语音识别镜像(基于speech_ngram_lm_zh-cn二次开发构建by科哥),实现音频文件快速转文字功能。该解决方案提供零配置WebUI界面,特别适合会议记录、访谈转录等场景,用户上传音频即可秒级获取精准文本输出,大幅提升语音处理效率。
告别复杂配置!FunASR语音识别WebUI一键部署,上传音频秒出文字
1. 为什么选择FunASR WebUI
语音识别技术已经深入到我们工作和生活的方方面面,但传统ASR系统的部署和使用门槛一直让很多非专业用户望而却步。今天要介绍的FunASR WebUI镜像,彻底改变了这一局面。
这个由科哥二次开发的镜像,基于阿里达摩院的FunASR框架和speech_ngram_lm_zh-cn语言模型构建,具有三大核心优势:
- 零配置部署:预装所有依赖和模型,真正做到开箱即用
- 直观可视化界面:告别命令行操作,所有功能点点鼠标就能完成
- 专业级识别效果:融合Paraformer大模型和N-gram语言模型,准确率媲美商业方案
无论你是需要转录会议录音的内容创作者,还是想要为应用添加语音交互能力的开发者,这个解决方案都能让你在5分钟内搭建起完整的语音识别系统。
2. 快速部署指南
2.1 环境准备
在开始前,请确保你的系统满足以下要求:
-
操作系统:Linux (推荐Ubuntu 20.04+) 或 Windows WSL2
-
硬件配置:
- CPU:4核以上
- 内存:8GB以上
- 如有NVIDIA显卡(推荐),请提前安装好CUDA驱动
-
软件依赖:
- Docker Engine 20.10+
- 约5GB可用磁盘空间
2.2 一键启动服务
打开终端,执行以下命令即可完成部署:
# 拉取镜像
docker pull your-mirror-repo/funasr-webui:latest
# 运行容器(GPU版本)
docker run -d --gpus all -p 7860:7860 -p 10095:10095 \
-v /path/to/local/models:/workspace/models \
your-mirror-repo/funasr-webui:latest
如果是纯CPU环境,去掉--gpus all参数即可。首次运行会自动下载所需模型文件,视网络情况可能需要10-30分钟。
2.3 访问Web界面
服务启动完成后,在浏览器中输入:
http://localhost:7860
如果是从其他设备访问,将localhost替换为服务器IP地址。看到如下界面说明部署成功:
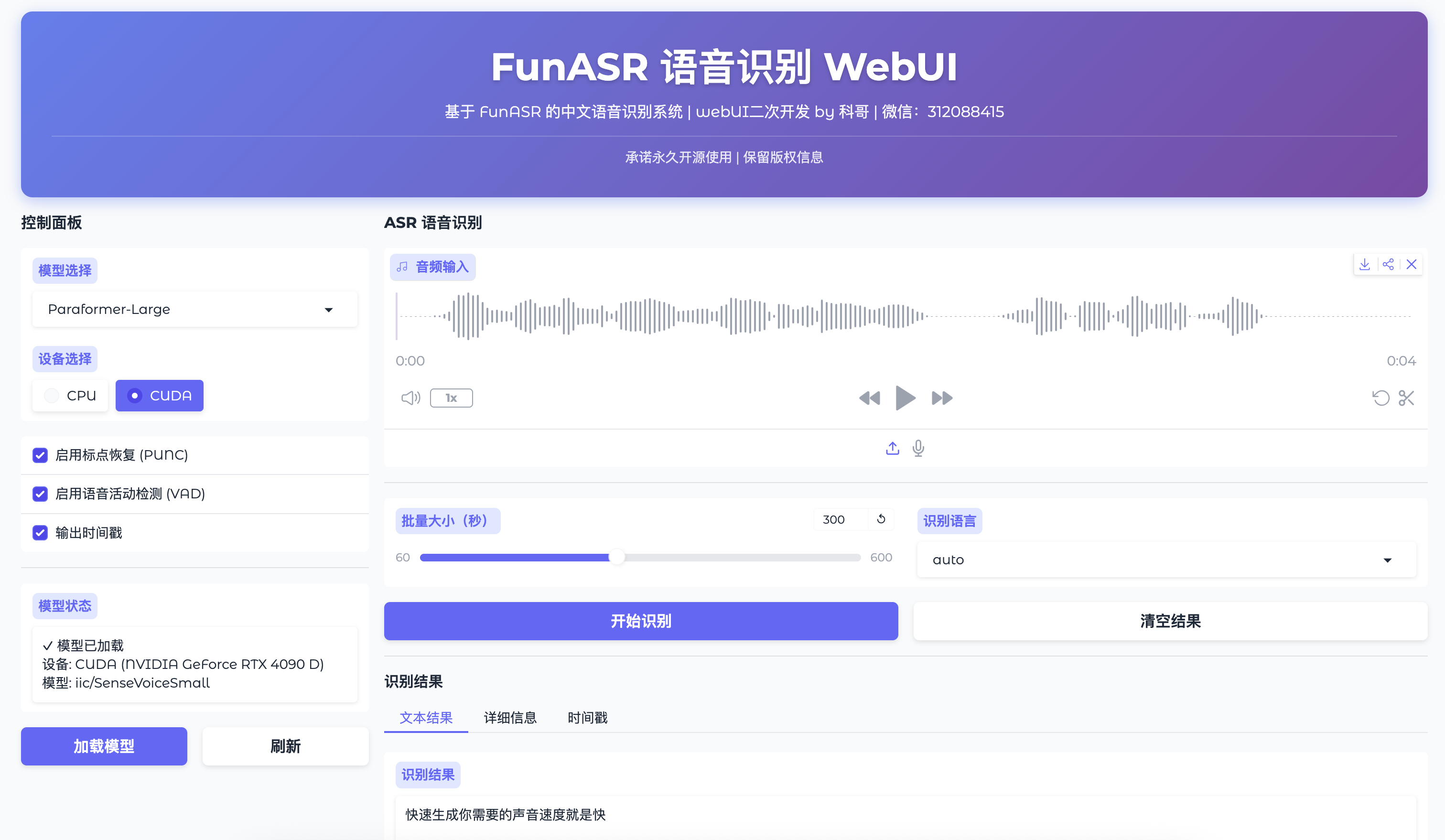
3. 核心功能详解
3.1 音频文件识别
这是最常用的功能,支持多种音频格式:
-
点击"上传音频"按钮,选择本地文件(支持MP3/WAV/M4A等格式)
-
选择识别模型:
- Paraformer-Large:高精度模式,适合正式场合录音
- SenseVoice-Small:快速模式,适合实时性要求高的场景
-
设置识别参数:
- 语言选择(自动/中文/英文等)
- 是否启用标点恢复
- 是否输出时间戳
-
点击"开始识别",等待处理完成
3.2 实时录音识别
对于需要即时转写的场景:
- 点击"麦克风录音"按钮,授权浏览器使用麦克风
- 开始说话,界面会实时显示录音波形
- 点击"停止录音"结束采集
- 点击"开始识别"获取文字结果
这个功能特别适合访谈记录、会议纪要等场景,识别延迟通常在1-2秒内。
3.3 结果导出与使用
识别完成后,你可以:
- 直接复制文本:用于即时粘贴到文档中
- 下载多种格式:
- TXT:纯文本格式
- JSON:包含完整元数据和置信度
- SRT:字幕文件,可直接导入视频编辑软件
所有输出文件会自动保存在outputs目录下,按时间戳分类存储,方便管理大量录音文件。
4. 高级技巧与优化建议
4.1 提升识别准确率
虽然默认配置已经能提供不错的效果,但通过以下调整可以进一步提升准确率:
-
选择合适的模型:
- 清晰的人声录音 → Paraformer-Large
- 带背景音的录音 → 开启VAD(语音活动检测)
- 专业领域内容 → 添加热词(见下文)
-
音频预处理:
- 确保采样率为16kHz
- 音量不宜过小(波形振幅建议在-3dB到-6dB之间)
- 使用Audacity等工具降噪(如有明显背景噪音)
4.2 热词定制技巧
对于包含专业术语的场景(如医疗、法律、科技),可以创建hotwords.txt文件:
冠状动脉 20
刑事诉讼法 15
神经网络 25
每行格式为热词 权重,权重范围1-100。将文件放在挂载的模型目录下,系统会自动加载。
4.3 批量处理长音频
对于超过5分钟的音频,建议:
- 在"批量大小"设置中调整分段时长(默认300秒)
- 或者先用ffmpeg分割音频:
ffmpeg -i long.mp3 -f segment -segment_time 300 -c copy out%03d.mp3 - 使用脚本批量上传处理
5. 常见问题解答
5.1 识别结果不准确怎么办?
- 检查音频质量,确保人声清晰
- 尝试切换不同语言模式(特别是中英混合内容)
- 添加相关热词提升专业术语识别率
- 如为方言,可尝试调整发音字典
5.2 服务启动失败的可能原因
- 端口冲突:7860或10095端口被占用,可修改映射端口
- 显存不足:尝试使用CPU模式或减小batch_size
- 模型下载失败:检查网络连接,或手动下载模型放置到挂载目录
5.3 如何集成到自己的应用中?
系统提供WebSocket API接口,开发文档如下:
import websockets
async def recognize_audio(audio_path):
async with websockets.connect('ws://localhost:10095') as ws:
# 发送配置
await ws.send('{"mode":"offline","wav_name":"test"}')
# 发送音频数据
with open(audio_path, 'rb') as f:
await ws.send(f.read())
# 获取结果
result = await ws.recv()
print(result)
6. 总结
FunASR WebUI镜像将专业的语音识别能力封装成了人人都能使用的傻瓜式工具,其核心价值在于:
- 极简部署:一条命令完成专业ASR系统搭建
- 开箱即用:精心优化的默认配置满足大部分场景
- 灵活扩展:支持热词定制、API集成等高级需求
无论是个人用户快速转录录音文件,还是企业开发者构建语音交互功能,这都是目前最简单高效的解决方案。现在就动手尝试,体验语音转文字的效率革命吧!
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 2
2 0
0- 0



 已为社区贡献166条内容
已为社区贡献166条内容

所有评论(0)