Apache Kafka 简介 | Apache Kafka 官方入门学习文档
Apache Kafka是一个分布式事件流处理平台,用于构建实时数据管道和流处理应用。它采用发布-订阅模型,通过生产者写入主题(Topic),消费者订阅消费。核心特性包括分区(Partition)实现并行处理、复制(Replication)保障高可用、高性能TCP协议传输等。Kafka支持多种场景,如金融交易处理、物联网数据采集、系统解耦等。主要组件包括Broker服务器集群、生产者/消费者API
Apache Kafka 简介 | Apache Kafka 官方入门学习文档
本文基于 Confluent 官方 Kafka 文档(https://docs.confluent.io/kafka/introduction.html#partitions)整理,为 Kafka 核心入门学习内容,涵盖其定义、核心概念、使用场景及核心组件等关键知识点。
一、Apache Kafka 是什么
Apache Kafka® 是一个分布式事件流处理平台,用于构建实时数据管道和流处理应用。Kafka 被设计为可高效处理海量数据,具备可扩展、容错的特性,是实时分析、数据摄入和事件驱动架构等场景的理想选择。
从核心本质来看,Kafka 是一个分布式的发布-订阅消息系统:
- 生产者(Producer)将数据写入 Kafka 的主题(Topic);
- 消费者(Consumer)从主题中读取并消费数据;
- 主题支持分区(Partition)处理,实现数据的并行计算;
- 主题可在多个代理(Broker)间复制,保障系统的容错性。
同时,Kafka 提供了用于管理和运维的命令行工具,以及 Java、Scala 开发 API,可基于此为各类业务场景构建定制化的事件流解决方案。
二、事件与事件流(Events and Event Streaming)
要理解分布式事件流,首先需要明确事件(Event) 的定义:事件是记录业务或现实世界中“发生了某件事”的一条记录。
举一个网约车系统中的事件示例:
- Event key:“Alice”
- Event value:“Trip requested at work location”
- Event timestamp:“Jun. 25, 2020 at 2:06 p.m.”
事件数据会描述发生了什么、发生的时间、涉及的对象。
事件流(Event streaming) 是从数据库、传感器、移动设备、云服务、软件应用等数据源中,实时捕获上述这类事件的实践。
事件流平台会按顺序捕获事件,并对事件流进行持久化存储,支持实时的处理、操作、响应,也可在后续需要时检索。此外,事件流可根据需求路由到不同的目标技术平台。
事件流能够确保数据的持续流转和解析,让正确的信息在合适的时间出现在合适的位置。为实现这一能力,Kafka 以集群形式运行在一台或多台服务器上,可跨多个数据中心部署,提供分布式、高可扩展、弹性、容错、安全的服务能力,同时支持部署在裸机硬件、虚拟机、容器中,也可在本地或云环境部署。
三、Kafka 典型使用场景
事件流技术在各行业、各类组织中有着广泛的应用,Kafka 作为主流的事件流平台,典型使用场景包括:
- 作为消息系统:实时处理支付和金融交易,例如证券交易所、银行、保险公司的交易处理场景。
- 行为追踪:实时跟踪和监控车辆、车队、货物运输状态,例如出租车服务、物流行业、汽车制造行业。
- 指标数据采集:持续捕获和分析物联网设备或其他设备的传感器数据,例如工厂、风电场的设备数据监控。
- 流处理:收集并响应客户交互和订单数据,例如零售、酒店旅游行业、移动应用的用户行为与订单处理。
- 系统解耦:连接、存储并共享企业内不同部门产生的数据,实现各系统间的解耦和数据互通。
- 与大数据技术集成:与 Hadoop 等其他大数据技术融合,构建完整的大数据处理链路。
四、Kafka 核心术语(Terminology)
Kafka 是一个分布式系统,由不同类型的服务器和客户端组成,它们通过高性能的 TCP 网络协议传输事件,所有组件协同工作完成事件流处理。以下是必须掌握的 Kafka 核心术语:
4.1 代理(Brokers)
Broker 是 Kafka 存储层中的一台服务器,用于存储来自一个或多个数据源的事件流。
- 一个 Kafka 集群通常由多个 Broker 组成;
- 集群中的每一个 Broker 同时也是引导服务器(bootstrap server) :只要能连接到集群中的任意一个 Broker,即可实现与集群中所有 Broker 的连接。
4.2 主题(Topics)
Kafka 集群将事件流按类别组织并持久化存储,这些类别被称为Topic(主题) ,是 Kafka 最基础的组织单元。可以将主题理解为文件系统中的文件夹,而事件则是文件夹中的文件。
主题的核心特性
- 仅追加写入:新的事件消息写入主题时,会被追加到日志的末尾;
- 事件不可变:事件写入后无法被修改;
- 基于偏移量消费:消费者通过查找偏移量(Offset) ,按顺序读取日志中的条目;
- 多生产者、多订阅者:一个主题可以有 0 个、1 个或多个生产者写入事件,也可以有 0 个、1 个或多个消费者订阅消费事件;
- 数据按需保留:主题不支持查询操作,但其中的事件可被多次读取;与其他消息系统不同,Kafka 的事件被消费后不会被立即删除,可配置为当数据达到指定存活时间或主题达到指定大小后,自动过期清理;
- 性能与数据量无关:Kafka 的性能不会随数据量的增加而显著下降,长时间存储数据对性能的影响极小。
Kafka 提供了多款管理集群、Broker 和主题的 CLI 工具,同时提供Admin Client API,可基于此实现自定义的运维管理工具。
4.3 生产者(Producers)
生产者是向 Kafka写入事件的客户端,核心特性包括:
- 生产者需指定要写入的目标主题;
- 生产者可控制事件在主题内的分区分配策略,常见方式包括轮询(round-robin) (实现负载均衡)、基于事件键(event key) 的语义分区函数分配;
- Kafka 提供Java Producer API,支持应用向 Kafka 集群发送事件流。
关于生产者的设计细节,以及生产者、Broker、消费者之间的消息交换机制,可参考《Kafka Producer Design》和《Kafka Message Delivery Guarantees》。
4.4 消费者(Consumers)
消费者是从 Kafka读取事件的客户端,核心特性包括:
- 消费者层面仅保留一个元数据:其在主题中的偏移量(Offset) ,即消费位置;
- 偏移量由消费者自主控制:正常情况下,消费者会随读取记录线性推进偏移量,也可按需调整偏移量,例如重置到旧的偏移量重新处理历史数据,或跳转到最新的偏移量从“当前时刻”开始消费;
- 低耦合性:消费者的上下线对 Kafka 集群和其他消费者的影响极小;
- Kafka 提供Java Consumer API,支持应用从 Kafka 集群读取事件流。
关于消费者的设计细节,以及生产者、Broker、消费者之间的消息交换机制,可参考《Kafka Consumer Design: Consumers, Consumer Groups, and Offsets》和《Kafka Message Delivery Guarantees》。
4.5 分区(Partitions)
主题会被拆分为多个分区(Partition) ,即一个主题的日志会被拆分为多个子日志,分布在不同的 Kafka Broker 上。
这种设计的核心价值是实现分布式存储与并行处理:存储消息、写入新消息、处理已有消息的工作可分散到集群中的多个节点,让客户端应用能够同时从多个 Broker 读写数据,是 Kafka 实现可扩展性的关键。
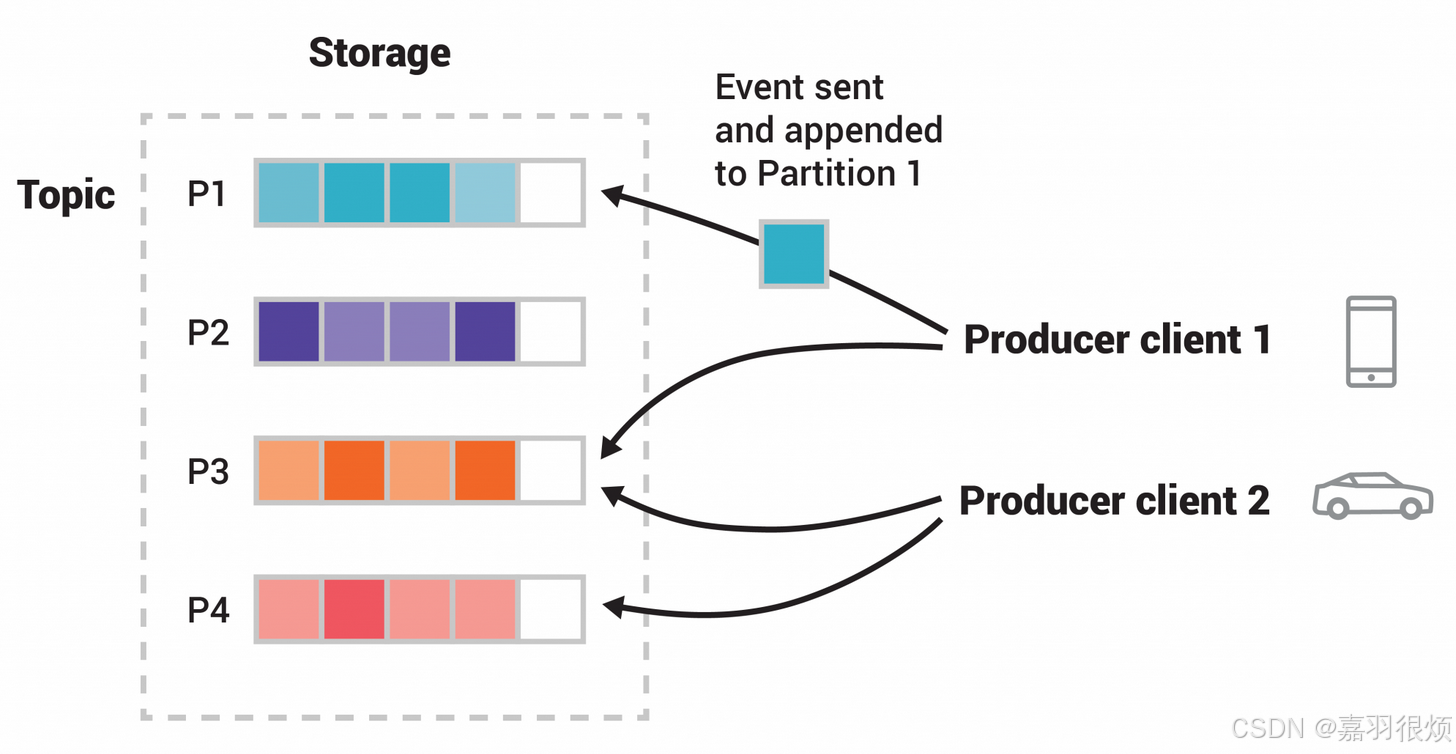
分区的核心规则
- 新事件发布到主题时,实际是被追加到该主题的某一个分区中;
- 相同事件键的事件(如同一客户标识、同一车辆 ID)会被写入同一个分区;
- Kafka 保证:消费某个主题分区的任意消费者,始终会按照事件的写入顺序读取该分区的事件。
一个典型的主题示例包含 4 个分区(P1–P4),两个独立的生产者客户端通过网络将事件写入主题的不同分区;相同键的事件(通常用不同颜色标识)会被写入同一个分区,且多个生产者可向同一个分区写入事件。
4.6 复制(Replication)
复制是保障 Kafka 数据高可用、容错的重要机制,核心特性包括:
- 每个主题都可被复制,甚至支持跨地理区域、跨数据中心的复制;
- 多份数据副本存储在不同的 Broker 上,可应对 Broker 故障、运维升级等场景,避免数据丢失和服务不可用;
- 生产环境常用配置:副本因子(replication factor)设为 3,即每份数据始终保留 3 个副本;
- 复制操作在主题分区级别执行。
关于 Kafka 复制的深入解析,可参考《Kafka Replication and Committed Messages》。
五、Kafka 其他核心组件
除了核心的 Broker、生产者、消费者外,Kafka 还有两个重要的组件,用于实现数据集成和复杂流处理,分别是 Kafka Connect 和 Kafka Streams。
5.1 Kafka Connect
Kafka Connect 是 Kafka 的数据集成组件,实现了数据库、键值存储、搜索索引、文件系统与 Kafka Broker 之间的双向数据同步。
它提供了统一的框架用于定义连接器(Connector) ,由连接器完成数据在外部系统与 Kafka 之间的迁移工作,连接器分为两类:
- 源连接器(Source connectors) :作为 Kafka 的生产者,将外部系统的数据导入 Kafka;
- 下沉连接器(Sink connectors) :作为 Kafka 的消费者,将 Kafka 中的数据导出到外部系统。
开发者可直接使用 Kafka 社区提供的多款开源连接器,也可通过Connect API开发自定义的导入/导出连接器,实现与外部系统的事件流读写。
5.2 Kafka Streams
在 Kafka 中,流处理器(stream processor) 是从输入主题获取持续的事件流,对其进行处理后,向输出主题生成持续事件流的组件。例如网约车应用中,流处理器可读取司机和乘客的输入流,输出当前正在进行的行程流。
简单的流处理可直接通过生产者和消费者 API 实现,而对于复杂的转换处理,Kafka 提供了 Kafka Streams 组件。
Kafka Streams 核心特性
-
是用于构建关键业务级实时应用和微服务的客户端库,其输入和/或输出数据均存储在 Kafka 集群中;
-
支持实现非简单的处理任务,例如基于事件流计算聚合指标、实现多流关联;
-
解决了流处理中的经典问题:乱序数据处理、代码变更后的输入重处理、有状态计算等;
-
基于 Kafka 核心原语构建,底层使用:
- 生产者和消费者 API 实现数据输入;
- Kafka 实现有状态存储;
- 与消费者相同的组机制,实现流处理器实例间的容错。
Kafka Streams 的并行性模型基于流分区(stream partition) 和流任务(stream task) 实现,流分区与 Kafka 主题分区一一映射,是实现数据本地性、弹性、可扩展性、高性能和容错的核心。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)