Model Context Protocol (MCP) 开发实战:从零构建 Python 数据交互服务
摘要: 本文介绍了如何利用Anthropic提出的Model Context Protocol (MCP)协议,通过Python和FastMCP SDK开发一个连接PostgreSQL数据库和本地文件的MCP Server。MCP协议解决了AI应用与外部数据源标准化连接的问题,替代了传统定制化插件的开发方式。教程详细演示了环境搭建、数据库查询工具(使用SQLAlchemy)和PDF文件读取功能的实
随着大模型应用(LLM Apps)的深入,如何让 AI 安全、高效地连接外部数据成为痛点。Anthropic 提出的 Model Context Protocol (MCP) 协议为此提供了标准化的解决方案。本文将手把手教你使用 Python 和 FastMCP SDK 开发一个能够操作 PostgreSQL 数据库和读取本地文件的 MCP Server,并探讨生产环境部署的相关策略。
一、 引言:为什么需要 MCP?
在日常的 智能体开发 和 RAG(检索增强生成) 项目中,我们经常需要把模型连接到企业的核心数据资产。比如,让 Agent 查询 PostgreSQL 中的业务数据,或者通过 PyPDF 解析本地合同文档。
传统的做法是针对每个模型平台开发一套插件,或者使用 LangChain/LlamaIndex 封装特定的 Tool。这导致了接口标准不一、重复造轮子的问题。
MCP (Model Context Protocol) 的出现改变了这一切。它是一个基于 JSON-RPC 的开放协议,旨在成为 AI 应用与数据源之间的“通用语言”。对于熟悉 Python 的开发者来说,MCP 让我们可以像写 FastAPI 或 Flask 服务一样,轻松暴露工具给 LLM 调用。
二、 环境准备
在开始编码之前,我们需要准备开发环境。为了演示方便,我们将使用 Anthropic 官方提供的 Python SDK mcp。
- 安装依赖
创建一个虚拟环境并安装必要的库。
# 安装 MCP SDK 及常用数据处理库
pip install mcp fastmcp sqlalchemy psycopg2-binary pypdf
注意:fastmcp 是一个更高级的封装,能让我们用装饰器极快地定义 Server,非常适合 Python 开发者。
- 项目结构
建议保持简单的目录结构,便于后续 Docker 封装:
mcp-tutorial/
├── server.py # MCP Server 核心代码
├── config.py # 数据库配置(模拟)
└── requirements.txt # 依赖列表
三、 开发第一个 MCP Server
我们将构建一个名为 MyDataServer 的服务,它具备两个核心能力:
- Tools:查询 PostgreSQL 数据库的用户信息(利用 SQLAlchemy)。
- Resources:读取服务器上的 PDF 文本内容。
1. 基础框架搭建
使用 FastMCP 可以极大地简化代码。创建 server.py
from mcp.server.fastmcp import FastMCP
from typing import Any
import os
# 实例化 MCP Server,名称将显示在客户端
mcp = FastMCP("Internal-Data-Tools")
# 在这里预定义一些全局配置,实际项目中可从环境变量读取
# 例如:DATABASE_URL = os.getenv("DB_URL")
2. 实现数据库查询工具
假设我们有一个 PostgreSQL 数据库,存储着项目需求或用户数据。我们需要定义一个 Tool,让 AI 能够通过自然语言触发 SQL 查询。
这里我们利用你熟悉的 SQLAlchemy 进行数据库操作,并通过 @mcp.tool() 装饰器将其暴露给 MCP 协议。
from sqlalchemy import create_engine, text
# 模拟数据库连接 (请替换为真实的连接字符串)
# 格式: postgresql+psycopg2://user:password@host:port/dbname
DB_CONNECTION_STRING = "postgresql+psycopg2://postgres:password@localhost:5432/mydb"
engine = create_engine(DB_CONNECTION_STRING)
@mcp.tool()
def query_project_status(project_id: int) -> str:
"""
查询指定 ID 的项目研发状态。
Args:
project_id: 项目的唯一标识 ID
Returns:
包含项目状态的字符串描述
"""
try:
with engine.connect() as conn:
# 执行参数化查询,防止 SQL 注入
sql = text("SELECT name, status, leader FROM projects WHERE id = :pid")
result = conn.execute(sql, {"pid": project_id}).fetchone()
if result:
return f"项目名称: {result[0]}, 当前状态: {result[1]}, 负责人: {result[2]}"
else = f"未找到 ID 为 {project_id} 的项目。"
except Exception as e:
return f"数据库查询出错: {str(e)}"
3. 实现本地文件读取资源
除了执行命令,MCP 还允许 AI “读取”文件。这在结合 RAG 场景时非常有用,比如让 AI 直接读取原始文档而不需要预先建立向量索引。这里我们模拟读取一个 PDF 文件。
import pypdf
@mcp.resource("docs://project-plan/{file_name}")
def read_project_plan(file_name: str) -> str:
"""
读取项目计划 PDF 文件的内容。
资源 URI 格式: docs://project-plan/{file_name}
"""
# 假设文件存储在 ./data 目录下
file_path = os.path.join("data", f"{file_name}.pdf")
if not os.path.exists(file_path):
return "错误:文件不存在"
try:
text_content = ""
with open(file_path, "rb") as f:
reader = pypdf.PdfReader(f)
for page in reader.pages:
text_content += page.extract_text()
return text_content
except Exception as e:
return f"读取 PDF 失败: {str(e)}"
4. 启动服务
代码的最后,添加启动逻辑:
if __name__ == "__main__":
# stdio 模式适合本地开发,与 Claude Desktop 等客户端通信
mcp.run(transport="stdio")
至此,一个具备数据库查询和文档读取能力的 MCP Server 就开发完成了。
四、 进行测试
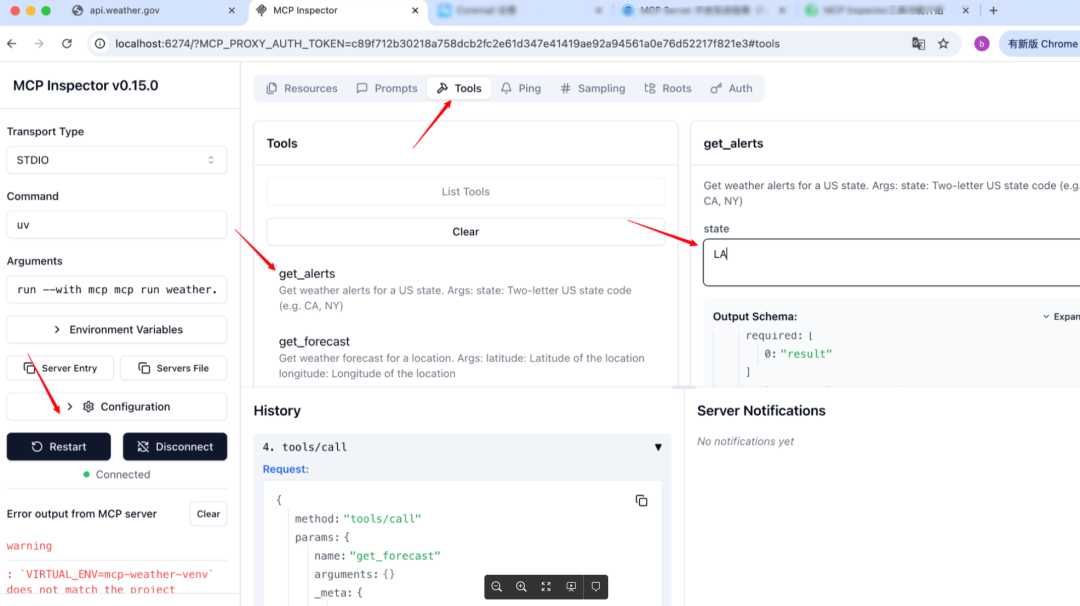
开发好 Server 后,使用官方提供的 Inspector 可视化工具来调试我们的服务器。
通过 mcp dev 来运行:mcp dev PYTHONFILE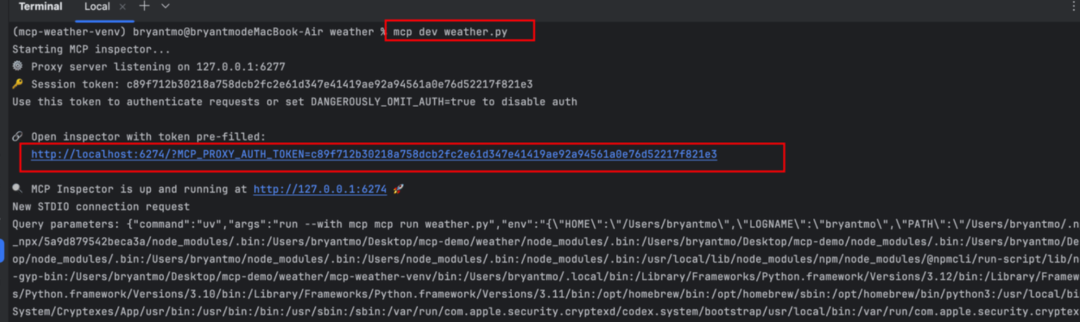
五、 进阶:生产环境部署策略
作为负责过项目研发计划和生产部署的开发者,我们知道 stdio 模式虽然开发方便,但在生产环境(如远程服务器)或对接多个服务时存在局限性。
1. 使用 SSE 传输模式
在生产环境,建议将 MCP Server 部署为 HTTP 服务,使用 Server-Sent Events (SSE) 进行通信。
修改启动代码:
# 需要安装 uvicorn: pip install uvicorn
import uvicorn
if __name__ == "__main__":
# 使用 SSE 模式,监听本地 8000 端口
mcp.run(transport="sse", port=8000, host="0.0.0.0")
2. Docker 容器化部署
为了保证环境一致性,我们使用 Docker 进行打包。创建 Dockerfile:
FROM python:3.10-slim
WORKDIR /app
# 复制依赖文件并安装
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# 复制源代码
COPY . .
# 暴露端口 (如果使用 SSE 模式)
EXPOSE 8000
# 启动命令 (如果是 stdio 模式,直接 python server.py)
CMD ["python", "server.py"]
构建并运行:
docker build -t mcp-server-prod .
docker run -d -p 8000:8000 --name my-mcp mcp-server-prod
3. 结合异步任务队列
在实际的 智能体开发 中,有些操作(如大规模数据处理、定时任务执行)非常耗时,不适合同步阻塞 MCP 连接。
我们可以引入 Celery 来处理耗时任务:
- MCP Tool 接收到请求后,不直接执行耗时操作,而是向 Celery 发送一个任务。
- 立即返回“任务已接收,正在处理”。
- 另外定义一个 MCP Tool get_task_result(task_id),让 Agent 定期轮询或查询结果。
这种架构能有效避免 MCP 连接超时,提升用户体验。
六、 总结
通过本教程,我们基于 Python、SQLAlchemy 和 PyPDF 构建了一个功能完整的 MCP Server。
回顾关键点:
- FastMCP 是 Python 生态下开发 MCP 服务的高效工具。
- Tools 对应“动作”(如查询数据库),Resources 对应“数据”(如读取文件)。
- 结合现有的技术栈(如 Docker、Celery),可以轻松将 MCP Server 推向生产环境,服务于实际的业务需求和客户对接场景。
- MCP 协议简化了 AI 与现有系统的集成难度,让我们能更专注于业务逻辑本身。快去试试把你们公司里的数据查询脚本封装成 MCP Server 吧!
希望这篇教程对你有所帮助,如果有任何关于代码实现或部署的问题,欢迎在评论区留言讨论。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)