Faiss工程化落地实战
本文介绍了Faiss组队学习的工程化落地实践,重点讲解了文本语义检索和图像相似检索两大实战任务。学习者需具备Python、数据处理和深度学习基础,通过Transformer生成文本嵌入或用CNN提取图像特征,结合Faiss构建检索系统,并利用FastAPI搭建服务接口。文章详细说明了实施流程,包括数据准备、特征提取、检索库构建等步骤,并强调了工程部署中的三大核心问题:索引更新、性能监控和容错处理,
本次是FaIss组队学习的task5同时也是最后一篇。本次的学习内容主要是Faiss工程化落地实践。(省略部分代码)
前提要求是需要我们学习者具备Python基础使用能力以及数据处理能力,并了解Transformer与CNN的基本原理还要熟悉umPy等基础数据科学库。本次的学习目标是让学习者掌握高维向量检索的完整流程,具备独立开发与部署向量检索系统的能力。
文本语义检索实战:核心是将非结构化文本转化为向量结构化向量后、通过相似性搜索实现“语义匹配”而非传统关键词匹配。环境准备需要是Python3.8-3.10版本。
# 虚拟环境创建(conda示例)
conda create -n faiss-env python=3.10 -y
conda activate faiss-env
# 核心依赖安装
pip install faiss-cpu # CPU版本,GPU版本需安装faiss-gpu
pip install sentence-transformers # 文本嵌入模型库
pip install fastapi uvicorn # API开发框架
pip install numpy pydantic # 数据处理与校验
pip install modelscope #魔塔社区库后续需要Transformer生成文本嵌入,此处可以使用魔搭社区。https://www.modelscope.cn/my/overview。文本嵌入(Embedding)是将文本转化为高维向量的过程。后续嵌入向量接入Faiss构建检索库,Faiss通过“索引”结构实现高维向量检索。通过FastApi搭建向量检索接口。一个实战任务是课程问答检索系统。实施步骤:数据准备、向量生成、检索库构建、接口优化、系统测试。实操检索接口开发代码:
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from typing import List, Dict
import faiss
import json
import numpy as np
import re # 用于句子切分的正则表达式
from sentence_transformers import SentenceTransformer
from pathlib import Path
import uvicorn
# ===================== 1. 配置路径与参数 =====================
app = FastAPI(title="文本语义检索API", version="1.0")
# 路径配置
txt_corpus_path = Path("./text_corpus.txt") # 待处理的TXT文本文件路径
data_dir = Path("./text_search_db") # 索引和元数据保存目录
index_path = data_dir / "faiss_index.index" # FAISS索引路径
metadata_path = data_dir / "metadata.json" # 元数据路径
# 模型与检索配置(换回指定的gte中文模型)
model_path = "./model/iic/nlp_gte_sentence-embedding_chinese-base" # 自定义模型路径
prefix = "" # gte中文模型无需前缀,可根据需求自定义
# 中文句子分隔符(正则表达式:匹配。!?;中的任意一个,后面可能跟换行/空格)
sentence_sep_pattern = re.compile(r'[。!?;]+')
# ===================== 2. 定义数据模型(请求/响应) =====================
class SearchRequest(BaseModel):
query: str
top_k: int = 3 # 默认返回3条结果
class SearchResult(BaseModel):
rank: int
similarity: float
text: str
metadata: Dict[str, str]
class SearchResponse(BaseModel):
query: str
results: List[SearchResult]
# ===================== 3. 工具函数 =====================
def read_and_split_sentences(txt_path: Path) -> List[str]:
"""
读取TXT文件并按中文句子切分,返回非空句子列表
"""
# 检查文件是否存在
if not txt_path.exists():
# 生成示例文本(首次运行时自动创建)
sample_text = """FAISS是由Facebook AI研究院开发的高效向量相似性检索库。它专为大规模高维向量的近邻搜索场景设计,支持CPU和GPU加速。
FAISS的核心特点包括支持多种索引类型,比如精确索引IndexFlatIP、IndexFlatL2,以及近似索引IVF、HNSW等。它能处理亿级别的向量数据,还提供了距离计算、向量归一化等工具。
FAISS的架构主要包含向量存储模块、距离计算模块和索引优化模块。它广泛应用于推荐系统、语义检索、计算机视觉中的特征匹配等场景。"""
with open(txt_path, "w", encoding="utf-8") as f:
f.write(sample_text)
print(f"未找到{txt_path},已自动生成示例文本!")
text_content = sample_text
else:
# 读取TXT文件内容
with open(txt_path, "r", encoding="utf-8") as f:
text_content = f.read()
# 按句子分隔符切分文本
sentences = sentence_sep_pattern.split(text_content)
# 过滤空句子和仅含空白字符的句子
sentences = [sent.strip() for sent in sentences if sent.strip()]
if not sentences:
raise ValueError("TXT文件中无有效句子可切分!")
return sentences
def build_faiss_index():
"""
构建FAISS索引:读取TXT→切分句子→生成嵌入→创建并保存索引/元数据
"""
# 1. 读取并切分句子
sentences = read_and_split_sentences(txt_corpus_path)
# 2. 加载指定的gte中文模型(本地路径,若不存在会自动从HuggingFace下载)
model = SentenceTransformer(model_path)
# 3. 生成句子嵌入(归一化,适配内积索引)
print("正在生成句子嵌入向量...")
embeddings = model.encode(
[prefix + sent for sent in sentences],
normalize_embeddings=True,
convert_to_numpy=True
).astype(np.float32) # FAISS要求float32类型
# 4. 构建元数据(包含句子ID、来源、文本内容)
metadata = []
for idx, sent in enumerate(sentences):
metadata.append({
"text": sent,
"metadata": {
"sentence_id": str(idx + 1),
"source": str(txt_corpus_path),
"total_sentences": str(len(sentences))
}
})
# 5. 创建FAISS索引(内积索引,归一化后等价于余弦相似度)
d = embeddings.shape[1] # 向量维度
index = faiss.IndexFlatIP(d)
index.add(embeddings)
# 6. 保存索引和元数据
data_dir.mkdir(parents=True, exist_ok=True)
faiss.write_index(index, str(index_path))
with open(metadata_path, "w", encoding="utf-8") as f:
json.dump(metadata, f, ensure_ascii=False, indent=2)
print(f"FAISS索引构建完成,共添加{index.ntotal}个句子向量")
return index, model, metadata
# ===================== 4. 初始化资源(启动时仅加载一次) =====================
print("正在初始化资源...")
try:
# 尝试加载已存在的索引和元数据
if index_path.exists() and metadata_path.exists():
model = SentenceTransformer(model_path) # 加载指定模型
index = faiss.read_index(str(index_path))
with open(metadata_path, "r", encoding="utf-8") as f:
metadata = json.load(f)
print(f"成功加载已有索引,包含{index.ntotal}个句子向量")
else:
# 索引不存在时,重新构建
index, model, metadata = build_faiss_index()
except Exception as e:
raise RuntimeError(f"资源初始化失败:{str(e)}")
# ===================== 5. 接口定义 =====================
@app.post("/text-search", response_model=SearchResponse, summary="文本语义检索")
def text_search(request: SearchRequest):
try:
# 生成查询向量(与句子嵌入使用相同的前缀和归一化)
query_embedding = model.encode(
prefix + request.query,
normalize_embeddings=True
).astype(np.float32).reshape(1, -1)
# 执行检索(IndexFlatIP:内积值越大,相似度越高)
distances, indices = index.search(query_embedding, request.top_k)
results = []
for i in range(request.top_k):
idx = indices[0][i]
if idx == -1: # 无匹配结果时的处理
continue
# 内积索引的相似度直接使用距离值(归一化后为余弦相似度,范围[-1,1])
similarity = round(distances[0][i], 4)
results.append(SearchResult(
rank=i+1,
similarity=similarity,
text=metadata[idx]["text"],
metadata=metadata[idx]["metadata"]
))
return SearchResponse(query=request.query, results=results)
except Exception as e:
raise HTTPException(status_code=500, detail=f"检索失败:{str(e)}")
@app.get("/health", summary="服务健康检查")
def health_check():
return {
"status": "healthy",
"index_vector_count": index.ntotal,
"corpus_source": str(txt_corpus_path),
"total_sentences": len(metadata),
"model_path": model_path
}
if __name__ == "__main__":
# 配置启动参数(可根据需求调整)
uvicorn.run(
app="main:app", # 格式:文件名:FastAPI实例名(若你的文件不是main.py,替换为实际文件名,如api:app)
host="0.0.0.0", # 允许局域网/公网访问
port=8000, # 服务端口
reload=True # 开发环境热重载(生产环境关闭)
)运行结果:
查询文本:FAISS的架构包含哪些模块?
排名:1
相似度:0.8575000166893005
文本:FAISS的架构主要包含向量存储模块、距离计算模块和索引优化模块
元数据:{'sentence_id': '5', 'source': 'text_corpus.txt', 'total_sentences': '6'}
排名:2
相似度:0.7817999720573425
文本:FAISS是由Facebook AI研究院开发的高效向量相似性检索库
元数据:{'sentence_id': '1', 'source': 'text_corpus.txt', 'total_sentences': '6'}
排名:3
相似度:0.7763000130653381
文本:FAISS的核心特点包括支持多种索引类型,比如精确索引IndexFlatIP、IndexFlatL2,以及近似索引IVF、HNSW等
元数据:{'sentence_id': '3', 'source': 'text_corpus.txt', 'total_sentences': '6'}实战主要以Faiss+FastApi为核心技术栈。完成了文本检索服务从本地实现到线上部署的全流程,从而进一步掌握对语义检索工程化落地的思路。
另一个为图像相似检索实战。环境准备需要深度学习框架torchvision与图像处理库opencv-python。
pip install torch torchvision # 深度学习框架
pip install pillow opencv-python # 图像处理库使用CNN(ResNet)提取图像特征,特征向量接入Faiss实现检索。另一个实战任务:论坛图片相似检索系统。实施步骤:数据准备、特征提取、检索库构建、交互功能开发、系统优化。
目前工程化部署需要注意:需解决索引更新、性能监控、容错处理三大核心问题,确保系统稳定高效运行。索引增量更新方面:小规模增量可以直接添加向量,大规模增量进行索引合并,接口性能监控(QPS/延迟)需要注意:需重点关注查询吞吐量(QPS)、响应延迟、服务器资源占用三大指标。指标采集通过prometheus-fastapi-instrumentator库采集API性能指标,结合Prometheus和Grafana实现可视化监控。监控指标关注项见图: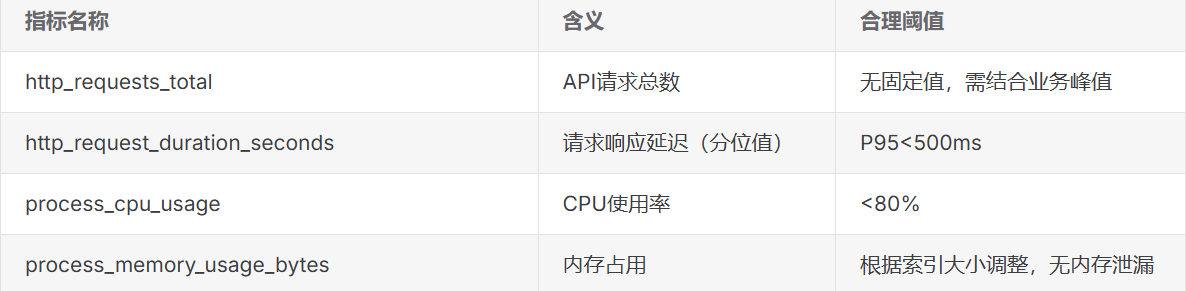
性能优化方向为:索引优化、缓存机制、分布式部署与模型优化。容错处理(索引损坏/向量缺失)方面:生产环境中需应对索引文件损坏、向量与元数据不匹配、服务异常中断等问题,确保系统容错能力。为应对索引损坏可以:定期备份和采用校验机制。向量缺失或元素不一致时可以采用数据检验或异常捕获。在服务高可用方面:可以采用进程守护以及日志记录和采用降级策略。
目前是本次Faiss项目工程化落地实战总结。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)