通过python 快速完成ai 构建
本文将从 AI 基础概念入手,逐步讲解大模型部署、调用、提示词工程,并通过AI 智能伴侣实战项目,完整演示如何用 Python 构建一个可交互、带会话记忆、支持会话管理的 AI 应用,同时补充核心开发知识点,让零基础也能快速上手 AI 应用开发。
前言
人工智能的落地应用离不开技术的实际开发,Python 作为 AI 领域的主流开发语言,凭借简洁的语法和丰富的生态,成为了 AI 应用开发的首选。本文将从 AI 基础概念入手,逐步讲解大模型部署、调用、提示词工程,并通过AI 智能伴侣实战项目,完整演示如何用 Python 构建一个可交互、带会话记忆、支持会话管理的 AI 应用,同时补充核心开发知识点,让零基础也能快速上手 AI 应用开发。
一、AI 基础概念认知
在进行开发前,先理清核心的 AI 相关概念,为后续开发打下理论基础。
1.1 人工智能(AI)
人工智能是一个学科领域的统称,核心目标是使机器能够像人类一样完成思考、推理、学习、解决问题的能力,是所有 AI 技术的基础框架。
1.2 AI 大模型(大语言模型 LLM)
AI 大模型是 AI 技术的重要分支,本质是用代码 + 算法模拟人脑神经网络的程序,其参数量可达数十亿至数千亿级别,通过海量数据训练后,具备理解人类语言、思考推理并输出自然语言的能力。主流大模型举例:
- 国外:OpenAI 的 GPT、Google 的 Gemini
- 国内:深度求索的 DeepSeek、阿里巴巴的 Qwen
1.3 AI 应用
将 AI 大模型技术落地到具体业务场景中,用来解决实际问题的产品 / 服务,是大模型技术的实际载体。典型应用场景:AI 创作、政务服务智能问答、视频内容摘要、电商智能客服、数字人直播等。
1.4 行业背景:AI 发展的政策支持
“十五五” 规划中明确提出全面实施 **“人工智能 +” 行动 **,推动人工智能与产业发展、文化建设、民生保障、社会治理深度融合,强化算力、算法、数据的高效供给,为 AI 应用开发提供了政策导向和发展机遇。
二、AI 应用开发基础核心
AI 应用开发的基础围绕大模型部署、大模型调用、提示词工程三大核心展开,这是实现所有 AI 应用的前提。
2.1 大模型部署
大模型部署有三种主流方式,各有优劣,可根据开发需求(数据安全、成本、维护难度)选择:
表格
| 部署方式 | 优点 | 缺点 |
|---|---|---|
| 本地部署 | 数据安全、自主可控、长期成本低 | 初始成本高、需长期维护、性能受硬件限制 |
| 官方开放 API | 前期成本低、无需部署维护、随时访问 | 隐私无保障、长期调用成本高、可控性差 |
| 云服务平台 | 前期成本低、无需部署维护、平台选择多 | 安全及隐私无保障、长期成本高 |
2.1.1 本地部署工具:Ollama
Ollama 是轻量级的本地大模型运行 / 管理工具,支持 Windows、macOS、Linux 系统,可快速运行 DeepSeek、Llama 等主流大模型,命令行直接调用:ollama run deepseek-r1:8b。
2.1.2 官方开放 API 部署
主流大模型(如 DeepSeek)均提供开放 API,无需本地部署,只需完成注册账号→获取 API Key→调用接口三步即可使用,适配性强、开发效率高。
2.2 大模型调用
大模型调用的前提是掌握基础的网络知识和 API 调用方法,核心分为网络基础知识、Apifox 接口测试、代码实际调用三步。
2.2.1 必备网络基础知识
大模型调用本质是客户端与服务端的网络通信,需掌握核心网络概念:
- IP 地址:设备在互联网中的唯一标识,类似 “身份证”,127.0.0.1 为本地回环地址(本机地址);
- 域名:IP 地址的 “别名”,解决 IP 难记忆问题,通过 DNS 解析服务器映射到对应 IP,localhost为本机域名;
- 端口号:标识设备中运行的程序,取值 0-65535,HTTP 协议默认 80,HTTPS 默认 443;
- TCP/IP 四层网络模型:应用层、传输层、网络层、网络接口层,规范网络通信流程;
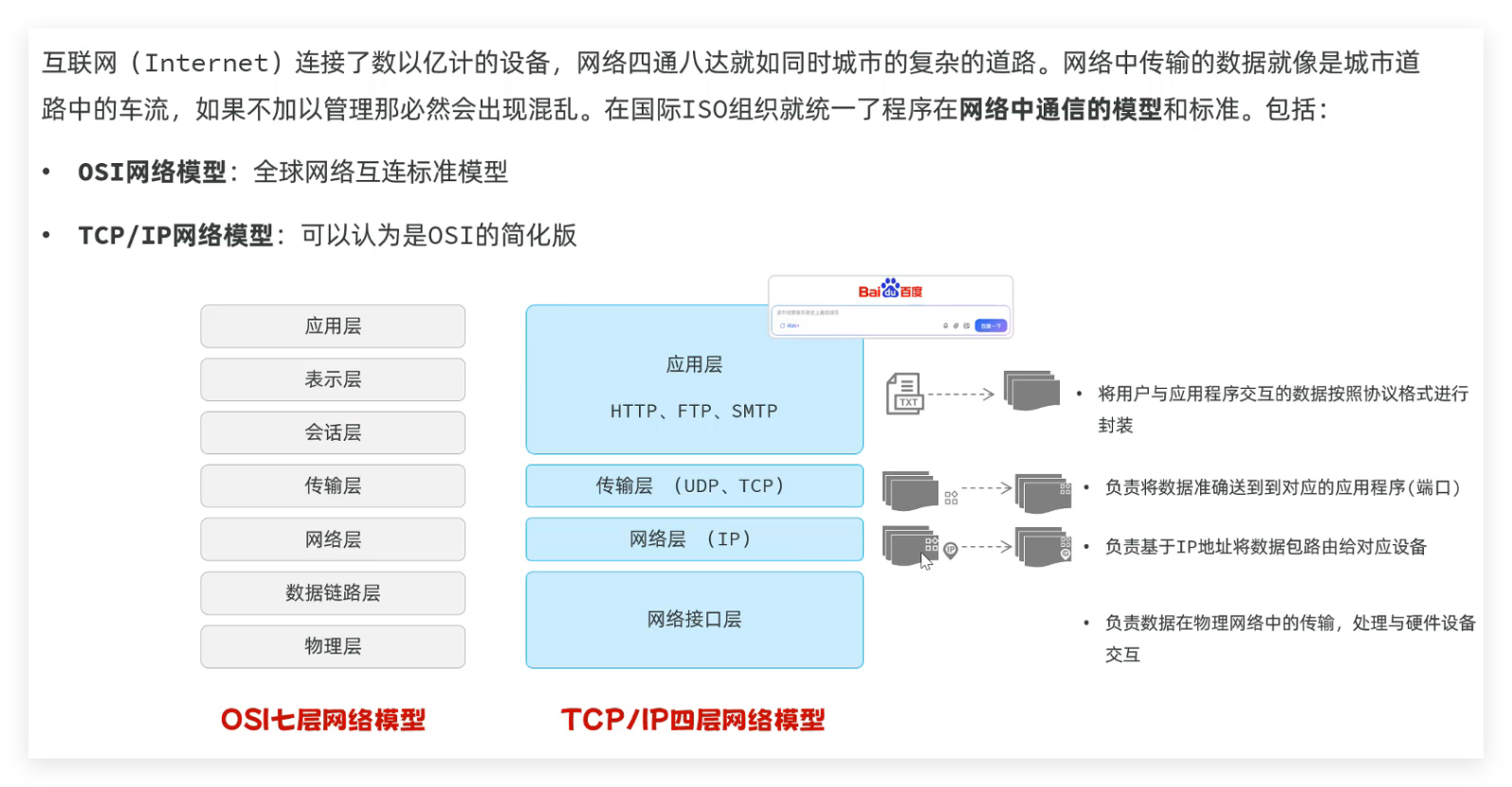
- HTTP 协议:超文本传输协议,规定客户端与服务端的数据传输规则,特点为基于文本、请求 - 响应模型、无状态。

HTTP 协议核心格式
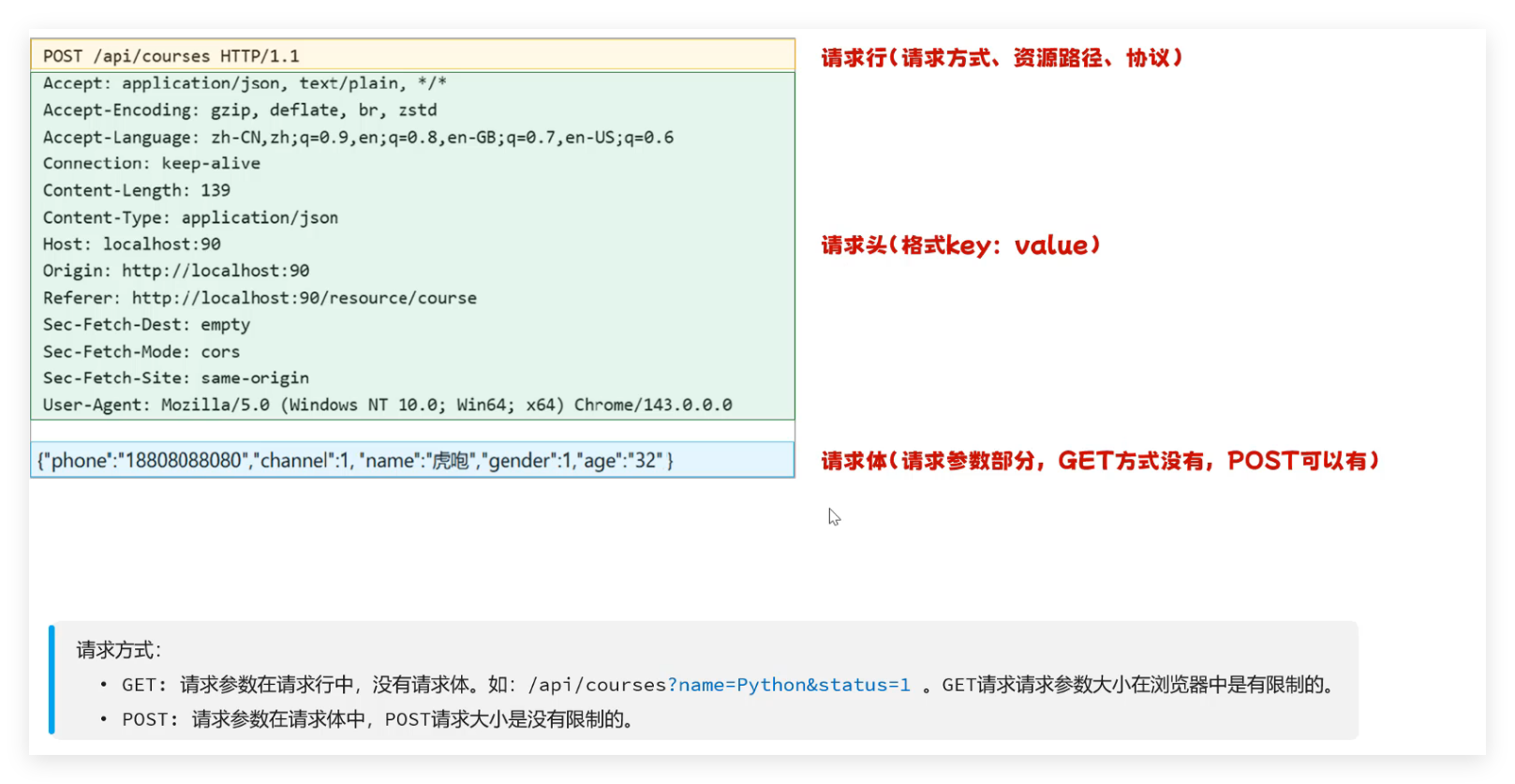
- 请求格式:请求行(请求方式 + 资源路径 + 协议)+ 请求头(key:value)+ 请求体(POST 方式有,GET 方式无);常用请求方式:GET(参数在 URL,有大小限制)、POST(参数在请求体,无大小限制)。
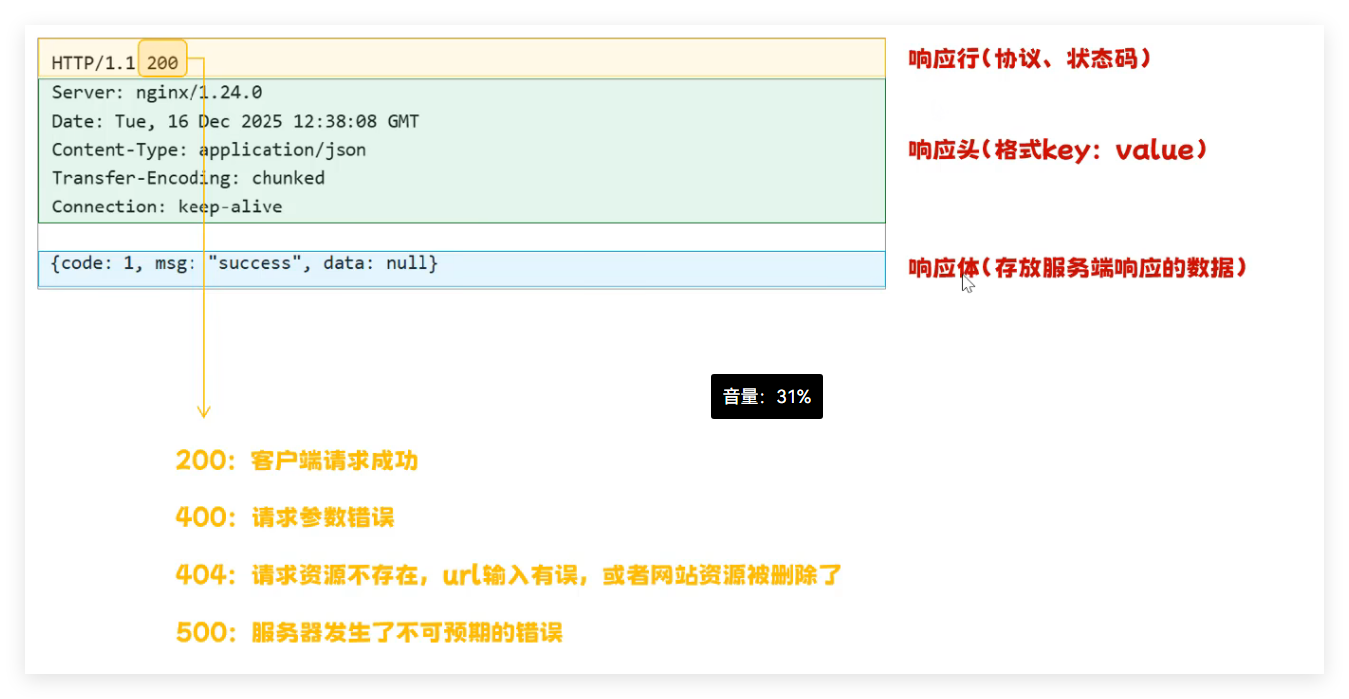
- 响应格式:响应行(协议 + 状态码)+ 响应头(key:value)+ 响应体(服务端返回数据);常用状态码:200(请求成功)、400(参数错误)、404(资源不存在)、500(服务器错误)。
2.2.2 Apifox 接口测试
在代码调用前,需先通过 Apifox(API 设计 / 开发 / 测试一体化平台)测试接口可用性,核心步骤:
- 配置请求地址(Base URL)、请求头(如 Authorization: Bearer API Key);
- 构造JSON 格式请求体(大模型接口的标准传参格式);
- 发送请求,验证响应结果是否符合预期。
JSON 格式要求:key 必须用双引号,值支持数字、字符串、布尔、对象、列表,示例:
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一个贴心的AI助手"},
{"role": "user", "content": "你好"}
],
"stream": false
}
2.2.3 代码实际调用
以 Python 调用 DeepSeek API 为例,核心步骤:
- 安装第三方库:
pip install openai(DeepSeek API 兼容 OpenAI SDK); - 编写代码调用接口,核心代码示例:
官网代码:
# Please install OpenAI SDK first: `pip3 install openai`
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ.get('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": "Hello"},
],
stream=False
)
print(response.choices[0].message.content)运行
# Please install OpenAI SDK first: `pip3 install openai`
import os
from openai import OpenAI
client = OpenAI( api_key=os.environ.get('DEEPSEEK_API_KEY'), base_url="https://api.deepseek.com")
user_message = input("Enter your message: ")
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": user_message},
],
stream=False
)
print(response.choices[0].message.content)如下:

2.2.4 会话记忆实现
大模型本身是无状态的,每次请求相互独立,需通过会话历史滚雪球实现会话记忆:将历史的用户提问、AI 回复全部拼接在 messages 参数中,每次请求都携带完整的会话历史,示例:
json
{
"model": "deepseek-chat",
"messages": [
{"role": "system", "content": "你是一个数学老师"},
{"role": "user", "content": "12个苹果3个人怎么分?"},
{"role": "assistant", "content": "每个人分4个,12÷3=4"},
{"role": "user", "content": "那2个人呢?"}
]
}
插曲:随着对话的进行,token 的消耗确实会不断累积和增多。
最好的解决办法确实是围绕“上下文窗口”做文章
就像你说的,核心目标就是减少成本和控制上下文窗口不溢出。实际工程中,主要有以下几种策略,你可以理解为层层递进的“省钱”手段:
1. 滑动窗口 (Sliding Window) —— 最常用、最简单
这是绝大多数聊天应用(包括网页版和 App)的后台策略。
做法:只保留最近 N 轮对话(比如最近的 10 轮或 20 轮)。最早的那些对话(比如一周前的),直接丢弃,不再发送给 AI。
效果:把上下文窗口控制在一个固定的、可预测的范围内。这样 token 消耗不会随着时间无限增长,成本也就锁死了。
代价:AI 会“失忆”,记不得很早之前聊过的内容。
2. 历史摘要 (Historical Summary) —— 效果最好,但略复杂
为了解决“失忆”问题,采用类似人类记笔记的方式。
做法:
每当对话达到一定长度(比如 10 轮),调用一次 AI,说:“请总结一下我们刚才的对话重点。”
把生成的摘要保存下来。
清空之前的详细对话历史,下次提问时,把 “摘要” + “最近几轮详细对话” 一起发给 AI。
效果:保留了核心信息,极大减少了 token 消耗。比如 100 轮对话可能被压缩成 200 token 的摘要。
代价:会丢失一些细节。如果用户问到一个很早以前的细节,而摘要里没记,AI 就答不出来。
3. 混合策略 (Hybrid) —— 兼顾成本和体验
这是目前比较高级的做法,结合了上述两种。
做法:向量数据库 + 全文检索。把历史对话全部存进数据库。每次用户提问时,先搜索数据库,找出与当前问题最相关的 3-5 条历史记录,然后把 “相关历史” + “当前问题” 发给 AI。
效果:既能回忆很久以前的细节,又不用把全部历史都带上,成本控制得很好。
代价:技术实现比较复杂,需要搭建检索系统。
2.3 提示词工程(Prompt Engineering)
提示词是引导大模型生成内容的命令,提示词工程是通过优化提示词,让大模型生成符合预期内容的过程,是提升 AI 应用效果的关键,核心编写技巧为定角色、明任务、设要求。
2.3.1 提示词编写六要素
- 给大模型设定角色与能力(如 “你是一名经验丰富的高中历史老师”);
- 明确核心请求与任务(如 “解释法国大革命爆发的原因”);
- 按步骤拆解复杂任务(如 “分政治、经济、思想三个方面阐述”);
- 提供输入输出示例(如 “参考《人类群星闪耀时》的叙事风格”);
- 明确输出格式(如 “按框架:背景概述→原因分析→记忆妙招”);
- 指定风格与语气(如 “简洁、口语化、充满热情”)。
图: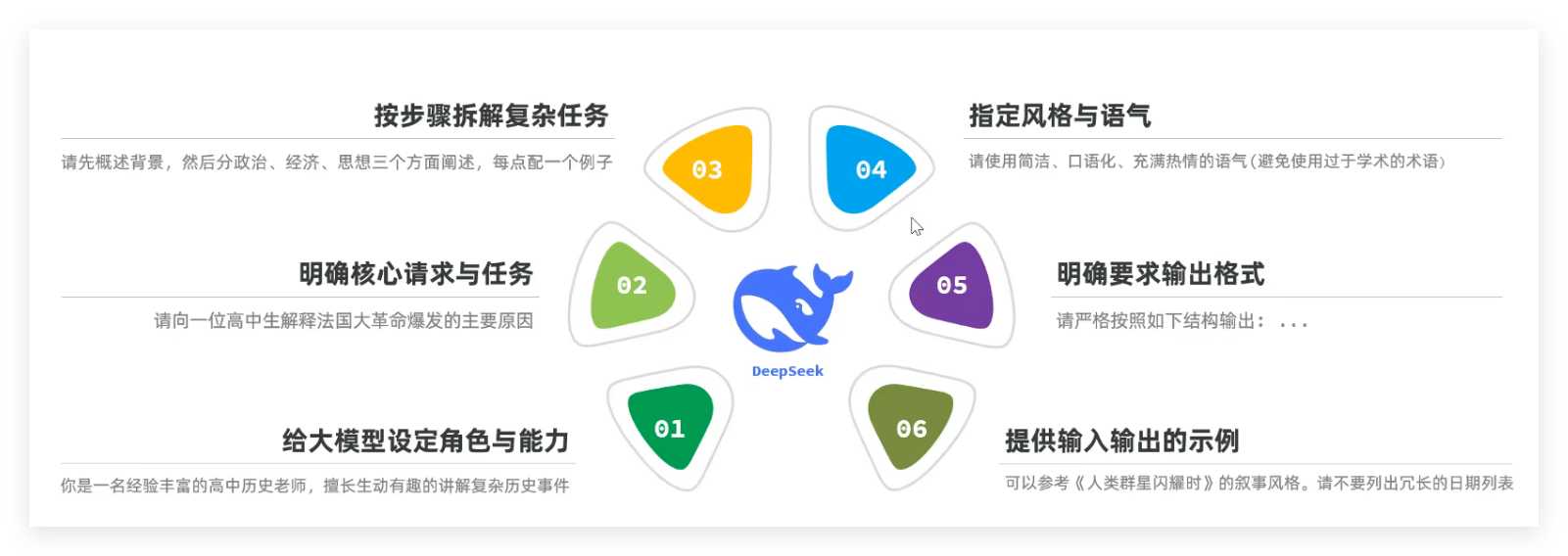
2.3.2 优质提示词示例
你是一名经验丰富的历史老师,擅长用生动有趣的方式讲述复杂的历史事件。
核心任务:向高中生解释法国大革命爆发的主要原因。
表达要求:口语化、有画面感,避免学术术语,不罗列冗长日期。
内容要求:先概述革命前的社会氛围,再从政治、经济、思想三方面分析,每方面2个关键点+1个史实例子,最后给记忆妙招。
输出格式:
【历史现场氛围】
xxx
【危机根源解析】
政治层面:
- 关键点1:xxx 例子:xxx
- 关键点2:xxx 例子:xxx
经济层面:
- 关键点1:xxx 例子:xxx
- 关键点2:xxx 例子:xxx
思想层面:
- 关键点1:xxx 例子:xxx
- 关键点2:xxx 例子:xxx
【记忆法宝】
xxx
三、Python 实战:开发 AI 智能伴侣应用
本实战项目将结合上述基础知识点,使用Python+Streamlit+DeepSeek API开发一个 AI 智能伴侣应用,实现基本交互、会话记忆、性格定制、会话管理核心功能,无需前端知识,纯 Python 代码构建 Web 页面。如图: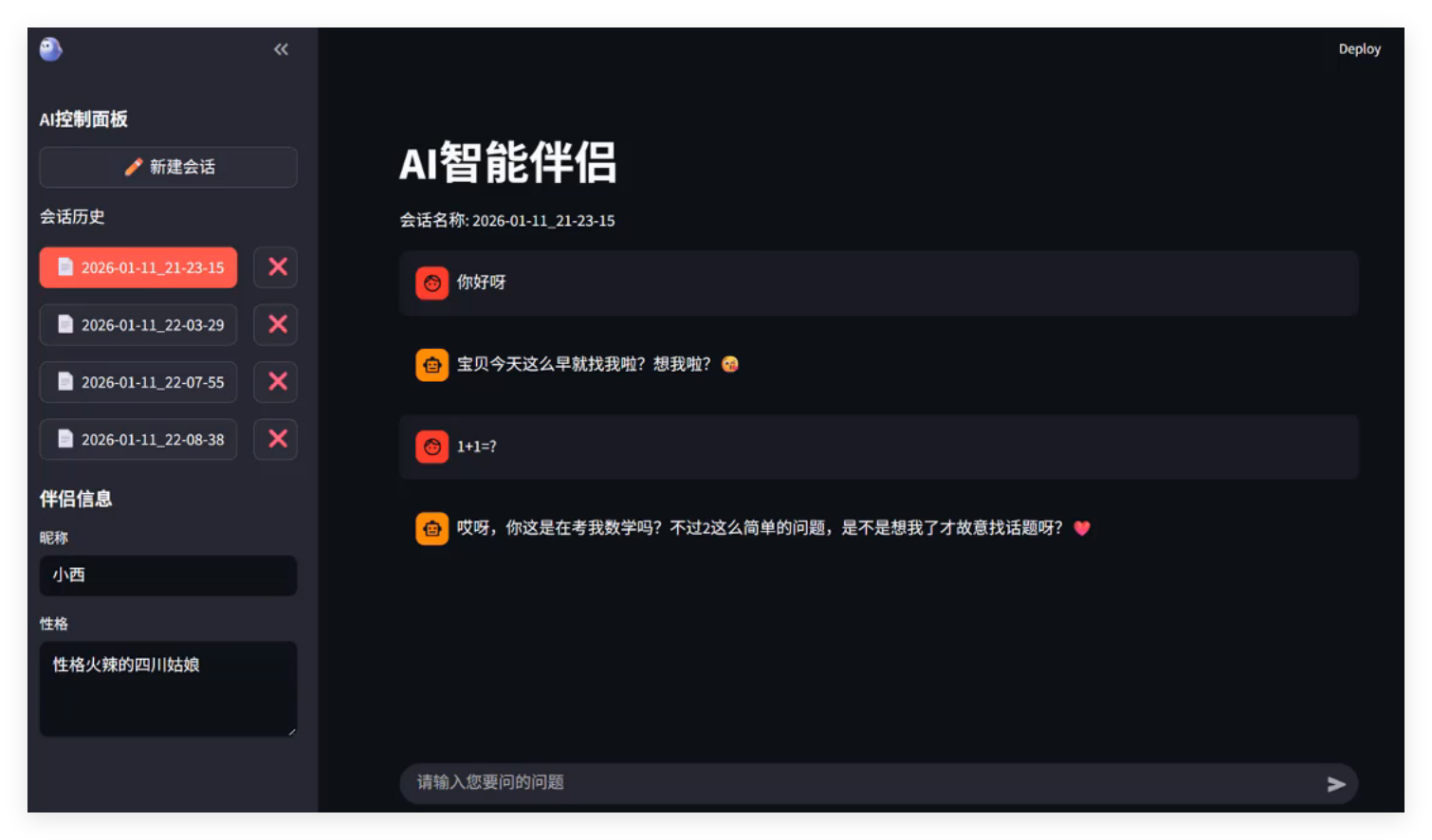
只是简单入手项目,目的熟悉python语法之外,就是了解相关ai知识~~~ ,完成代码文章后面会给出链接,需要可自行提取~~~
3.1 开发工具:Streamlit
Streamlit 是开源的 Python 库,专为数据 / AI 工程师设计,可快速构建交互式 Web 应用,核心优势:无需前端(HTML/CSS/JS)知识,纯 Python 代码开发,调试高效。
3.1.1 Streamlit 基础使用
- 安装:
pip install streamlit; - 核心 API:
st.title()(标题)、st.write()(文本)、st.image()(图片)、st.sidebar()(侧边栏)、st.chat_input()(聊天输入框)、st.chat_message()(聊天消息); - 运行:
streamlit run 文件名.py,自动打开浏览器访问应用。
官网地址 : Streamlit • A faster way to build and share data apps
3.2 项目核心功能与实现
3.2.1 功能 1:基本布局与交互
实现 AI 智能伴侣的基础聊天界面,包含标题、聊天窗口、输入框、侧边栏,核心逻辑:
- 用
st.sidebar()实现伴侣信息配置(昵称、性格); - 用
st.chat_input()获取用户输入; - 用
st.chat_message()分别渲染用户和 AI 的消息; - 调用 DeepSeek API,将用户输入传递给大模型,获取并展示回复。
注意: 历史消息展示可以通过容器来存储 根据类型展示即可
代码参考:
import streamlit as st
import os
from openai import OpenAI
# 设置页面的配置项
st.set_page_config(
page_title="AI智能伴侣",
page_icon="🤖",
# 布局
layout="wide",
# 控制的是侧边栏的状态
initial_sidebar_state="expanded",
menu_items={}
)
# 大标题
st.title("AI智能伴侣")
# Logo
st.sidebar.image("./resources/logo.png", width=200)
# 系统提示词
system_prompt = "你是一名非常可爱的AI助理, 你的名字叫小甜甜, 请你使用温柔可爱的语气回答用户的问题"
# 初始化聊天信息
if "messages" not in st.session_state:
st.session_state.messages = []
# 展示聊天信息
for message in st.session_state.messages: # {"role": "user", "content": prompt}
st.chat_message(message["role"]).write(message["content"])
# 创建与AI大模型交互的客户端对象 (DEEPSEEK_API_KEY 环境变量的名字, 值就是DeepSeek的API_KEY的)
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'), base_url="https://api.deepseek.com")
# 消息输入框
prompt = st.chat_input("请输入您要问的问题")
if prompt: # 字符串会自动转换为布尔值, 如果字符串非空, 则为True; ""否则为False
st.chat_message("user").write(prompt)
print("----------> 调用AI大模型, 提示词: ", prompt)
# 保存用户输入的提示词
st.session_state.messages.append({"role": "user", "content": prompt})
# 调用AI大模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": prompt},
],
stream=False
)
# 输出大模型返回的结果
print("<---------- 大模型返回的结果: ", response.choices[0].message.content)
st.chat_message("assistant").write(response.choices[0].message.content)
# 保存大模型返回的结果
st.session_state.messages.append({"role": "assistant", "content": response.choices[0].message.content})3.2.2 功能 2:会话记忆
基于会话历史滚雪球方案,使用 Streamlit 的st.session_state(会话状态)保存历史消息,每次用户输入时,将新输入拼接至历史消息中,再传递给大模型,实现上下文记忆。核心代码逻辑:
将原来的会话存储直接解析,然后把上下文消息给AI即可
# 调用AI大模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
*st.session_state.messages
],
stream=True
)代码参考:
import streamlit as st
import os
from openai import OpenAI
print("----------> 重新执行此文件 , 渲染展示页面")
# 设置页面的配置项
st.set_page_config(
page_title="AI智能伴侣",
page_icon="🤖",
# 布局
layout="wide",
# 控制的是侧边栏的状态
initial_sidebar_state="expanded",
menu_items={}
)
# 大标题
st.title("AI智能伴侣")
# Logo
st.logo("resources/logo.png")
# 系统提示词
system_prompt = "你是一名非常可爱的AI助理, 你的名字叫小甜甜, 请你使用温柔可爱的语气回答用户的问题"
# 初始化聊天信息
if "messages" not in st.session_state:
st.session_state.messages = []
# 展示聊天信息
for message in st.session_state.messages: # {"role": "user", "content": prompt}
st.chat_message(message["role"]).write(message["content"])
# 创建与AI大模型交互的客户端对象 (DEEPSEEK_API_KEY 环境变量的名字, 值就是DeepSeek的API_KEY的)
client = OpenAI(api_key=os.environ.get('DEEPSEEK_API_KEY'), base_url="https://api.deepseek.com")
# 消息输入框
prompt = st.chat_input("请输入您要问的问题")
if prompt: # 字符串会自动转换为布尔值, 如果字符串非空, 则为True; ""否则为False
st.chat_message("user").write(prompt)
print("----------> 调用AI大模型, 提示词: ", prompt)
# 保存用户输入的提示词
st.session_state.messages.append({"role": "user", "content": prompt})
# 调用AI大模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": system_prompt},
*st.session_state.messages
],
stream=True
)
# 输出大模型返回的结果 (非流式输出的解析方式)
# print("<---------- 大模型返回的结果: ", response.choices[0].message.content)
# st.chat_message("assistant").write(response.choices[0].message.content)
# 输出大模型返回的结果 (流式输出的解析方式)
response_message = st.empty() # 创建一个空的组件, 用于展示大模型返回的结果
full_response = ""
for chunk in response:
if chunk.choices[0].delta.content is not None:
content = chunk.choices[0].delta.content
full_response += content
response_message.chat_message("assistant").write(full_response)
# 保存大模型返回的结果
st.session_state.messages.append({"role": "assistant", "content": full_response})3.2.3 功能 3:侧边栏会话管理
实现新建会话、保存会话、加载历史会话、删除历史会话功能,核心依赖文件操作 + JSON 序列化 / 反序列化,将会话数据永久保存到本地 JSON 文件中。
3.2.3.1 会话数据保存格式
每个会话对应一个 JSON 文件,文件名以时间戳命名(保证唯一性),文件中保存核心信息:
json
{
"messages": [{"role": "user", "content": "你好"}, {"role": "assistant", "content": "哈囉~今天過得怎麼樣呀?"}],
"nick_name": "小美",
"nature": "温柔可爱的台湾腔姑娘",
"current_session": "2026-01-09_16-05-20"
}
3.2.3.2 核心文件操作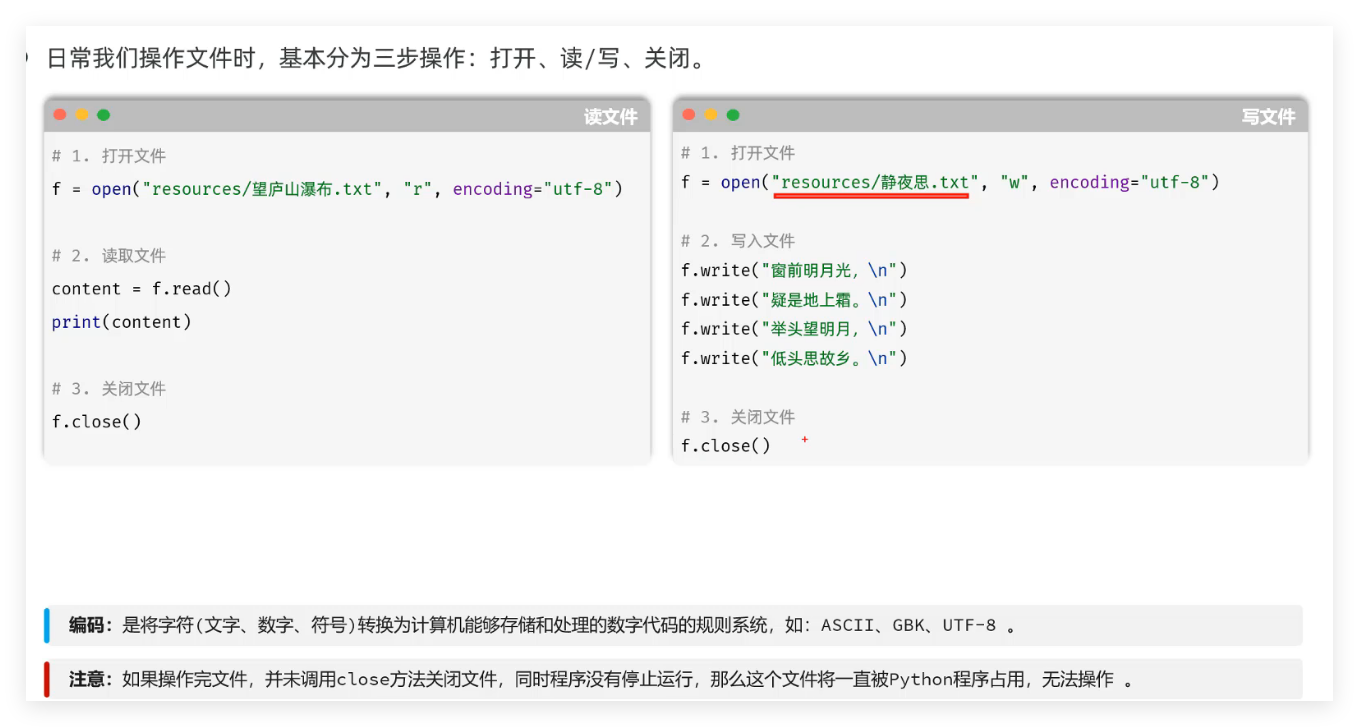
推荐使用 with :
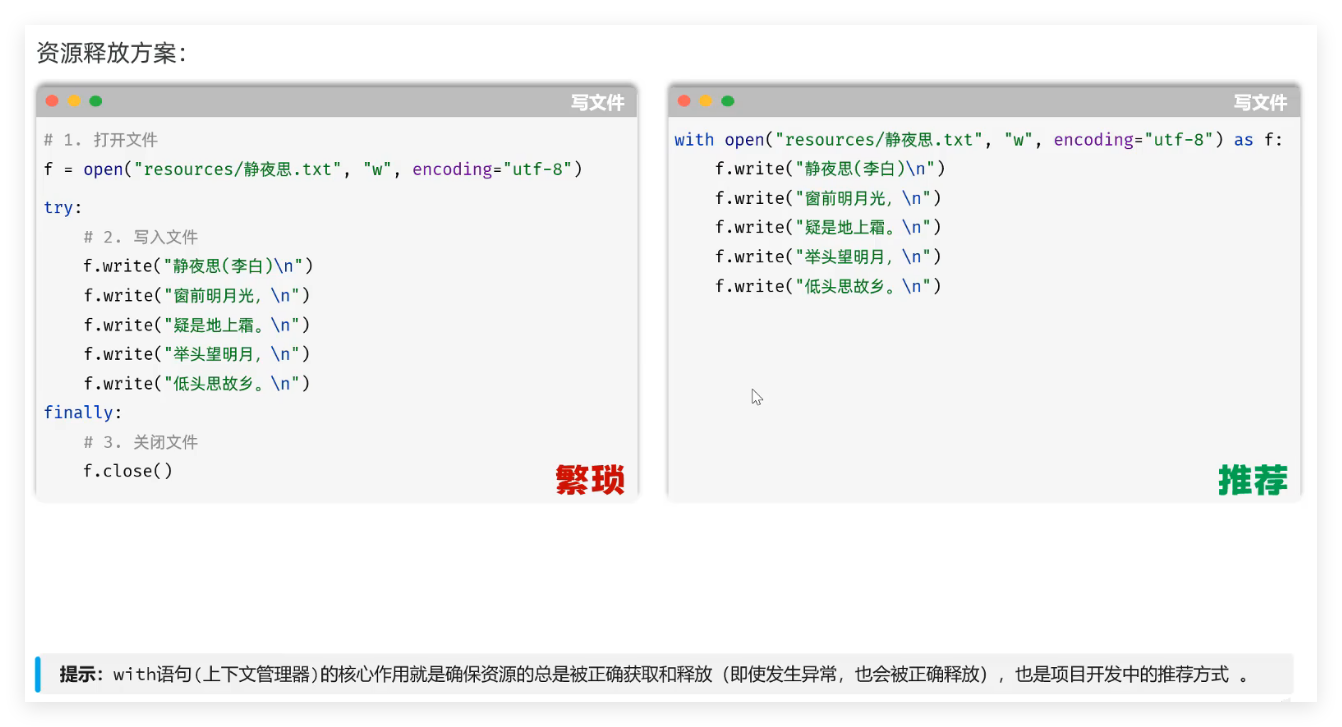
Python 操作文件的最佳实践是with 语句(上下文管理器),即使发生异常也能自动释放文件资源,结合json模块实现 JSON 文件的读写:
JSON是软件开发中最常用的数据交换格式,而为了简化JSON数据的处理,在Python标准库中就提供了处理JSON数据的核心模块json。
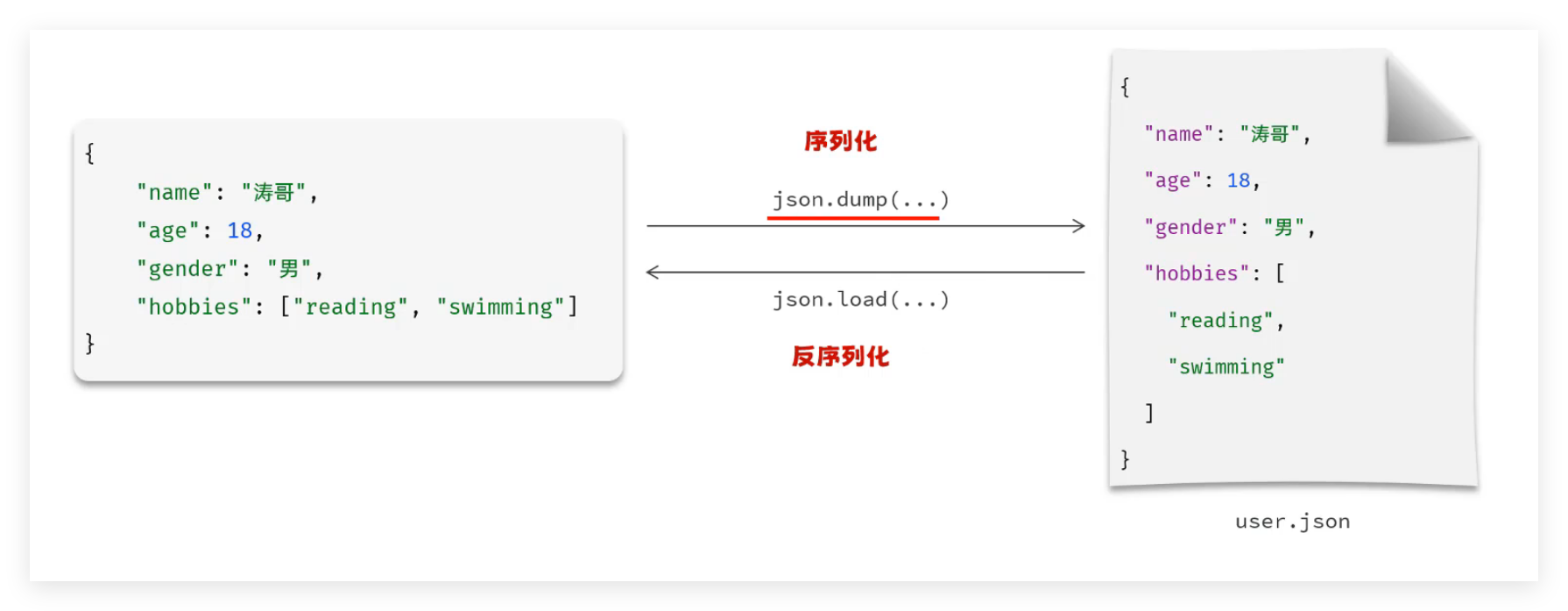
语法参考:
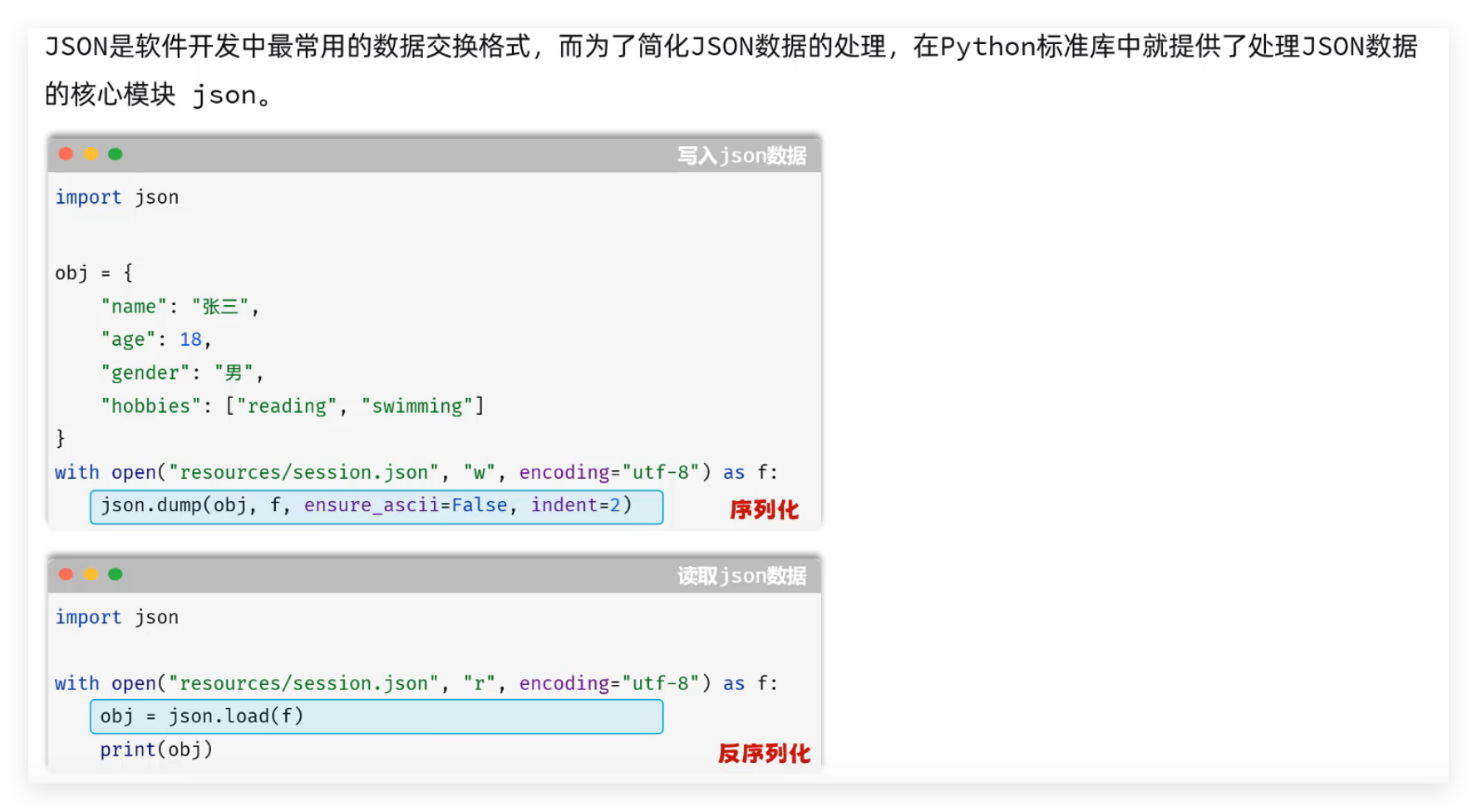
代码参考:
import json
# 写入json数据文件
user = {
"name": "zheng哥",
"age": 18,
"gender": "男",
"hobbies": ["reading", "swimming"]
}
with open("resources/user.json", "w", encoding="utf-8") as f:
# ensure_ascii: 默认为True, 确保所有的数据输出的数据都是ascii编码(非ASCII码会进行转义); False, 非ASCII码保留原样输出
# indent: 会在输出的json数据中添加缩进(格式化)
json.dump(user, f, ensure_ascii=False, indent=2)
# 读取json数据文件
with open("resources/user.json", "r", encoding="utf-8") as f:
user = json.load(f)
print(user)
print(type(user))- 写入 JSON 文件(序列化):将 Python 字典保存为 JSON 文件
运行
import json
import datetime
# 构造会话数据
session_data = {
"messages": st.session_state.messages,
"nick_name": "小美",
"nature": "温柔可爱的台湾腔姑娘",
"current_session": datetime.datetime.now().strftime("%Y-%m-%d_%H-%M-%S")
}
# 写入JSON文件
with open(f"session/{session_data['current_session']}.json", "w", encoding="utf-8") as f:
json.dump(session_data, f, ensure_ascii=False, indent=2)
- 读取 JSON 文件(反序列化):将 JSON 文件解析为 Python 字典
运行
import json
# 读取历史会话文件
with open("session/2026-01-09_16-05-20.json", "r", encoding="utf-8") as f:
session_data = json.load(f)
# 加载到会话状态
st.session_state.messages = session_data["messages"]
st.session_state.nick_name = session_data["nick_name"]
st.session_state.nature = session_data["nature"]
3.2.3.3 会话管理核心逻辑
- 新建会话:清空
st.session_state中的历史消息,重新初始化; - 保存会话:将当前会话数据写入本地 JSON 文件,存放至指定
session文件夹;# 新建会话 if st.button("新建会话", width="stretch", icon="✏️"): # 1. 保存当前会话信息 save_session() # 2. 创建新的会话 if st.session_state.messages: # 如果聊天信息非空, True; 否则, False st.session_state.messages = [] st.session_state.current_session = generate_session_name() save_session() st.rerun() # 重新运行当前页面 - 加载历史会话:遍历
session文件夹,获取所有 JSON 文件,选择指定文件解析并加载到会话状态;# 保存会话信息函数 def save_session(): if st.session_state.current_session: # 构建新的会话对象 session_data = { "nick_name": st.session_state.nick_name, "nature": st.session_state.nature, "current_session": st.session_state.current_session, "messages": st.session_state.messages } # 如果 sessions 目录不存在, 则创建 if not os.path.exists("sessions"): os.mkdir("sessions") # 保存会话数据 with open(f"sessions/{st.session_state.current_session}.json", "w", encoding="utf-8") as f: json.dump(session_data, f, ensure_ascii=False, indent=2) # 加载所有的会话列表信息 def load_sessions(): session_list = [] # 加载sessions目录下的文件 if os.path.exists("sessions"): file_list = os.listdir("sessions") for filename in file_list: if filename.endswith(".json"): session_list.append(filename[:-5]) return session_list # 会话历史 st.text("会话历史") session_list = load_sessions() for session in session_list: col1,col2 = st.columns([4,1]) with col1: # 加载会话信息 # 三元运算符: 如果条件为真, 则返回第一个表达式的值; 否则, 返回第二个表达式的值 --> 语法: 值1 if 条件 else 值2 if st.button(session, width="stretch", icon="📄", key=f"load_{session}", type="primary" if session == st.session_state.current_session else "secondary"): load_session(session) st.rerun() with col2: # 删除会话信息 if st.button("", width="stretch", icon="❌️", key=f"delete_{session}"): pass # 输出大模型返回的结果 (流式输出的解析方式) response_message = st.empty() # 创建一个空的组件, 用于展示大模型返回的结果 full_response = "" for chunk in response: if chunk.choices[0].delta.content is not None: content = chunk.choices[0].delta.content full_response += content response_message.chat_message("assistant").write(full_response) # 保存大模型返回的结果 st.session_state.messages.append({"role": "assistant", "content": full_response}) # 保存会话信息 save_session() - 删除历史会话:删除指定的 JSON 文件,刷新历史会话列表。
# 删除会话信息函数 def delete_session(session_name): try: if os.path.exists(f"sessions/{session_name}.json"): os.remove(f"sessions/{session_name}.json") # 删除文件 # 如果删除的是当前会话, 则需要更新消息列表 if session_name == st.session_state.current_session: st.session_state.messages = [] st.session_state.current_session = generate_session_name() except Exception: st.error("删除会话失败!") with col2: # 删除会话信息 if st.button("", width="stretch", icon="❌️", key=f"delete_{session}"): delete_session(session) st.rerun()
3.3 项目总结
AI 智能伴侣项目整合了 AI 应用开发的核心知识点,实现了从大模型调用到Web 页面构建,再到数据持久化的完整开发流程,核心技术栈:
- 大模型调用:DeepSeek API + openai 库;
- Web 开发:Streamlit;
- 数据持久化:文件操作 + json 模块;
- 核心功能:会话记忆、性格定制、会话管理。
通过该项目,可快速掌握 Python 开发 AI 应用的基本思路,后续可扩展多模型切换、语音交互、个性化推荐等功能。
四、开发必备知识扩展
在 AI 应用开发中,除了核心的 AI 和网络知识,还需掌握 Python 的基础开发技巧,重点补充文件操作和Python 包管理。
4.1 高级文件操作
4.1.1 文件操作模式
除了基础的r(读)、w(写),还有常用的a(追加)模式,核心区别:
w:覆盖写入,原有内容会被删除,文件不存在则创建;a:追加写入,新内容添加到文件末尾,文件不存在则创建。
4.1.2 路径写法
- 相对路径:相对于当前工作目录的路径(如
session/2026-01-09.json),推荐使用,可移植性强、简洁; - 绝对路径:从文件系统根目录开始的完整路径(如
C:/project/ai/session/2026-01-09.json),适用于固定部署场景。
4.2 Python 包管理工具:pip
Python 的第三方库均通过 pip 管理,核心命令:
- 安装包:
pip install 包名(最新版本)、pip install 包名==版本号(指定版本); - 卸载包:
pip uninstall 包名; - 查看已安装包:
pip list; - 查看包详情:
pip show 包名; - 升级 pip:
python -m pip install --upgrade pip。
五、总结与拓展
5.1 全文核心总结
本文从 AI 基础概念出发,讲解了大模型部署、大模型调用、提示词工程三大 AI 应用开发基础,通过AI 智能伴侣实战项目,完整演示了用 Python 构建 AI 应用的流程,核心要点:
- 大模型部署选择:小项目 / 快速开发选官方开放 API,对数据安全要求高选本地部署;
- 大模型调用关键:掌握 HTTP 协议、JSON 格式,通过 Apifox 测试后再进行代码开发;
- 会话记忆实现:会话历史滚雪球,携带完整上下文调用大模型;
- 提示词工程:定角色、明任务、设要求,让大模型输出更符合预期;
- Python 开发工具:Streamlit 快速构建 Web 页面,json 模块实现数据持久化,pip 管理第三方库。
5.2 应用拓展方向
掌握本文的基础后,可基于该框架开发更多实际的 AI 应用:
- AI 办公助手:实现文档摘要、PPT 生成、代码编写、邮件撰写;
- AI 教育助手:实现知识点讲解、作业批改、个性化刷题;
- AI 电商客服:实现商品咨询、订单查询、售后答疑;
- AI 内容创作:实现小说生成、文案撰写、短视频脚本创作。
5.3 学习建议
- 先掌握基础:网络知识、HTTP 协议、JSON 格式、Python 文件操作,这是 AI 接口调用的前提;
- 多练提示词:不同的提示词会带来完全不同的结果,多尝试、多优化,总结适合自己场景的提示词模板;
- 从小项目入手:先实现基础的聊天交互,再逐步添加会话记忆、数据持久化、个性化配置等功能;
- 关注大模型生态:主流大模型会持续更新功能和 API,及时关注官方文档,适配新特性。
AI 应用开发的核心是将大模型技术与实际场景结合,Python 作为入门简单、生态丰富的语言,是连接 AI 技术和实际应用的最佳桥梁。希望本文能帮助大家快速上手 Python AI 应用开发,让 AI 技术真正落地到实际工作和生活中。
项目链接:https://pan.baidu.com/s/1EM415Y7110u6SUNA0kNB1w?pwd=MNHZ


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)