彻底搞懂消息队列:Kafka/RabbitMQ架构对比与实战指南
消息队列是分布式系统中不可或缺的中间件,能够实现异步通信、系统解耦和流量削峰。本文将深入对比两大主流消息队列Kafka与RabbitMQ的架构设计、核心特性及适用场景,帮助你快速掌握消息队列选型与实战技巧。## 消息队列核心价值与应用场景消息队列本质是一个存储消息的容器,通过"生产者-消费者"模型实现跨服务通信。现代分布式系统中,消息队列主要解决三大核心问题:### 异步处理:提升系统
彻底搞懂消息队列:Kafka/RabbitMQ架构对比与实战指南
 项目地址: https://gitcode.com/gh_mirrors/ja/JavaGuide
项目地址: https://gitcode.com/gh_mirrors/ja/JavaGuide 消息队列是分布式系统中不可或缺的中间件,能够实现异步通信、系统解耦和流量削峰。本文将深入对比两大主流消息队列Kafka与RabbitMQ的架构设计、核心特性及适用场景,帮助你快速掌握消息队列选型与实战技巧。
消息队列核心价值与应用场景
消息队列本质是一个存储消息的容器,通过"生产者-消费者"模型实现跨服务通信。现代分布式系统中,消息队列主要解决三大核心问题:
异步处理:提升系统响应速度
将非核心流程通过消息队列异步化,缩短主流程响应时间。例如用户下单后,订单系统只需将消息发送到队列即可返回成功,后续的库存扣减、物流通知等操作由消费者异步处理。
流量削峰:保护后端系统
面对秒杀等高并发场景,消息队列可暂存瞬时洪峰请求,再按照系统处理能力匀速消费,避免直接压垮数据库等核心服务。
系统解耦:降低服务依赖
通过消息队列隔离服务间直接调用,上游服务只需关注消息生产,下游服务按需消费,极大提升系统扩展性。
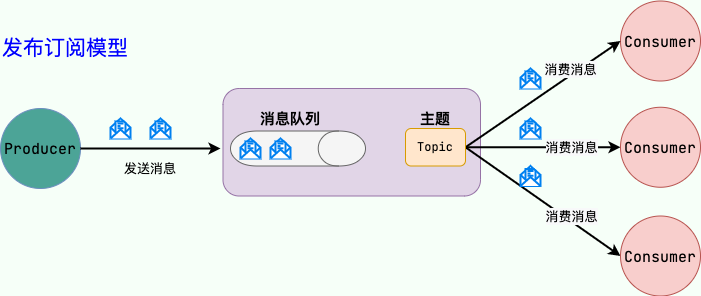
Kafka架构深度解析
Kafka作为分布式流式处理平台,以高吞吐量和持久化能力著称,其核心架构包含以下组件:
核心概念与数据模型
- Topic(主题):消息分类容器,类似数据库表
- Partition(分区):主题的物理分片,实现水平扩展
- Broker(代理节点):Kafka服务器实例
- Consumer Group(消费者组):多个消费者协同消费主题
Kafka通过分区机制实现高并发,每个分区只能被同一消费者组的一个消费者消费,保证消息顺序性。

高性能设计原理
- 顺序写入:消息追加到分区尾部,避免随机IO
- 零拷贝技术:直接通过内核缓冲区传输数据,减少用户态切换
- 批量处理:合并小消息批量发送,降低网络开销
- 数据持久化:消息落盘存储,支持数据重放
可靠性保障机制
- 多副本策略:每个分区可配置多个副本,通过ISR(同步副本集)保证数据不丢失
- ACK机制:生产者可配置消息确认级别(0/1/all)
- 日志清理:基于时间或大小的日志滚动策略
RabbitMQ架构深度解析
RabbitMQ基于AMQP协议实现,以灵活的路由机制和丰富的消息特性为特色:
核心概念与消息路由
- Exchange(交换机):接收生产者消息并路由到队列
- Queue(队列):存储消息直到被消费
- Binding(绑定):定义交换机与队列间的路由规则
交换机类型与应用场景
- Direct Exchange:精确匹配路由键,适合点对点通信
- Topic Exchange:支持通配符匹配,实现灵活路由
- Fanout Exchange:广播消息到所有绑定队列,实现发布订阅
- Headers Exchange:基于消息头属性路由,较少使用
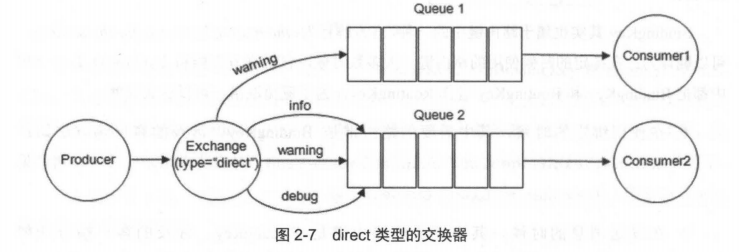
高级特性
- 死信队列:处理失败或过期消息
- 延迟队列:通过TTL+死信交换机实现消息延时投递
- 优先级队列:支持消息优先级排序
- 镜像队列:实现队列高可用
Kafka与RabbitMQ关键指标对比
| 特性 | Kafka | RabbitMQ |
|---|---|---|
| 吞吐量 | 十万级/秒 | 万级/秒 |
| 延迟 | 毫秒级 | 微秒级 |
| 消息可靠性 | 可配置(0/1/all) | 强可靠性 |
| 消息顺序 | 分区内有序 | 队列内有序 |
| 路由灵活性 | 简单(主题路由) | 丰富(多种交换机类型) |
| 适用场景 | 大数据流处理、日志收集 | 业务解耦、异步通信 |
典型应用场景推荐
- Kafka:日志收集、用户行为分析、实时数据管道
- RabbitMQ:订单处理、通知推送、服务解耦
实战配置与最佳实践
Kafka核心配置优化
# 生产者配置
acks=all # 消息确认级别
retries=3 # 重试次数
batch.size=16384 # 批量大小
linger.ms=5 # 等待时间
# 消费者配置
enable.auto.commit=false # 关闭自动提交
max.poll.records=500 # 每次拉取数量
RabbitMQ高级特性实现
- 死信队列配置
// 声明死信交换机
channel.exchangeDeclare("dlx.exchange", "direct");
// 声明普通队列并绑定死信交换机
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "dlx.exchange");
channel.queueDeclare("normal.queue", true, false, false, args);
- 延迟队列实现
// 设置消息TTL
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder()
.expiration("5000") // 5秒后过期
.build();
channel.basicPublish("exchange", "routingKey", properties, message.getBytes());
消息队列常见问题解决方案
消息丢失问题
- 生产者:启用确认机制,失败重试
- 服务端:配置持久化,多副本策略
- 消费者:手动确认消息,处理完成后提交offset
消息重复消费
- 实现业务幂等性(如唯一ID去重)
- 消费端处理逻辑设计为可重入
消息积压处理
- 临时扩容消费者实例
- 优化消费逻辑,提高处理速度
- 历史数据归档,避免重复处理
选型决策指南
选择Kafka还是RabbitMQ,需综合评估以下因素:
- 吞吐量需求:高吞吐量选Kafka
- 延迟敏感:低延迟选RabbitMQ
- 路由复杂度:复杂路由选RabbitMQ
- 数据持久化:需长期存储选Kafka
- 生态集成:大数据场景优先Kafka
消息队列作为分布式系统的"胶水",选择合适的产品并合理配置,能有效提升系统可靠性与扩展性。无论是Kafka的高吞吐还是RabbitMQ的灵活路由,关键在于理解其设计理念并结合业务场景做出最佳选择。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 25
25 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)