多模态检索模型clip、vit 测试报告
本文对多模态检索模型在RK3588硬件平台上的性能进行了全面测试,使用COCO和MSVD数据集评估了包括SigLIP2、nllb-clip等7种主流模型。测试结果显示,ViT-SO400M-16-SigLIP2-384__webli表现最优,在图像到文本任务中R@10达0.927,文本到图像任务中R@10达0.815。nllb-clip系列在长尾数据检索中更具优势。人工验证表明模型在Immich环
·
多模态检索模型测试报告
一、测试环境
-
硬件平台:RK3588
-
测试系统:Immich 内部环境
-
测试数据集:
- 图像数据集:COCO,包含 5,000 张图片,25014条描述
- 视频数据集:MSVD,包含 1,970 个视频,1987条描述
-
测试方式:
- 自动化评测:采用标准检索指标(R@1、R@5、R@10、MedR、MnR)
- 人工验证:在 Immich 前端实际检索图片和视频
-
测试方法举例说明:
-
假设每条查询的“第一个真实相关结果”的名次分别是:
- Q1:1 对查询 Q1,正确答案出现在排序第 1 位
- Q2:7 对查询 Q2,正确答案出现在排序第 7 位
- Q3:2 对查询 Q3,正确答案出现在排序第 2 位
则:
- R@1:只有 Q1 命中 → 1/3 = 33.3%
- R@5:Q1、Q3 命中 → 2/3 = 66.7%
- R@10:三条都命中 → 3/3 = 100%
- MedR:median(1, 7, 2) = 2(越低越好)
- MnR:(1+7+2)/3 = 3.33(越低越好)
若每个查询有多个GT(如 Image→Text 有5个正确caption),先在该查询的排序列表里找到这5个GT的最小名次,用它参与 R@K / MedR / MnR 的统计。
-
二、测试模型与结果
| 任务方向 | 模型名称 | 数据集 | R@1 | R@5 | R@10 | MedR | MnR |
|---|---|---|---|---|---|---|---|
| Text→Image | clip-vit-large-patch14 | coco | 0.354 | 0.600 | 0.702 | 2 | 22.1 |
| Image→Text | clip-vit-large-patch14 | coco | 0.560 | 0.795 | 0.868 | 0 | 6.2 |
| Text→Image | ViT-SO400M-16-SigLIP2-384__webli | coco | 0.503 | 0.735 | 0.815 | 1 | 31.3 |
| Image→Text | ViT-SO400M-16-SigLIP2-384__webli | coco | 0.670 | 0.875 | 0.927 | 1 | 4.2 |
| Text→Image | nllb-clip-large-siglip__v1 | coco | 0.473 | 0.726 | 0.813 | 2 | 13.1 |
| Image→Text | nllb-clip-large-siglip__v1 | coco | 0.605 | 0.832 | 0.896 | 1 | 5.7 |
| Text→Image | nllb-clip-large-siglip__mrl | coco | 0.489 | 0.741 | 0.827 | 2 | 12.1 |
| Image→Text | nllb-clip-large-siglip__mrl | coco | 0.582 | 0.811 | 0.892 | 1 | 6.3 |
| Text→Image | ViT-B-32__openai | coco | 0.298 | 0.541 | 0.652 | 4 | 26.4 |
| Image→Text | ViT-B-32__openai | coco | 0.487 | 0.734 | 0.819 | 2 | 11.0 |
| Text→Image | ViT-L-16-SigLIP2-256__webli | coco | 0.492 | 0.729 | 0.811 | 2 | 31.4 |
| Image→Text | ViT-L-16-SigLIP2-256__webli | coco | 0.682 | 0.876 | 0.924 | 1 | 4.1 |
| Text→Image | XLM-Roberta-Large-Vit-B-16Plus | coco | 0.403 | 0.657 | 0.756 | 2 | 17.0 |
| Image→Text | XLM-Roberta-Large-Vit-B-16Plus | coco | 0.578 | 0.812 | 0.882 | 1 | 6.5 |
三、人工测试与实际表现
在 Immich 内部环境中,对 ViT-SO400M-16-SigLIP2-384__webli 模型进行了人工验证:
- 图片检索:所有目标图片均能被检索到。
- 少数未直接命中的情况,主要原因是数据集中存在大量相似图片,导致模型在首批结果中返回相似项。经过更换描述或调整检索方式后,目标图片/视频均能成功检索到。
四、结果分析
整体性能
- 在 Image→Text 任务中,SigLIP2 系列模型表现突出(R@10 可达 0.924~0.927),远高于 ViT-B-32 基线模型(0.819)。
- 在 Text→Image 任务中,ViT-SO400M-16-SigLIP2-384__webli 的性能最佳,R@10 达到 0.815,比 CLIP-L/14(0.702)提升显著。
不同模型对比
在本次 RK3588 硬件测试中,我们对多种主流模型进行了横向对比,涵盖 SigLIP2 系列、nllb-clip 系列、OpenAI 基线模型(ViT-B-32)、跨语言模型(XLM-Roberta-Large-ViT-B-16Plus) 等。以下从准确率、鲁棒性、多语言支持和实际应用四个角度进行分析:
1. SigLIP2 系列(ViT-SO400M-16-SigLIP2-384__webli、ViT-L-16-SigLIP2-256__webli)
- 准确率优势:
- Text→Image 的 R@10 为 0.815(SO400M)和 0.811(L-16)。
- Image→Text 的 R@10 分别为 0.927 和 0.924,在所有模型中最高。
- 排名指标:MedR 基本保持在 1,MnR 也在 4~31 范围,说明结果较为集中且排名靠前。
- 特点总结:
- 在图像检索和文本检索两种方向上均表现突出,尤其适合需要快速、精准检索的应用场景。
- 更大的 ViT-SO400M 在 Text→Image 上更强,而 ViT-L-16 在 Image→Text 上表现更好。
- 属于本次测试中整体性能最优的系列,推荐作为主力模型部署。
2. nllb-clip 系列(v1 与 mrl)
- 准确率表现:
- Text→Image 的 R@10 在 0.813~0.827,高于基线模型。
- Image→Text 的 R@10 在 0.892~0.896,接近 SigLIP2。
- 鲁棒性:
- MnR 仅在 5.7~13.1,比 SigLIP2 的 MnR(31.3/31.4)更低,说明在长尾检索中(大量相似图片时)更具优势。
- MedR 多数为 1~2,能保证前几个检索结果中出现目标。
- 特点总结:
- 综合性能良好,特别是在需要处理长尾数据或跨语言检索时,更具应用价值。
- 可以作为 SigLIP2 的补充模型,弥补其在长尾与多语言场景下的不足。
3. OpenAI 基线模型(ViT-B-32__openai)
- 准确率表现:
- Text→Image 的 R@10 为 0.652。
- Image→Text 的 R@10 为 0.819,明显落后于 SigLIP2 和 nllb-clip。
- 指标劣势:
- MedR 高达 4(Text→Image),MnR 也在 26.4/11.0,说明排名分散,检索不够稳定。
- 特点总结:
- 作为早期 CLIP 的代表模型,仅能作为对比基线,证明新一代 SigLIP2、nllb-clip 的性能提升。
- 不适合实际部署,但有助于做实验和回归测试。
4. XLM-Roberta-Large-ViT-B-16Plus
- 准确率表现:
- Text→Image 的 R@10 为 0.756。
- Image→Text 的 R@10 为 0.882,性能介于 SigLIP2 与基线模型之间。
- 跨语言能力:
- 结合 XLM-Roberta 的文本编码能力,更适合多语言场景,尤其在中文/英文混合检索时,理论上比纯英语训练的 CLIP 模型更有优势。
- 特点总结:
- 在单语言任务中不及 SigLIP2 和 nllb-clip,但在多语言环境下具备一定补充价值。
- 适合对跨国团队、多语言用户群体的支持场景。
5. 总体对比结论
- 性能第一:SigLIP2 系列(SO400M 和 L-16)在绝大多数指标上领先,R@10 接近 0.93,检索成功率极高。
- 长尾与鲁棒性:nllb-clip 系列 R@10 达到 0.89 左右,MnR 更低,更适合数据复杂、图片相似度高的环境。
- 跨语言应用:XLM-Roberta-Large-ViT-B-16Plus 在 R@10 上表现为 0.88,结合多语言支持,可与 SigLIP2 组合部署。
- 基线参考:ViT-B-32 的 R@10 仅为 0.65~0.82,明显不足,仅建议作为基线模型参考。
实际应用价值
- 在 RK3588 上运行上述模型均可实现稳定推理,配合 Immich 前端检索功能,用户能够高效完成图片和视频检索。
- 人工测试进一步验证了模型的可用性,表明即使在复杂检索场景下,通过调整检索描述,仍可有效定位目标资源。
五、结论
- ViT-SO400M-16-SigLIP2-384__webli 是当前在 RK3588 硬件与 Immich 平台中表现最佳的模型,推荐作为主力部署方案。
- nllb-clip 在多语言与长尾检索上有较好补充作用,可作为辅助模型。
- 基线模型(ViT-B-32) 仅适用于对比实验,不建议在实际应用中使用。
- 测试结果表明:在 Immich 内部部署的检索系统,能够有效支持图像和视频的跨模态检索需求。
六、 以下内容为在 Immich 系统中进行的实际测试结果。
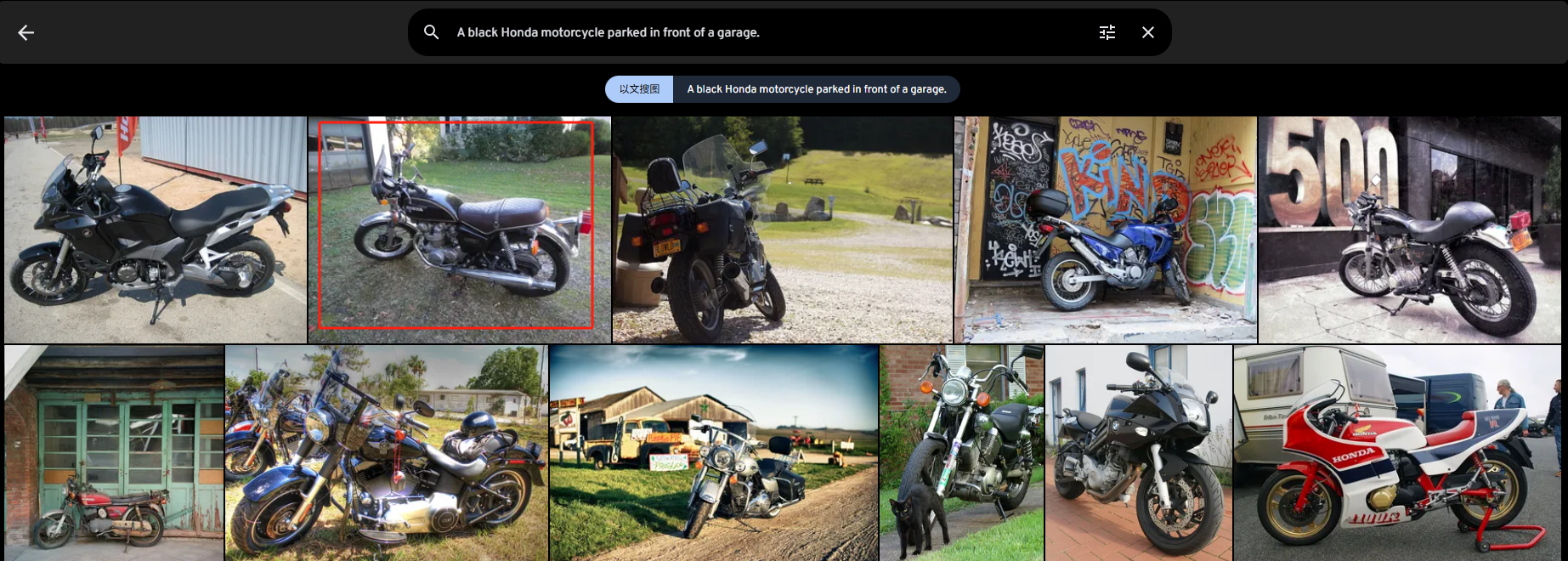
A black Honda motorcycle parked in front of a garage.
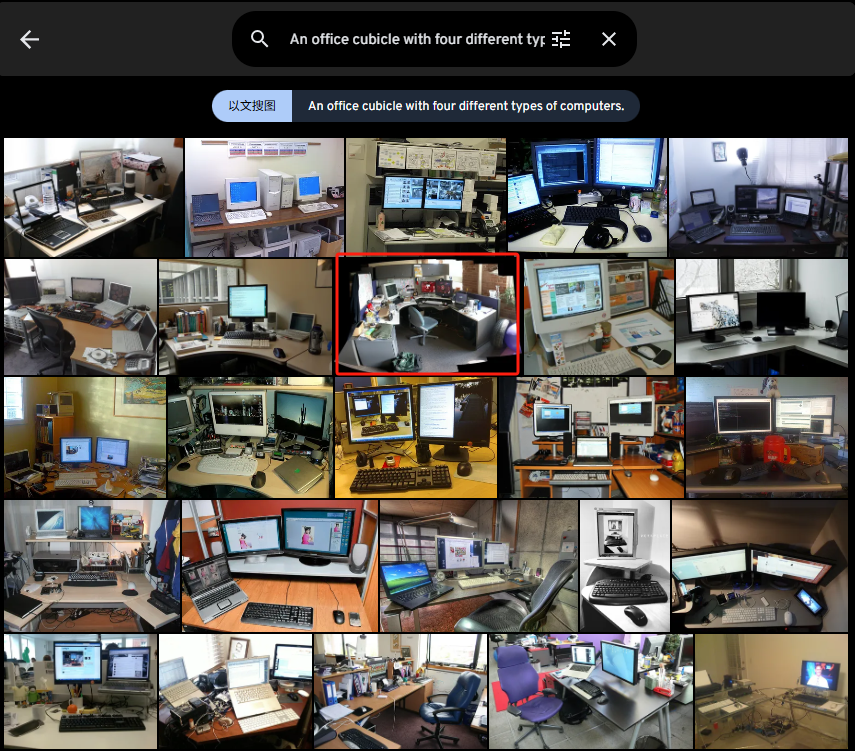
An office cubicle with four different types of computers.
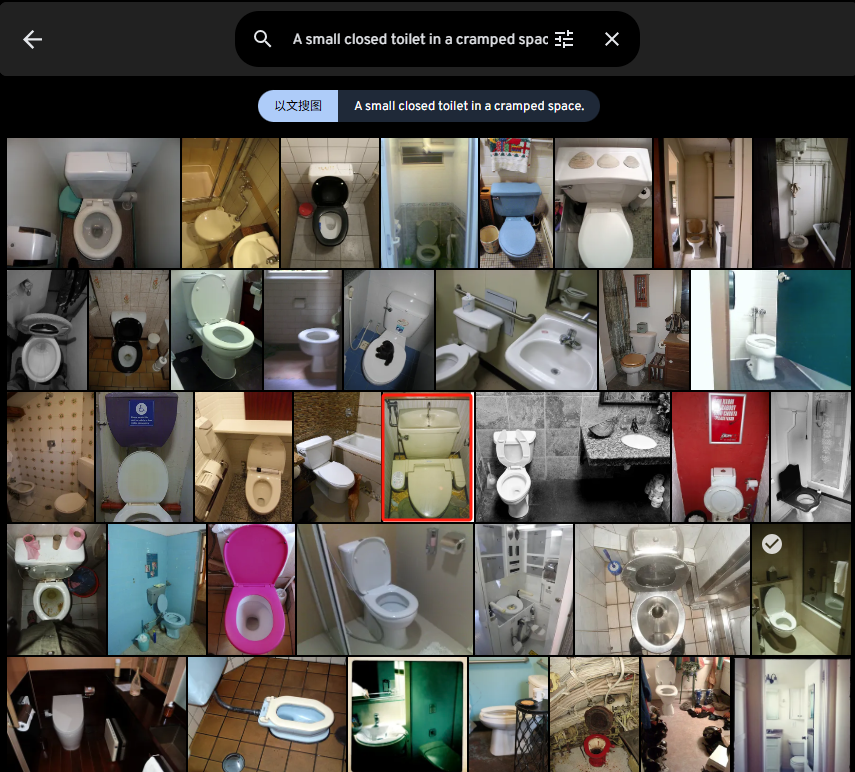
A small closed toilet in a cramped space.
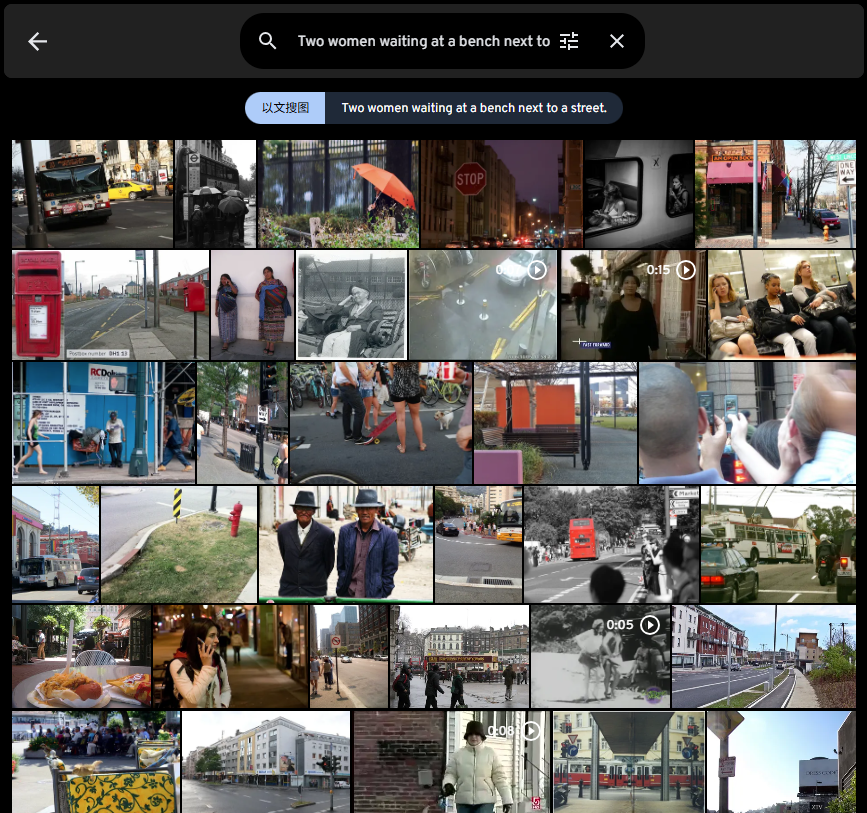
Two women waiting at a bench next to a street.(没有找到,相似的图片太多)
对应的图片

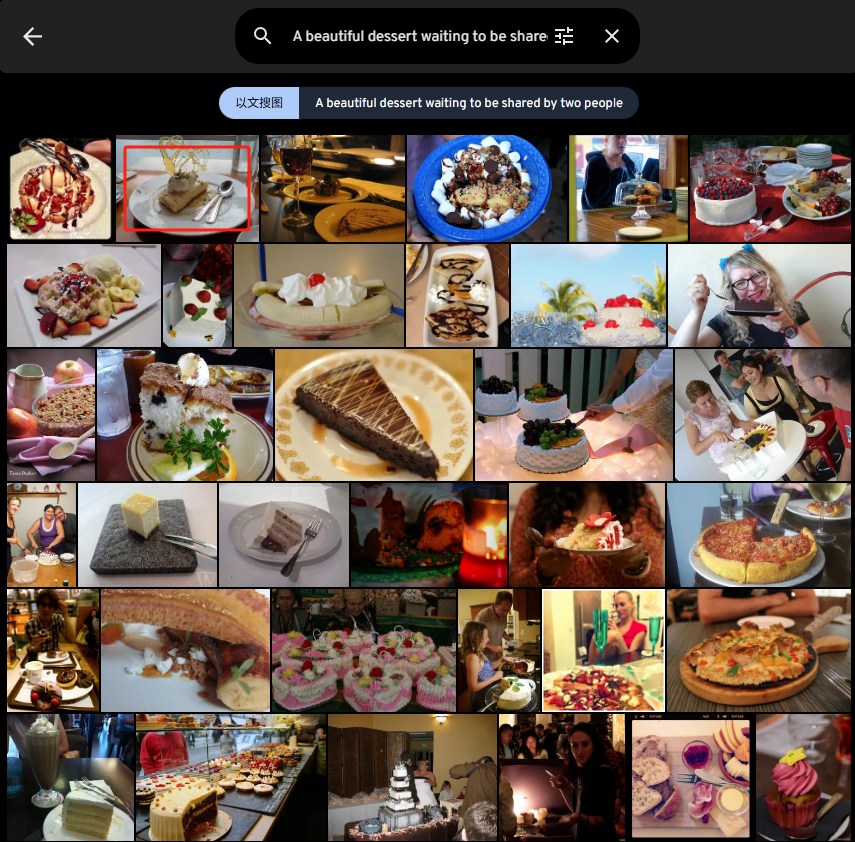
A beautiful dessert waiting to be shared by two people
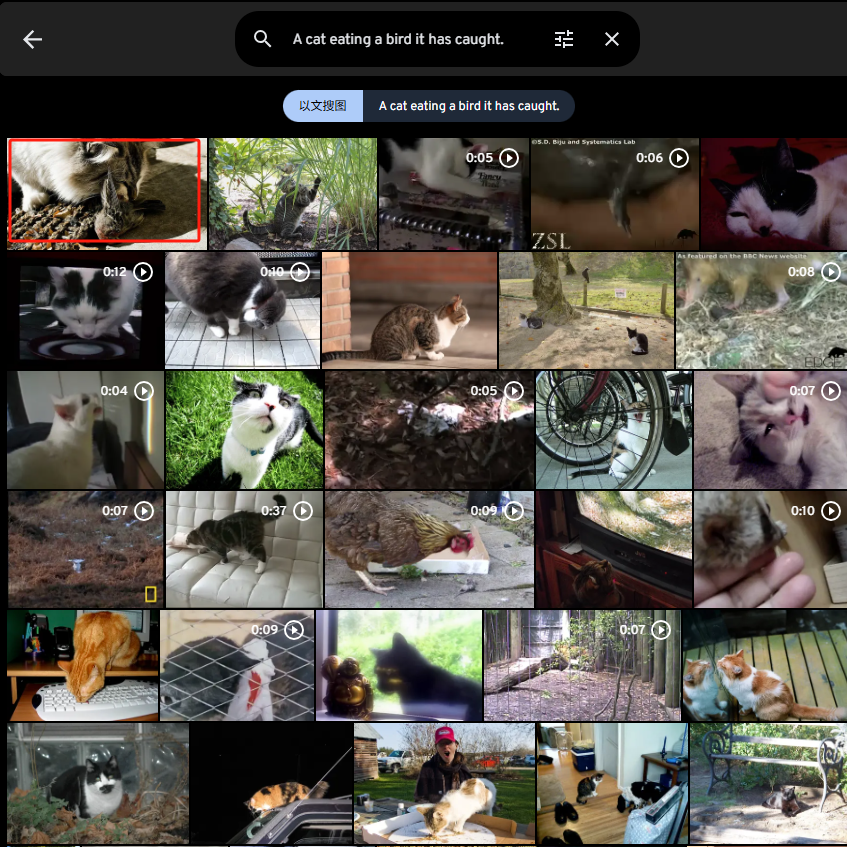
A cat eating a bird it has caught.
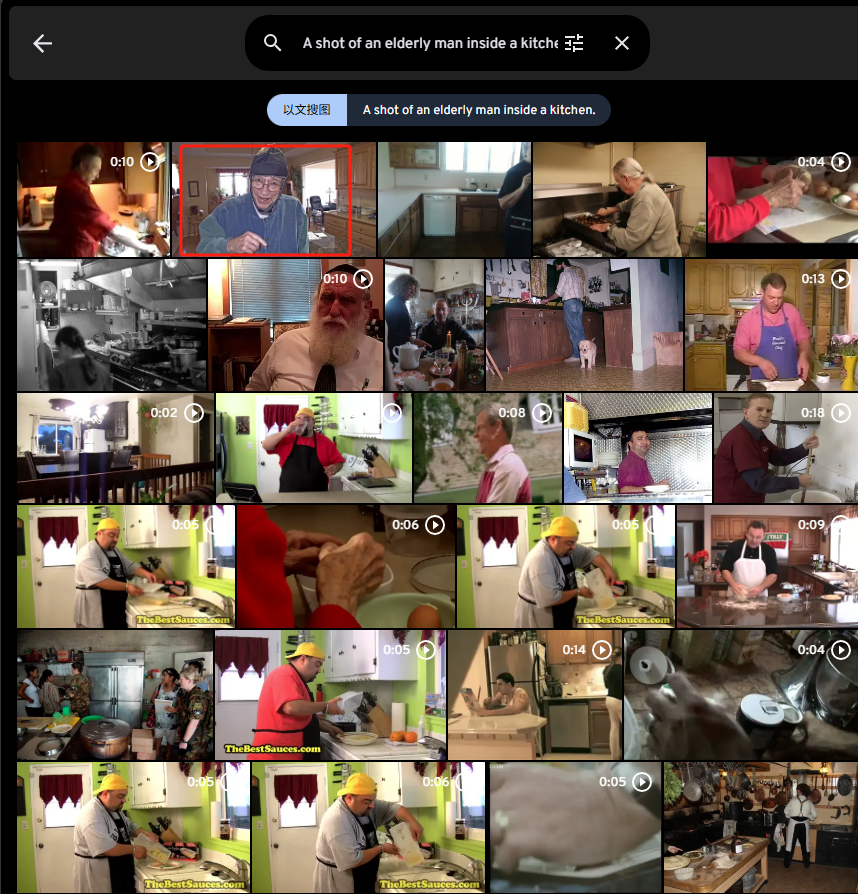
A shot of an elderly man inside a kitchen.
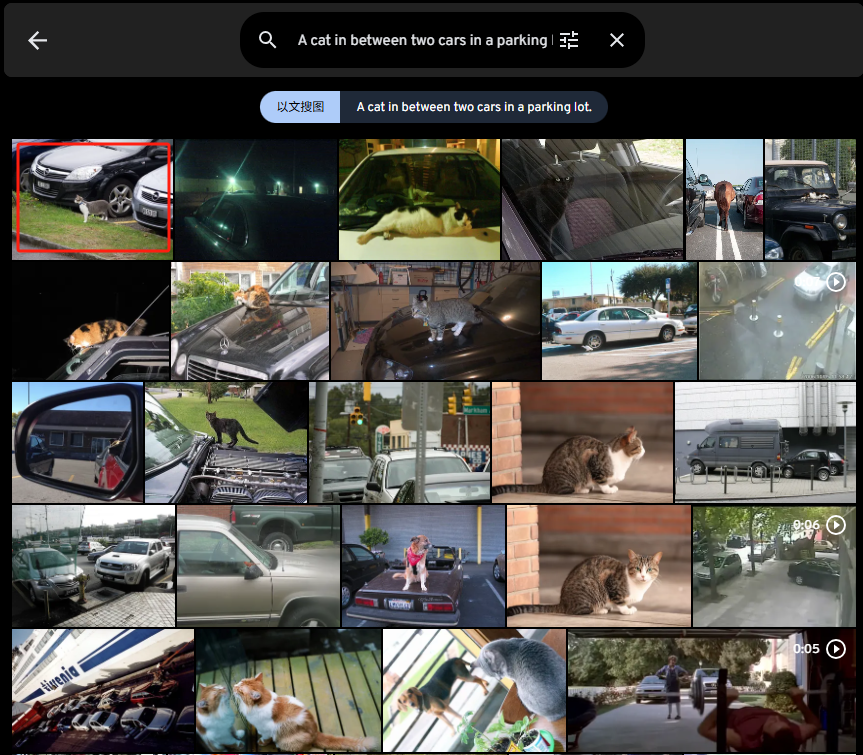
A cat in between two cars in a parking lot.
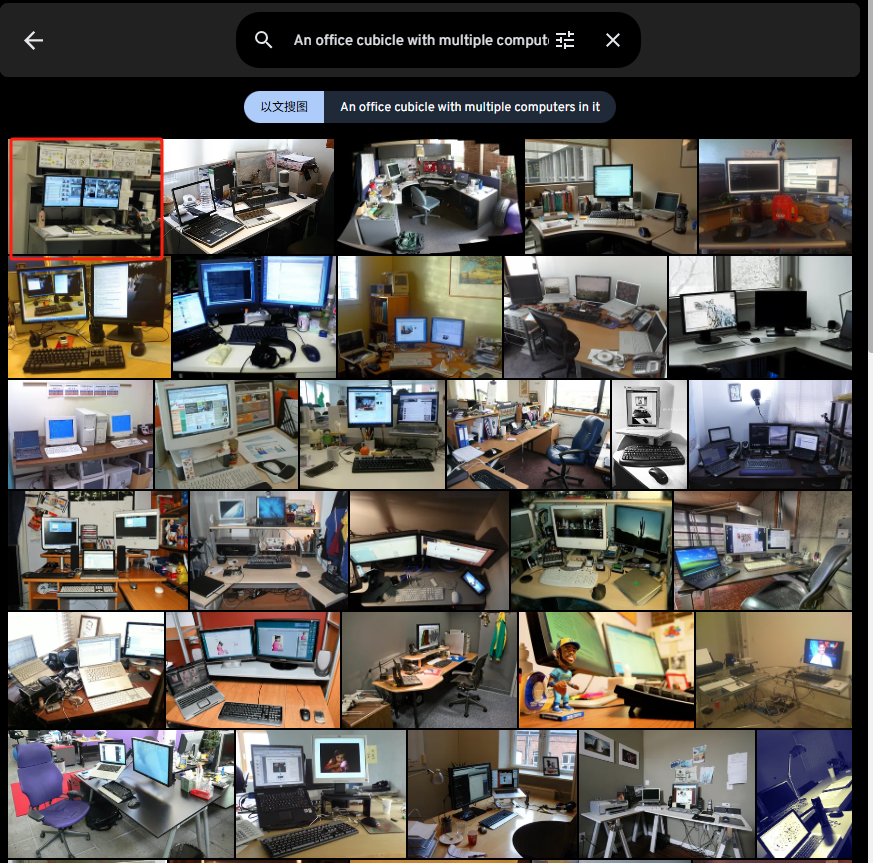
An office cubicle with multiple computers in it
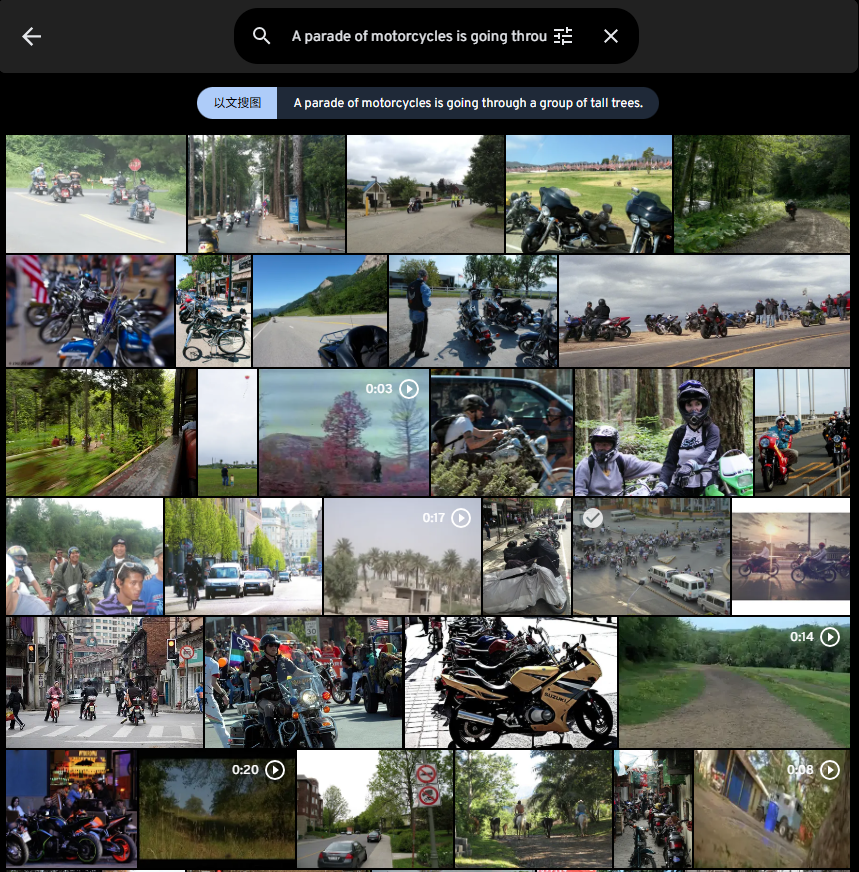
A parade of motorcycles is going through a group of tall trees.(没有找到,更换描述后找到。)
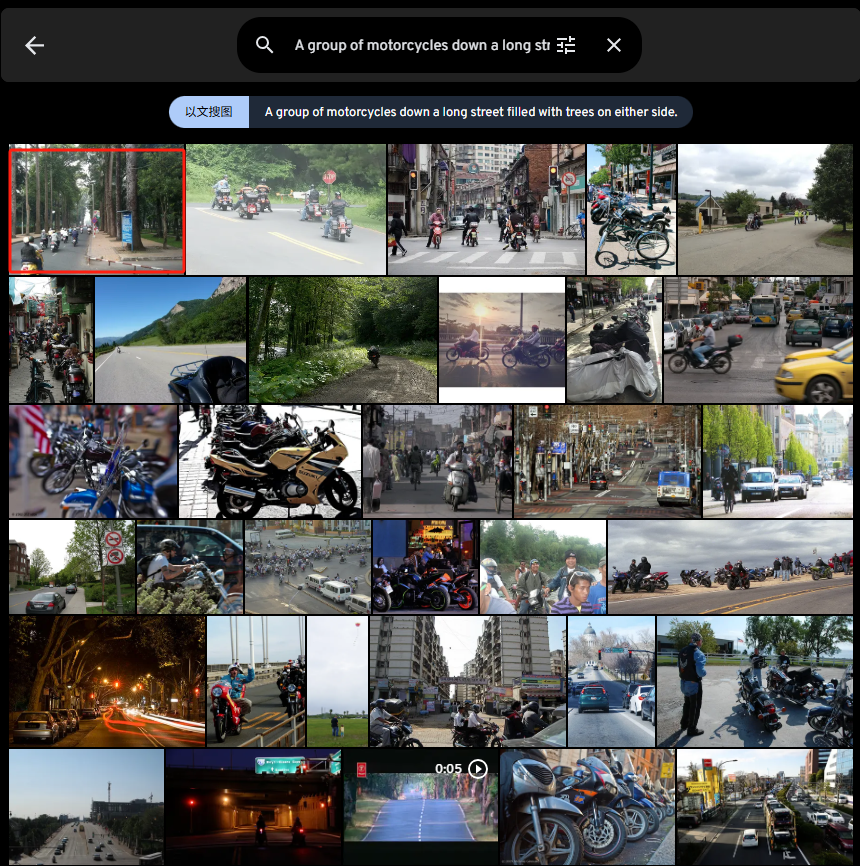
实际图片

A group of motorcycles down a long street filled with trees on either side.
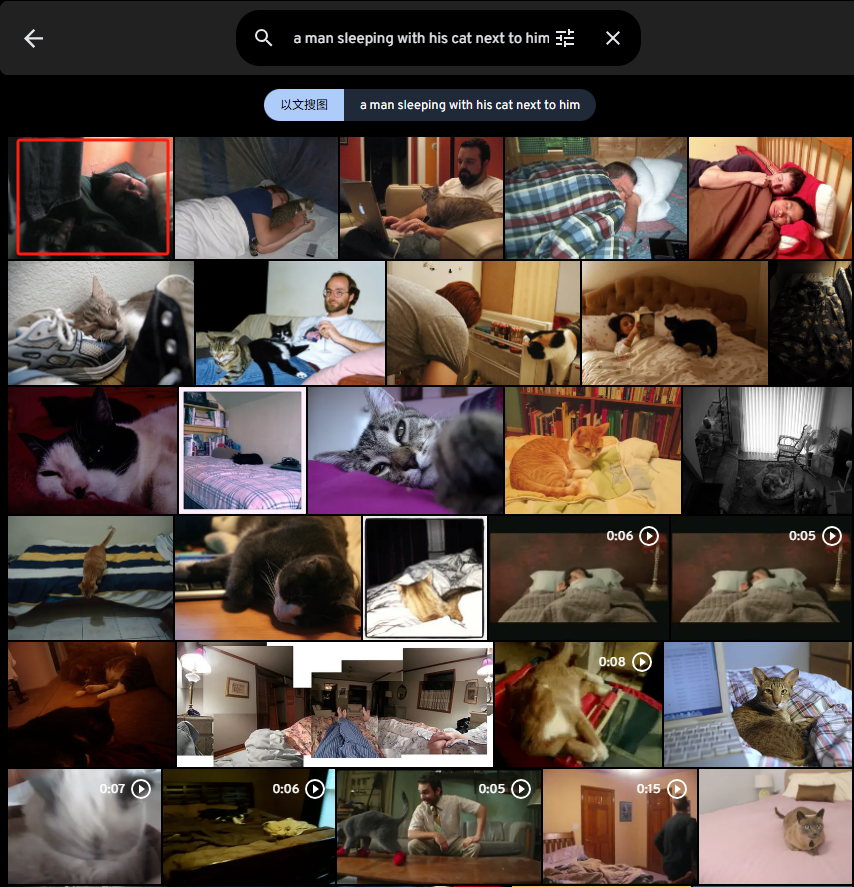
a man sleeping with his cat next to him
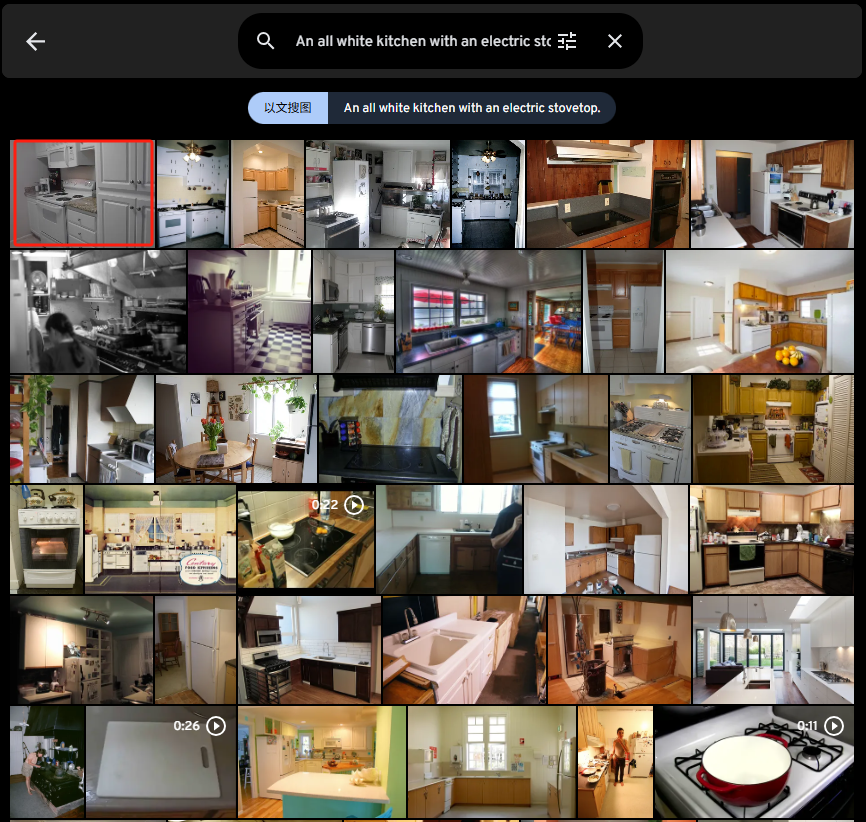
An all white kitchen with an electric stovetop.
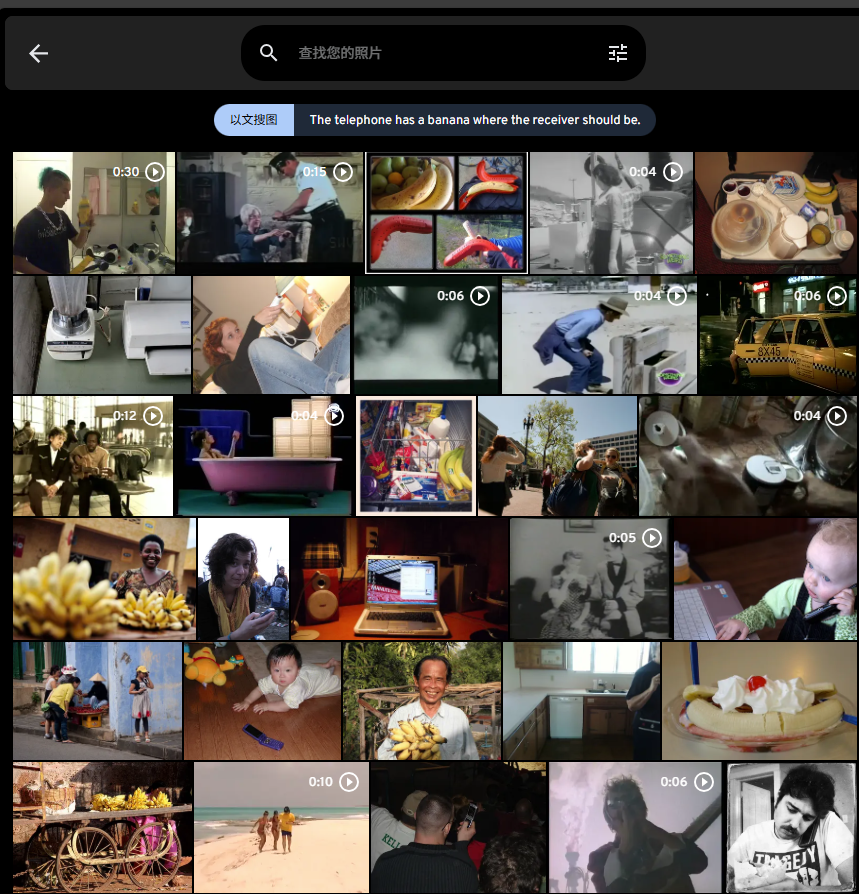
The telephone has a banana where the receiver should be.(没有找到,更换描述后找到。)
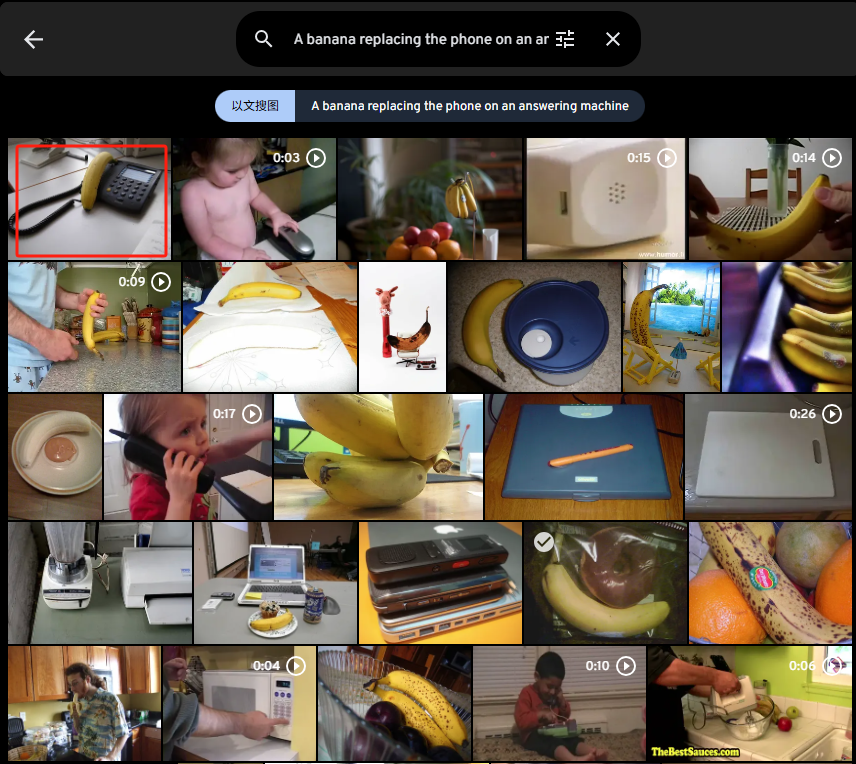
原图:

A banana replacing the phone on an answering machine
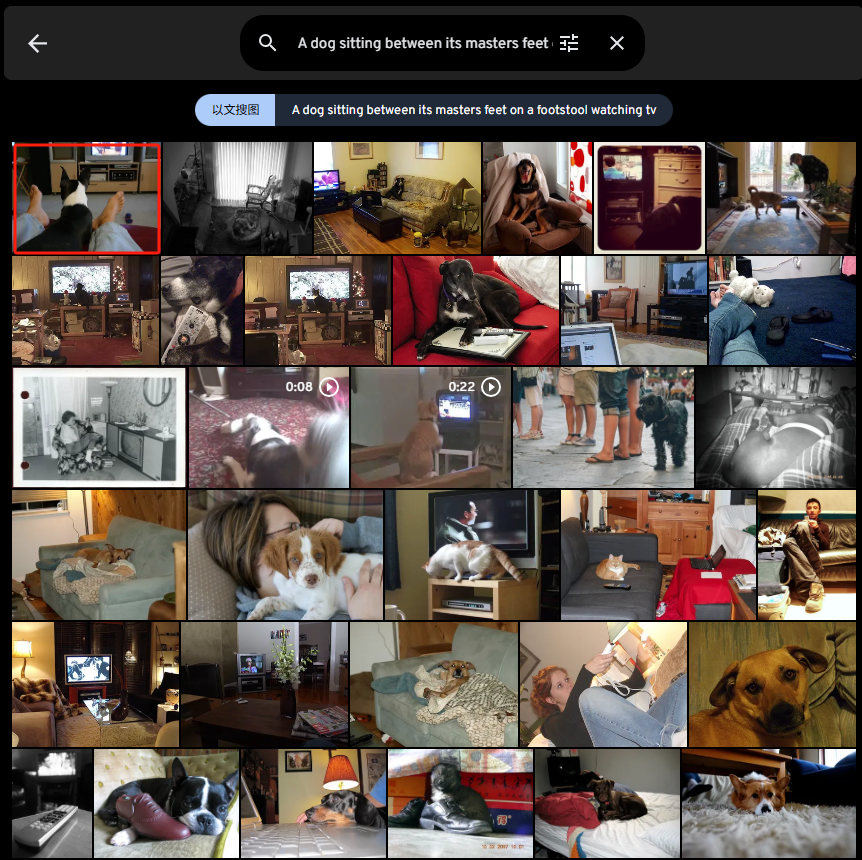
A dog sitting between its masters feet on a footstool watching tv
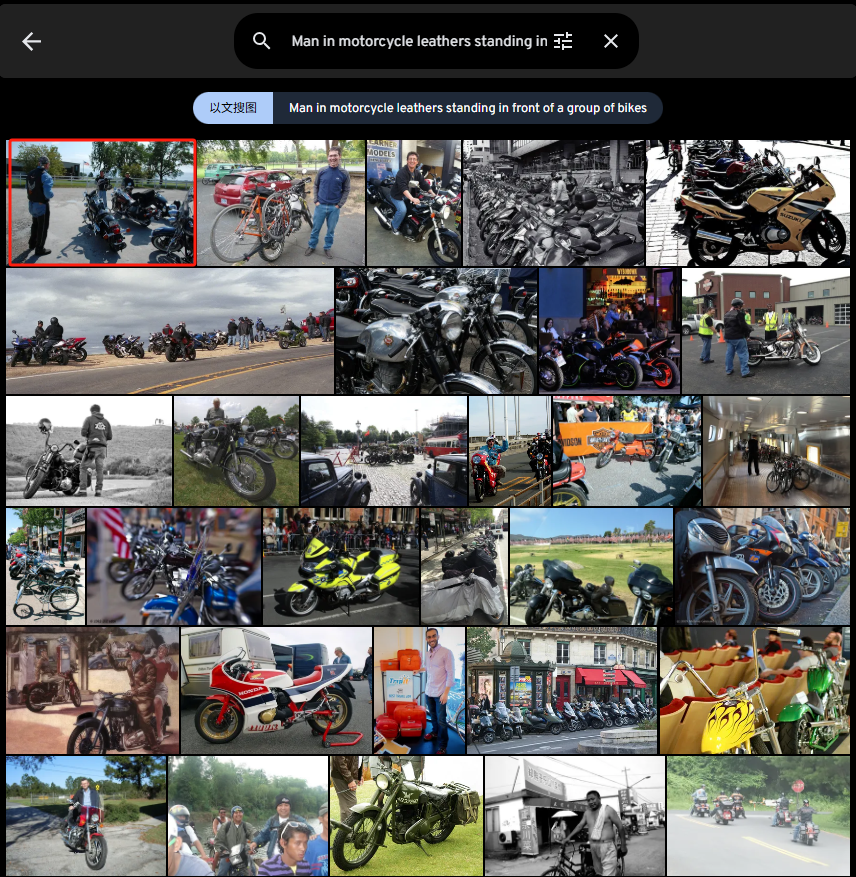
Man in motorcycle leathers standing in front of a group of bikes
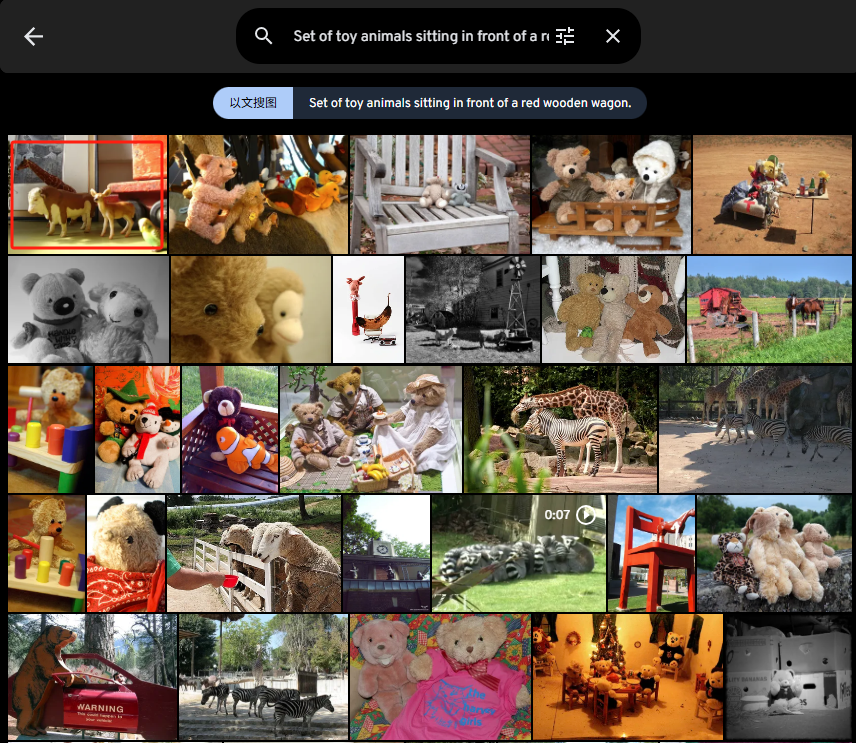
Set of toy animals sitting in front of a red wooden wagon.
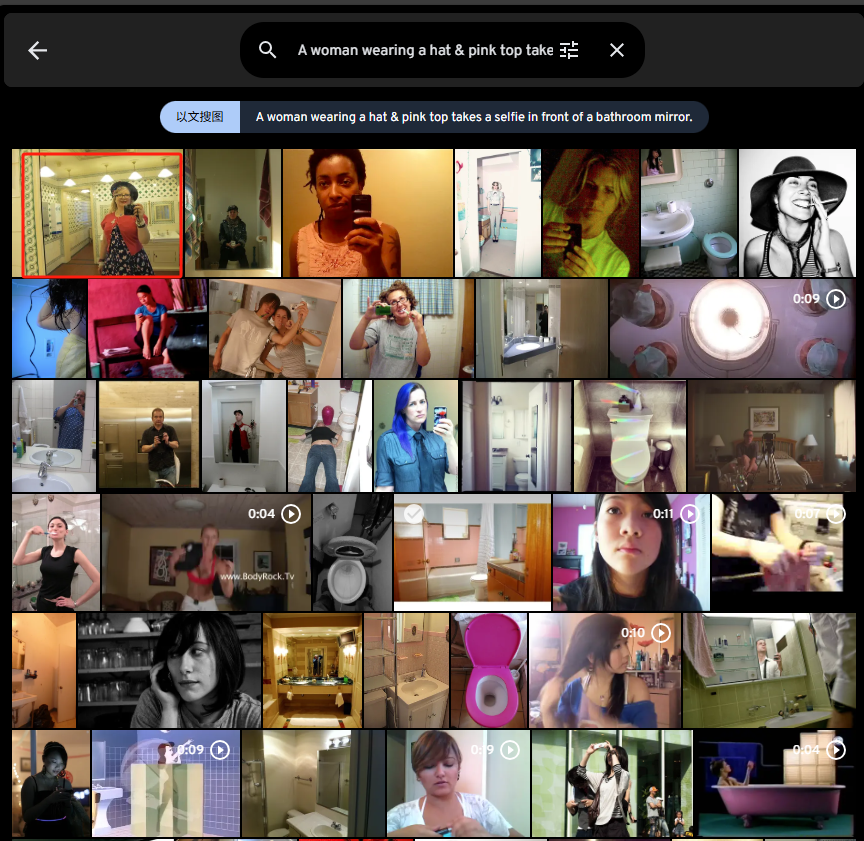
A woman wearing a hat & pink top takes a selfie in front of a bathroom mirror.
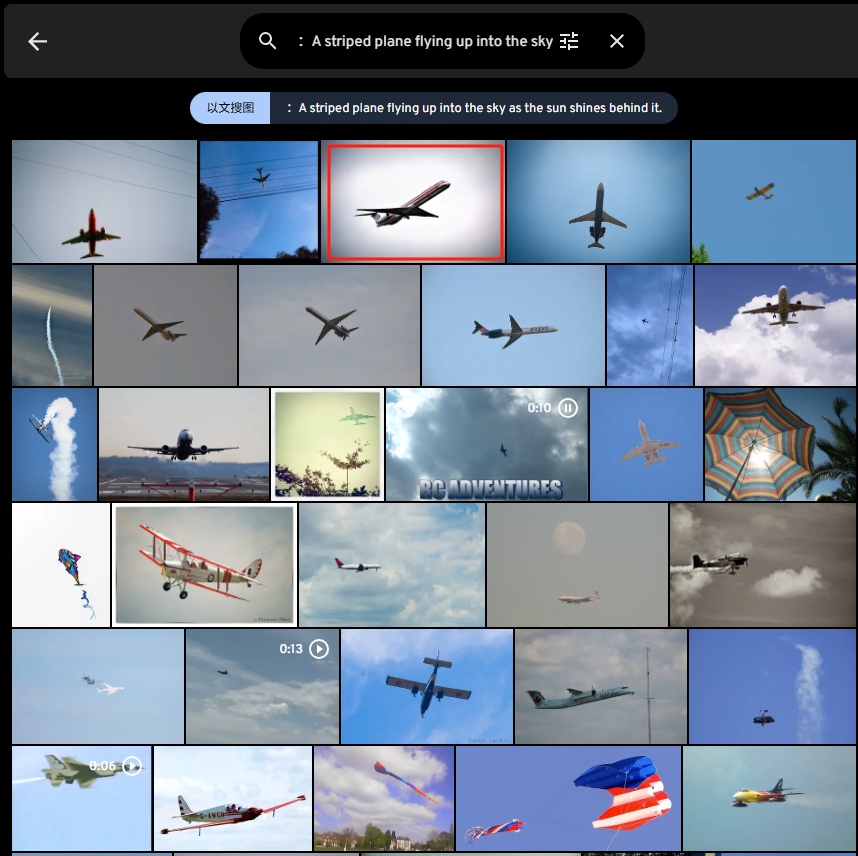
A striped plane flying up into the sky as the sun shines behind it.
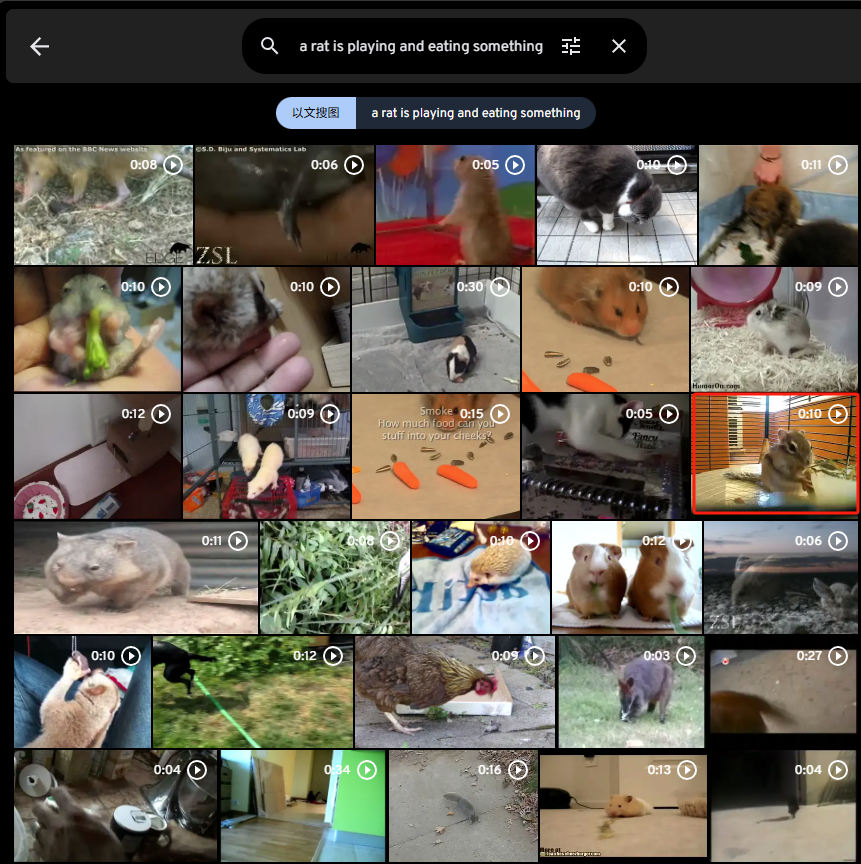
a rat is playing and eating something
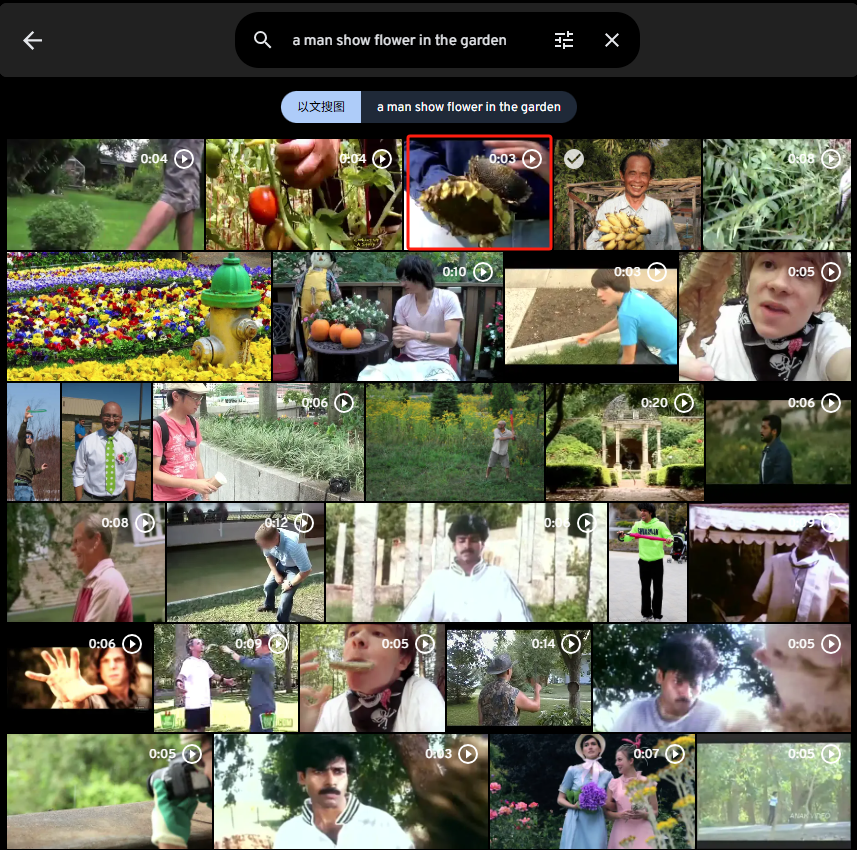
a man show flower in the garden

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)