《ElasticSearch》10 聚合:聚合查询之Pipline聚合详解
如何理解pipeline聚合
如何理解管道聚合呢?最重要的是要站在设计者角度看这个功能的要实现的目的:让上一步的聚合结果成为下一个聚合的输入,这就是管道。
管道机制的常见场景
责任链模式
管道机制在设计模式上属于责任链模式,如果你不理解,请参看如下文章:
责任链模式: 通过责任链模式, 你可以为某个请求创建一个对象链. 每个对象依序检查此请求并对其进行处理或者将它传给链中的下一个对象。
FilterChain
在软件开发的常接触的责任链模式是FilterChain,它体现在很多软件设计中:
- 比如Spring Security框架中
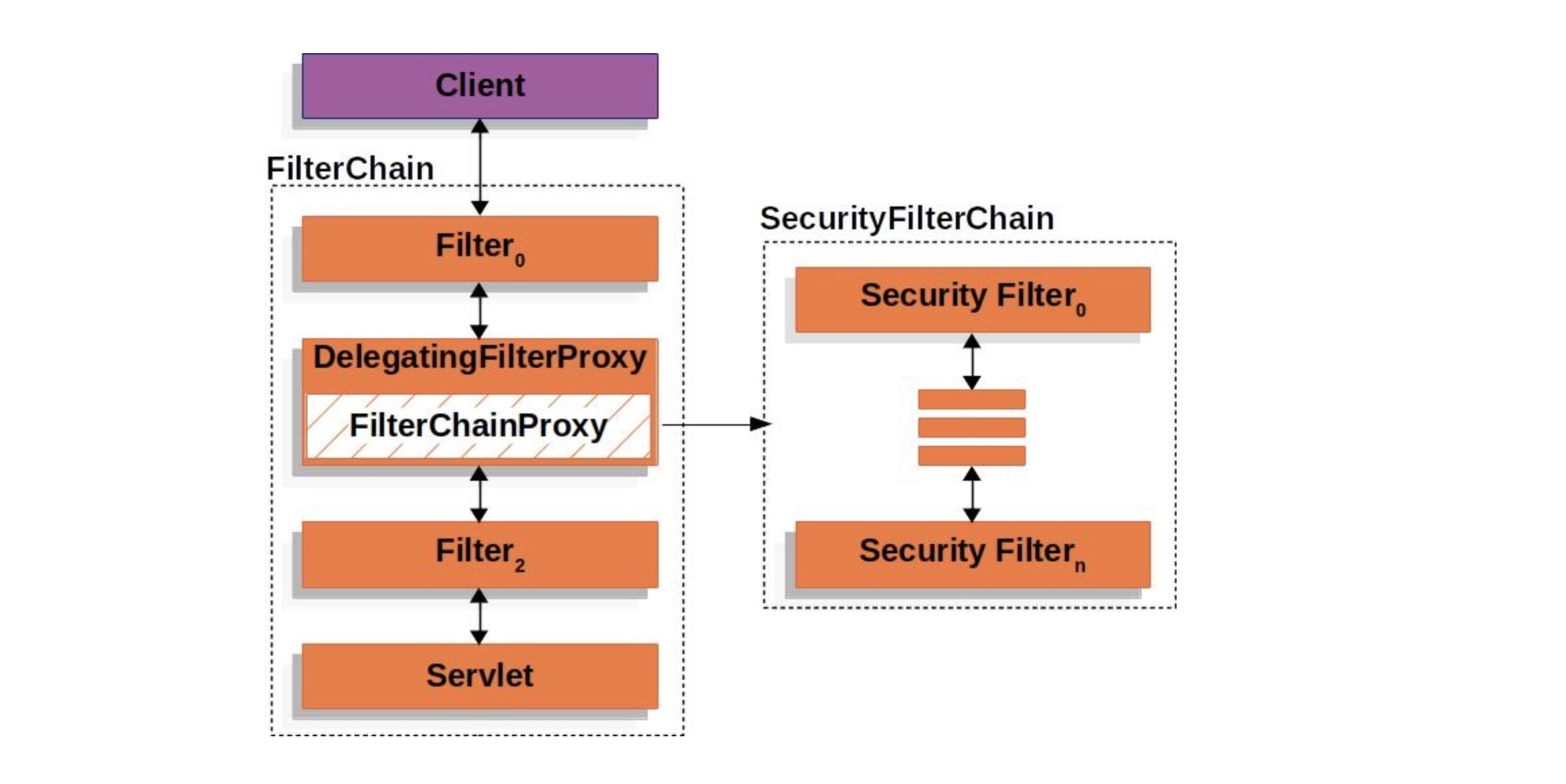
- 比如HttpServletRequest处理的过滤器中
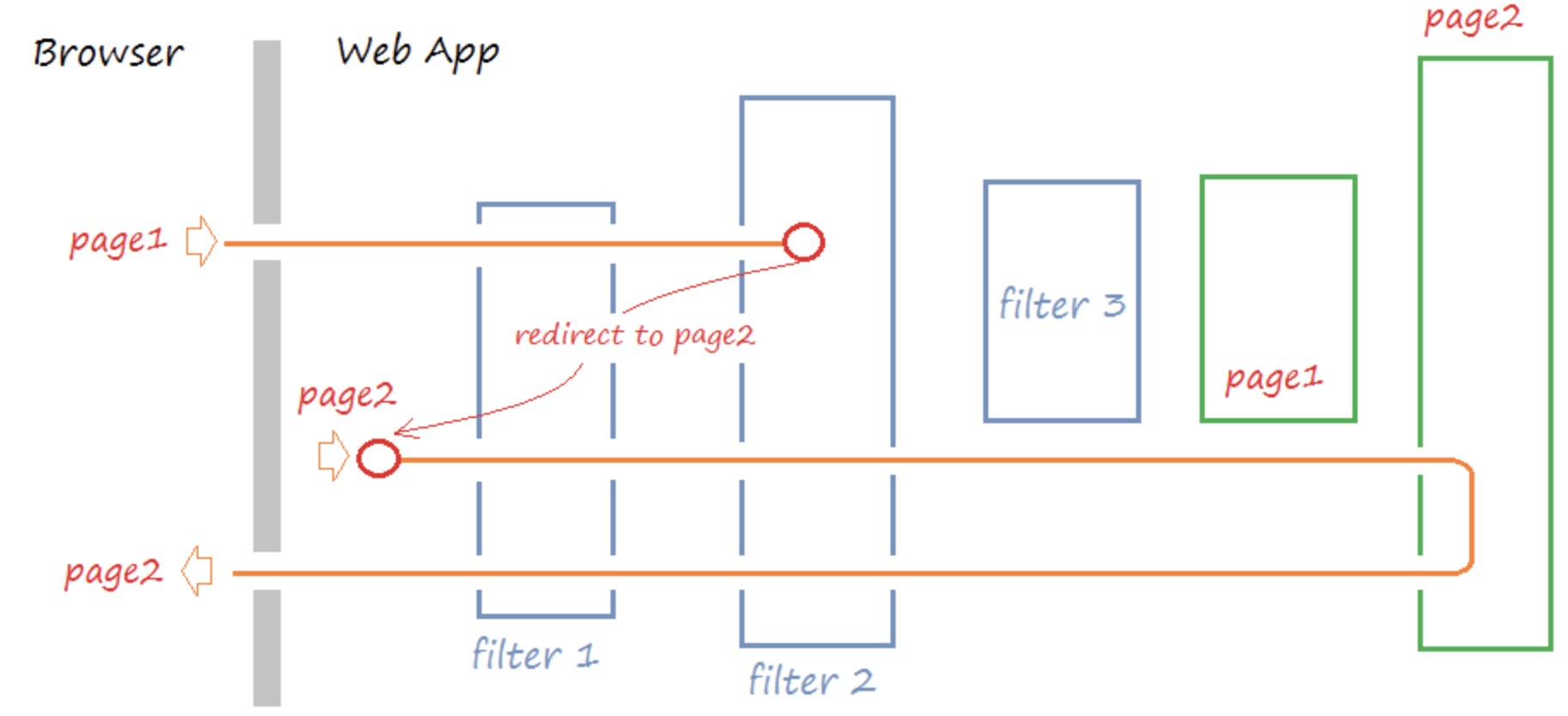
当一个request过来的时候,需要对这个request做一系列的加工,使用责任链模式可以使每个加工组件化,减少耦合。也可以使用在当一个request过来的时候,需要找到合适的加工方式。当一个加工方式不适合这个request的时候,传递到下一个加工方法,该加工方式再尝试对request加工。
网上找了图,这里我们后文将通过Tomcat请求处理向你阐述。
ElasticSearch设计管道机制
简单而言:让上一步的聚合结果成为下一个聚合的输入,这就是管道。
接下来,无非就是对不同类型的聚合有接口的支撑,比如:
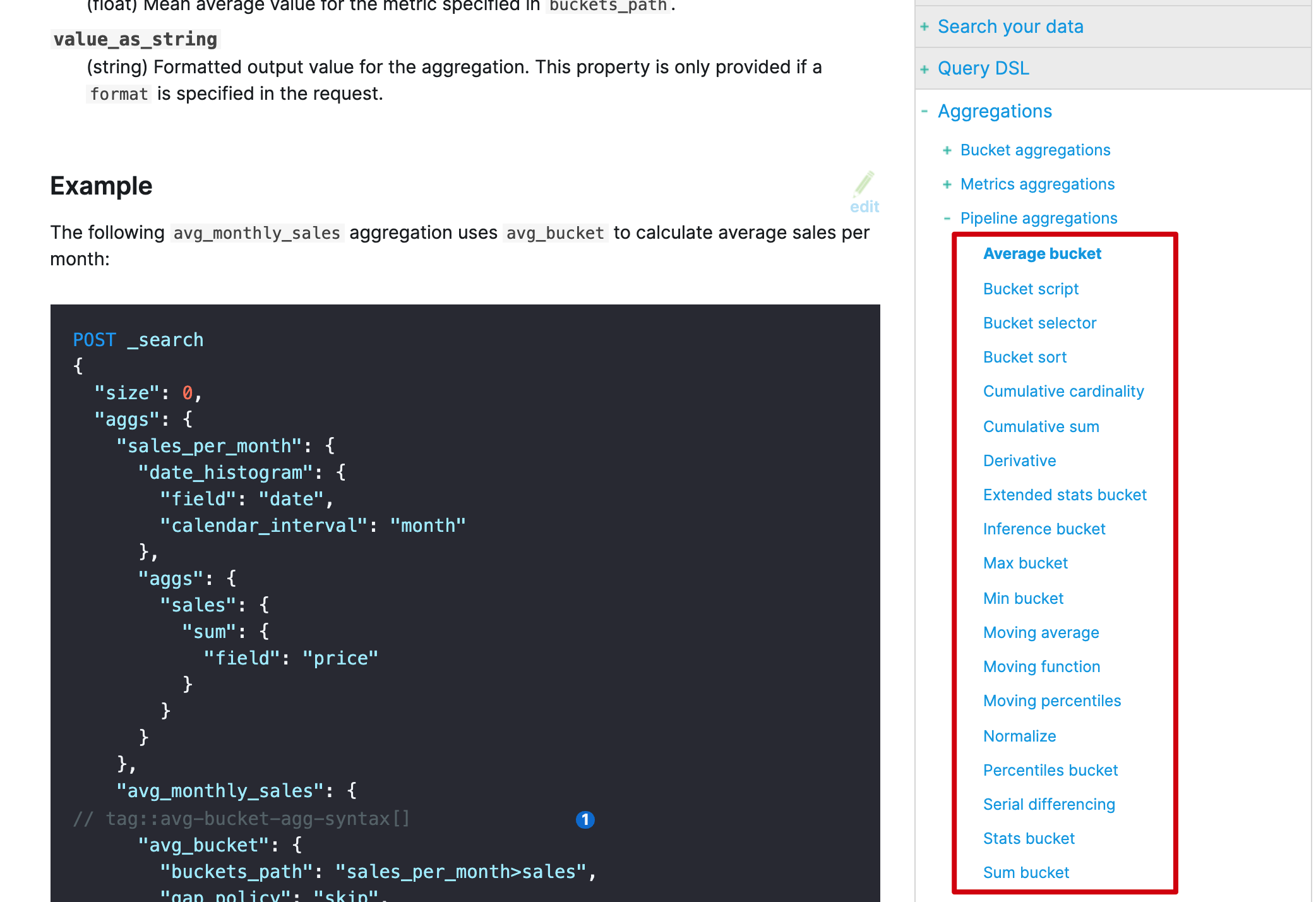
第一个维度:管道聚合有很多不同类型,每种类型都与其他聚合计算不同的信息,但是可以将这些类型分为两类:
-
父级 父级聚合的输出提供了一组管道聚合,它可以计算新的存储桶或新的聚合以添加到现有存储桶中。
-
兄弟 同级聚合的输出提供的管道聚合,并且能够计算与该同级聚合处于同一级别的新聚合。
第二个维度:根据功能设计的意图
比如前置聚合可能是Bucket聚合,后置的可能是基于Metric聚合,那么它就可以成为一类管道
进而引出了:`xxx bucket
- Bucket聚合 -> Metric聚合
: bucket聚合的结果,成为下一步metric聚合的输入
-
Average bucket
-
Min bucket
-
Max bucket
-
Sum bucket
-
Stats bucket
-
Extended stats bucket
对构建体系而言,理解上面的已经够了,其它的类型不过是锦上添花而言。
一些例子
这里我们通过几个简单的例子看看即可,具体如果需要使用看看文档即可。
Average bucket 聚合
POST _search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"avg_monthly_sales": {
// tag::avg-bucket-agg-syntax[]
"avg_bucket": {
"buckets_path": "sales_per_month>sales",
"gap_policy": "skip",
"format": "#,##0.00;(#,##0.00)"
}
// end::avg-bucket-agg-syntax[]
}
}
}
-
嵌套的bucket聚合:聚合出按月价格的直方图
-
Metic聚合:对上面的聚合再求平均值。
字段类型:
-
buckets_path:指定聚合的名称,支持多级嵌套聚合。
-
gap_policy 当管道聚合遇到不存在的值,有点类似于term等聚合的(missing)时所采取的策略,可选择值为:skip、insert_zeros。
-
skip:此选项将丢失的数据视为bucket不存在。它将跳过桶并使用下一个可用值继续计算。
-
format 用于格式化聚合桶的输出(key)。
输出结果如下
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"avg_monthly_sales": {
"value": 328.33333333333333,
"value_as_string": "328.33"
}
}
}
Stats bucket 聚合
进一步的stat bucket也很容易理解了
POST /sales/_search
{
"size": 0,
"aggs": {
"sales_per_month": {
"date_histogram": {
"field": "date",
"calendar_interval": "month"
},
"aggs": {
"sales": {
"sum": {
"field": "price"
}
}
}
},
"stats_monthly_sales": {
"stats_bucket": {
"buckets_path": "sales_per_month>sales"
}
}
}
}
返回
{
"took": 11,
"timed_out": false,
"_shards": ...,
"hits": ...,
"aggregations": {
"sales_per_month": {
"buckets": [
{
"key_as_string": "2015/01/01 00:00:00",
"key": 1420070400000,
"doc_count": 3,
"sales": {
"value": 550.0
}
},
{
"key_as_string": "2015/02/01 00:00:00",
"key": 1422748800000,
"doc_count": 2,
"sales": {
"value": 60.0
}
},
{
"key_as_string": "2015/03/01 00:00:00",
"key": 1425168000000,
"doc_count": 2,
"sales": {
"value": 375.0
}
}
]
},
"stats_monthly_sales": {
"count": 3,
"min": 60.0,
"max": 550.0,
"avg": 328.3333333333333,
"sum": 985.0
}
}
}
聚合查询总结:Bucket、Metric 与 Pipeline
一、核心概念与对比

二、Metric 聚合(度量聚合)
-
定义
对索引中的文档进行数学计算,返回具体的数值指标。 -
常见分类
单值数值聚合:返回单个数值。
avg:平均值
sum:求和
min / max:最小值 / 最大值
value_count:非空值的计数
cardinality:去重计数(类似 COUNT(DISTINCT))
多值数值聚合:返回多个数值。
stats:一次返回 count、min、max、avg、sum
extended_stats:扩展统计,包含方差、标准差、平方和等
percentiles:百分位统计(如 TP50、TP99)
percentile_ranks:给定值处于哪个百分位
geo_bounds:地理边界
top_hits:返回桶内匹配的顶部文档(实际是聚合嵌入的查询结果)
-
关键机制与注意点
执行位置:聚合主要运行在 doc_values(列式存储)上,性能极佳。确保聚合字段的 doc_values 为 true(默认对 keyword 和数值类型开启)。
内存消耗:cardinality 聚合采用 HyperLogLog++ 算法,近似精确,内存消耗固定,可通过 precision_threshold 参数在精度与内存间平衡。
数据准确性:percentiles 采用 T-Digest 算法,也是近似算法,适合大规模数据。
三、Bucket 聚合(桶聚合)
-
定义
将满足特定条件的文档划分到不同的桶中。每个桶关联一个 Key 和一组文档,可以嵌套子聚合进行多维分析。 -
常见分类
词条聚合:
terms:根据字段值分组(类似 GROUP BY field),返回词条及其文档计数。
multi_terms:多字段组合分组(ES 7.x+ 引入)。
significant_terms / significant_text:分析出现频率显著高于背景集的词条,常用于异常检测。
范围聚合:
range / date_range:自定义数值或日期范围分组。
histogram / date_histogram:按固定间隔(如每 10 元一个区间,或每天一个区间)直方图分组。
其他类型:
filter / filters:自定义过滤条件创建桶(每个桶对应一个过滤器)。
nested / reverse_nested:针对嵌套对象的聚合,允许在嵌套文档和父文档之间切换上下文。
geohash_grid / geotile_grid:地理坐标网格聚合。
-
关键机制与注意点
深度与精度:terms 聚合默认只返回前 10 个桶(可通过 size 调整)。为了快速返回 Top 桶,ES 使用节点内部频率排序,不保证绝对精确,可通过增加 shard_size 提高精度,但会增加网络开销。嵌套层次:Bucket 聚合可以无限嵌套,形成多维下钻分析(如:先按日期分桶,再按地域分桶,再计算平均销售额)。
性能优化:避免在 text 字段上直接进行 Bucket 聚合(应使用 keyword 子字段),否则会启用 fielddata,消耗大量堆内存。
四、Pipeline 聚合(管道聚合)
-
定义
对其他聚合的输出结果进行二次计算。管道聚合不直接操作文档,而是“流淌”在已有聚合结果之上。 -
分类(根据执行方式)
Parent 管道(父级管道):基于父聚合(通常是 Bucket 聚合)的结果进行计算,并将结果追加到父聚合的每个桶中。
derivative:求导数(计算变化率,常用于时间序列)。
moving_avg / moving_fn:移动平均值(平滑曲线)。注意:moving_avg 在较新版本中已废弃,推荐使用
moving_fn 自定义函数。cumulative_sum:累积求和。
avg_bucket / sum_bucket / max_bucket / min_bucket:计算同级桶内特定度量的平均值/总和等。
Sibling 管道(同级管道):基于同级聚合的结果进行计算,输出一个新的聚合,与父聚合同级(不添加到已有桶中)。
bucket_script:执行脚本,对多个度量进行算术运算(如计算 a / b),生成新的值。
bucket_selector:根据条件过滤桶(类似 HAVING),符合条件的桶保留,不符合的丢弃。
bucket_sort:对父聚合的桶进行排序、截断(实现分页)。
stats_bucket / extended_stats_bucket:计算同级桶中特定度量的统计信息。
-
关键机制与注意点
依赖关系:Pipeline 聚合必须指定 buckets_path,指明数据来源于哪个聚合(支持多级路径)。执行顺序:先执行普通的 Metric 和 Bucket 聚合,然后按定义顺序执行 Pipeline 聚合。
脚本使用:bucket_script 和 bucket_selector 支持 Painless 脚本,可实现灵活的业务逻辑。
五、实战组合逻辑
在实际开发中,这三种聚合通常组合使用,解决复杂业务需求。
常见组合模式
1、Bucket + Metric(最常用)场景:统计每个部门的平均薪资。
逻辑:terms(部门)→ 内嵌 avg(薪资)。
2、Bucket + Bucket + Metric(多维下钻)
场景:统计近 7 天,每天销售额最高的前 10 个商品。
逻辑:date_histogram(天)→ 内嵌 terms(商品 ID),并在 terms 中按 sum(销售额)排序且设置 size:10。
3、Bucket + Metric + Pipeline(Parent)(高级分析)
场景:统计 2024 年每月销售额,并计算环比增长率。
逻辑:date_histogram(月)→ sum(销售额)→ 得到每月销售额。 derivative 管道聚合(Parent)→ 基于上述sum 计算相邻桶差值(变化量),再配合 bucket_script 计算增长率。
4、Bucket + Metric + Pipeline(Sibling)(Having 子句)
场景:筛选出平均销售额大于 10000 的部门。
逻辑:
terms(部门)→ avg(销售额)。 bucket_selector(Sibling)→ 如果 avg_sales <= 10000则过滤掉该桶(相当于 HAVING avg_sales > 10000)。5、多重 Pipeline 组合
场景:获取销售额排名前 3 的部门,并按销售额降序输出。
逻辑:
terms(部门)→ sum(销售额)。 bucket_sort(Sibling)→ 按 sum_sales 降序,设置 size: 3。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)