Pulsar IO:零代码实现数据同步
它就像一根"数据管道"——一端连着你的数据源(比如 MySQL),另一端连着你的目标系统(比如 Elasticsearch、Redis、PostgreSQL),中间的脏活累活全部由平台自动完成:。360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。加一个订阅就行,不用改订单系统的一行代码。数据团队需要把线上 MySQL 的
还在为数据同步写代码?还在半夜被同步任务告警吵醒?是时候换个方式了。
一、你是否正在经历这些痛苦?
场景 A: 运营在后台改了一个商品价格,用户在 APP 搜索页看到的还是旧价格——因为 MySQL 和 Elasticsearch 之间的同步脚本又挂了。
场景 B: 数据团队需要把线上 MySQL 的订单数据同步到分析库做报表,DBA 写了一套定时全量 dump 脚本,每天凌晨跑一次,白天的数据永远看不到。
场景 C: 用户下单支付成功,但物流迟迟没有发货通知——因为订单系统和物流系统之间靠轮询数据库来感知状态变化,延迟高达分钟级。
场景 D: 架构师想给核心表的每一次变更记一份审计日志,开发团队评估后说"至少要两周,还得改十几个服务的写入逻辑"。
如果这些场景让你觉得似曾相识,那么这篇文章就是为你写的。
二、一句话说清 Pulsar IO 能做什么
Pulsar IO 可以让你不写一行代码,就把数据从 A 系统实时同步到 B 系统。
企业的数据往往散落在不同类型的存储系统中:MySQL 存业务数据,Elasticsearch 做搜索,Redis 做缓存,ClickHouse 做分析,MongoDB 存日志…… Pulsar IO 可以在这些不同类型的系统之间建立实时的数据同步通道,无需编写任何代码。它就像一根"数据管道"——一端连着你的数据源(比如 MySQL),另一端连着你的目标系统(比如 Elasticsearch、Redis、PostgreSQL),中间的脏活累活全部由平台自动完成:
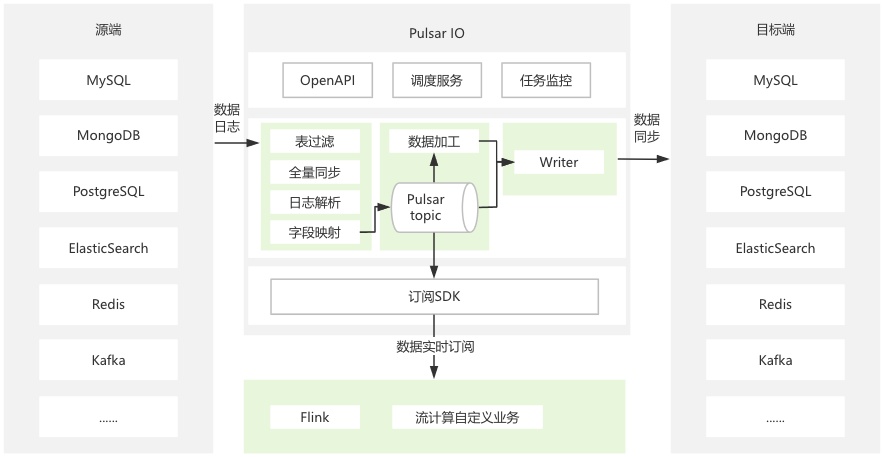
你只需要告诉平台"从哪来、到哪去",剩下的事情交给 Pulsar。
1、核心优势
-
零代码:只需编写配置文件,不需要写任何 Java/Python 代码
-
内置 30+ 连接器:覆盖 MySQL、PostgreSQL、MongoDB、Elasticsearch、Kafka、Redis、HDFS 等主流系统
-
Exactly-Once 语义:配合 Pulsar 事务,可实现端到端精确一次语义
-
弹性伸缩:通过
parallelism参数调整并发度,由 Pulsar Functions Worker 自动调度 -
统一管理:通过
pulsar-adminCLI 或 REST API 统一创建、监控、更新、停止连接器
2、内置连接器一览
Debezium 是业界最成熟的 CDC(Change Data Capture)框架。Pulsar 原生集成了 Debezium,支持 MySQL、PostgreSQL、MongoDB、Oracle、SQL Server 五大数据库。
|
类型 |
连接器 |
|
CDC Source |
Debezium MySQL、Debezium PostgreSQL、Debezium MongoDB、Debezium Oracle、Debezium MSSQL、Canal |
|
消息队列 |
Kafka、RabbitMQ、NSQ |
|
数据库 Sink |
JDBC PostgreSQL、JDBC MariaDB、JDBC ClickHouse、MongoDB、Cassandra、HBase |
|
搜索引擎 |
Elasticsearch / OpenSearch、Solr |
|
缓存 |
Redis |
|
大数据存储 |
HDFS、Alluxio |
|
云服务 |
AWS Kinesis、DynamoDB、Azure Data Explorer |
三、典型业务场景
场景 1:搜索实时性保障
"用户搜索的结果必须和数据库保持一致。"
痛点: 商品、文章、用户资料等数据存在 MySQL 中,搜索功能依赖 Elasticsearch。两者之间的同步一旦滞后或故障,用户搜到的就是过期数据,甚至搜不到刚发布的内容。
Pulsar IO 方案: 自动监听 MySQL 的每一条变更,实时推送到 Elasticsearch。从数据写入 MySQL 到 Elasticsearch 可搜索,延迟通常在秒级以内。无需编码,无需定时任务。
MySQL 商品表 ──[实时变更捕获]──▶ Pulsar ──[自动写入]──▶ Elasticsearch 商品索引 ↑ 价格改了?搜索结果秒级更新场景 2:缓存自动更新
"数据库改了,缓存怎么同步失效?"
痛点: 很多团队在代码里手动维护"写数据库 + 清缓存"的逻辑。一旦漏写、异常、或者有人直接改数据库,缓存和数据库就不一致了。用户看到的就是脏数据。
Pulsar IO 方案: 不管数据怎么被修改(应用写入、DBA 手动改、其他系统改),只要数据库有变化,Pulsar 就会捕获到,并自动同步到 Redis 缓存。彻底消除缓存不一致的隐患。
任何方式写入 MySQL ──[变更自动捕获]──▶ Pulsar ──[自动同步]──▶ Redis 缓存场景 3:跨系统事件驱动
"订单支付成功后,怎么最快通知到下游?"
痛点: 订单状态变更后需要触发多个下游动作(物流发货、积分发放、短信通知、数据统计……)。传统做法是在支付回调里依次调用各个系统,耦合严重、链路越来越长、一个下游超时整个链路就卡住。
Pulsar IO 方案: 监听订单表的状态变化,变更事件自动进入 Pulsar。各下游系统独立订阅自己关心的事件,互不影响。新增下游?加一个订阅就行,不用改订单系统的一行代码。
订单表 status 变更 │ ▼ Pulsar ╱ │ ╲ ▼ ▼ ▼ 物流 积分 短信 ← 各自独立消费,互不干扰场景 4:数据变更审计
"监管要求我们记录每一条数据的变更历史。"
痛点: 传统审计方案需要在每个写入点埋日志逻辑,开发工作量大、容易遗漏。如果有人绕过应用直接改库,审计日志就丢失了。
Pulsar IO 方案: 直接从数据库层面捕获所有变更(包含变更前后的完整数据),不依赖应用代码。无论数据是谁改的、怎么改的,都能完整记录。天然适合金融、医疗、政务等合规审计场景。
所有数据变更(不论来源) │ ▼ Pulsar 持久化存储 ──▶ 审计日志库 / 归档存储 │ └── 变更前的值是什么?变更后是什么?谁改的?什么时候改的?全部记录场景 5:数据库迁移的安全保障
"我们要从 MySQL 迁移到 PostgreSQL,但不敢一步切。"
痛点: 数据库迁移最怕的是数据不一致。全量迁移后如果发现问题想回滚,增量数据已经丢了。
Pulsar IO 方案: 迁移期间让新旧数据库实时双写——Pulsar 捕获旧库的变更,自动同步到新库。业务可以逐步切流验证,不一致随时可以回滚。迁移完成后关掉同步链路即可。
场景 6:一份数据,多个目标(扇出同步)
业务需求: 同一份业务数据需要同时同步到搜索引擎、缓存、分析库、日志归档等多个目标。
传统做法: 为每个目标写一套同步逻辑,或者在代码里层层调用。每加一个目标,就要改一次代码,测试一次上线。
Pulsar IO 做法: 一次采集,多次分发。Pulsar 从 MySQL 采集一份变更流,多个目标系统各自独立消费。新增目标?加一个配置即可,不需要碰现有的任何链路。
┌──▶ Elasticsearch (搜索) │ ├──▶ Redis (缓存) │MySQL ──▶ Pulsar (采集一次) ──┤ │ ├──▶ ClickHouse (分析) │ └──▶ 归档存储 (审计)对 MySQL 只采集一次,不增加线上数据库压力任何一个目标出问题,不影响其他目标场景 7:实时分析 MySQL → ClickHouse / PostgreSQL
业务需求: 业务数据存在 MySQL OLTP 库中,数据分析团队需要在分析库(ClickHouse、PostgreSQL 等)中做复杂查询和报表。
传统做法: 每天凌晨跑一次全量 ETL,白天的数据要第二天才能看到。数据团队经常抱怨"昨天的数据今天还没到"。
Pulsar IO 做法: 实时同步,MySQL 中的每一条变更都在秒级写入分析库。数据团队终于可以看到"此刻"的数据。
┌──▶ ClickHouse (实时报表) │MySQL (业务库) ──▶ Pulsar ──┤ │ └──▶ PostgreSQL (自助分析)四、为什么选择 Pulsar IO 而不是自己写?
1. 零代码,开箱即用
不需要写 Java、Python 或者任何同步脚本。只需要提供"从哪来"和"到哪去"的信息,平台完成剩余所有工作。30+ 内置连接器覆盖主流数据系统。
2. 实时,不是"准实时"
数据变更从源端到目标端,端到端延迟通常在秒级以内。不是定时轮询的"准实时",而是基于数据库日志的真正实时推送。
3. 不丢数据,可断点续传
即使同步链路中间发生故障(网络抖动、目标系统宕机等),恢复后会自动从断点继续,不会丢失数据、不会重复处理。
4. 对线上数据库零侵入
不需要修改任何业务代码,不需要在应用里加"双写"逻辑。Pulsar IO 直接读取数据库的变更日志(binlog / WAL),对线上业务完全透明。
5. 一次采集,多处分发
同一份变更数据可以同时分发给多个目标系统,每个目标独立消费、互不干扰。新增目标不需要改动任何已有配置。
6. 平台化运维,统一管控
所有同步链路在统一平台上管理:启动、停止、监控、告警、配置变更,一站式操作。不用再逐个维护散落的同步脚本。
五、传统方案 vs Pulsar IO 方案
|
传统自研方案 |
Pulsar IO 方案 |
|
|
搭建耗时 |
周 ~ 月级 |
小时级 |
|
代码量 |
数千行同步代码 |
零代码(配置驱动) |
|
数据延迟 |
分钟 ~ 小时(定时任务) |
亚秒 ~ 秒级(实时流) |
|
故障恢复 |
手动排查、手动补数据 |
自动断点续传 |
|
数据库侵入 |
需改业务代码加"双写" |
零侵入,读取变更日志 |
|
新增同步目标 |
改代码、测试、上线 |
加一个配置即可 |
|
维护成本 |
持续投入人力 |
平台托管 |
|
可观测性 |
自建监控 |
平台统一监控 |
六、哪些团队适合用 Pulsar IO?
请对照以下清单,如果你的团队命中了任意一项,Pulsar IO 都能帮到你:
-
有 MySQL / PostgreSQL / MongoDB 等数据库,需要将变更实时同步到其他系统
-
搜索功能依赖 Elasticsearch,但搜索结果和数据库经常不一致
-
缓存(Redis)和数据库之间存在数据不一致问题
-
数据分析团队抱怨数据延迟,每天只能看"昨天的数据"
-
业务代码里写了大量的"双写"逻辑,维护成本越来越高
-
正在做数据库迁移(比如 MySQL → PostgreSQL),需要实时双写保障
-
有合规审计需求,需要记录数据的完整变更历史
-
订单、支付等状态变更需要实时通知多个下游系统
-
团队维护着多套同步脚本/定时任务,经常出问题
七、下一步
如果你的业务有以上场景,欢迎联系我们进一步沟通。我们可以:
-
场景评估:帮你梳理当前的数据同步需求,评估 Pulsar IO 的适用性
-
方案设计:根据你的数据源、目标系统和业务要求,设计完整的同步方案
-
快速验证:最快半天完成 POC 验证,用你的真实数据跑通全链路
-
上线支持:提供生产环境部署和调优支持
END
360智汇云AI产品推荐:
大模型开发TLM:https://zyun.360.cn/product/tlm
AI标注平台TLP:https://zyun.360.cn/product/tlp
AI评测平台TEP:https://console.zyun.360.cn/tep
MCP市场MCPMKT:https://console.zyun.360.cn/mcpmkt
智能体对话AIMI:https://zyun.360.cn/product/aimi
智能体记忆AMS:https://console.zyun.360.cn/ams/
更多技术干货,
请关注“360智汇云开发者”👇
360智汇云是以"汇聚数据价值,助力智能未来"为目标的企业应用开放服务平台,融合360丰富的产品、技术力量,为客户提供平台服务。目前,智汇云提供数据库、中间件、存储、大数据、人工智能、计算、网络、视联物联与通信等多种产品服务以及一站式解决方案。
官网:https://zyun.360.cn(复制在浏览器中打开)
更多好用又便宜的云产品,欢迎试用体验~
如果您想使用我们的计算、中间件类产品(目前官网暂时不可见),欢迎联系我们客服为您开通。
添加工作人员企业微信👇,get更快审核通道+试用包哦~


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)