Kafka核心知识一文说清
> 学习后端技术想必会经常使用Kafka做消息推送或者业务异步隔离,今天给大家一文说清Kafka全部知识要点
## 目录
1. [Kafka的工作流程是怎么样的?](#一kafka的工作流程是怎么样的)
2. [怎么防止Kafka丢数据?](#二怎么防止kafka-丢数据)
3. [生产者会不会弄丢数据?如何保障消息只生产消费一次?](#三生产者会不会弄丢数据如何保障消息只生产消费一次)
4. [消息队列的使用场景有哪些?](#四消息队列的使用场景有哪些)
5. [什么是零拷贝技术?](#五什么是零拷贝技术)
6. [Kafka刷盘时机是怎么样的?](#六kafka刷盘时机是怎么样的)
7. [Kafka什么时候进行rebalance?](#七kafka什么时候进行rebalance)
8. [Kafka的选举机制](#八kafka的选举机制)
---
## 一、Kafka的工作流程是怎么样的?
### 整体架构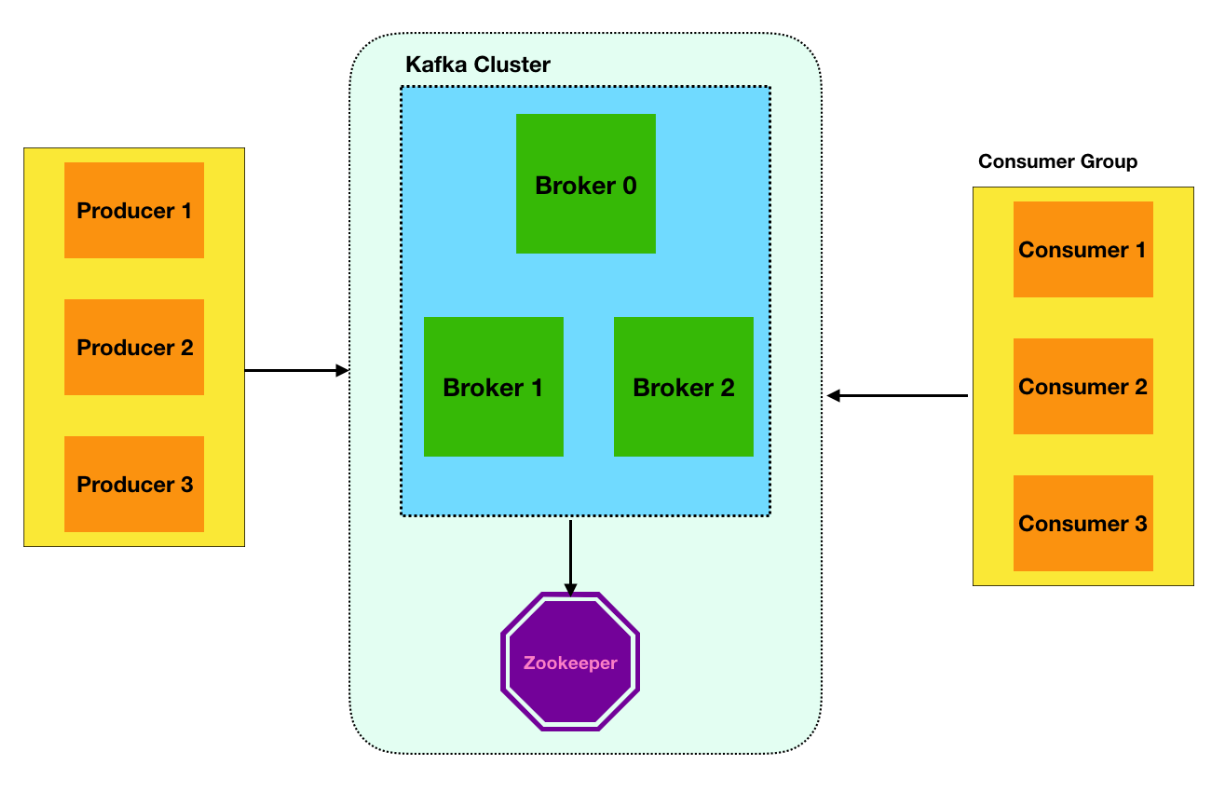
Kafka集群由多个broker(服务器)组成,每一类消息称为一个topic(主题)。生产者将消息发送给broker,消费者从broker拉取消息。
### 消息分发机制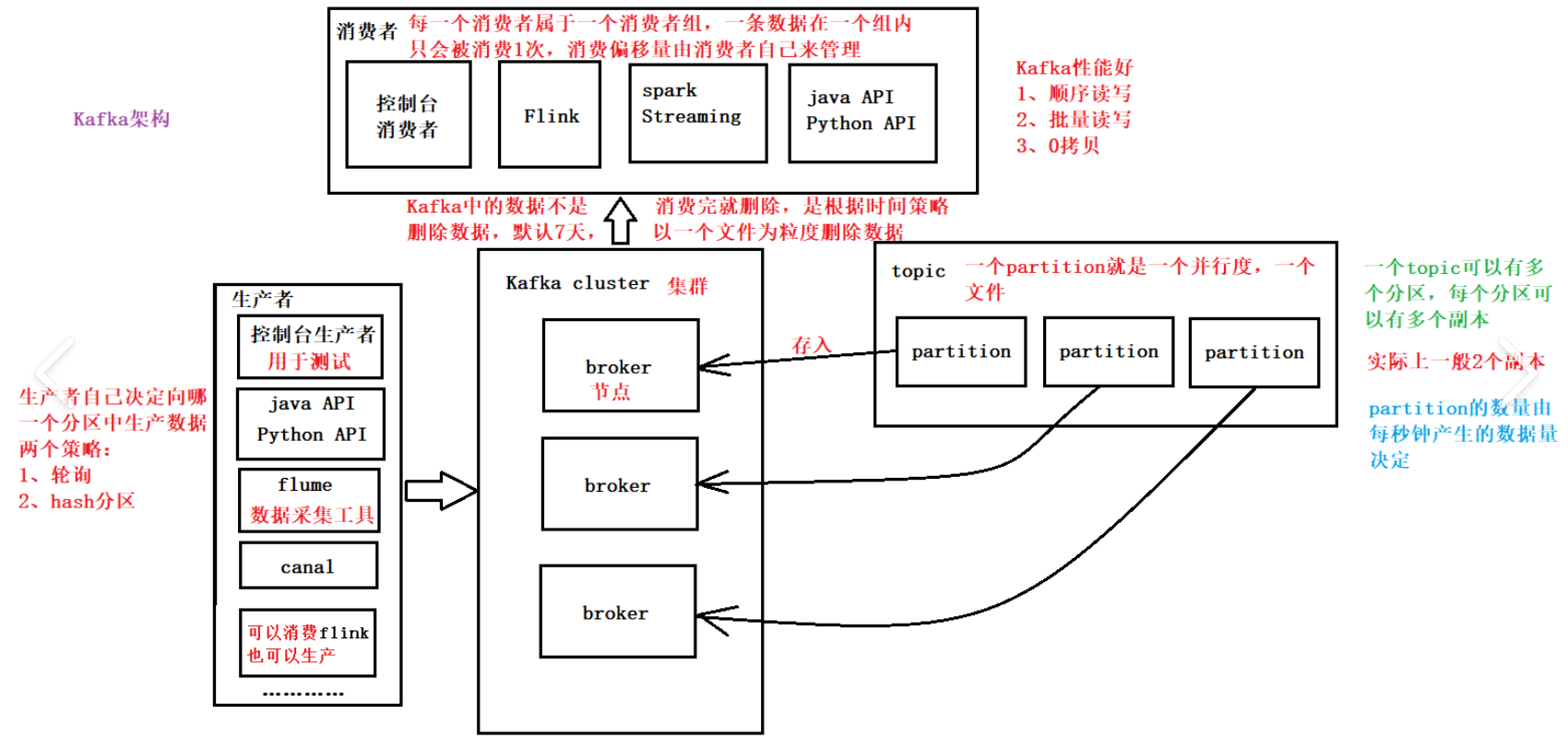
当生产者发送消息时,broker会根据规则将消息分配到topic下的某个分区: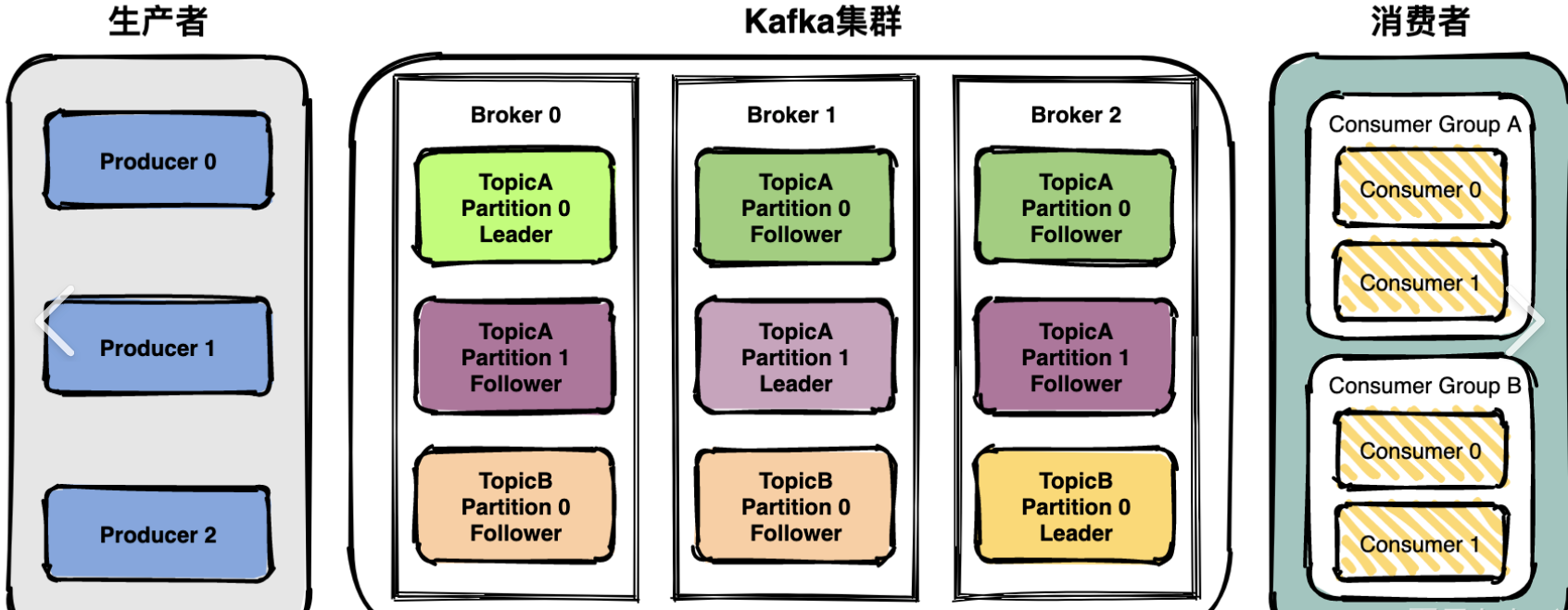
| 分发规则 | 说明 |
|---------|------|
| **指定分区** | 直接发送到指定分区 |
| **指定key** | 根据murmur2哈希算法计算哈希值,与分区数取余得到分区 |
| **无指定** | 根据自增计数与分区数取余,实现均匀分发 |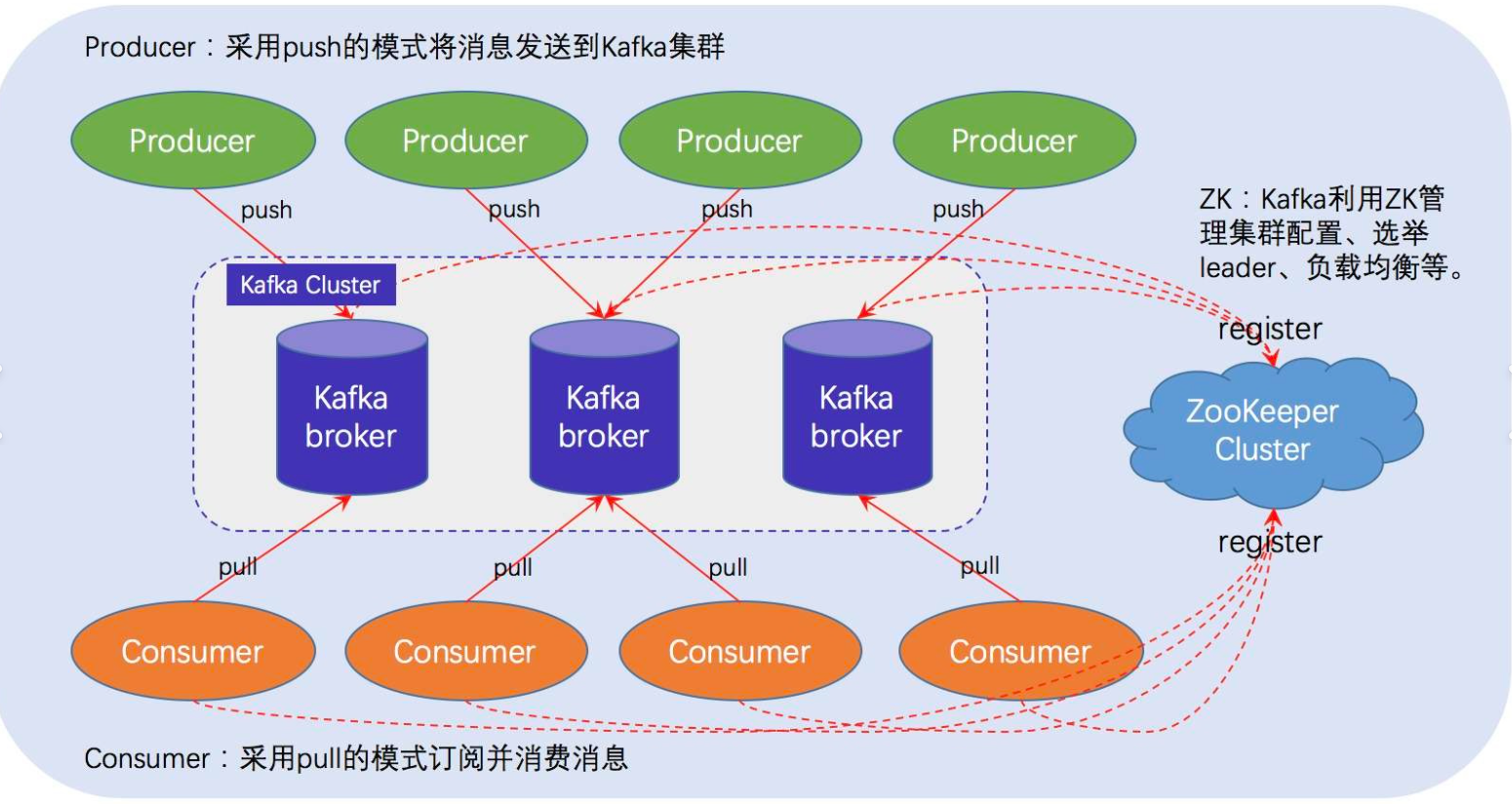
### 分区存储结构
每个分区对应一个目录,内部由多个大小相等的segment(段)文件组成: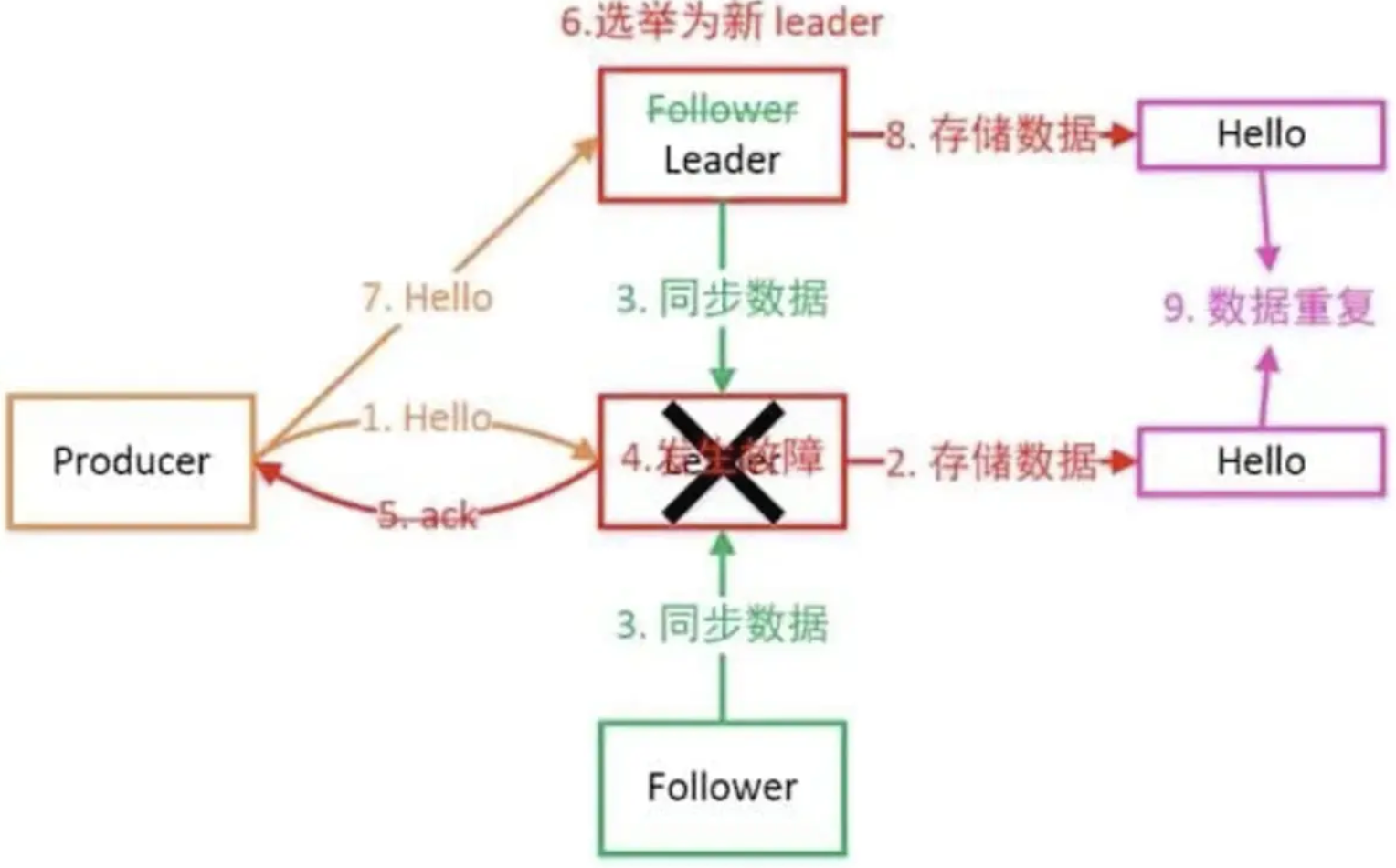
- **.index文件**:记录消息的offset及其在log文件中的偏移量
- **.log文件**:实际存储消息数据(包含offset、消息体大小、消息内容)
**查询过程**:根据offset先查index文件找到偏移量,再到log文件中读取具体数据。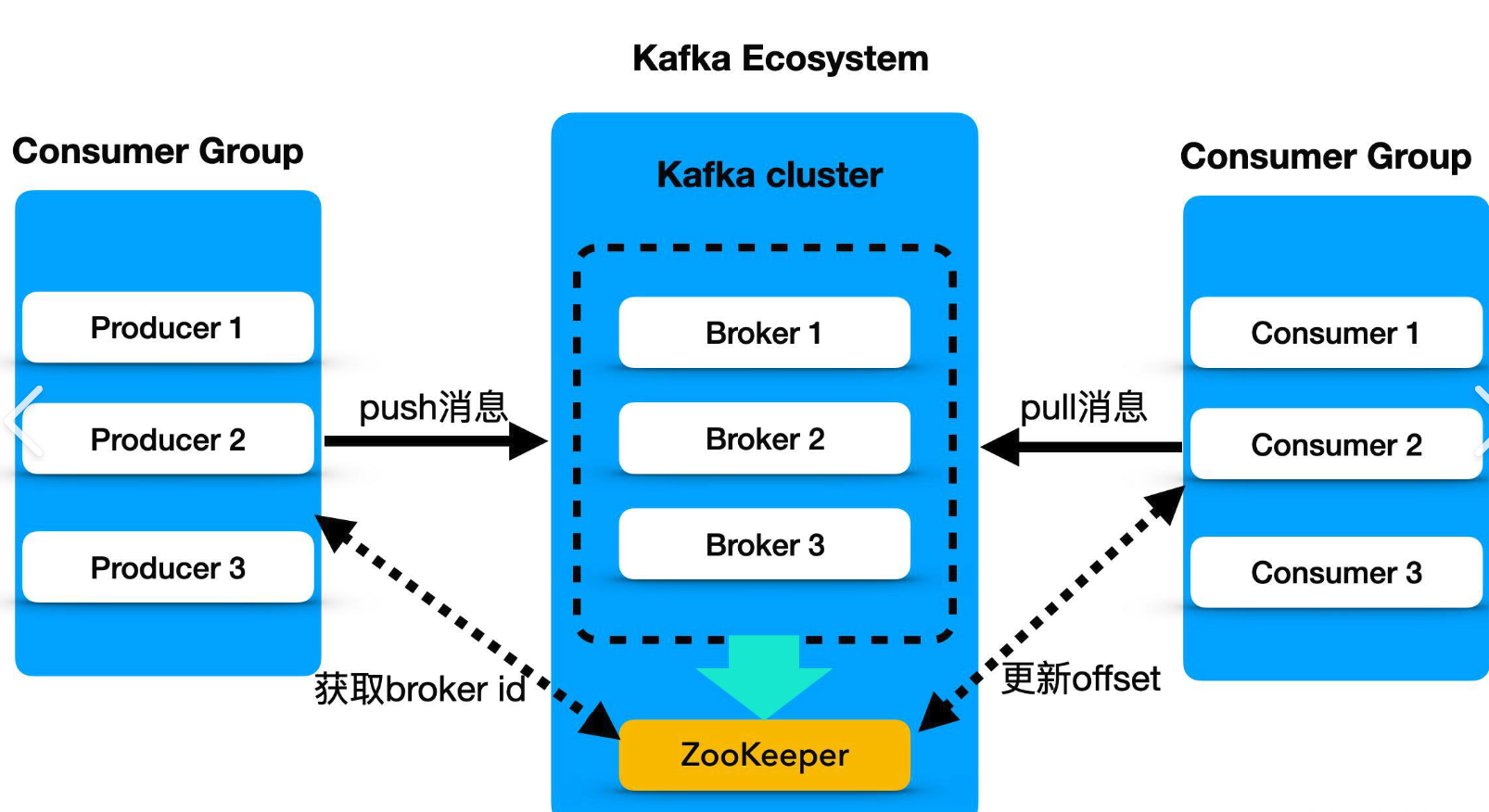
### segment切分触发条件
- log文件大小 > `log.segment.bytes`(默认1G)
- segment中最早消息距离当前时间 > `log.roll.ms`(默认7天)
- 索引文件大小 > `log.index.size.max.bytes`(默认10M)
### 数据同步机制
分区leader将消息存储到日志后,会同步给所有follower。当follower同步完成并返回ack,leader才认为写入成功,并给生产者返回成功响应。
### 消费者消费
消费者从分区leader读取数据,一个消费者可消费多个分区,但一个分区只能被一个消费者消费。建议关闭自动提交,在消费成功后手动提交offset。
### 重要配置说明
| 配置项 | 说明 |
|--------|------|
| `replication.factor >= 2` | 每个分区至少2个副本 |
| `min.insync.replicas` | 默认1,ISR集合中最小副本数(配合acks=all使用) |
| `acks` | 生产者写入确认机制 |
| `retries` | 写入失败重试次数 |
### 生产者ACK配置详解
| ACK值 | 含义 | 可靠性 | 性能 |
|-------|------|--------|------|
| **0** | 发送出去不管,不等待确认 | 最低 | 最高 |
| **1(默认)** | leader接收成功即算成功 | 中等 | 中等 |
| **-1(all)** | ISR所有follower确认才算成功 | 最高 | 最低 |
---
## 二、怎么防止Kafka丢数据?
### 常见丢数据场景
Kafka某个broker宕机,重新选举partition的leader时,如果follower还没来得及同步数据,就会造成数据丢失。
### 解决方案(4个关键参数)
1. **`replication.factor >= 2`**:每个partition至少2个副本
2. **`min.insync.replicas > 1`**:leader至少感知到一个follower保持联系
3. **`acks=all`**:要求所有副本都写入才算成功
4. **`retries=MAX`**(无限重试):写入失败就无限重试
配置这些参数后,即使leader所在broker故障,进行leader切换时也能保证数据不丢失。
---
## 三、生产者会不会弄丢数据?如何保障消息只生产消费一次?
### 生产者会不会丢数据?
按照上述配置设置`acks=all`,并配合无限重试,生产者不会丢数据。
### 如何实现Exactly-Once(精确一次处理)?
#### 1. 生产端幂等性发送
Kafka引入**PID(Producer ID)**和**Sequence Number**:
- 每个Producer初始化时被分配唯一PID
- 每个`<PID, Topic, Partition>`对应一个从0开始单调递增的Sequence Number
- Broker为每个`<PID, Topic, Partition>`维护序号,接受序号恰好大1的消息,否则丢弃
**解决的两个问题**:
- Broker保存消息后、发送ACK前宕机,导致Producer重试造成数据重复
- 消息乱序问题
#### 2. 消费端幂等性
业务层面保证重复消费的幂等性,例如引入版本号机制。
#### 3. 事务性保证
引入**Transaction ID**,保证跨多个`<Topic, Partition>`的写操作原子性:
- 应用程序提供稳定唯一的Transaction ID
- 新的Producer启动后,旧的具有相同Transaction ID的Producer失效
- 保证跨Session的数据幂等发送和事务恢复
---
## 四、消息队列的使用场景有哪些?
### 主要使用场景
| 场景 | 说明 |
|------|------|
| **异步通信** | 不想立即处理的消息放入队列,需要时再处理 |
| **解耦** | 降低工程间强依赖,异构系统适配 |
| **冗余** | 消息持久化直到被完全处理,避免数据丢失 |
| **扩展性** | 增加处理过程即可扩容,无需修改代码 |
| **过载保护** | 关键组件顶住突发访问压力,不会完全崩溃 |
| **可恢复性** | 部分组件失效不影响整体系统 |
| **顺序保证** | 消息队列天然排序,保证处理顺序 |
| **缓冲** | 控制和优化数据流经系统的速度 |
| **数据流处理** | 收集业务日志、监控数据、用户行为等海量数据 |
### 消息队列的缺点
| 缺点 | 说明 |
|------|------|
| **系统可用性降低** | 引入外部依赖,MQ挂掉整套系统可能崩溃 |
| **系统复杂度提高** | 需处理重复消费、消息丢失、顺序保证等问题 |
| **一致性问题** | 多个系统写库,部分成功部分失败导致数据不一致 |
---
## 五、什么是零拷贝技术?
### 传统I/O的缺点
#### read()系统调用过程
1. 用户态→内核态切换(一次上下文切换)
2. DMA技术将磁盘文件拷贝到内核缓冲区(一次DMA拷贝)
3. CPU将数据从内核缓冲区拷贝到用户缓冲区(一次CPU拷贝)
4. 内核态→用户态切换(一次上下文切换)
#### write()系统调用过程
1. 用户态→内核态切换(一次上下文切换)
2. CPU将数据从用户缓冲区拷贝到内核Socket缓冲区(一次CPU拷贝)
3. DMA技术将数据从Socket缓冲区拷贝到网卡(一次DMA拷贝)
4. 内核态→用户态切换(一次上下文切换)
**总计**:4次上下文切换 + 2次CPU拷贝 + 2次DMA拷贝
### MMAP + write
- 将内核内存空间映射到用户进程空间,用户进程可直接访问
- **节省**:减少1次CPU拷贝
- **仍需**:4次上下文切换 + 1次CPU拷贝 + 2次DMA拷贝
### sendfile(零拷贝)
Kafka发送消息给消费者时使用
**Linux 2.4+版本流程**:
1. 用户态→内核态切换
2. DMA将文件从磁盘拷贝到内核缓冲区(DMA拷贝)
3. 将数据在内核缓冲区的位置和偏移量写入Socket缓存(无数据拷贝)
4. DMA直接从Socket缓存读取位置信息,将数据拷贝到网卡(DMA拷贝)
5. 内核态→用户态切换
**总计**:2次上下文切换 + 0次CPU拷贝 + 2次DMA拷贝
### 三种方案对比
| 方案 | 上下文切换 | CPU拷贝 | DMA拷贝 | 能否修改数据 |
|------|-----------|---------|---------|-------------|
| read + write | 4次 | 2次 | 2次 | 能 |
| mmap + write | 4次 | 1次 | 2次 | 能 |
| sendfile | 2次 | 0次 | 2次 | 不能 |
---
## 六、Kafka刷盘时机是怎么样的?
### 刷盘相关参数
| 参数 | 说明 |
|------|------|
| `log.flush.interval.messages` | 最大刷盘消息数量 |
| `log.flush.interval.interval.ms` | 最大刷盘时间间隔 |
| `log.flush.scheduler.interval.ms` | 定期刷盘间隔 |
### Kafka的设计理念
**Kafka不推荐设置这些参数**,而是让操作系统来决定刷盘时机,这样可以支持更高的吞吐量。
### 为什么可以这样做?
Kafka的可用性是通过多副本来保证的:
- 如果一个机器挂掉,会选举副本作为新的leader
- 数据持久化依赖副本机制,而非单机刷盘
---
## 七、Kafka什么时候进行rebalance?
### 触发Rebalance的条件
1. **topic分区数量变化**(增加或减少,通常是手动触发)
2. **消费者数量变化**(新增消费者或消费者挂掉)
### 消费者掉线的判定
| 参数 | 说明 |
|------|------|
| `session.timeout.ms` | 最大会话超时时间,默认10s。超过未收到心跳,认为掉线 |
| `max.poll.interval.ms` | 两次拉取消息的最大间隔,默认5分钟。超过则认为掉线 |
### Rebalance导致的问题
消费者A拉取100条消息,消费时间超过5分钟,被broker认定下线→触发rebalance→分区分配给其他消费者→其他消费者重复消费
### 解决方案
| 方案 | 说明 |
|------|------|
| **减少每批消息处理时间** | 修改`max.poll.records`,减小每次拉取数量 |
| **自行存储offset** | 在MySQL或Redis中存储每个分区消费的offset |
| **消息去重** | 为消息分配唯一ID,判定是否重复消费 |
### Kafka版本优化
| 版本 | 优化内容 |
|------|---------|
| **1.1** | 新增`group.initial.rebalance.delay.ms`参数,避免服务启动时消费者陆续加入引起的频繁Rebalance |
| **2.3** | 引入静态成员ID,消费者重启后可保持旧标识,避免Rebalance;即使发生Rebalance,尽量保持原有partition分配 |
---
## 八、Kafka的选举机制
### 控制器(Controller)选举
Kafka集群中多个broker,通过ZooKeeper选举出一个**Controller**:
1. 每个broker启动时尝试在ZooKeeper中创建`/controller`节点
2. 创建成功的broker成为Controller
3. Controller负责管理所有分区的leader选举、分区分配等
### 分区leader选举
当分区leader宕机时,Controller从该分区的ISR集合中选举新的leader:
- **优先选择ISR中的副本**
- 如果ISR为空,但`unclean.leader.election.enable=true`,则允许从非ISR副本中选举(可能丢失数据)
- 如果ISR为空且不允许非ISR选举,则分区不可用
### ISR(In-Sync Replicas)机制
ISR是Kafka为每个分区维护的同步副本集合:
- 只有处于ISR中的副本才有资格被选举为leader
- follower从leader同步数据的延迟超过`replica.lag.time.max.ms`,会被移出ISR
- 追赶上的follower可以重新加入ISR
- 一条消息只有被ISR中所有副本接收,才被视为"已同步"
### 与ZooKeeper的区别
- **ZooKeeper**:半数以上节点写入即成功
- **Kafka ISR**:需要ISR中所有副本都接收到才算成功
---
**本文总结**:Kafka作为业界主流的消息队列,通过分区多副本、ISR同步机制、零拷贝技术等设计,实现了高吞吐、高可靠、可持久化的消息传递。掌握Kafka的核心原理,对于后端架构设计、性能优化和问题排查都至关重要。希望本文能帮助大家全面理解Kafka的工作机制!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)