Kafka 完整执行流程全解析:ZK 模式与 KRaft 模式核心链路与差异
Kafka 执行流程解析:ZK 与 KRaft 模式核心差异 摘要: Kafka 消息处理流程包含生产者发送、集群存储同步和消费者消费三大环节,支持 Zookeeper 和 KRaft 两种元数据管理模式。ZK 模式下依赖外部 ZK 集群管理元数据,由 Controller Broker 调度;KRaft 模式则通过内部 Raft 协议实现元数据管理,完全去中心化。两种模式的核心差异在于集群初始化
Kafka 完整执行流程全解析:ZK 模式与 KRaft 模式核心链路与差异
Kafka 的核心执行流程围绕生产者发消息、集群存储与同步、消费者消费消息三大核心环节展开,结合 ZK 元数据管理、Controller 集群调度、副本高可用等机制,形成一套完整的分布式消息传输链路。
一、核心执行流程总览(极简版)
若为Zookeeper模式:
整体链路:生产者获取元数据 → 向 Partition Leader 发消息 → Leader 写入日志并同步至 Follower → 消费者获取元数据 + 分配分区 → 从 Leader 拉取消息 → 消费后提交 Offset,全程由 ZK 管理元数据、Controller 负责集群调度,核心规则为所有读写仅与 Leader 交互,Follower 仅后台同步。
ZK 集群(元数据中心)←→ Kafka Broker 集群(Controller 调度)
↑↓
生产者(发消息)→ Leader 副本(写日志)→ Follower 副本(同步日志)
↓
消费者组(拉消息)→ 消费处理 → 提交 Offset(记录消费位置)
若为KRaft模式:
整体链路:生产者获取元数据 → 向 Partition Leader 发消息 → Leader 写入日志并同步至 Follower → 消费者获取元数据 + 分配分区 → 从 Leader 拉取消息 → 消费后提交 Offset,全程由 KRaft 协议管理元数据、Controller Node 负责集群调度,元数据存储于 Kafka 内部专用 Topic,无外部依赖。
Kafka 集群(Controller Node 调度 + Raft 元数据管理)
↑↓
生产者(发消息)→ Leader 副本(写日志)→ Follower 副本(同步日志)
↓
消费者组(拉消息)→ 消费处理 → 提交 Offset(记录消费位置)
二、分阶段详细执行流程
以下按集群初始化→生产者发送消息→集群内部数据同步→消费者消费消息→故障容灾(Leader 切换) 分阶段拆解,每个阶段明确组件职责和交互逻辑。
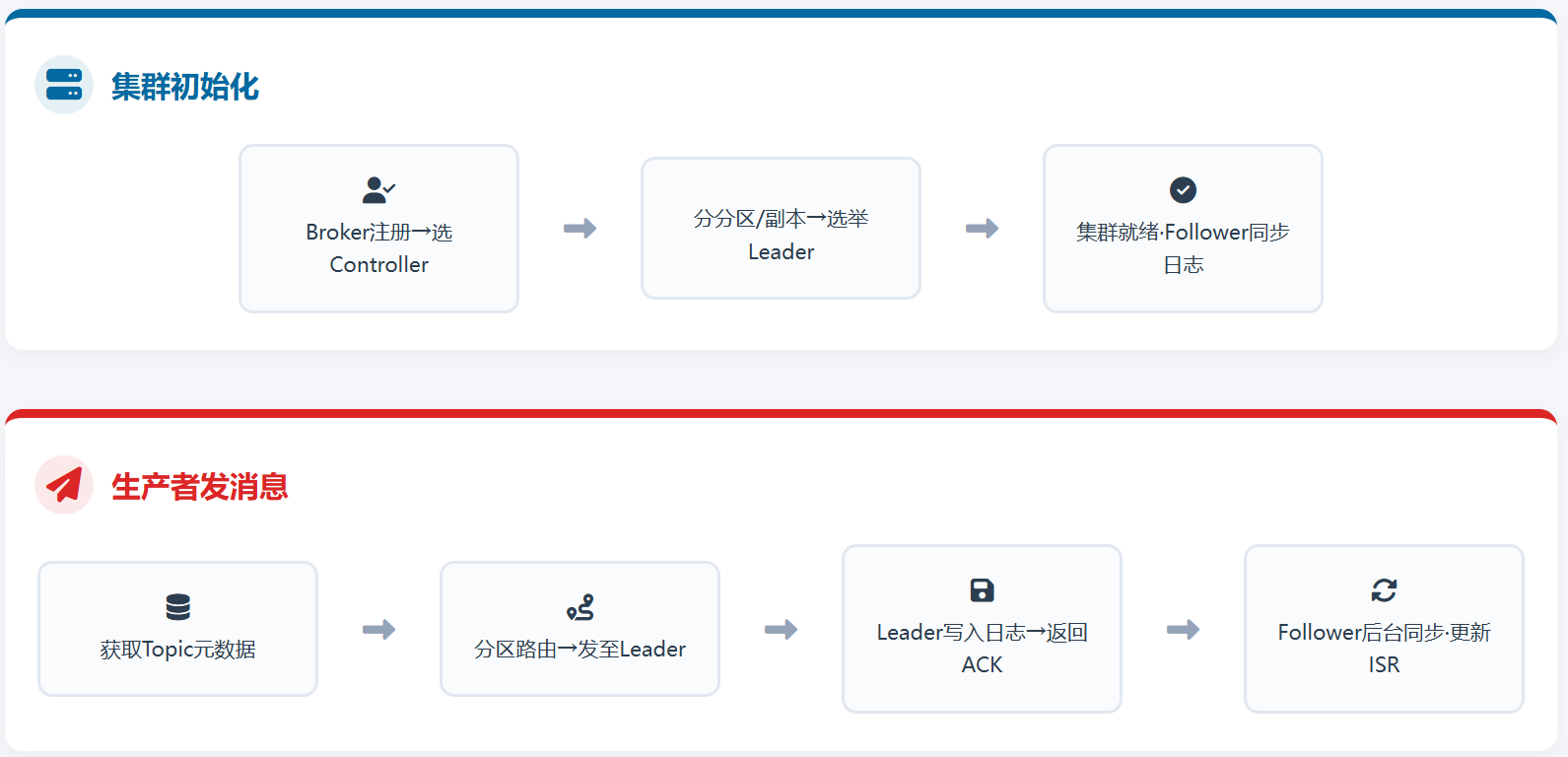
阶段 1:Kafka 集群初始化(前置准备,仅启动时执行)
若为Zookeeper模式:
集群启动是所有操作的基础,核心完成元数据注册、Controller 选举、副本初始化,依赖 ZK 实现集群协同:
- 所有 Broker 启动后,向 ZooKeeper 集群注册自身节点(含 Broker ID、IP / 端口),ZK 维护可用 Broker 列表;
- ZK 从所有可用 Broker 中选举 1 个作为 Controller Broker(集群管理者),并将选举结果存储在 ZK 节点中;
- 管理员创建 Topic 时,指定分区数(Partition) 和副本数(Replica),Controller 接收到 Topic 配置后,将 Partition 及其副本均匀分配到不同 Broker(同一份副本不存同一 Broker,保证高可用);
- Controller 为每个 Partition选举 1 个 Leader 副本(其余为 Follower 副本),并将「Topic-Partition-Leader 对应关系、ISR 列表(同步副本集)」等元数据同步至 ZK 和所有 Broker;
- 各 Broker 初始化本地 Partition 日志文件,Follower 副本开始后台向对应 Leader 副本发起同步请求,进入数据同步状态。
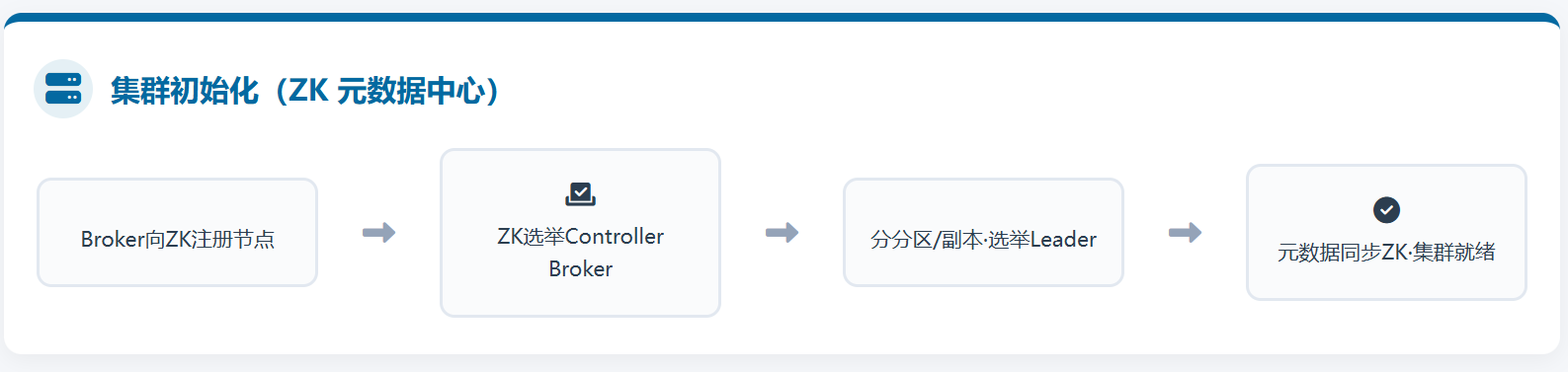
若为KRaft模式:
集群启动核心完成节点角色初始化、Raft 集群组建、元数据初始化、副本调度,全程无外部依赖,由 Kafka 自身 Controller Node 通过 Raft 协议实现集群协同,核心是组建 Raft 控集群,由 Controller Node 统一管理所有元数据:
- 节点启动与角色识别:所有节点启动,根据配置识别角色(Combined Node:兼任 Controller Node 和 Broker Node,生产环境推荐;纯 Controller Node:仅做集群管理;纯 Broker Node:仅做消息存储 / 传输),Controller Node 至少 3 个(保证 Raft 集群高可用);
- Raft 控集群组建:所有 Controller Node 通过 Raft 协议完成集群选主,选举出 1 个 Leader Controller(主控制器)和若干 Follower Controller(从控制器),Leader Controller 负责所有元数据的写入 / 调度,Follower Controller 同步元数据,保证元数据一致性;
- Broker 节点注册:所有 Broker Node(含 Combined Node 中的 Broker 角色)向Leader Controller发送注册请求,提交自身 Broker ID、IP / 端口等信息,Leader Controller 维护集群可用 Broker 列表,并同步至所有 Controller Node 和 Broker Node;
- Topic 配置与分区 / 副本分配:管理员创建 Topic 时,指定分区数(Partition)和副本数(Replica),Leader Controller 接收到配置后,将 Partition 及其副本均匀分配到不同 Broker(同一份副本不存同一 Broker,保证高可用);
- Leader 副本选举与元数据同步:Leader Controller 为每个 Partition选举 1 个 Leader 副本(其余为 Follower 副本),生成「Topic-Partition-Leader 对应关系、ISR 列表(同步副本集)」等核心元数据,将元数据写入 Kafka 内部专用元数据 Topic(__cluster_metadata),由 Raft 协议同步至所有 Controller Node 和 Broker Node,所有节点缓存元数据;
- 副本初始化与同步启动:各 Broker 初始化本地 Partition 日志文件,Follower 副本开始后台向对应 Leader 副本发起同步请求,进入数据同步状态,完成集群初始化,等待生产 / 消费请求。
阶段 2:生产者发送消息(核心写流程)
生产者(Producer)仅与 Partition 的 Leader 副本交互,核心完成元数据获取、消息分区、发送与确认,支持批量、幂等发送,步骤如下:
- 生产者初始化:加载配置(Broker 地址、序列化器等),创建 KafkaProducer 实例,向任意一个可用 Broker 发送元数据请求(查询目标 Topic 的 Partition 列表、每个 Partition 的 Leader 副本所在 Broker);
- Broker 返还元数据:接收请求的 Broker 从本地缓存(或从 ZK/Controller 获取)目标 Topic 的元数据,返回给生产者(含 Partition 分布、Leader 地址);
- 消息分区路由:生产者通过内置分区器确定消息归属的 Partition(规则:指定 Key 则按 Key 哈希分区;未指定则轮询分区,保证负载均衡);
- 发送消息至 Leader:生产者直接向「目标 Partition 的 Leader 副本所在 Broker」发送消息(可配置批量发送,攒够指定大小 / 时间后一次性发送,提升吞吐);
- Leader 写入并确认:Leader 副本接收到消息后,将消息按顺序写入本地磁盘的 Partition 日志文件(磁盘顺序写,高性能),并根据生产者配置的 acks规则返回确认(ACK):
acks=1(生产环境常用):Leader 写入成功即返回 ACK,生产者收到后认为发送成功;acks=all(最高可用):Leader 写入成功且ISR 列表中所有 Follower 同步完成后,才返回 ACK;
- 生产者处理结果:收到 ACK 则完成发送;发送失败则根据配置的重试次数重新发送,保证消息尽可能送达。
阶段 3:集群内部数据同步(高可用保障,后台异步执行)
Follower 副本的唯一核心工作是同步 Leader 消息,保证 Leader 故障时能无缝接管,核心依赖ISR 同步副本集机制,步骤如下:
- Follower 副本启动后,持续向对应 Leader 副本发送拉取请求(请求同步最新的消息日志);
- Leader 副本接收到拉取请求后,将本地未同步的消息日志返回给 Follower;
- Follower 副本将接收到的消息按顺序写入本地 Partition 日志文件,完成后向 Leader 反馈同步成功;
- ISR 列表维护:Leader 实时监控所有 Follower 的同步延迟,将同步延迟在阈值内的 Follower 加入 ISR 列表(同步副本集),延迟超出阈值则移出;只有 ISR 中的 Follower 有资格参与后续 Leader 选举;
- 同步完成后,Follower 副本处于「数据与 Leader 一致」的就绪状态,等待 Leader 故障时的选举触发。
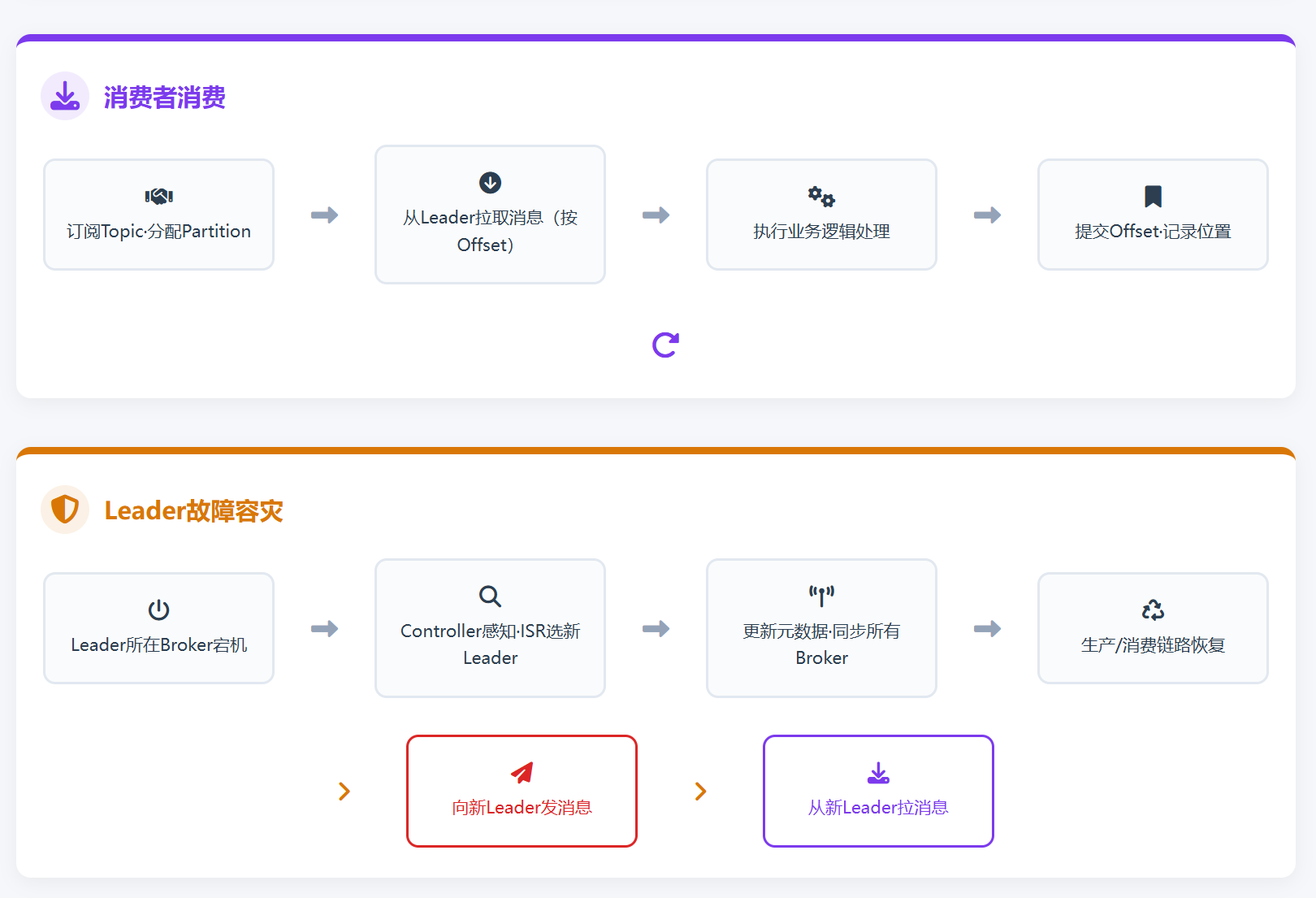
阶段 4:消费者消费消息(核心读流程)
消费者(Consumer)以消费者组(Consumer Group) 为单位消费,核心完成元数据获取、分区分配、拉取消息、消费与 Offset 提交,严格遵循「一个 Partition 仅被组内一个消费者消费」的规则,步骤如下:
- 消费者组初始化:组内所有消费者启动后,加载配置(Broker 地址、反序列化器、Group ID 等),向任意可用 Broker 发送订阅请求(订阅目标 Topic)和元数据请求;
- 分区分配:Controller(或 Broker 协调器)根据「Topic 分区数、消费者组内消费者数量」,将目标 Topic 的 Partition均匀分配给组内消费者(分配规则:分区数 ≤ 消费者数时,每个消费者分配 1 个或多个分区;分区数 > 消费者数时,多余消费者空闲);
- 拉取消息:消费者向「分配到的 Partition 的 Leader 副本所在 Broker」发送拉取请求,指定要拉取的Offset 范围(即从哪个位置开始消费,首次消费则按配置
auto.offset.reset确定:earliest从最开始,latest从最新消息); - Broker 返还消息:Leader 副本从本地日志文件中读取对应 Offset 范围的消息,返回给消费者(包含消息内容、Topic、Partition、Offset 等信息);
- 消费者处理消息:消费者接收到消息后,执行业务逻辑处理(如写入数据库、调用微服务、日志分析等);
- Offset 提交:处理完成后,消费者提交 Offset(记录消费位置),告知 Kafka「该 Partition 已消费到某个 Offset,后续从该位置下一条开始拉取」,提交方式分两种:
- 自动提交:按配置的时间间隔自动提交,简单但可能出现「消费未完成但 Offset 已提交」导致消息丢失;
- 手动提交:消费业务处理完成后手动调用 API 提交,生产环境推荐,保证消息「消费成功才提交 Offset」,避免丢失;
- 持续轮询消费:消费者通过无限循环 Poll 方式持续拉取消息,实现实时消费,若暂无消息则按配置的超时时间等待后返回空集合。
阶段 5:故障容灾流程(Leader 副本宕机,高可用切换)
若为Zookeeper模式:
当某个 Partition 的 Leader 副本所在 Broker 宕机(或 Leader 故障),Kafka 会触发自动 Leader 选举,全程对生产者 / 消费者几乎无感知,保证服务不中断、数据不丢失,步骤如下:
- 故障感知:ZK 实时监控所有 Broker 的心跳状态,Broker 宕机后 ZK 触发节点事件,Controller 立即感知到 Leader 副本所在 Broker 失效;
- 筛选候选副本:Controller 从失效 Partition 的ISR 列表中筛选候选 Follower 副本(仅同步完成的 Follower 有资格,保证数据一致性);
- 重新选举 Leader:Controller 从候选副本中选举 1 个作为新 Leader 副本(默认选举 ISR 中同步最及时的 Follower);
- 更新元数据:Controller 将「新 Leader 副本的位置、ISR 列表更新」等元数据,同步至 ZK 和所有剩余 Broker,更新集群元数据缓存;
- 通知生产 / 消费者:生产者 / 消费者再次发送元数据请求时,Broker 返还新的 Leader 副本地址;
- 服务恢复:生产者向新 Leader 发送消息,消费者从新 Leader 拉取消息,整个切换过程毫秒级完成,生产 / 消费链路无缝恢复,无人工干预。
若为KRaft模式:
当某个 Partition 的 Leader 副本所在 Broker 宕机(或 Leader 故障),Kafka 会触发自动 Leader 选举,全程对生产者 / 消费者几乎无感知,保证服务不中断、数据不丢失,步骤如下:
- 故障感知:Leader Controller 实时监控所有 Broker 的心跳状态(Broker 定时向 Controller 发送心跳),Broker 宕机后心跳中断,Leader Controller 立即感知到 Leader 副本所在 Broker 失效;
- 筛选候选副本:Leader Controller 从失效 Partition 的ISR 列表中筛选候选 Follower 副本(仅同步完成的 Follower 有资格,保证数据一致性);
- 重新选举 Leader:Leader Controller 从候选副本中选举 1 个作为新 Leader 副本(默认选举 ISR 中同步最及时的 Follower);
- 更新元数据:Leader Controller 将「新 Leader 副本的位置、ISR 列表更新」等元数据,写入内部元数据 Topic(__cluster_metadata),由 Raft 协议同步至所有 Controller Node 和剩余 Broker,所有节点更新本地元数据缓存;
- 通知生产 / 消费者:生产者 / 消费者再次发送元数据请求时,Broker 返还新的 Leader 副本地址;
- 服务恢复:生产者向新 Leader 发送消息,消费者从新 Leader 拉取消息,整个切换过程毫秒级完成,生产 / 消费链路无缝恢复,无人工干预。
Kafka执行流程图解:
ZooKeeper经典模式与kRaft模式只有集群的初始化有区别分别是:
Zookeeper:
kRaft:

三、Kafka 执行流程的核心关键规则(贯穿全程)
所有流程均遵循以下核心规则,这是 Kafka 实现高吞吐、高可用、分布式的基础,也是理解流程的关键:
-
读写唯一入口:仅与 Leader 交互—— 生产者发送消息、消费者拉取消息,全程只与 Partition 的 Leader 副本交互,Follower 副本仅后台同步日志,不处理任何业务请求,简化客户端逻辑,提升读写性能;
-
Offset 分区内唯一——Offset 仅在 Partition 内部递增且唯一,不同 Partition 的 Offset 相互独立,消费者仅维护自己分配到的 Partition 的 Offset,互不影响;
-
消费者组分区独占—— 同一个消费者组内,一个 Partition 仅能被一个消费者消费,避免重复消费;不同消费者组可独立消费同一个 Topic,互不干扰(实现多副本消费);
-
副本分散存储—— 同一个 Partition 的多个副本,必须分散在不同的 Broker 上,避免单 Broker 宕机导致某个 Partition 的所有副本同时失效,保证数据高可用;
-
Leader 负载均衡—— 同一个 Topic 的不同 Partition 的 Leader 副本,会被均匀分配到不同的 Broker 上,避免单 Broker 成为所有读写的性能瓶颈,实现集群负载均衡;
-
元数据统一管理——ZooKeeper 作为唯一元数据中心,存储所有集群配置(Broker/Topic/Partition)、Controller 选举结果、消费者组 Offset 等,所有组件通过 ZK 实现元数据协同。
KRaft 模式下由Raft 协议保证元数据一致性,元数据写入仅由 Leader Controller 处理,同步至所有节点,避免元数据混乱。
四、KRaft 模式与 ZK 模式的流程核心差异
Kafka 2.8+ 推出的 KRaft 模式(无 ZK 依赖),核心执行流程(生产 / 消费 / 同步)与 ZK 模式完全一致,仅集群初始化和元数据管理环节不同,其余环节无感知,差异点如下:
- 元数据存储:移除 ZK 依赖,元数据存储在 Kafka 内部专用 Topic(__cluster_metadata) 中,由 Raft 协议保证元数据一致性;
- Controller 选举:无需 ZK 选举,由 Kafka 自身的Controller Node 节点通过 Raft 协议选举产生,集群分为 Combined 节点(兼任 Controller 和 Broker)和普通 Broker 节点;
- 集群初始化:Broker 启动后向 Controller Node 注册,而非 ZK,Topic 配置、分区分配、Leader 选举均由 Controller Node 直接处理,无需通过 ZK 中转;
- Offset 存储:消费者组 Offset 直接存储在 Kafka 内部 Topic(__consumer_offsets)中,与 ZK 模式一致,无变化。
差异点汇总表:
| 对比维度 | ZooKeeper 模式 | KRaft 模式(官方推荐) |
|---|---|---|
| 元数据存储位置 | 外部 Zookeeper 集群 | Kafka 内部专用 Topic(__cluster_metadata) |
| 元数据一致性保障 | ZK 集群共识机制 | Kafka 内置 Raft 协议 |
| 控制器选举 | 由 ZK 临时节点选举 Controller Broker | 由 Controller Node 通过 Raft 协议选举 Leader Controller |
| Broker 注册 | 向 ZK 集群注册自身信息 | 向 Leader Controller 注册自身信息 |
| 集群管理依赖 | 强依赖外部 ZK 集群,需单独部署维护 | 无外部依赖,由 Kafka 自身完成集群管理 |
| 元数据调度节点 | Controller Broker(单节点) | Leader Controller(Raft 集群主节点) |
| 集群扩展能力 | 受 ZK 性能限制,支持分区数有限 | 无外部瓶颈,支持百万级 Partition 扩展 |
五、执行流程极简总结(核心链路提炼)
-
集群启动(Zookeeper专属):Broker 注册 → 选举 Controller → 分配分区 / 副本 → 选举 Leader → Follower 开始同步;
集群启动(KRaft 专属):节点角色初始化 → Raft 控集群组建 & 选主 → Broker 向 Controller 注册 → 分配分区 / 副本 → 选举 Leader → Follower 开始同步;
-
生产者发消息:获取元数据 → 分区路由 → 发至 Leader → Leader 写入并返回 ACK → Follower 后台同步;
-
消费者消费:订阅 Topic → 分配分区 → 获取元数据 → 从 Leader 拉取消息 → 处理业务 → 提交 Offset;
→ 选举 Leader → Follower 开始同步; -
生产者发消息:获取元数据 → 分区路由 → 发至 Leader → Leader 写入并返回 ACK → Follower 后台同步;
-
消费者消费:订阅 Topic → 分配分区 → 获取元数据 → 从 Leader 拉取消息 → 处理业务 → 提交 Offset;
-
故障恢复:Leader 宕机 → Controller 感知 → 从 ISR 选举新 Leader → 更新元数据 → 生产 / 消费无缝切换。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)