移动机器人路径规划这事儿吧,光靠传统算法是真费劲。今天咱们聊聊怎么用Q-learning让机器人自己学会找路,MATLAB代码实操走起
这里有几个有意思的点:1)给障碍物设置-10的惩罚比目标奖励还狠,毕竟撞墙比走远路严重;完整代码跑下来,机器人从刚开始的横冲直撞到后来丝滑避障,这学习过程跟教小孩走路似的。强化学习的魅力就在这儿——不需要精确建模,让机器自己在试错中成长。机器人路径优化:基于强化学习Q-learning算法的移动机器人路径优化MATLAB。机器人路径优化:基于强化学习Q-learning算法的移动机器人路径优化MA
机器人路径优化:基于强化学习Q-learning算法的移动机器人路径优化MATLAB
先整一个5x5的网格环境,障碍物直接用矩阵标记。看这段初始化代码:
grid_size = [5,5];
start = [1,1];
goal = [5,5];
obstacles = [2,2;3,3;4,4];
q_table = zeros(prod(grid_size),4); % 上下左右四个动作这里有个骚操作——把二维坐标转成一维状态,直接用sub2ind函数搞定。状态编码是Q-learning的关键,相当于给每个位置办身份证。
重点来了,Q值更新规则:
alpha = 0.1; % 学习率
gamma = 0.9; % 折扣因子
epsilon = 0.2; % 探索概率
for episode = 1:1000
state = start;
while ~isequal(state,goal)
current_state = sub2ind(grid_size,state(1),state(2));
% ε-greedy策略
if rand() < epsilon
action = randi(4);
else
[~,action] = max(q_table(current_state,:));
end
% 执行动作
new_state = move_robot(state,action);
% 计算奖励
if ismember(new_state,obstacles,'rows')
reward = -10;
elseif isequal(new_state,goal)
reward = 100;
else
reward = -1;
end
% Q值更新
next_state_idx = sub2ind(grid_size,new_state(1),new_state(2));
q_table(current_state,action) = q_table(current_state,action) + ...
alpha*(reward + gamma*max(q_table(next_state_idx,:)) - q_table(current_state,action));
state = new_state;
end
end这里有几个有意思的点:1)给障碍物设置-10的惩罚比目标奖励还狠,毕竟撞墙比走远路严重;2)每步-1的奖励迫使机器人找最短路径;3)ε-greedy里那个rand()用得妙,既保证探索又不失效率。
机器人路径优化:基于强化学习Q-learning算法的移动机器人路径优化MATLAB
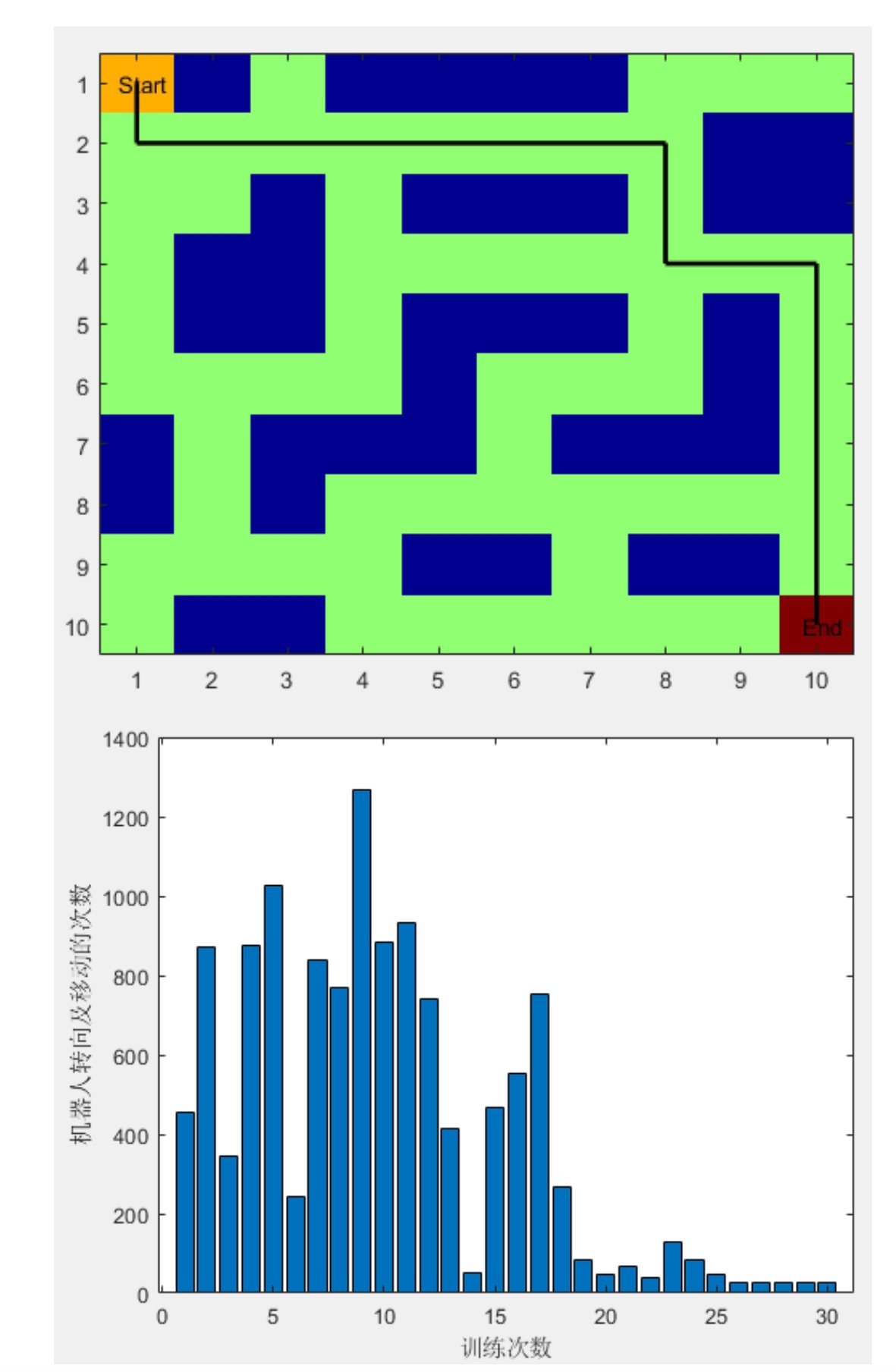
路径可视化可以玩点花的:
[xx,yy] = meshgrid(1:5);
scatter(xx(:),yy(:),100,'k','filled');
hold on
scatter(goal(1),goal(2),200,'r','pentagram')
patch(obstacles(:,1),obstacles(:,2),'r','EdgeColor','none')用色块标注障碍物,五角星表示终点,训练完的路径用折线连起来,效果直接拉满。
调试时发现个坑:当折扣因子gamma超过0.95时,机器人容易在起点附近转圈。后来发现是远期回报权重太高,导致眼前的小奖励失去吸引力。调参这事儿,真是差之毫厘谬以千里。
完整代码跑下来,机器人从刚开始的横冲直撞到后来丝滑避障,这学习过程跟教小孩走路似的。强化学习的魅力就在这儿——不需要精确建模,让机器自己在试错中成长。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)