我把攀岩岩点识别模型塞进 iPhone:YOLOv8 一键导出 Core ML(含 NMS)
摘要 本文介绍了将YOLOv8攀岩岩点识别模型部署到iPhone的完整流程。作者采用Core ML方案实现iOS端离线推理,通过一键导出脚本将NMS直接打包进模型,显著简化端上代码。工程重点包括:1) 基于YOLOv8训练岩点检测模型;2) 开发导出脚本支持Core ML格式转换;3) 提供Vision框架集成方案处理图像预处理;4) 强调输入尺寸一致性和NMS内置等部署关键点。该方案具有隐私友好
我把攀岩岩点识别模型塞进 iPhone:YOLOv8 一键导出 Core ML(含 NMS)
前言
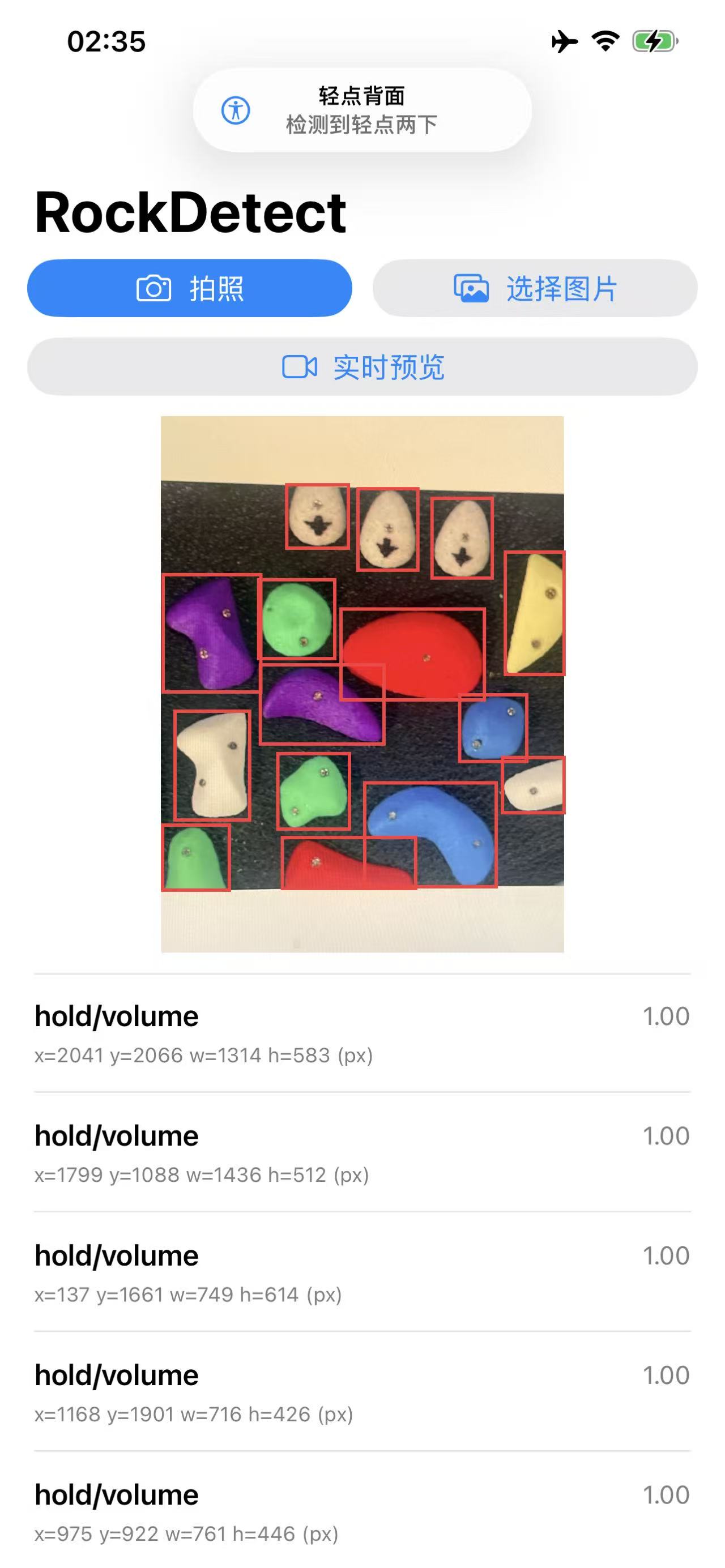
我平时喜欢把“能跑的 demo”变成“能装进手机的功能”。这次做的是 攀岩岩点识别/岩点检测:输入一张岩壁照片,输出岩点(或抓握点/路线点位)的检测框。
重点不搞论文那一套,纯工程:我想要的是 iOS 端离线推理。所以训练出 best.pt 之后,直接一键导出 Core ML(.mlmodel/.mlpackage),丢进 Xcode 就能跑,手机没网也照样识别。
文中出现的 “hold/抓握点” 等称呼,属于岩馆/岩壁场景里的常见目标类型之一;你也可以把类别定义成更泛化的“rock_point/岩点”,流程完全一致。
为什么我坚持用 iOS 的 Core ML(而不是绕一圈)
我把模型往 iOS 上落地时,最看重的是“少写代码、少踩坑、可维护”。Core ML 对我来说有几个很实在的好处:
- 离线/隐私友好:图片不出手机,网络差也能跑(攀岩馆里信号你懂的)
- 延迟更稳:端上推理避免网络波动;体验比“拍照→上传→等返回”舒服太多
- 能耗/系统协同:Core ML 能更好地吃到 iOS 的加速路径(实际体验通常更省电、更顺滑)
- Xcode 原生集成:把
.mlmodel/.mlpackage拖进工程就有 Swift 接口,工程味儿很浓 - 我最爱的点:NMS 可以直接打包进模型:导出时加
--nms,iOS 端少写一大坨后处理逻辑,出 bug 的概率也直线下降
我做了哪些“聪明但不花哨”的工程化
- 面向攀岩岩点识别:输出岩点(或抓握点/路线上点位)的检测框与置信度,可用于标注辅助、路线分析、端上识别等
- 训练/推理一体化:基于
ultralytics的 YOLOv8,训练、推理、导出脚本齐全 - iOS 友好:我写了
scripts/export_coreml.py一键导出 Core ML,并支持 将 NMS 融合进模型(端上代码更干净) - 本地可视化:提供
app/web.py(Streamlit)上传图片即可验证模型效果 - 多种部署格式:除 Core ML 外,也可以导出 ONNX(方便跨平台)
目录结构
RockClimbingRecognition/
app/
web.py # Streamlit 可视化
scripts/
train_yolov8.py # 训练脚本
infer.py # 推理脚本
export_onnx.py # 导出 ONNX
export_coreml.py # 导出 Core ML(iOS)
runs/detect/climbing-hold/weights/ # 训练输出目录(名称可自定义)
best.pt # 训练产物(示例路径)
best.mlpackage/ # Core ML 导出产物(示例)
1. 环境准备
建议 Python 3.10+(macOS 推荐 3.10/3.11)。安装依赖:
python3 -m venv .venv
source .venv/bin/activate
python -m pip install -U pip
python -m pip install -r requirements.txt
如果你要导出 Core ML(iOS 部署用),再安装 iOS 相关依赖:
python -m pip install -r requirements.ios.txt
其中 requirements.ios.txt 里关键是 coremltools。
2. 数据准备
不管数据从哪里来,只要你最终能整理成 YOLO 标准格式,后面一套命令就能跑:
dataset/
images/
train/*.jpg
val/*.jpg
labels/
train/*.txt
val/*.txt
data.yaml
data.yaml 我通常就写得很直白(类别名按你的任务填写,比如 “rock_point/岩点”):
path: /abs/path/to/dataset
train: images/train
val: images/val
names:
0: rock_point
说明:本文不披露具体数据来源与获取方式;你可以替换为任意自建/授权数据或公开数据,只要格式一致,后面的训练与部署流程完全通用。
3. 训练 YOLOv8(先把 best.pt 练出来)
训练脚本使用方式以仓库内 scripts/train_yolov8.py 为准。典型命令如下(参数可按你的机器调整):
python scripts/train_yolov8.py \
--data /abs/path/to/data.yaml \
--model yolov8n.pt \
--imgsz 640 \
--epochs 50 \
--batch 16
训练完成后,默认会在类似路径生成权重:
runs/detect/climbing-hold/weights/best.pt
4. 导出 Core ML
iOS 端我就走 Core ML 原生路线,省心。项目里已经封装了一键导出脚本 scripts/export_coreml.py:
python scripts/export_coreml.py \
--weights runs/detect/climbing-hold/weights/best.pt \
--imgsz 640 \
--nms
参数说明:
--nms:强烈建议开。把 NMS(非极大值抑制)融合进模型,iOS 端不需要自己写 NMS,少写一大段易错代码--half:导出 FP16(更小更快,可能略影响精度)--int8:导出 INT8(更小,但精度/兼容性需要你自己验证)
导出产物一般是 .mlmodel 或 .mlpackage(取决于版本)。本仓库示例里能看到类似:
runs/detect/climbing-hold/weights/best.mlpackage/
5. iOS 端集成
5.1 把模型丢进 Xcode
- 打开 Xcode 工程
- 将导出的
best.mlmodel或best.mlpackage拖入工程(建议勾选 Copy items if needed) - Xcode 会自动编译成
*.mlmodelc,并生成对应的 Swift 接口(在右侧 “Model Class” 可看到)
如果你使用
.mlpackage,同样可以直接拖入 Xcode,Xcode 会完成编译。
5.2 我推荐用 Vision 包一层(少踩图像方向/缩放坑)
实际项目中我更喜欢用 Vision,它能帮你处理图片缩放、方向等细节(尤其是来自相机的图像)。下面给一个通用的 Vision 推理模板(你只需要把 best 换成 Xcode 自动生成的模型类名)。
Swift(Vision)示例
import UIKit
import Vision
import CoreML
final class RockPointDetector {
private lazy var vnModel: VNCoreMLModel = {
// Xcode 自动生成的模型类名:通常等于文件名,例如 best()
let coreMLModel = try! best(configuration: MLModelConfiguration()).model
return try! VNCoreMLModel(for: coreMLModel)
}()
func detect(on image: UIImage, completion: @escaping ([VNRecognizedObjectObservation]) -> Void) {
let request = VNCoreMLRequest(model: vnModel) { req, _ in
let results = (req.results as? [VNRecognizedObjectObservation]) ?? []
completion(results)
}
request.imageCropAndScaleOption = .scaleFill // 对齐 imgsz=640 的训练/导出设置
guard let cgImage = image.cgImage else {
completion([])
return
}
let handler = VNImageRequestHandler(cgImage: cgImage, orientation: .up, options: [:])
try? handler.perform([request])
}
}
拿到 VNRecognizedObjectObservation 后,你就可以根据 confidence 与 boundingBox(归一化坐标)绘制“岩点检测框”了:
boundingBox是相对于图像的归一化矩形(0~1)- iOS 坐标系与图像坐标系需要转换(尤其是预览层/缩放显示时)
5.3 关键注意事项(iOS 部署最常踩坑的点)
- 输入尺寸一致:导出时
--imgsz 640,iOS 推理时确保预处理逻辑与训练一致(Vision 的imageCropAndScaleOption会影响缩放策略) - NMS 是否内置:如果导出时开启
--nms,iOS 端一般直接拿到“已做过 NMS 的候选框”;如果没开,需要你自己写 NMS(更麻烦) - 阈值策略:在端上通常需要一个
confidence阈值(比如 0.25~0.5)来过滤低置信度框 - 性能建议:
- 优先考虑 FP16(
--half)降低模型体积与延迟 - 尽量避免在主线程做推理(相机实时检测请用后台队列)
- 优先考虑 FP16(
6. 我自己怎么验:先用 Web 快速看效果
为了在导出前快速验证模型效果,项目提供了一个最简 Web 页面 app/web.py。启动方式:
python -m streamlit run app/web.py
上传图片即可看到检测结果,方便你在“训练 → 导出 → iOS 集成”前先把模型质量确认好。
7. 收个尾
这套流程我追求的就是:训练一次 → 导出 Core ML → iOS 离线跑起来。下一步很自然:把输入从 UIImage 换成 CMSampleBuffer(AVFoundation),接上相机实时画框;模型不变,工程往前推进就行。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)