自用音视频转文字工具分享
忍不了这种麻烦,就去查了查相关方案,发现 OpenAI 有款开源的语音识别模型特别合适!于是干脆自己用 Python 对接了这个模型,还顺手做了个 GUI 界面,不用敲代码就能直接用,新手也能快速上手~经常需要把音视频转成文字,试过不少市面上的工具,要么操作繁琐步骤多,要么动辄就要收费,用着特别不方便。链接:https://pan.quark.cn/s/de824834b118。第一次使用先下载模
·
经常需要把音视频转成文字,试过不少市面上的工具,要么操作繁琐步骤多,要么动辄就要收费,用着特别不方便。
忍不了这种麻烦,就去查了查相关方案,发现 OpenAI 有款开源的语音识别模型特别合适!于是干脆自己用 Python 对接了这个模型,还顺手做了个 GUI 界面,不用敲代码就能直接用,新手也能快速上手~
软件里内置了 5 个可选模型,大家可以根据自己的需求选:
- tiny:体积最小,运行速度最快,识别精度相对一般,适合追求效率、对精度要求不高的场景(比如快速转写会议录音要点);
- base:速度和精度的平衡款,日常使用最常用,大部分场景下都能满足需求;
- small:精度比 base 更高,运行速度会稍慢一点,追求更好识别效果又不想等太久的话选它准没错;
- medium:识别精度进一步提升,但对设备计算资源要求更高;
- large:精度最高,但硬件门槛也最高,运行速度也偏慢。
这里重点推荐大家选「small 模型」!识别精度足够高,日常转写视频台词、音频笔记都够用~ 至于 medium 和 large 模型,因为它们需要显卡支持,还要额外装显卡驱动,操作麻烦不说,打包后的安装包也会变大,所以我只保留了 CPU 版本,不用折腾显卡,普通电脑就能流畅运行。
第一次使用先下载模型!!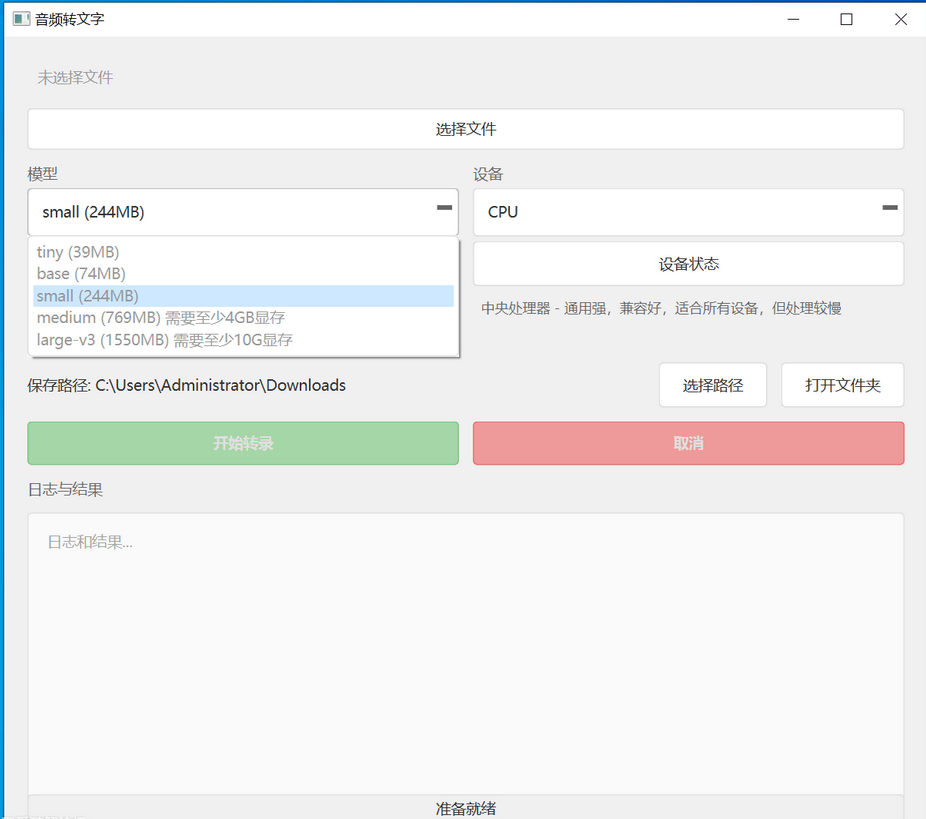
分享了「音视频转文字」
链接:https://pan.quark.cn/s/de824834b118

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)