医学图像分割系统新突破:基于Unet的皮肤病识别
DL00366-基于Unet的医学图像分割系统 用Unet来做医学图像分割。 我们将会以皮肤病的数据作为示范,训练一个皮肤病分割的模型出来,用户输入图像,模型可以自动分割去皮肤病的区域和正常的区域。
在医学图像处理领域,图像分割就像给CT片上的肿瘤画重点。今天咱们用最经典的Unet网络,从零开始打造一个皮肤病区域分割器。不需要高大上的设备,准备一张显卡和你的Python环境就够了。
先看数据怎么处理。皮肤病数据集通常包含RGB图片和对应的黑白mask(病变区域标注为白色)。咱们用albumentations做实时增强:
import albumentations as A
train_transform = A.Compose([
A.RandomRotate90(p=0.5),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.3),
A.RandomBrightnessContrast(p=0.2),
A.Resize(256, 256)
])这个配置让模型在训练时看到更多样的图像——旋转、翻转、亮度变化。注意别把增强玩脱了,医学图像的特征比自然图像敏感得多,过度增强反而会让模型学偏。
模型架构是重头戏。Unet的编码器部分像漏斗,逐步提取特征;解码器则像放大镜,把特征还原到原图尺寸。关键在跳跃连接——把编码阶段的细节直接喂给解码器:
from tensorflow.keras import Model
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Conv2DTranspose, concatenate
def unet(input_size=(256,256,3)):
inputs = Input(input_size)
c1 = Conv2D(64, (3,3), activation='relu', padding='same')(inputs)
p1 = MaxPooling2D((2,2))(c1)
# ...中间层省略...
# 解码器
u5 = Conv2DTranspose(64, (2,2), strides=(2,2), padding='same')(c4)
u5 = concatenate([u5, c3]) # 跳跃连接
c5 = Conv2D(64, (3,3), activation='relu', padding='same')(u5)
# ...输出层...
return Model(inputs=[inputs], outputs=[outputs])注意concatenate那行,这就是Unet的灵魂操作。编码器在pooling时丢失的空间信息,通过直接拼接浅层特征得到补偿,这对精确分割病灶边缘至关重要。
DL00366-基于Unet的医学图像分割系统 用Unet来做医学图像分割。 我们将会以皮肤病的数据作为示范,训练一个皮肤病分割的模型出来,用户输入图像,模型可以自动分割去皮肤病的区域和正常的区域。
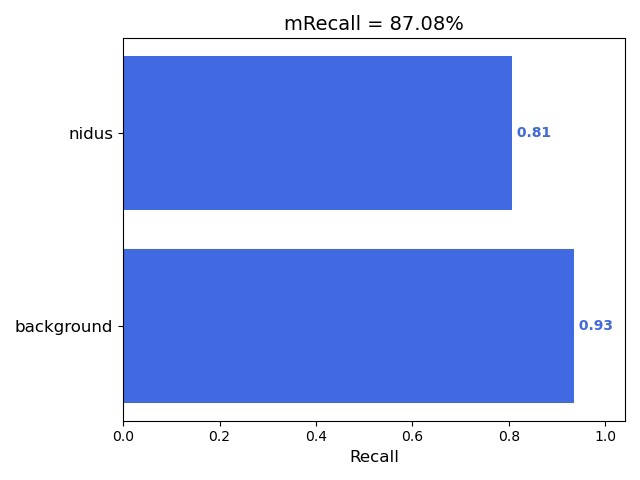
训练时有个小技巧——用带权重的交叉熵损失。皮肤病数据往往存在严重类别不平衡(病变区域占比小),这样能让模型更关注难例:
def dice_coeff(y_true, y_pred):
smooth = 1.
y_true_f = K.flatten(y_true)
y_pred_f = K.flatten(y_pred)
intersection = K.sum(y_true_f * y_pred_f)
return (2. * intersection + smooth) / (K.sum(y_true_f) + K.sum(y_pred_f) + smooth)
model.compile(optimizer=Adam(1e-4),
loss='binary_crossentropy',
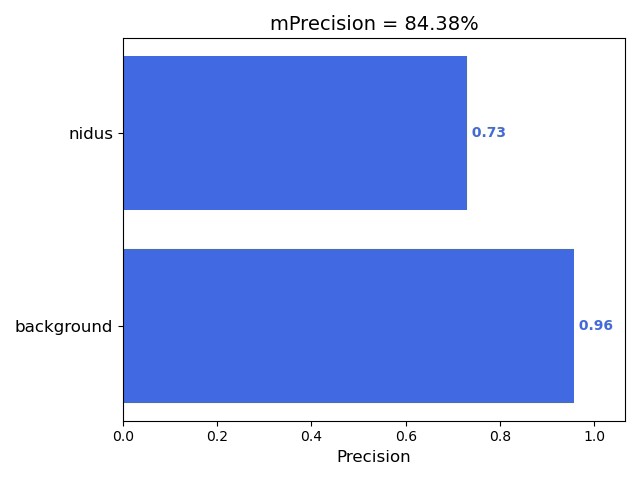
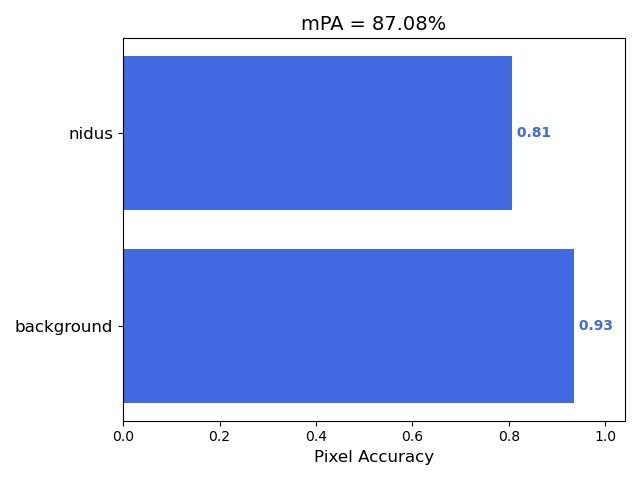
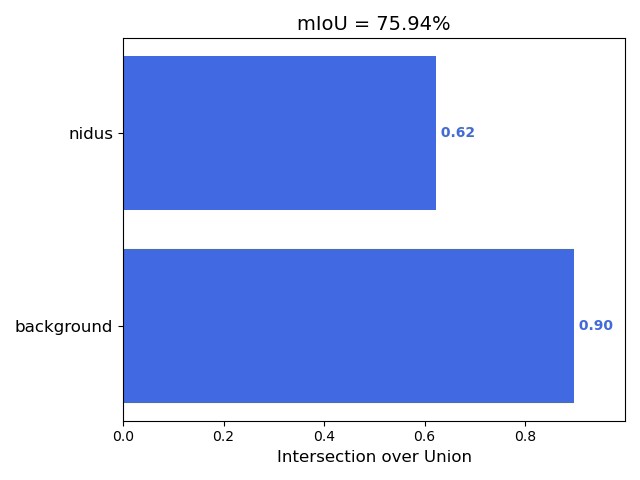
metrics=[dice_coeff])Dice系数这个指标比单纯准确率更靠谱,因为它更关注预测区域和真实区域的覆盖面积比例。实际训练时如果指标卡住,可以试着把学习率砍半继续练。
预测阶段要注意输入输出对齐。模型输出的是概率图,需要做后处理:
def predict(image_path):
img = load_img(image_path, target_size=(256,256))
prob_map = model.predict(np.expand_dims(img, 0))[0]
mask = (prob_map > 0.5).astype(np.uint8) * 255
return mask阈值0.5是个经验值,实际部署时可以根据ROC曲线调整。最终效果应该是输入一张皮肤病变图像,输出对应的二值mask,医生可以直接看到病灶轮廓。
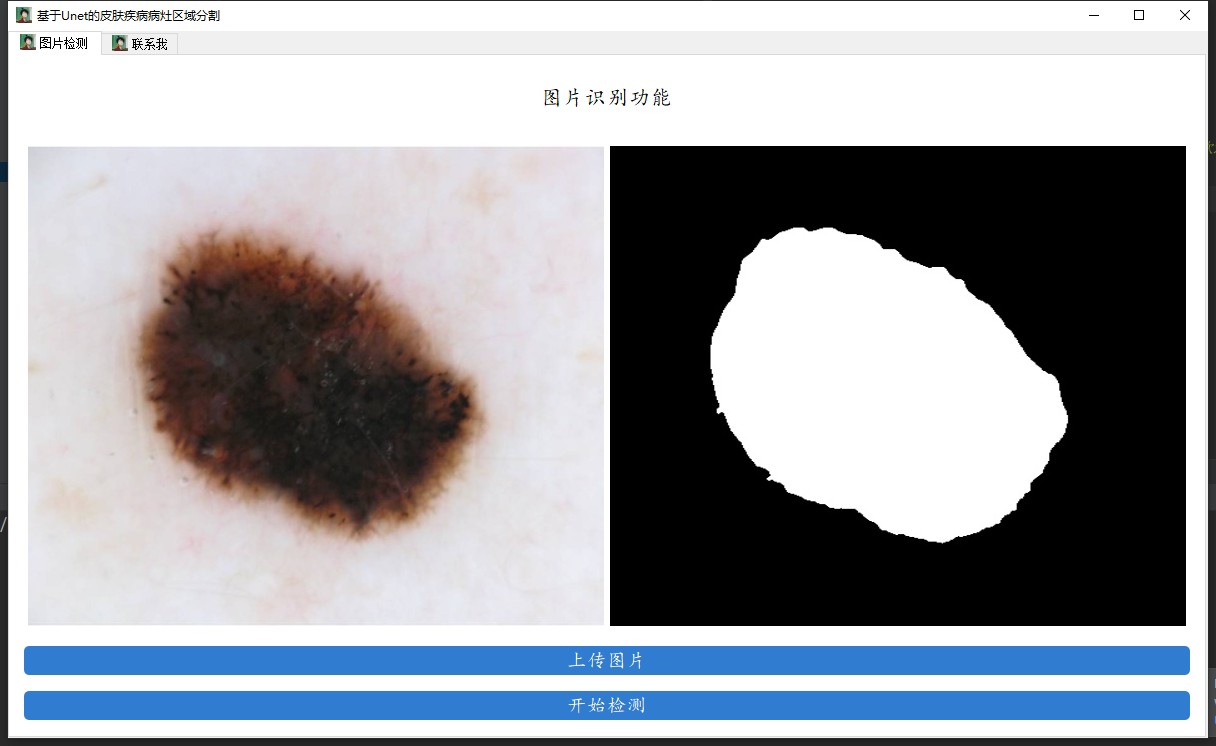
踩过的坑提醒:1. 数据归一化别用ImageNet的均值方差,医学图像有自己的分布;2. 遇到显存不足时可以把batch_size调小到4或8;3. 输出层用sigmoid激活而不是softmax,因为是二分类问题。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)