xinference驱动多模态模型利用自定义tool对接maxkb+全离线环境迁移实践
一、版本
起点os : win10(22H2)
目标os : win10(20H2)
xinference : v2.0.0
maxkb : v2.5.0(社区版,dockerdesktop部署)
当前常用的两个离线推理框架对接maxkb支持情况如下表:
| 大语言模型 | 向量模型 | 重排模型 | 语音识别 | 语音合成 | 视觉模型 | 图片生成 | 文生视频 | 图生视频 | |
| Ollama | ✔ | ✔ | ✔ | ✔ | |||||
| XInference | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
二、联网环境部署(这里重点讲解xinference)
//创建虚拟环境(路径要提前考虑好,迁移前后conda环境需完全一致)
conda create --prefix E:\xinference\xinference_envs\xinference_cosyvoice python=3.10 -y
conda activate E:\xinference\xinference_envs\xinference_cosyvoice
//此镜像源下载的还是cpu版本,但是我们为了速度,先执行此命令完成下级依赖快速安装
pip install torch torchvision torchaudio -f https://mirrors.aliyun.com/pytorch-wheels/cu118
//卸载cpu版本torch
pip uninstall torch torchvision torchaudio -y
//在官网下载gpu版本torch
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
//只涉及多模态模型,先只安装transformers加载器相关
pip install "xinference[transformers]"
//安装模型,后续也可以在xinference的ui启动
xinference launch --model-name CosyVoice-300M --model-type audio --endpoint "http://localhost:9998"
xinference launch --model-name CosyVoice-300M-SFT --model-type audio --endpoint "http://localhost:9998"
//后续可能还需要补充pip install特定模型的依赖,可先试运行,遇到问题再补充为启动服务,编写.bat。
@echo off
REM Xinference 持久化启动脚本
REM 修改下面的路径为你的实际环境路径
:: 设置环境变量(关键参数)
set XINFERENCE_HEALTH_CHECK_TIMEOUT=60
set XINFERENCE_HOME=E:\xinference\xinference_cache\xinference_cosyvoice
set LOG_LEVEL=info
set HF_ENDPOINT=https://hf-mirror.com
:: 设置conda环境路径(修改为你的实际路径)
set CONDA_ENV_PATH=E:\xinference\xinference_envs\xinference_cosyvoice
:: 激活conda环境(后续迁移,修改为conda实际路径)
call F:\ProgramData\anaconda3\Scripts\activate.bat %CONDA_ENV_PATH%
:: 启动Xinference
echo [%date% %time%] Starting Xinference...
xinference-local --host 127.0.0.1 --port 9998
pause由于可能涉及模型依赖冲突,故采取较为激进的办法:为每类模型单独启xinference服务。则需要多次执行上述步骤。
三、模型接入
对于CosyVoice-300M-SFT等添加模型时预设下拉框内已有的模型,直接填写表单添加后使用组件即可, API URL格式为http://host.docker.internal:9998/v1。
对于Cosyvoice-300M等添加模型时预设下拉框内没有的模型或者模型类型,一般maxkb未为此做好组件,此时不再需要在ui中执行添加模型,而是需要用户自定义工具作为组件,分享工具代码如下:
import requests
import uuid
from xinference_client import RESTfulClient
def main(input_text: str, audio_file_list: list, prompt_text: str, base_url: str, auth_token: str):
# 1. 下载参考音频
file_id = audio_file_list[0]['file_id']
headers = {"Authorization": f"Bearer {auth_token}"} if auth_token else {}
ref_audio = requests.get(f"{base_url.rstrip('/')}/oss/file/{file_id}", headers=headers).content
# 2. 生成克隆音频
client = RESTfulClient("http://172.30.80.1:9998")
model = client.get_model("CosyVoice-300M")
speech_bytes = model.speech(input=input_text, prompt_text=prompt_text, prompt_speech=ref_audio)
# 3. 上传生成的音频
files = {'file': (f"cloned_{uuid.uuid4().hex[:8]}.mp3", speech_bytes, 'audio/mpeg')}
upload_resp = requests.post(f"{base_url.rstrip('/')}/api/oss/file", headers=headers, files=files).json()
# 4. 返回音频标签
file_path = upload_resp.get('data')
return f'<audio controls src="{file_path}"></audio>'配置如下: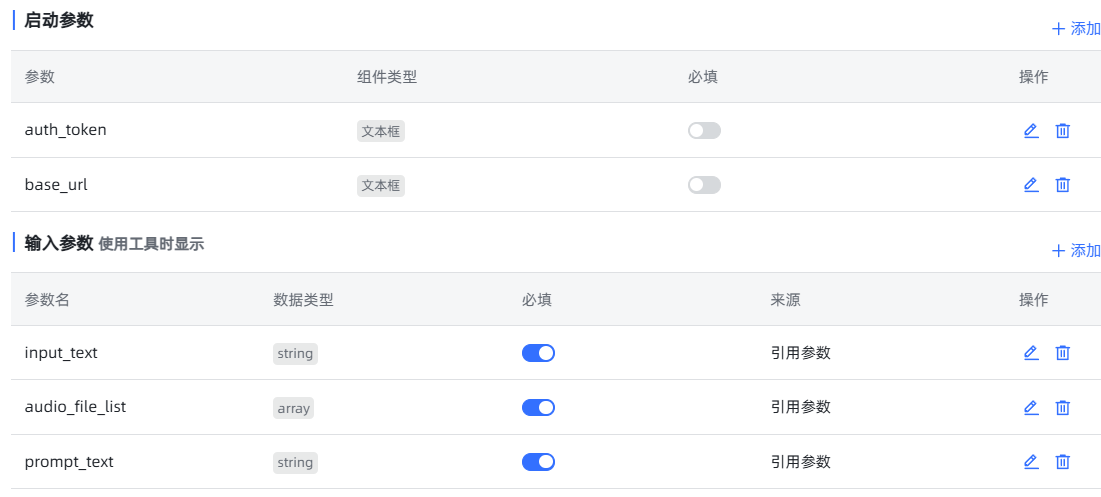
需注意几点:
1.需预先进入容器pip install需要的依赖。
2.上传文件和下载文件接口需鉴权,auth_token为智能体访问密钥。
3.base_url为maxkb服务地址,这里需填写http://172.30.80.1:8080/chat。
4.可能因自定义工具安全性问题,当决定使用时,需统一设置172.30.80.1(单机以太网适配器 vEthernet (WSL):地址),而非127.0.0.1或者host.docker.internal,故xinference服务启动命令也需改为:
xinference-local --host 172.30.80.1 --port 9998四、环境迁移
对于maxkb,当前版本只挂载了一处路径,已包含安装的py包,只需要将挂载文件进行迁移替换后,删除容器重建即可。
对于xinference,需保证迁移前后conda环境完全一致!对此,笔者尝试了如下办法,通过conda-pack打包迁移后,执行硬编码路径修复,但以失败告终,原因是无法自动修复xinference相关部分硬编码路径问题。
# 打包整个环境(会生成单文件)
conda pack --prefix E:\xinference\xinference_env -o E:\backup_whisper_env.tar.gz
# 创建目标目录
mkdir E:\xinference_envs
# 解压到新位置
cd E:\xinference_envs
tar -xzf E:\backup_whisper_env.tar.gz
# 关键:修复所有硬编码路径
使用 base 环境的 Python 运行(否则会死锁而失败)
C:\Users\Lenovo\Miniconda3\python.exe E:\xinference\xinference_envs\xinference_whisper\Scripts\conda-unpack-script.py
C:\Users\Lenovo\Miniconda3\python.exe E:\xinference\xinference_envs\xinference_whisper\Scripts\conda-unpack-script.py五、总结
通过此方法,当前已完成上述提到的模型,加whisper-tiny、FLUX.1-schnell部署及向离线环境迁移,视觉模型通过ollama即可快速便捷完成。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)