【小白】【超详细】从零开始搭建自己的YOLO
特别致谢@kidousCSDN同名。
特别致谢@kidous CSDN同名
目录
环境准备
素材准备
模型训练
前言
在目前的深度学习领域中,最主流的框架包括PyTorch、TensorFlow、Keras等,其中PyTorch因其灵活性、易用性和高效的性能收到了学术界与工业界的广泛欢迎。
本章的主要内容为Ultralytics工程的复现,Ultralytics 是一个专注于计算机视觉技术的公司,以其开发的YOLO(You Only Look Once)系列目标检测算法而闻名。YOLO是一种实时物体检测系统,能够在视频的每一帧中同时预测多个物体的位置和类别。它因其速度和效率而在学术界和工业界得到了广泛的应用。
Ultralytics工程中所提供的YOLO系列模型是开源的,这使得研究人员、开发爱好者可以方便的使用这些先进算法。除了这些算法以外,Ultralytics还提供了相关的服务与支持,包括但不限于模型训练、优化、部署等方面的支持,因此,接触Ultralytics对想要入门CV的同学来说十分合适,同学们可以在复现的过程中体会一个深度学习模型从无到有的过程。
环境准备
watt toolkit
steampp-windows密码:1234
打开链接
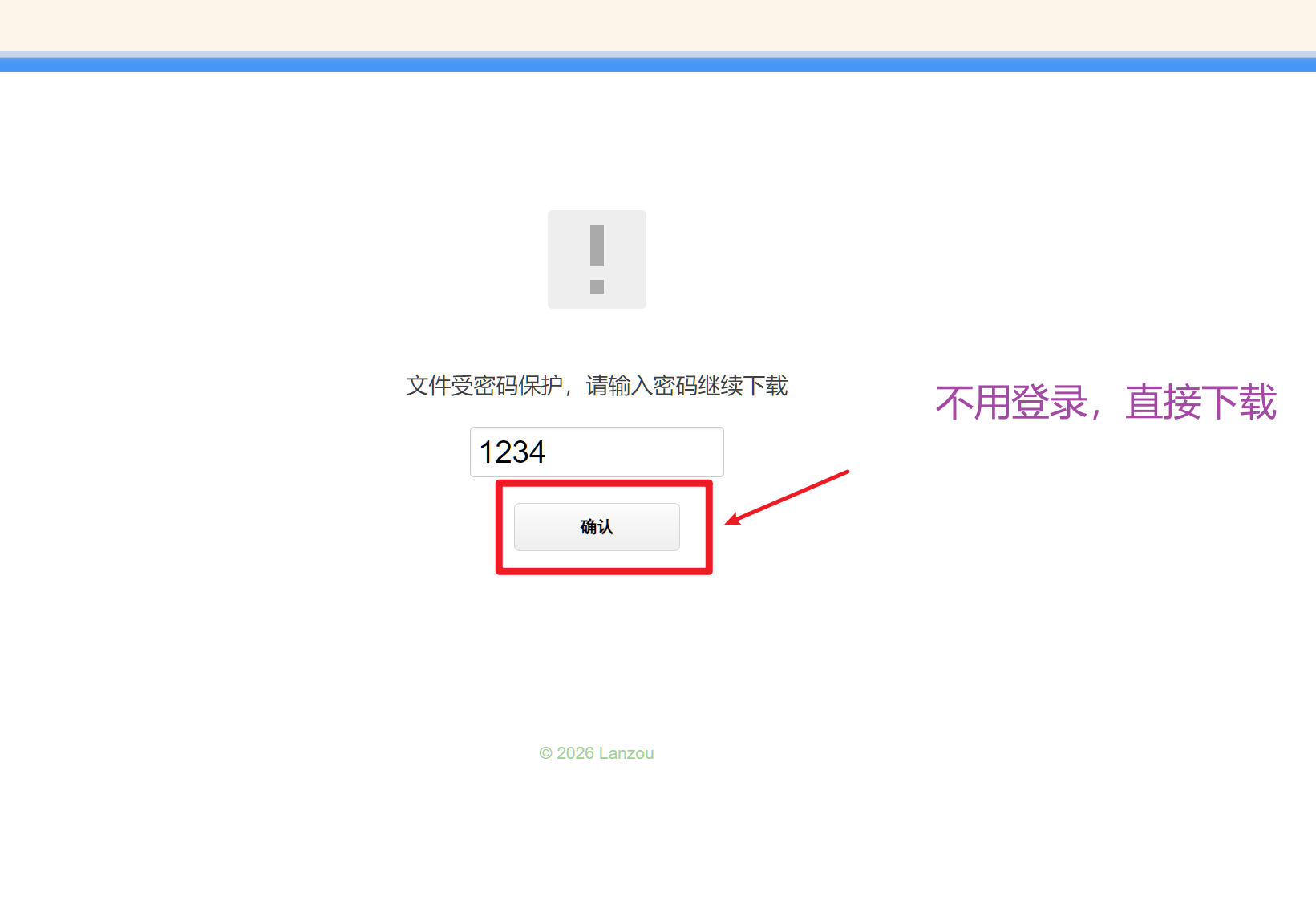
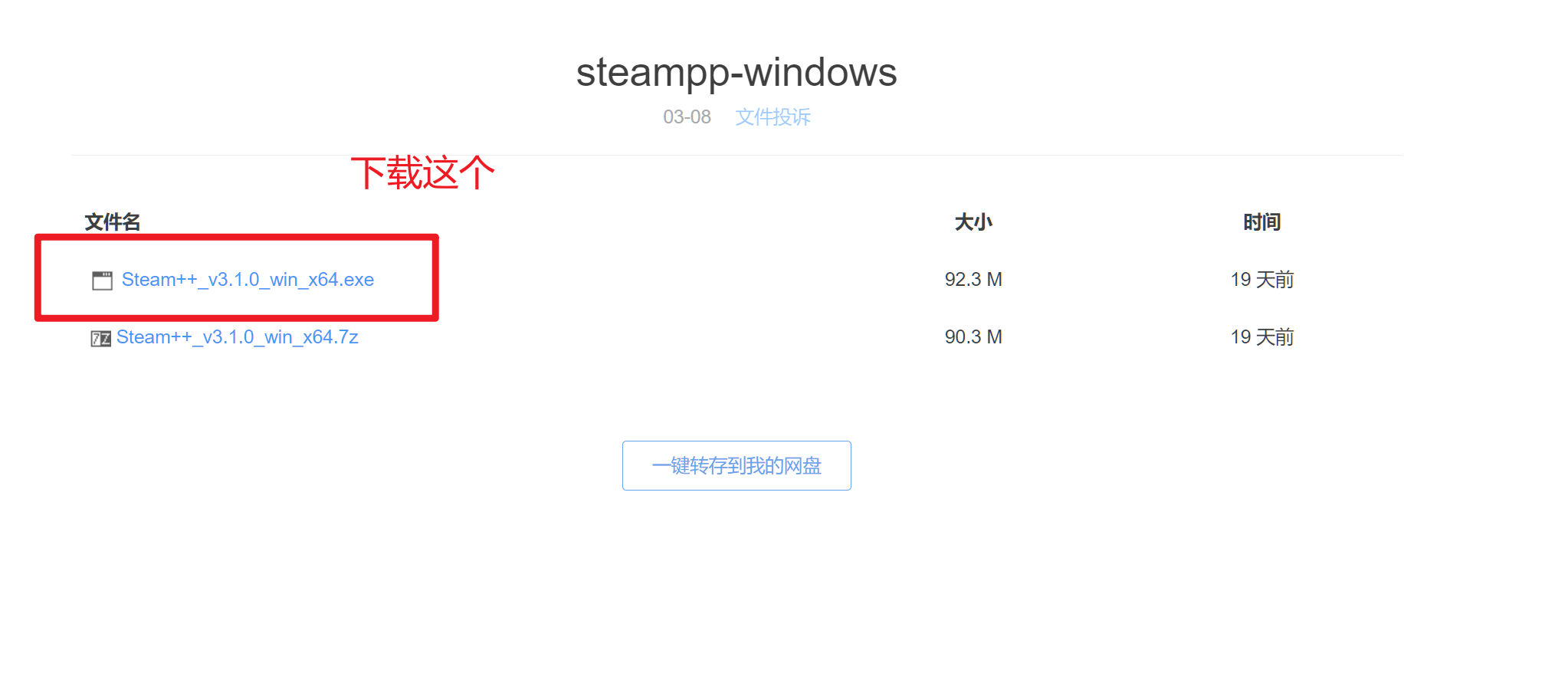

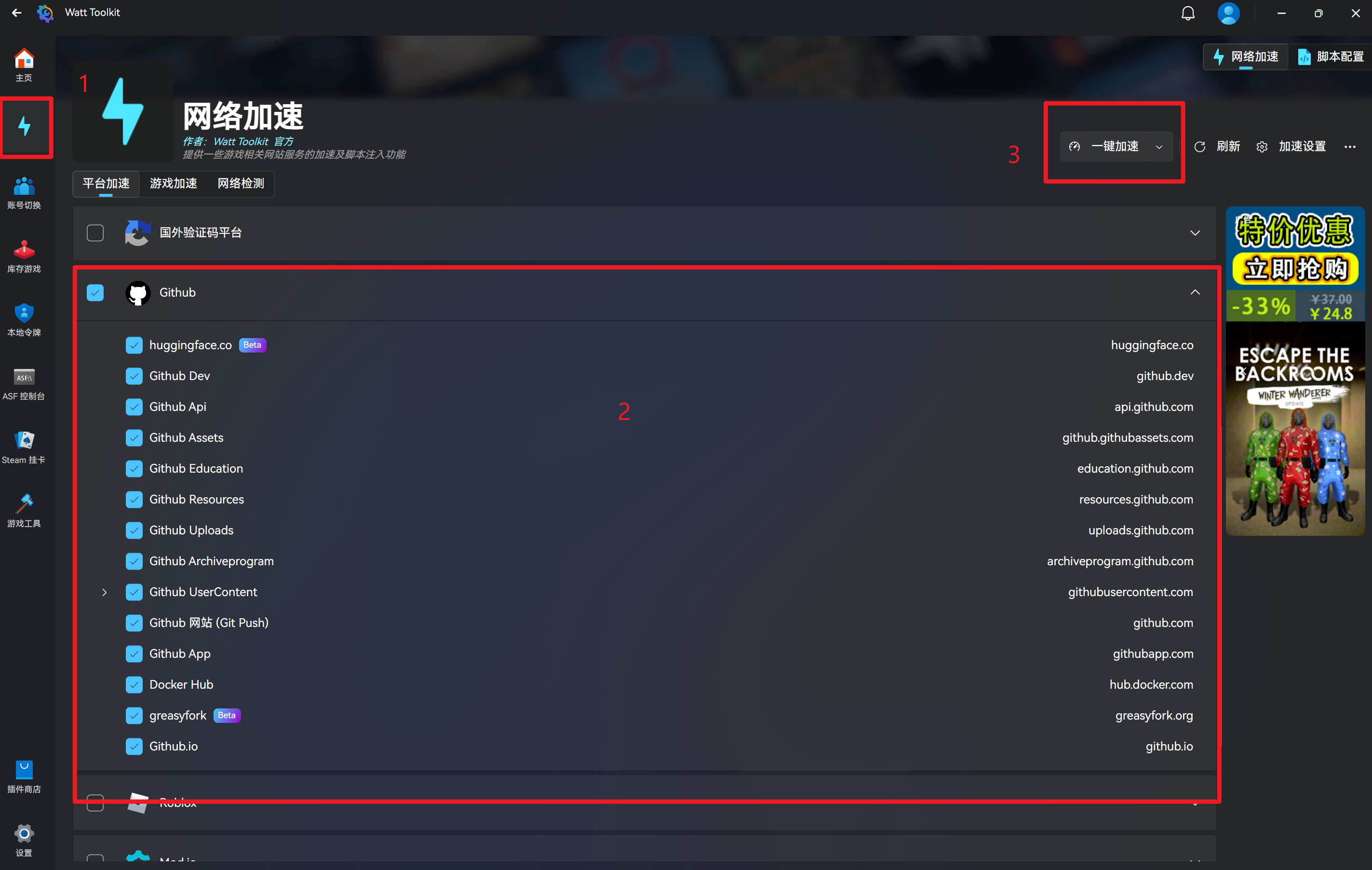
加速后就能正常访问github了~
VScode
Visual Studio Code - The open source AI code editor
正常安装后打开如下图:
接下来安装两个拓展:
chinese
python
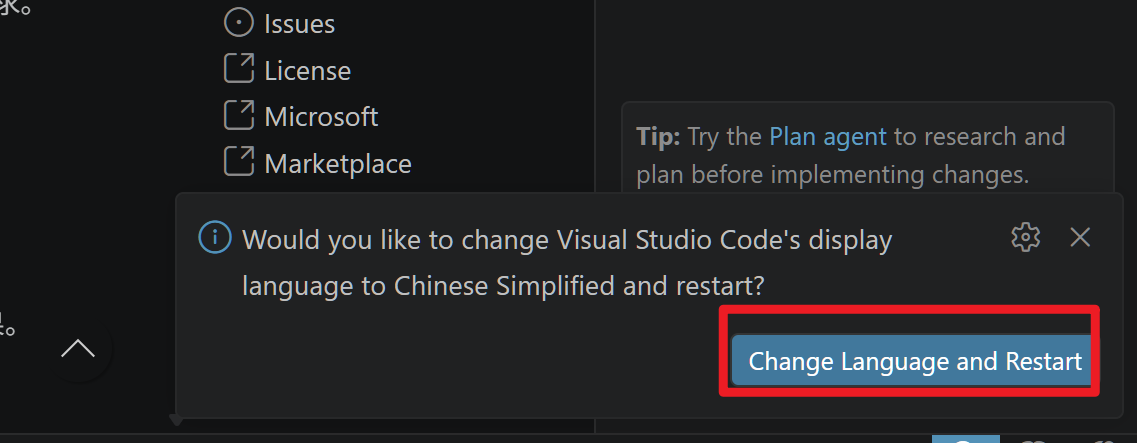
安装中文后,右下角会让你重启,点击即可
接下来搜索:python,下载标红的这个
Miniforge
Miniforge是Miniconda的替代品(处理超快下载超强)
而Miniconda是一种环境管理工具
还有Anaconda(臃肿的conda)
现在点击下面的链接:
Releases · conda-forge/miniforge
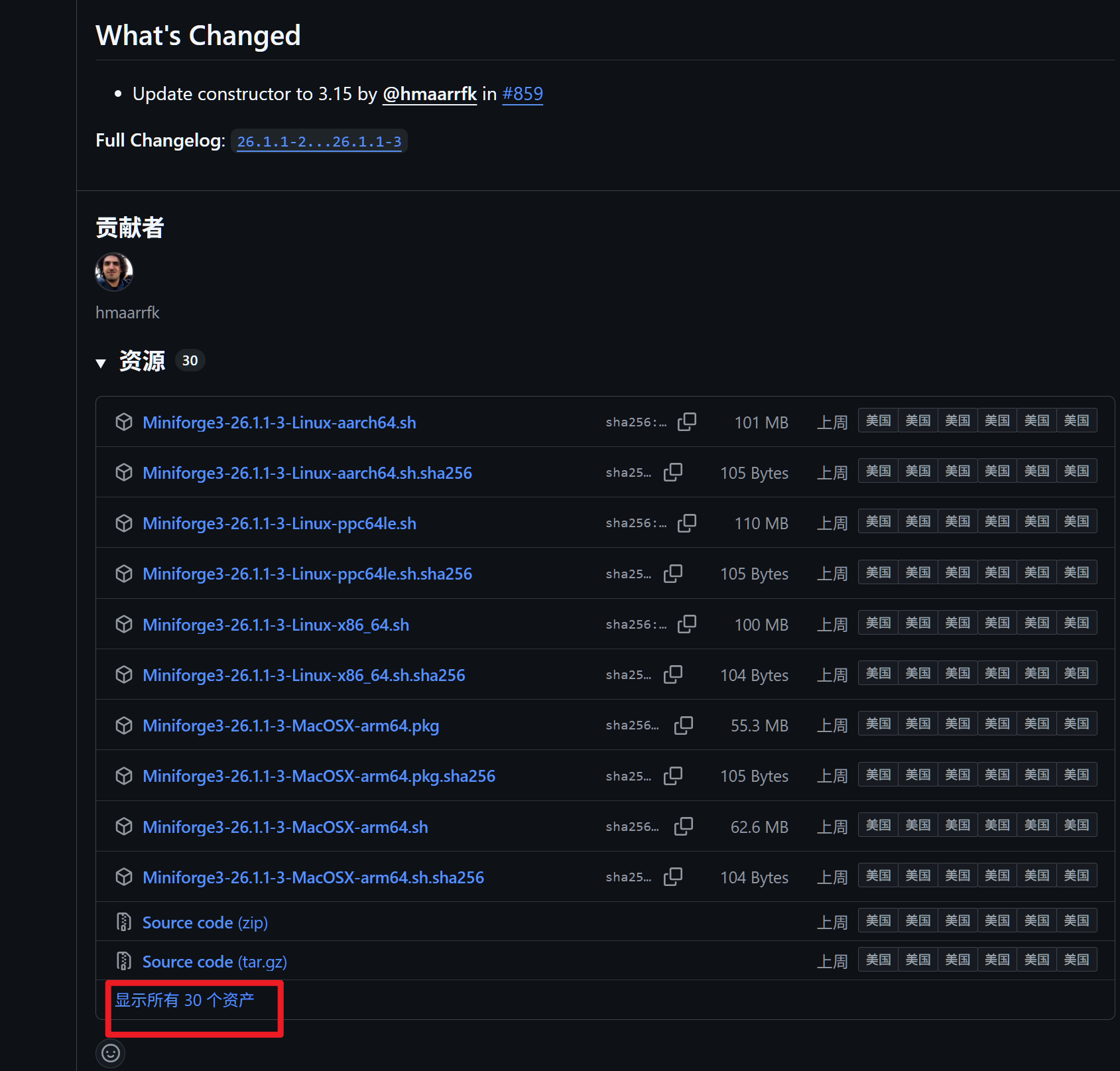
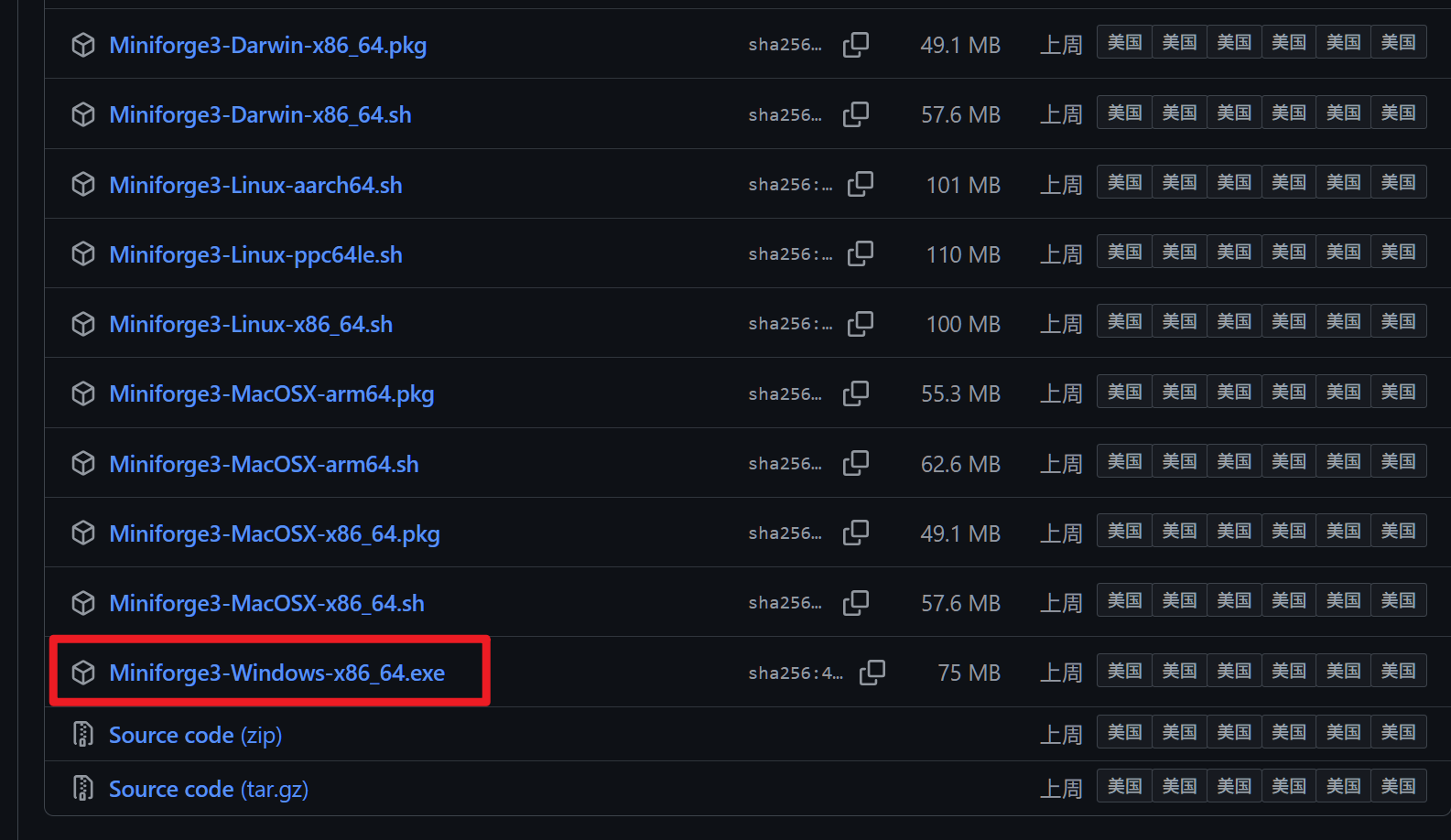
找到适合自己系统的版本进行下载
安装成功后,按下win键,下图所示
 搜索Miniforge,会显示:
搜索Miniforge,会显示:
打开后出现以下
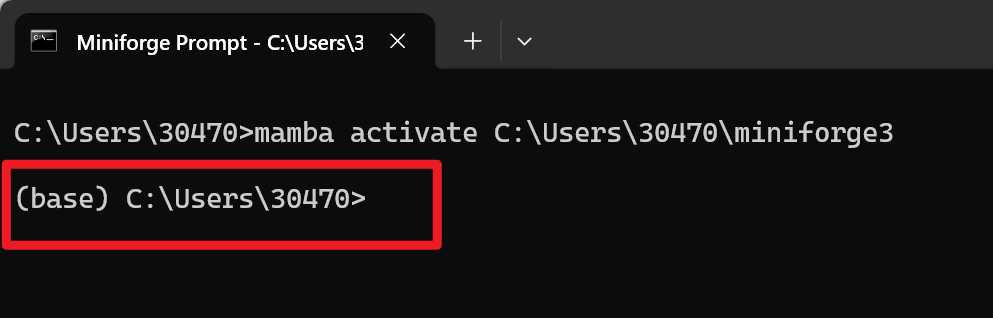
我们输入以下指令:
mamba create -n yolo python=3.11
意思是用mamba创建一个名字叫做yolo的环境,这个环境的python解释器版本为3.11

等待弹出提示后,输入:y
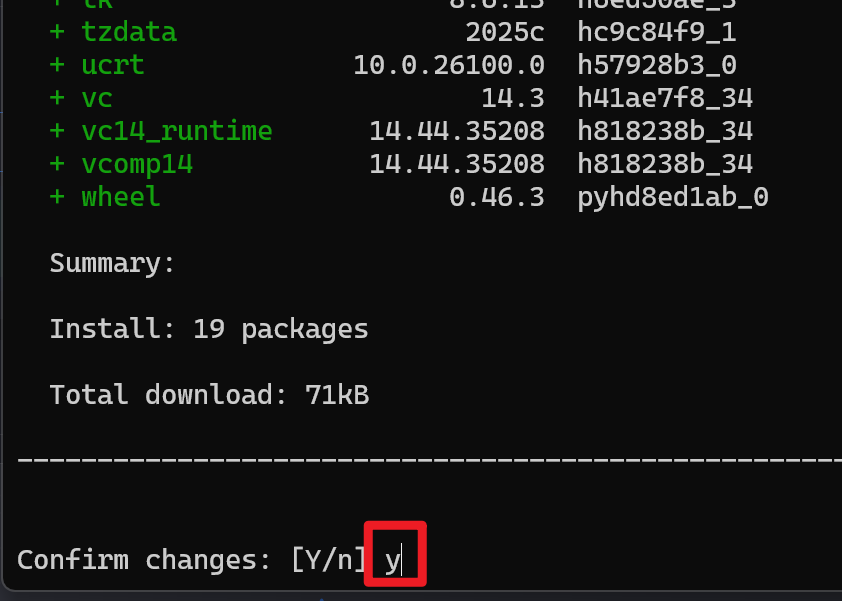
出现以下内容则代表新环境创建成功
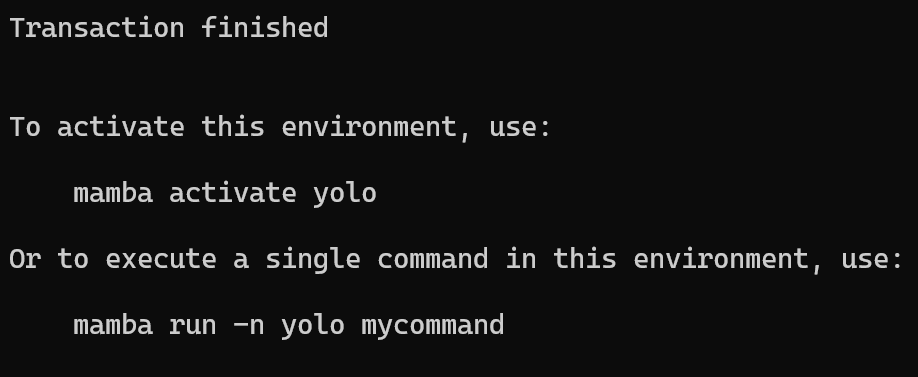
接着我们输入:
conda activate yolo

我们发现,最前面的括号里的内容变了

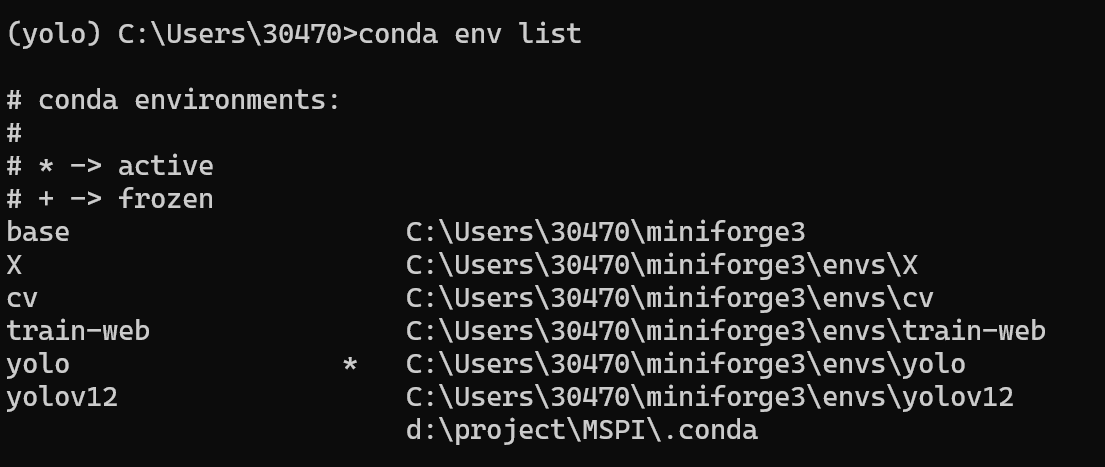
我们可以输入:conda env list 来查看我们有哪些环境
*号代表当前我们所在的环境
Git
git是一个版本控制工具
下载链接如下

安装完成后,打开Miniforge,输入:git --version
出现类似下图则代表安装成功:

接着输入(请替换你实际的名字和邮箱):
git config --global user.name "你的用户名"
git config --global user.email "你的邮箱"
输入完成后即可正常使用Git
保持在Miniforge的终端内:
确保前面的环境名字为上文的yolo:
输入:pip install ultralytics

出现以下画面代表安装成功
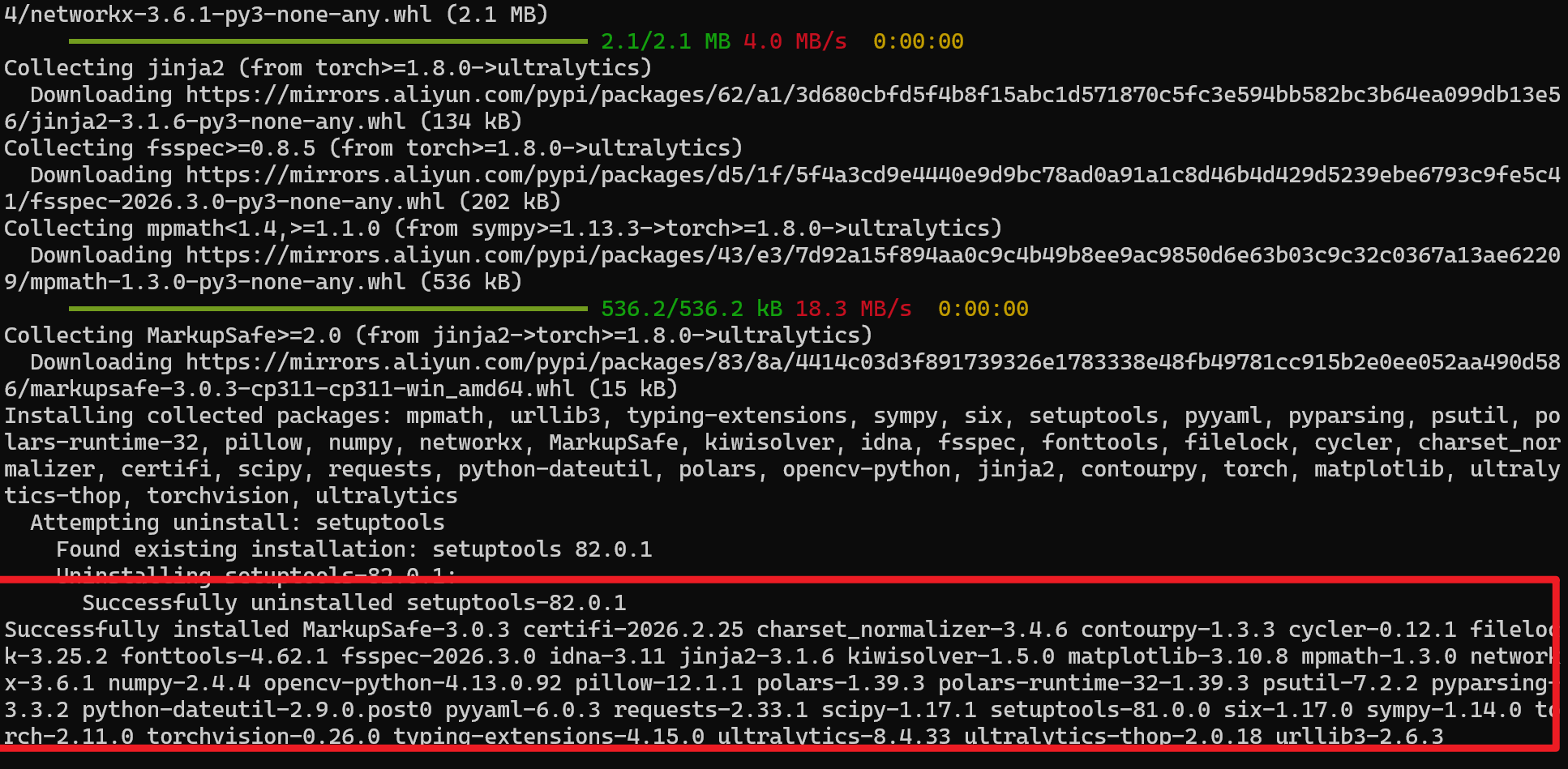
接着我们可以来到桌面等任意位置,右键新建一个文件夹
我们取名为X

接着我们安装X-AnyLabeling,也就是我们打标的工具
打开以下链接
Releases · CVHub520/X-AnyLabeling
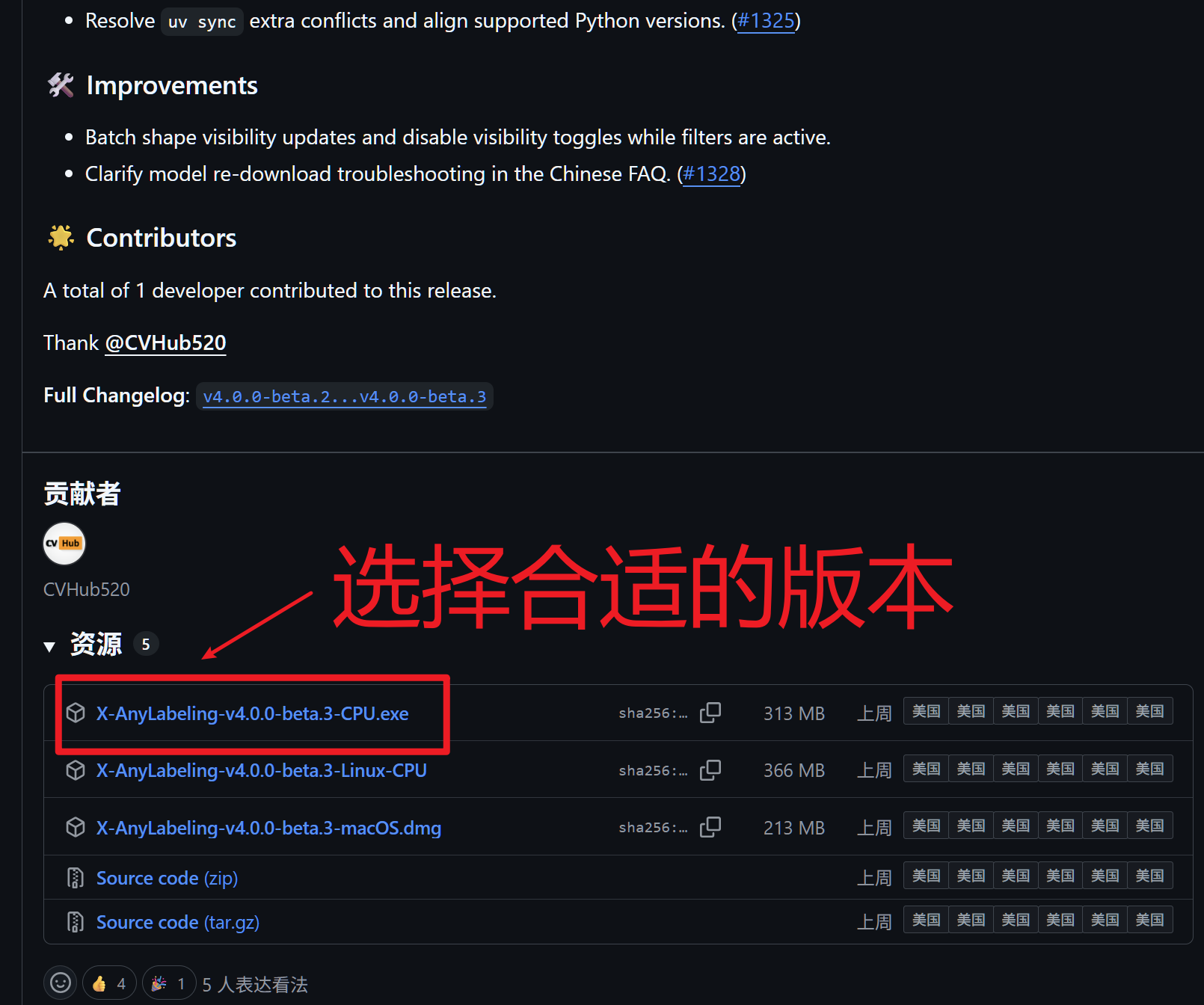
下载好后大概率会报告不安全:
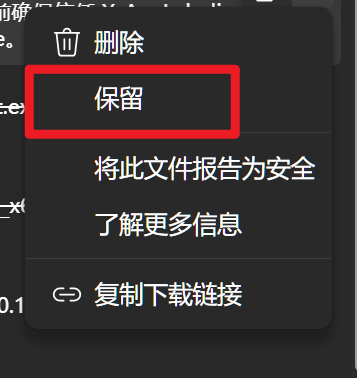
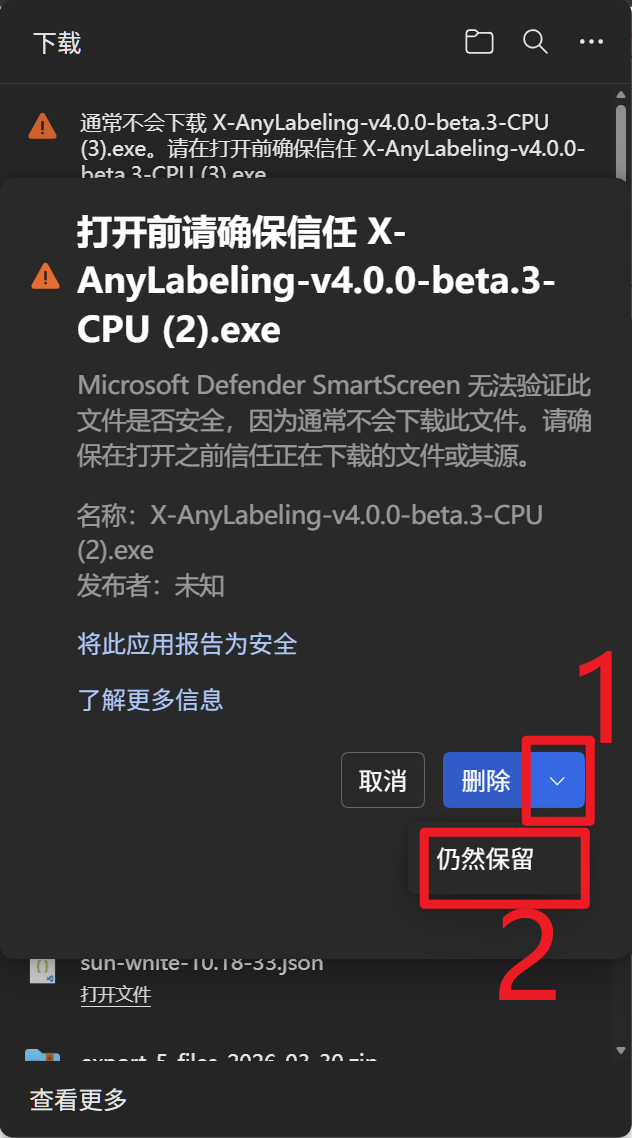

这样就可以正常打开了
打开后,看到这么多英文不要怕,立刻切换语言
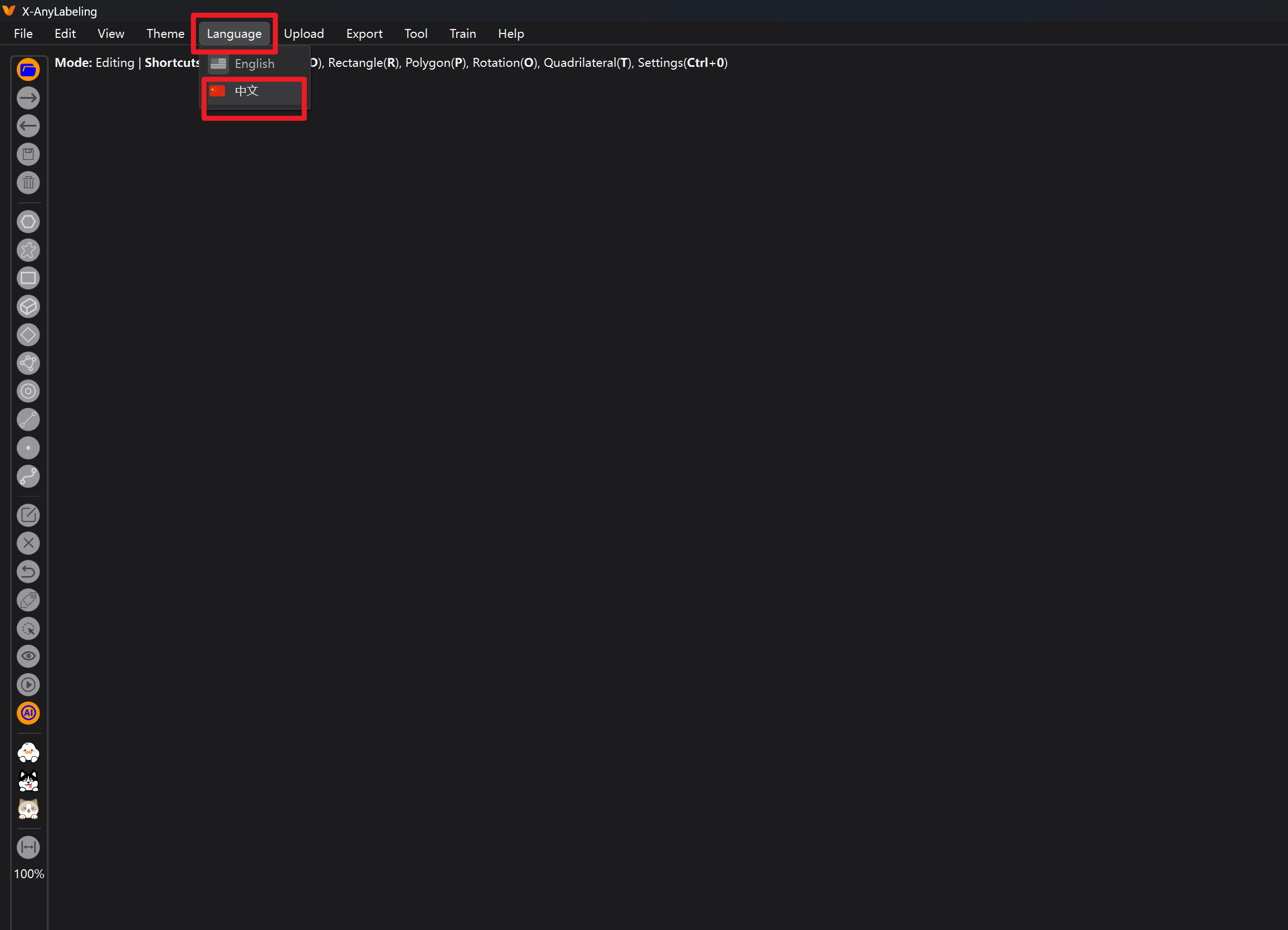
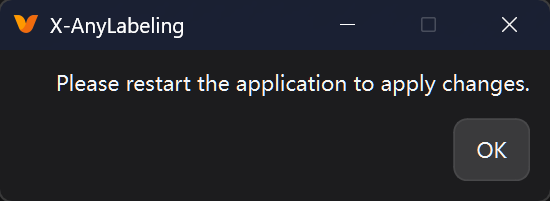
重新打开就是中文的啦!
除此之外,我们还有更高阶的打开方法(用GPU加速),推荐使用这种方法:
我们回到我们之前的X文件夹,打开它

输入:conda activate yolo,保证进入正确环境

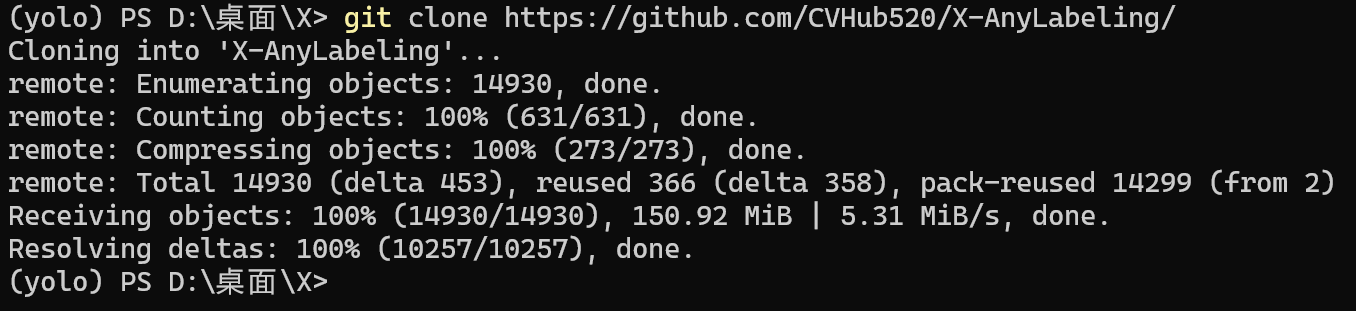
接着输入:git clone https://github.com/CVHub520/X-AnyLabeling/
![]()
表示用git,把这个链接的东西下载到当前文件夹
若出现以下情况,代表无法找到github,是一种网络环境问题
可以用这个工具进行解决:Releases · docmirror/dev-sidecar,更详细的请看相关教程


若出现以下画面,则代表下载成功
我们输入: cd .\X-AnyLabeling\
代表进入这个目录
选择以下一种方式,进行安装
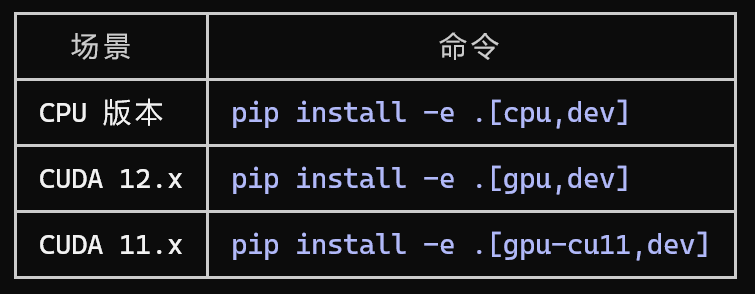
只有电脑有GPU,才有可能有CUDA
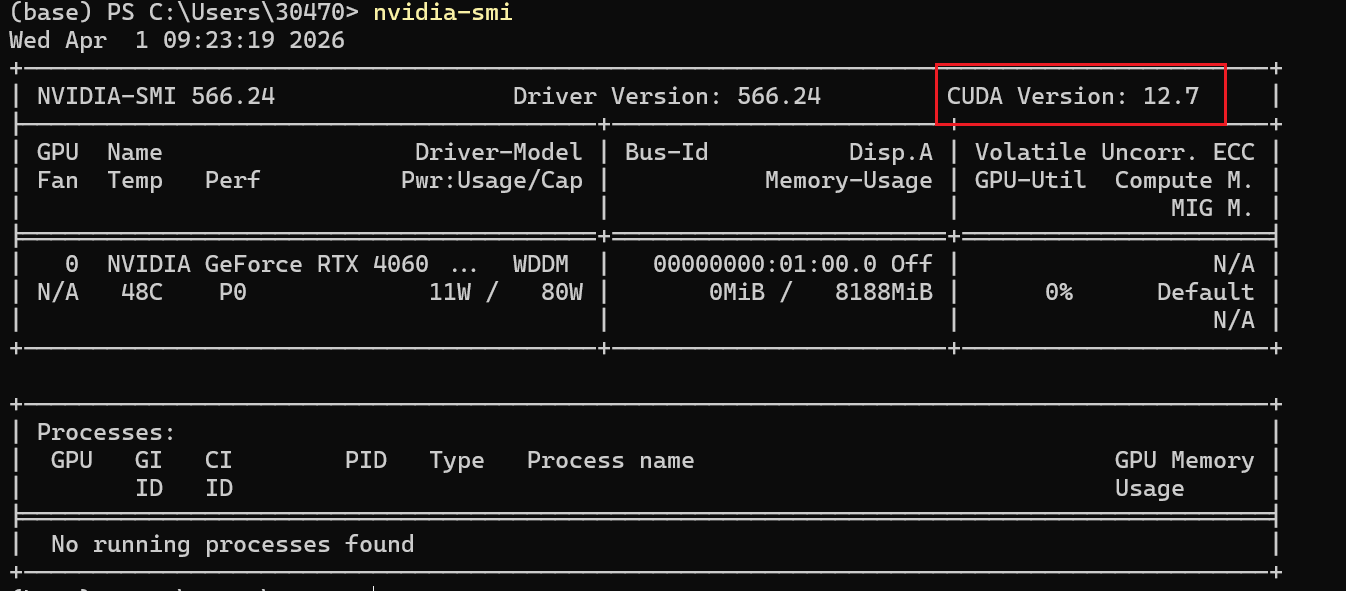
要首先知道的CUDA版本,需要输入:
nvidia-smi
看到右上角,对应你的CUDA版本
出现以下画面,代表安装成功

接着,我们找到我们的X文件夹
打开X-AnyLabeling文件夹
左侧打开对应的文件
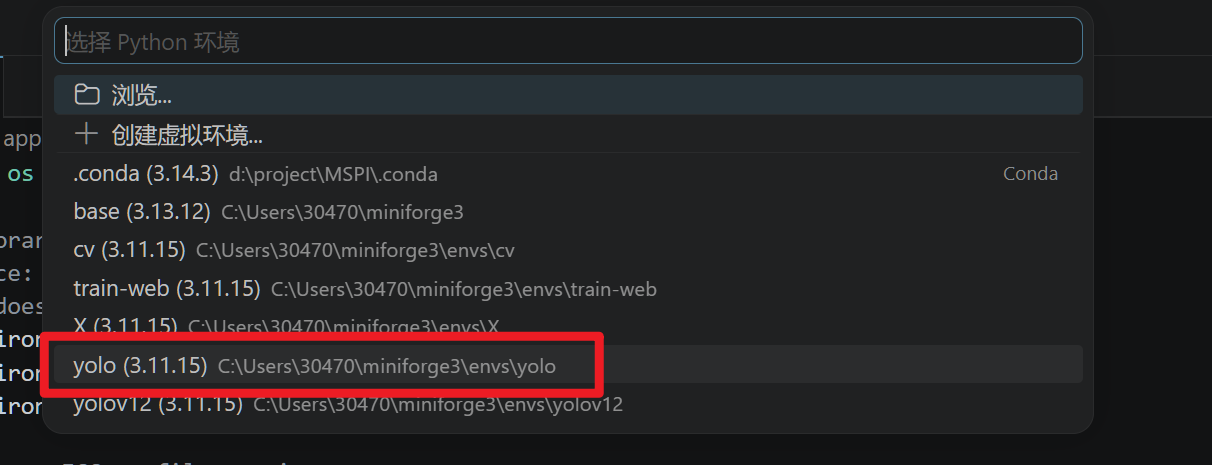
右下角选择解释器
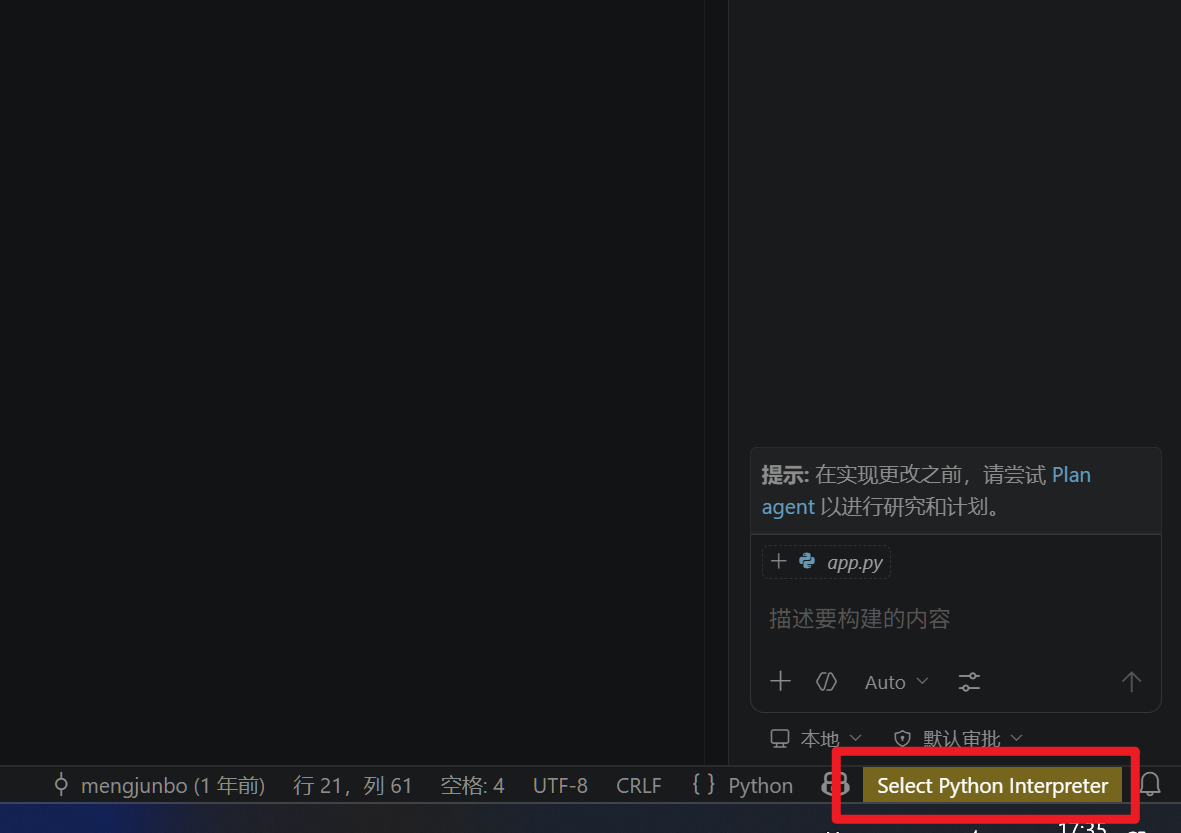
选择我们的yolo环境
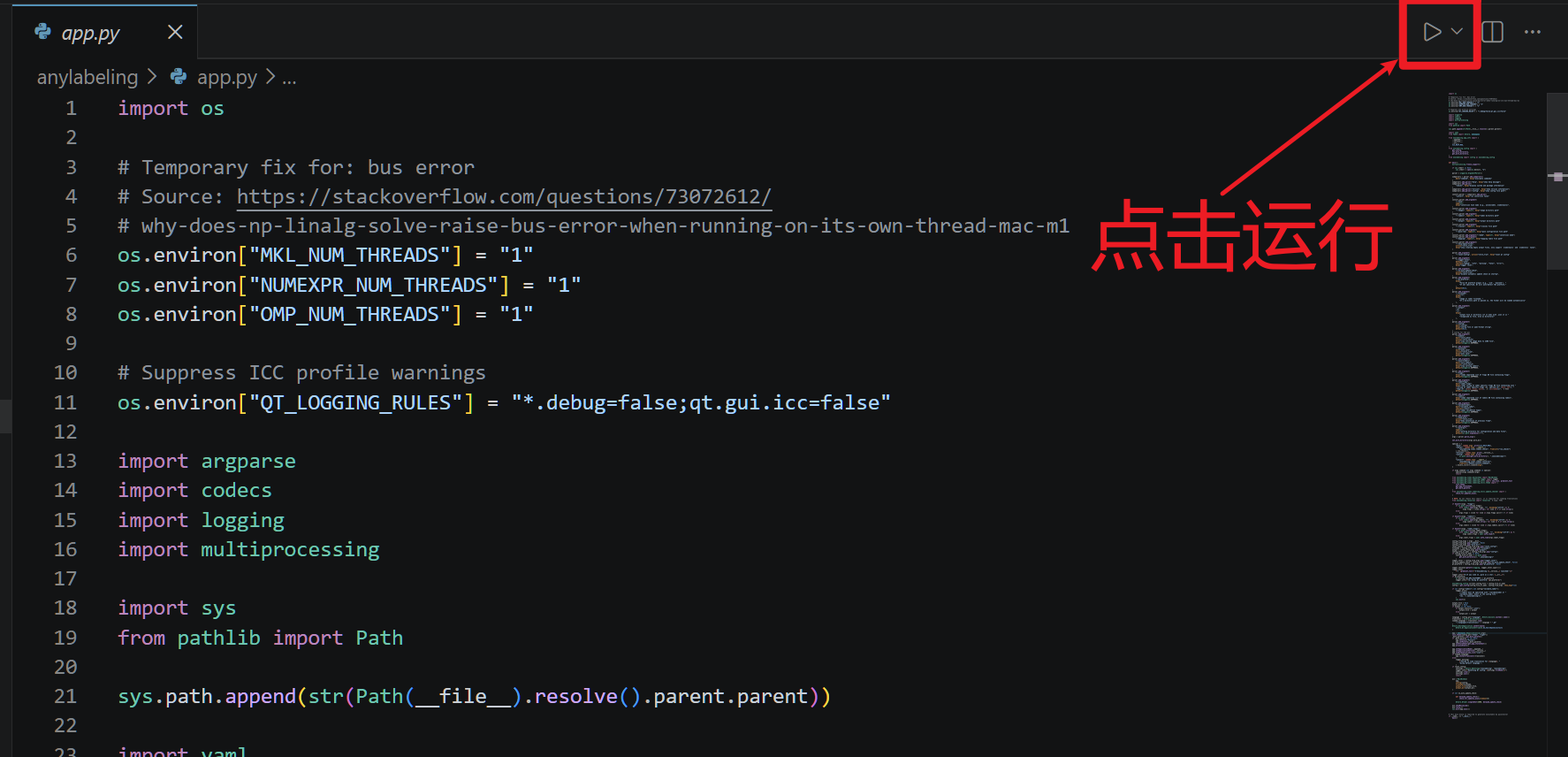
出现以下画面,代表启动正确:

我们发现我们打开了同一个界面
这样的好处是,打标的时候更快更稳定,且我们还可以根据自己的需求进行自定义
如自定义快捷键和自定义模型等操作
我们再来到X这个文件夹
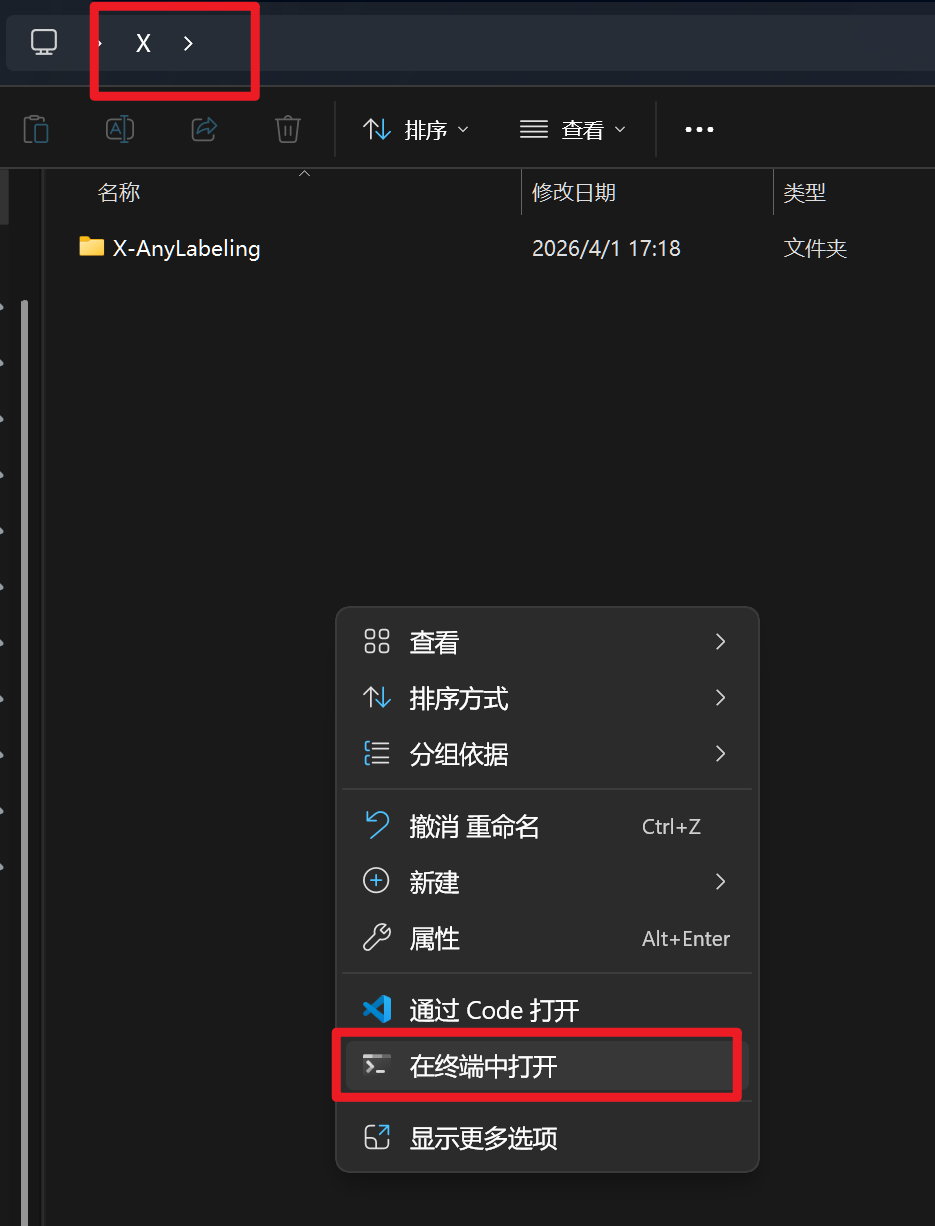
输入:
git clone https://github.com/Linmoqian/yolo_train![]()
这是我为大家准备的相关脚本,省去大家查资料敲代码的功夫
以同样的方法用vscode打开我们新下的文件夹
素材准备
接下来我们去网上找10张动物的照片(PNG或JPG格式)
当然我已经为大家准备好了,放在了your_data路径下
我们回到anylabeling,打开your_data的文件夹
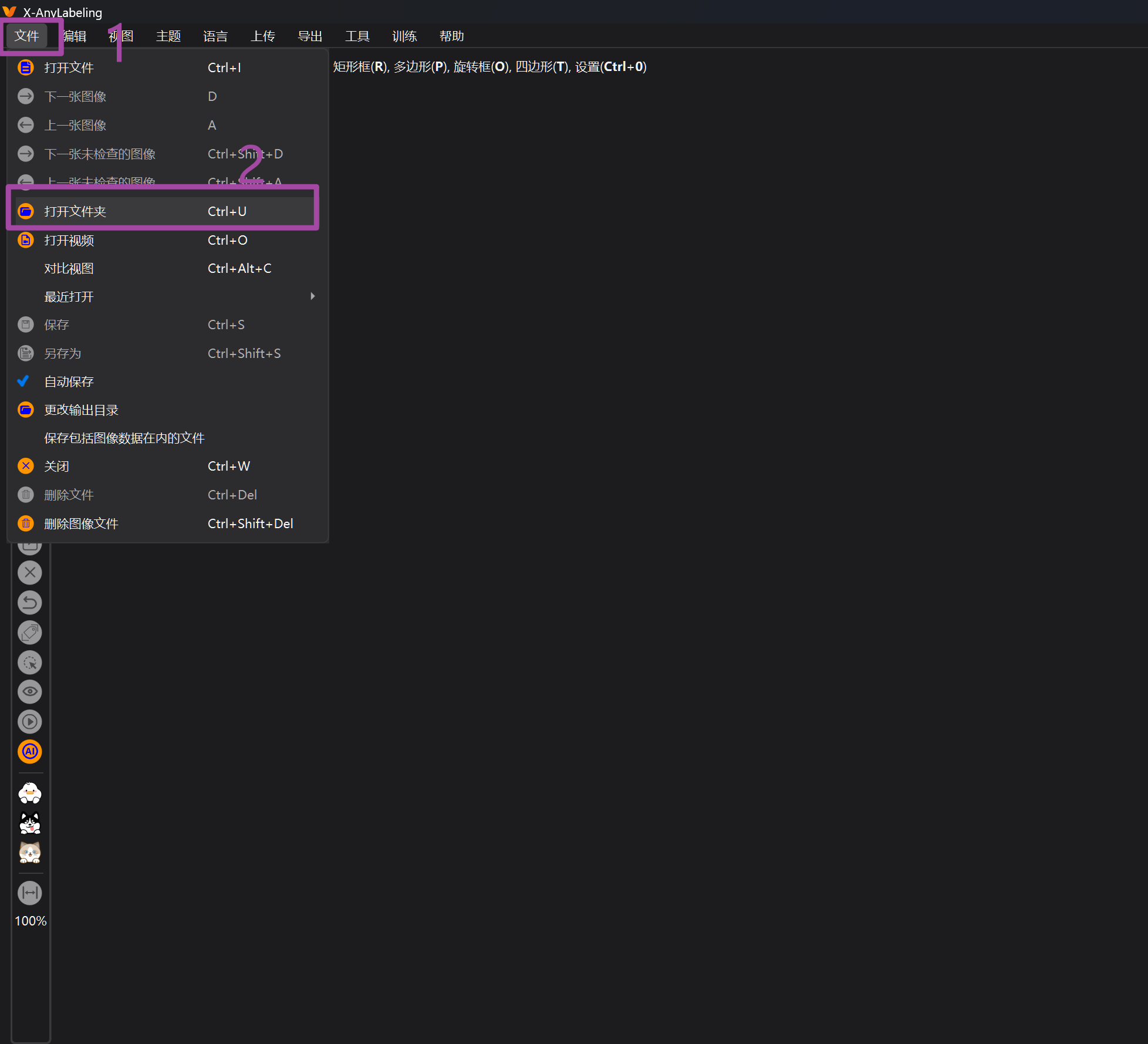
可能出现以下提示: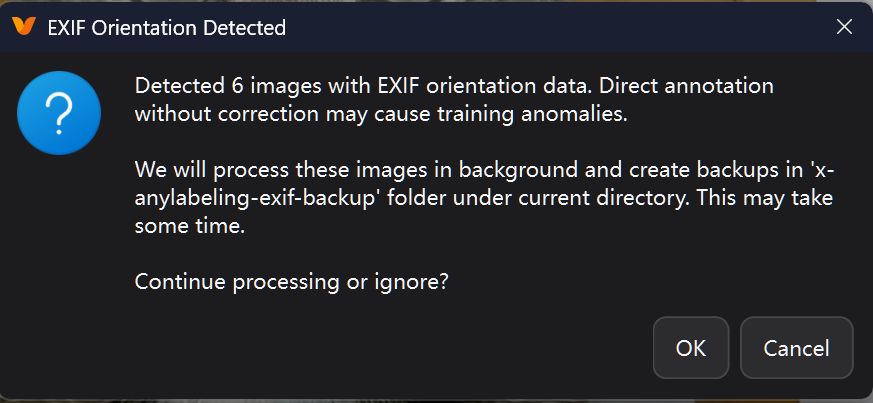
这是系统检测到部分图片包含EXIF方向信息(通常是手机拍摄的照片会带有这种信息,记录照片的旋转方向)
如果不处理这些EXIF方向数据,直接进行图像标注可能会导致:
-
标注位置与实际图像不匹配
-
训练模型时出现异常
-
标注结果不准确
因此,选择OK,等待处理完成
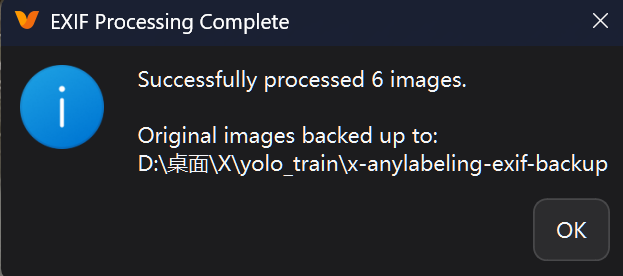
处理完成不要着急打标,要再一次打开图片所在的文件夹,进行刷新,避免未加载
(exe版本就会出现这个问题,源码版本不清楚,但是为了以防万一还是重新打开一下吧~)

接着我们点击右键
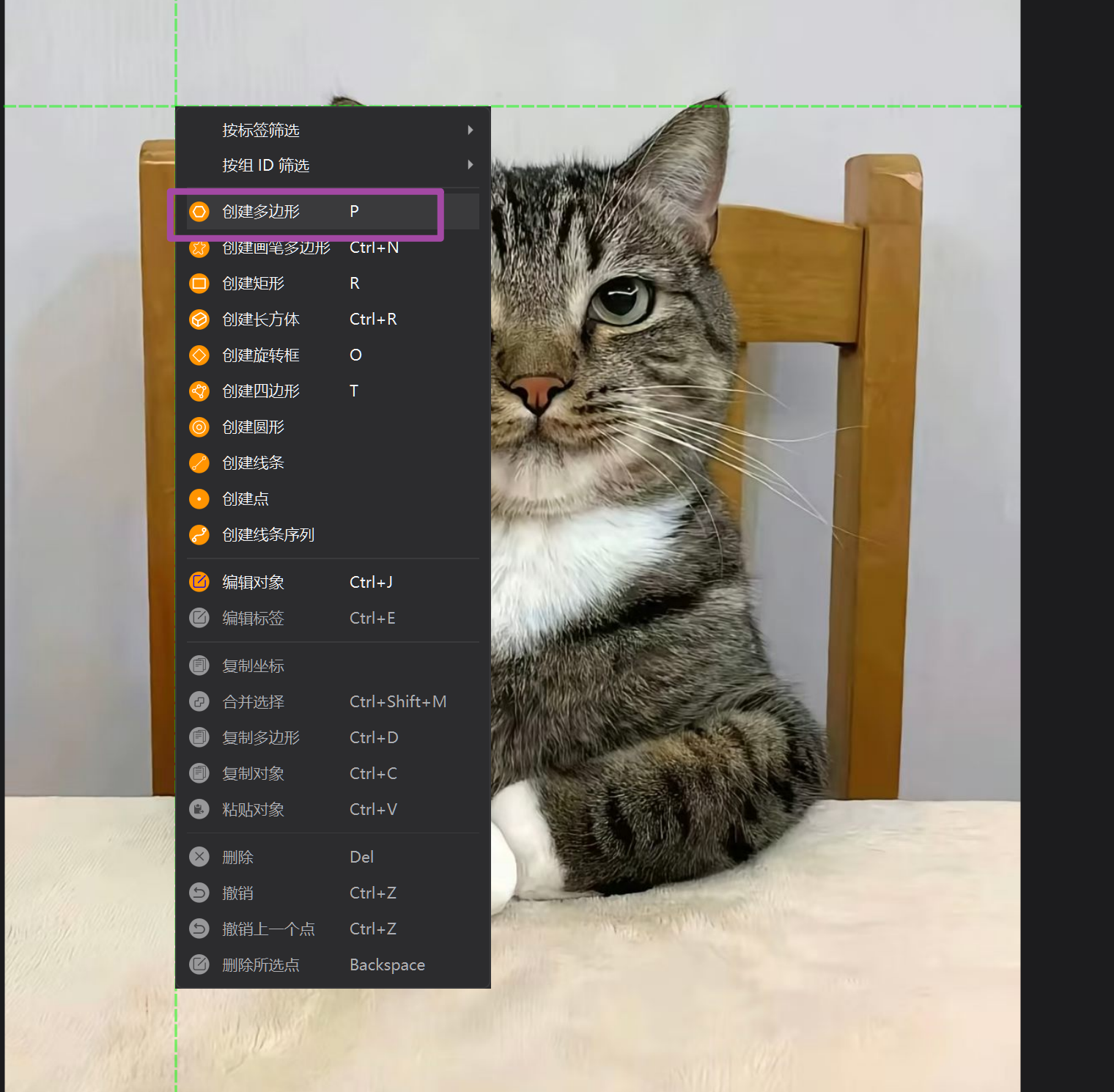
创建多边形或者创建矩形,选中后
 输入对应的标签
输入对应的标签
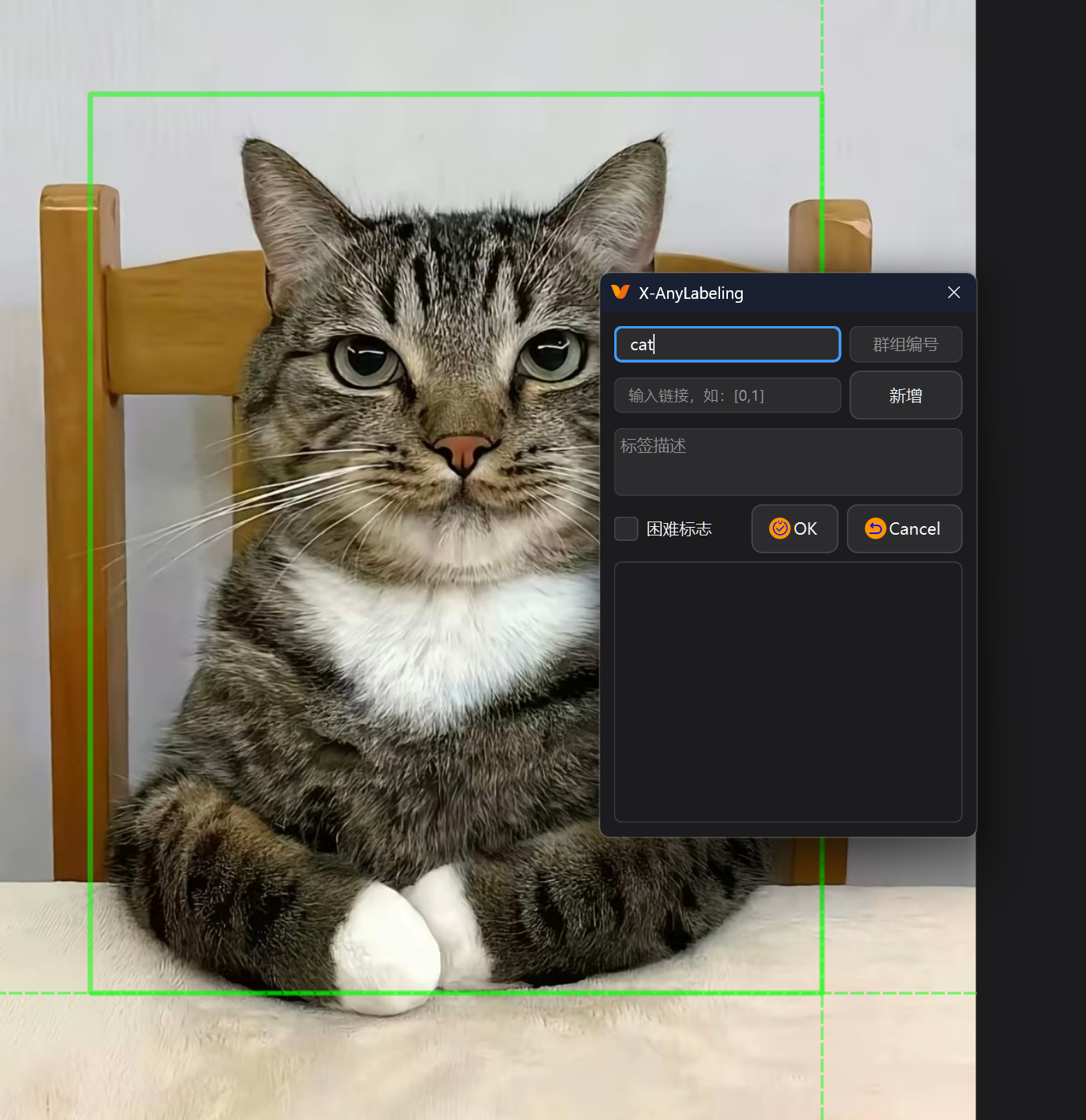
接着我们打下一张,以此类推,打完为止
确保自己全部打完
我们看到图片所在的文件夹,会发现,多出来了json文件
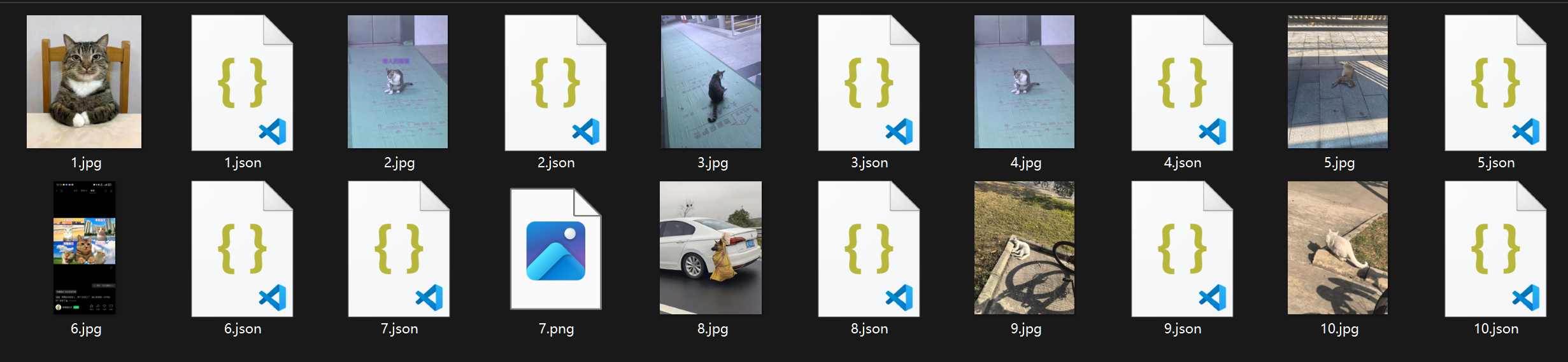
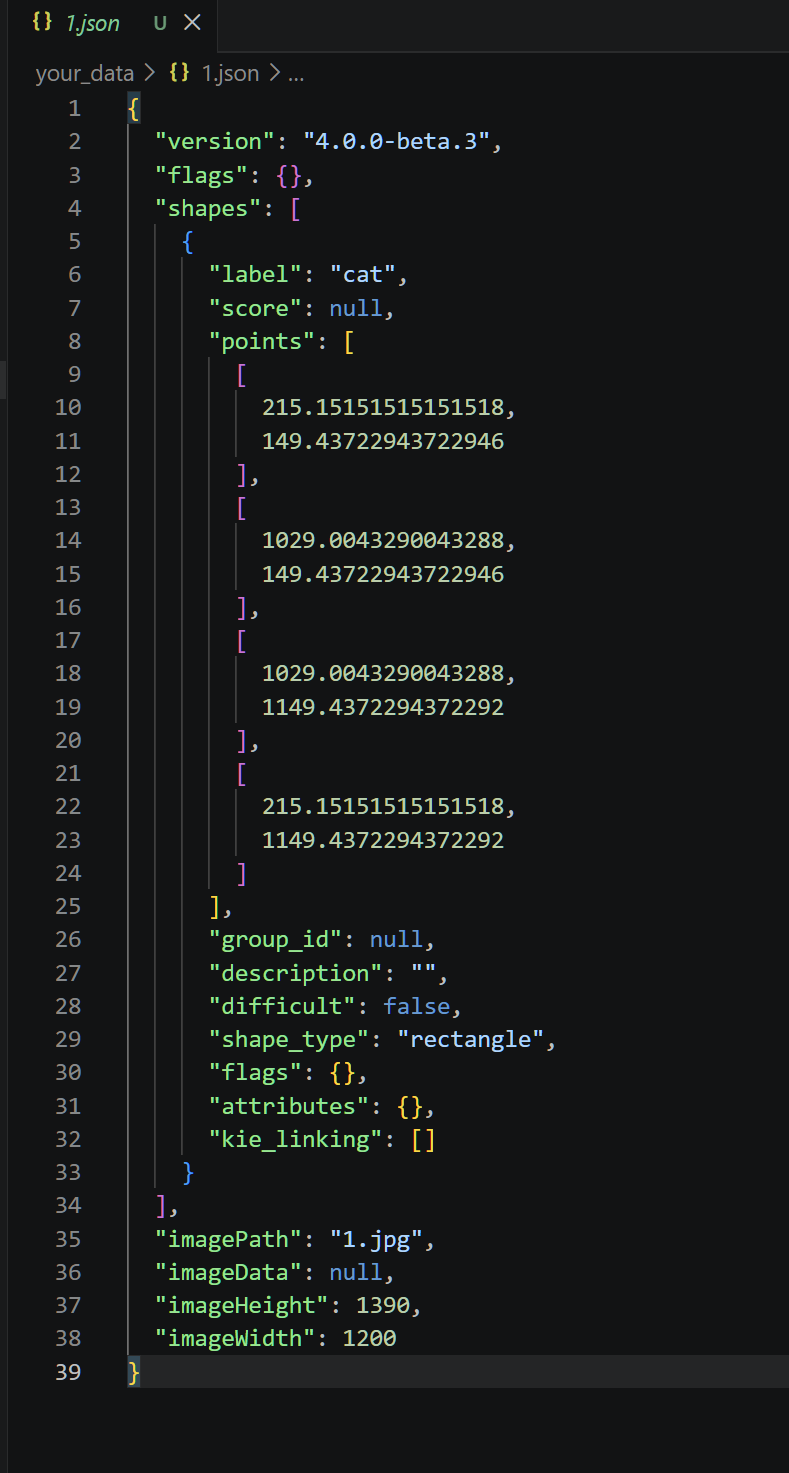
json文件里便记录了刚才我们打标时的信息
详细如下:
| 字段 | 值 | 作用说明 |
| version | "4.0.0-beta.3" | 标注工具的版本号(如LabelMe) |
| flags | {} | 全局标志位,用于图像级别的分类标签 |
| imagePath | "1.jpg" | 被标注图像的文件名/路径 |
| imageData | null | 图像的base64编码数据(null表示未嵌入) |
| imageHeight | 1390 | 图像高度(像素) |
| imageWidth | 1200 | 图像宽度(像素) |
| 字段 | 值 | 作用说明 |
| `label` | "cat" | 类别标签(猫) |
| `score` | null | 检测置信度(手动标注为null,自动检测时有值) |
| `shape_type` | "rectangle" | 标注形状类型(矩形框) |
| `points` | [[x1,y1], [x2,y2], [x3,y3], [x4,y4]] | 边界框坐标点(4个顶点) |
| `group_id` | null | 分组ID(用于关联多个标注) |
| `description` | "" | 文字描述 |
| `difficult` | false | 是否困难样本(用于评估) |
| `flags` | {} | 该标注的特定标志 |
| `attributes` | {} | 扩展属性(如颜色、姿态等) |
| `kie_linking` | [] | 关键信息提取的链接关系 |
每个shape代表一个标注框
但是我们先不管那么多,下一步,找到我为大家提供的这个脚本
json2txt.py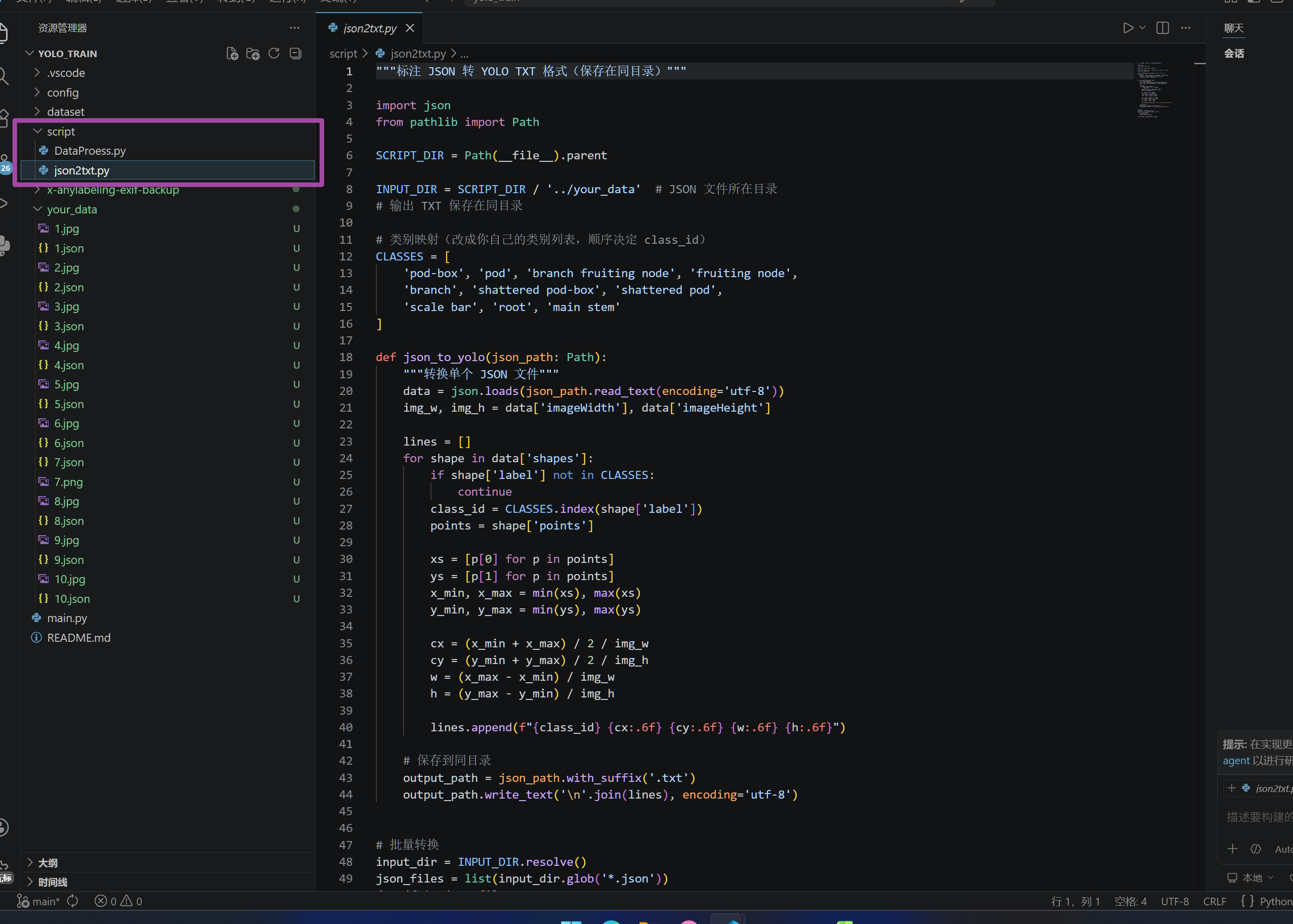
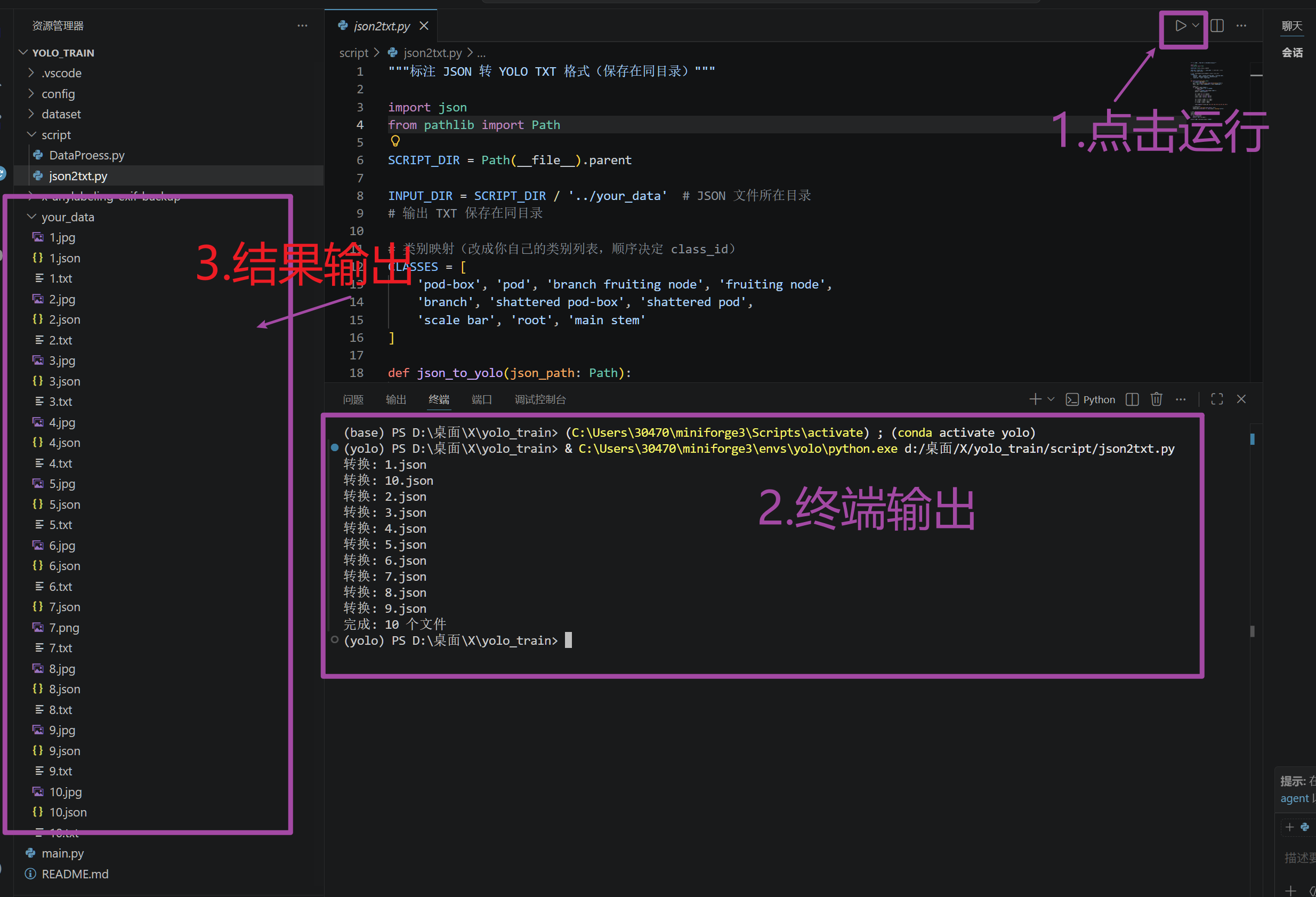
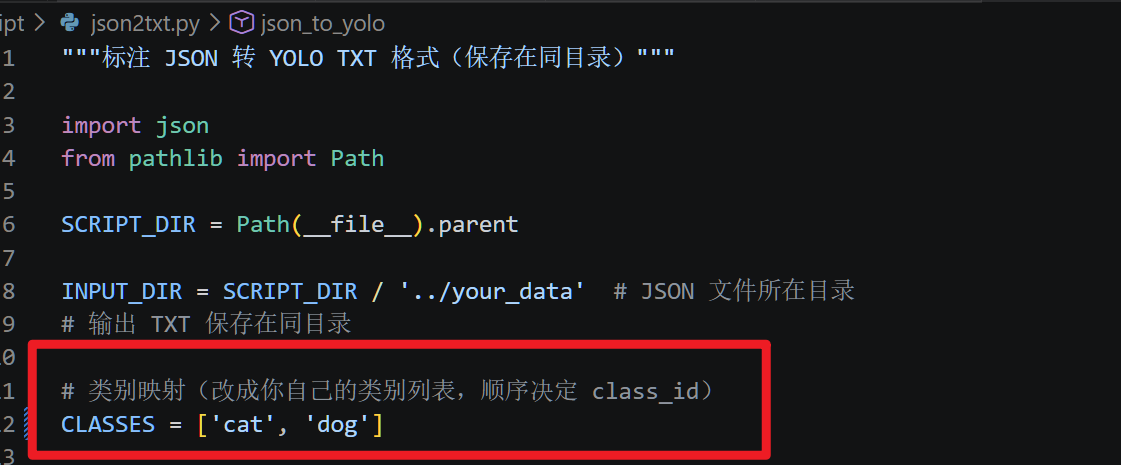
注意需要将类别映射修改
再换到下一个脚本,进行数据集划分
DataProess.py
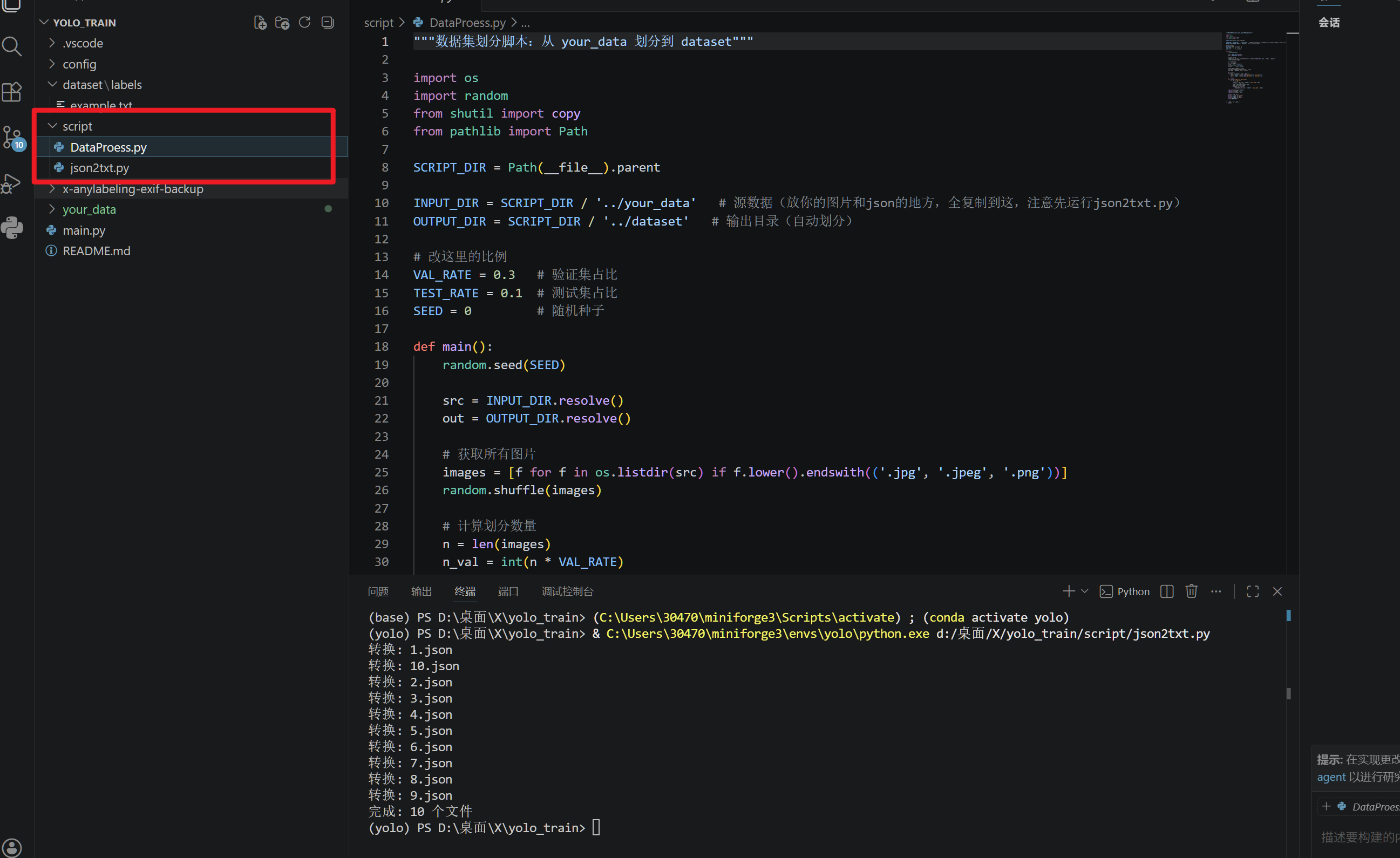
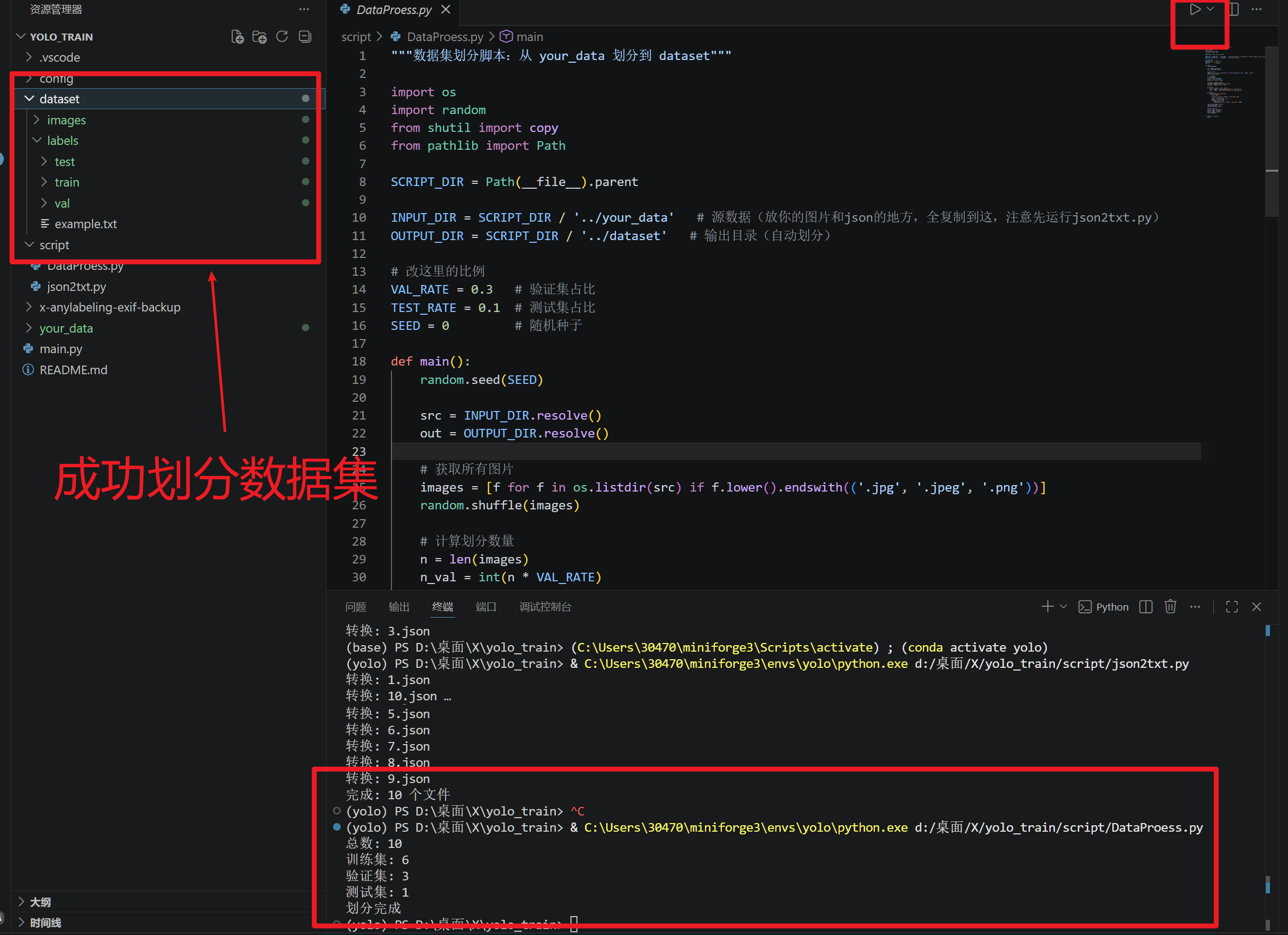
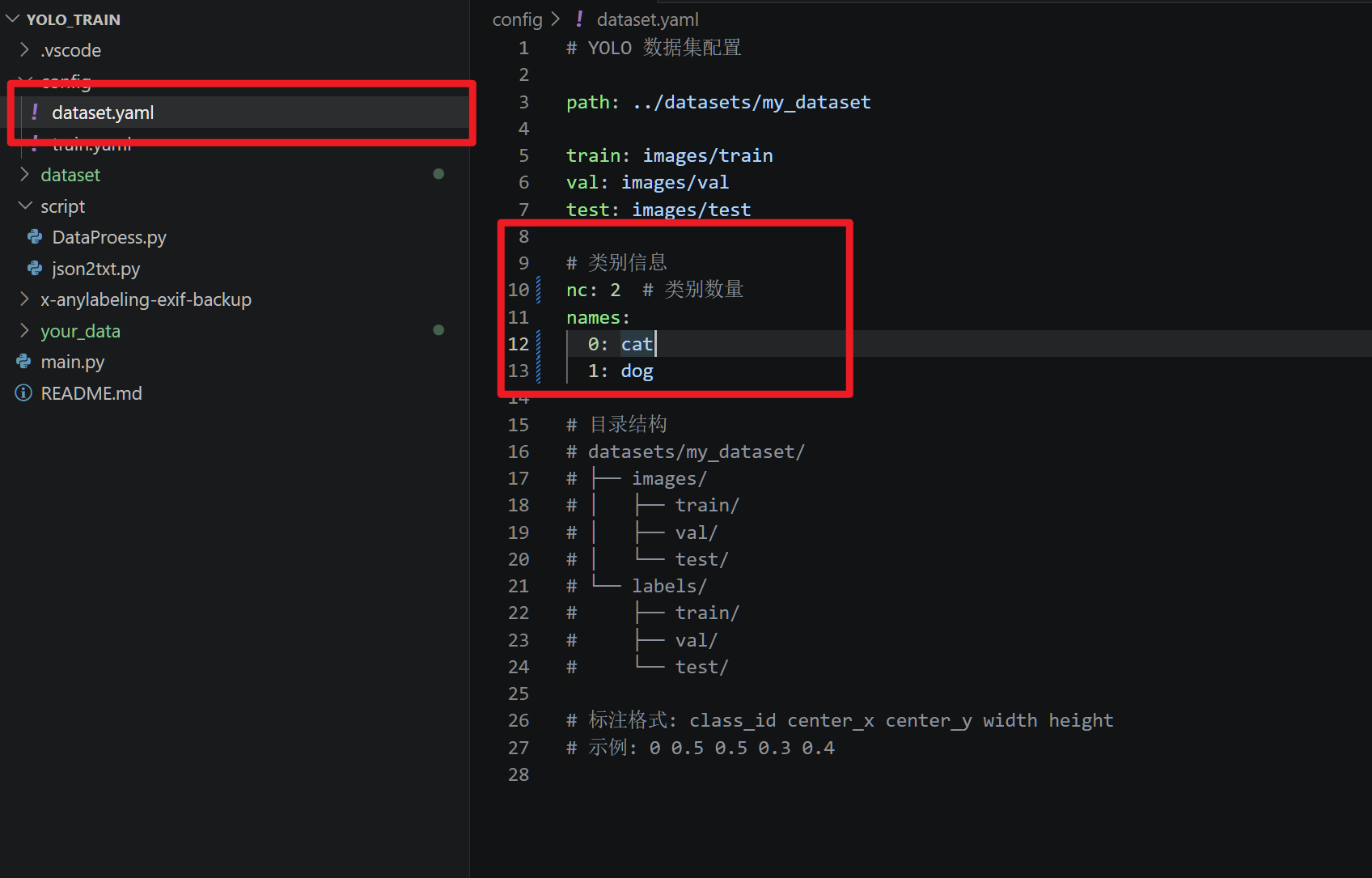
接下来修改数据集配置
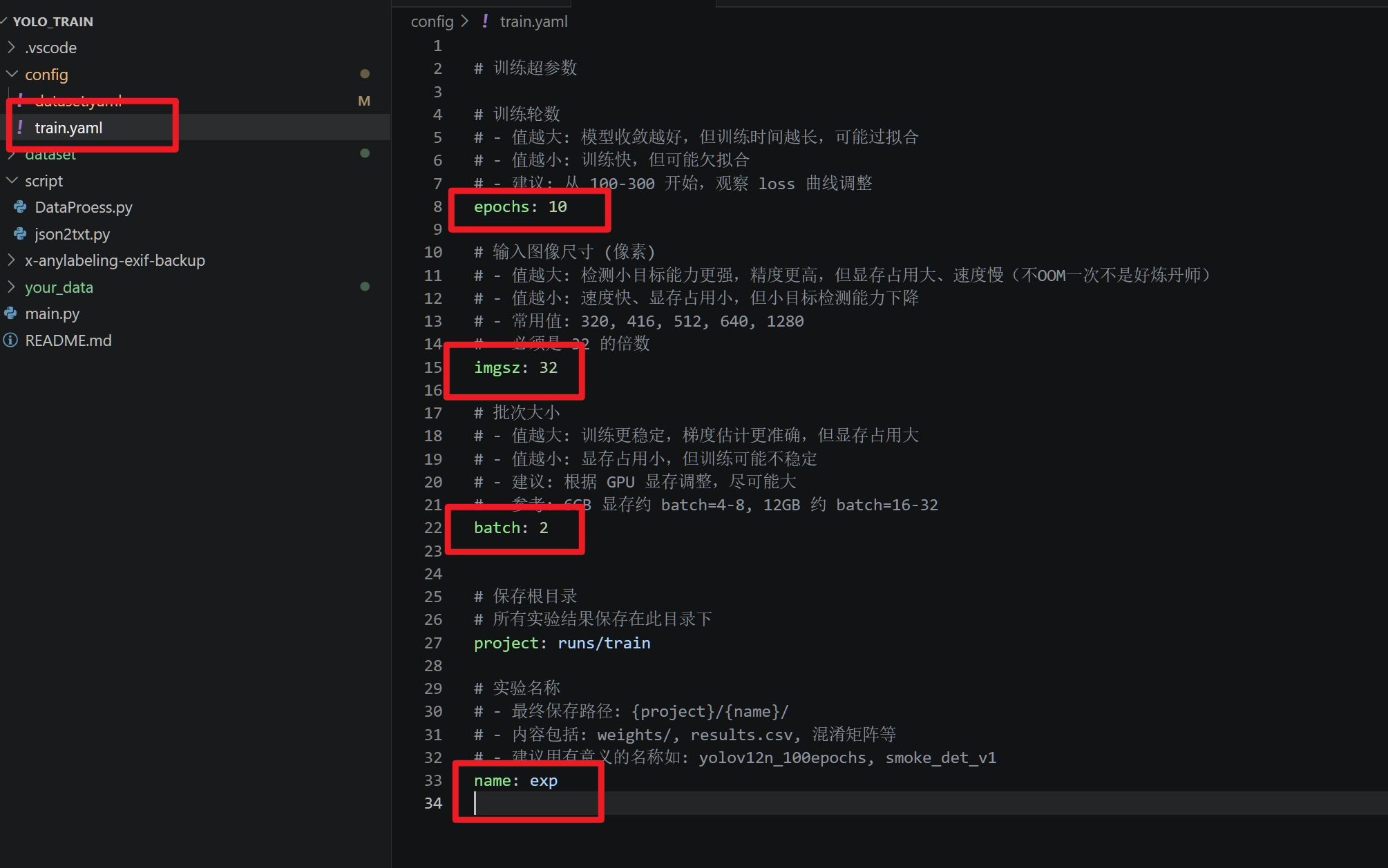
修改训练参数配置(根据自己的硬件能力量力而行噢)
训练
回到佛祖保佑的代码,进行运行
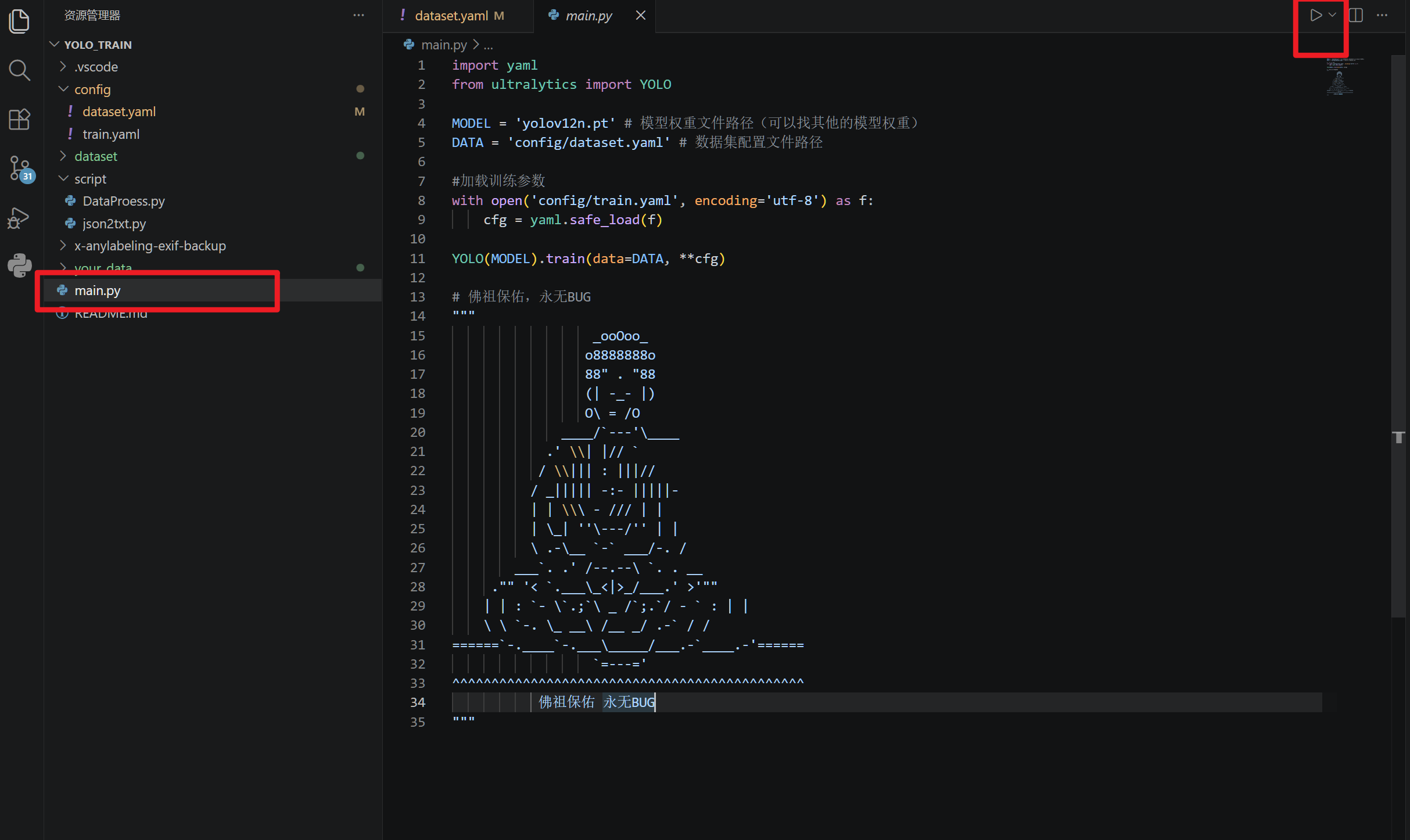
出现以下情况,代表我们训练成功
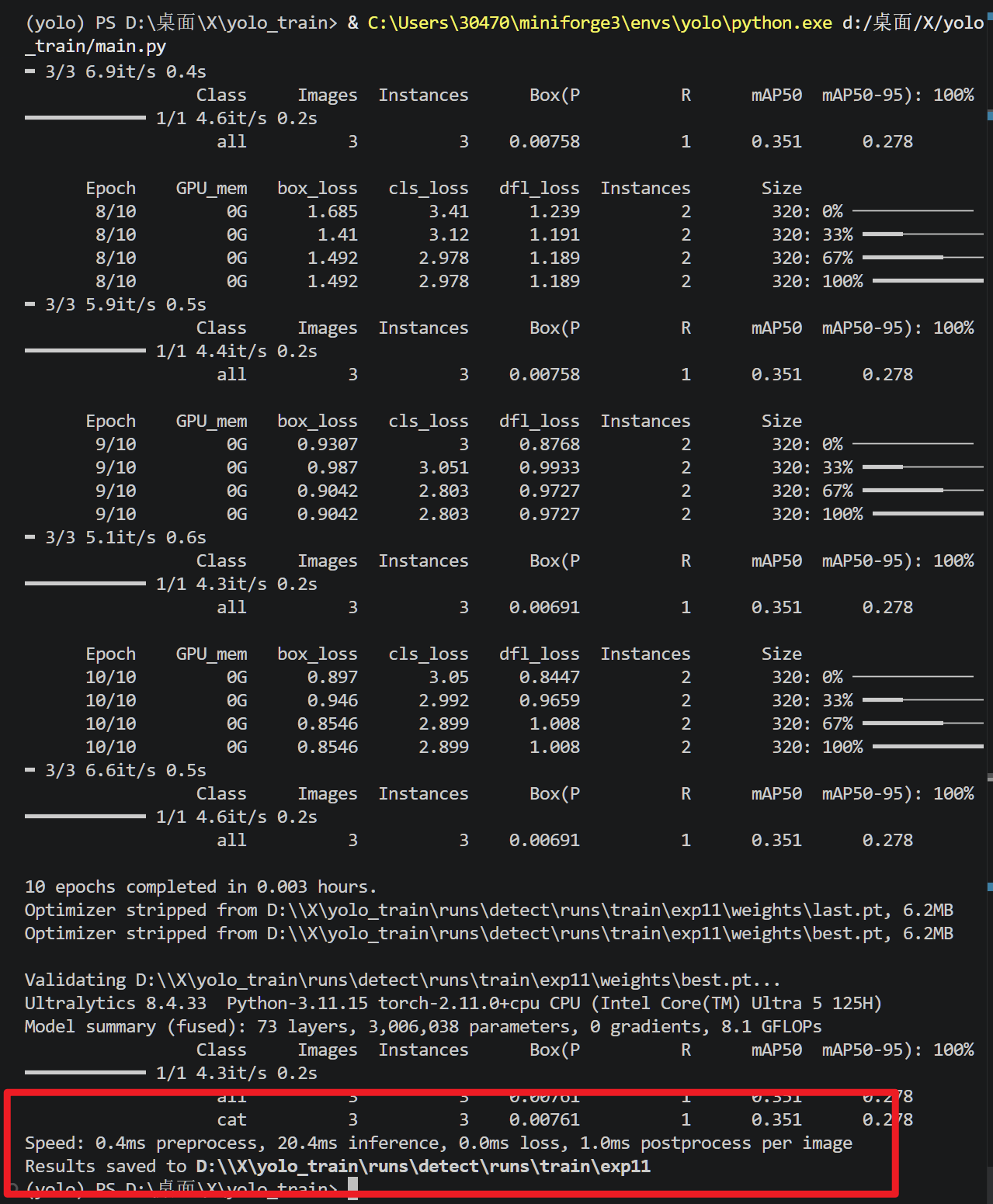
训练的开头会打印模型网络参数,包括模型每一层所使用的模块(module),以及该层的参数(arguements)
from表示该层的输入是从第几层来的,若为-1则表示该层是输入是上一层是输出,n表示该模块的重复次数
arguement中的第一个元素一般表示输入维度,第二个元素一般表示输出维度,若为卷积层(Conv)第三个元素则表示卷积核大小(kernal_size),第四个元素表示卷积核每次移动的步幅(stride)
训练的过程中会打印每个epoch的各类信息,包括显存占用(GPU_mem)、边界框损失(box_loss)、分割损失(seg_loss)、分类损失(cls_loss)、分布焦点损失(dfl_loss)、实例数量(Instance)、图像大小(Size),以及基于分类(Class)和掩码(Mask)的精确率(Precision—P)、召回率(Recall—R)、IoU阈值为50的平均精度均值(mAP50)和IoU阈值范围在50到95之间的平均精度均值(mAP50-95)
训练结束后,会模型进行一次验证(Val),打印验证结构会回将模型的权重文件保存在runs中,如下:
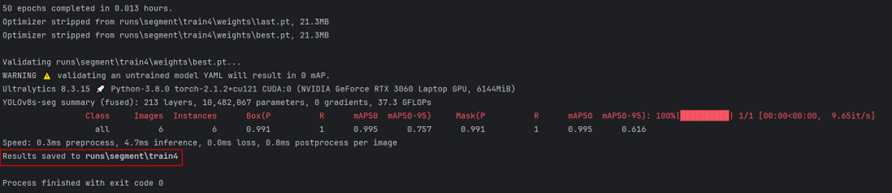
现在来看看训练的效果吧

效果很好
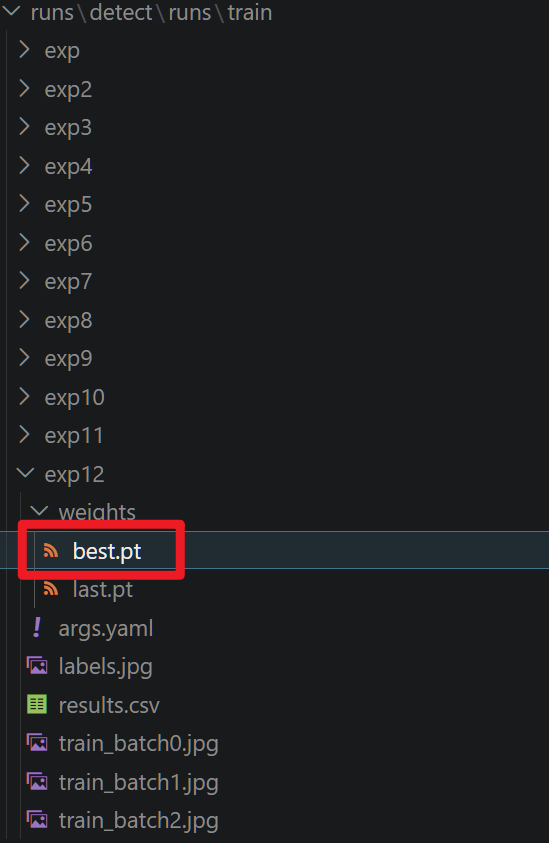
找到这里的best.pt,就是训练好的模型权重啦~
我们可以把它导为其他类型的格式,如ONNX,在边缘设备上进行推理!
想要测试推理的效果,千万不要拿给模型训练过的照片去测评!
不然这和期末考试老师直接给你答案有什么区别(有这好事?)
推理代码如下,自己尝试一下吧~
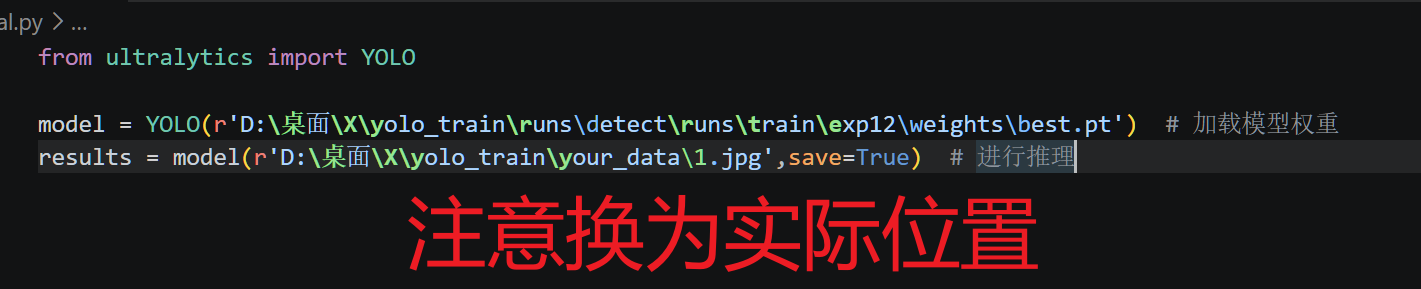
接下大家可以尝试:
标注自己的好兄弟为:dog
然后,尝试调用电脑摄像头进行实时推理!
至于如何调整YOLO的模型架构、制作自己的模块,下一期出(猴年马月吧)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)