ELK Stack 落地实战:搭建、配置与日志测试
ES 版本:7.17.11JDK 版本: 1.8.0_211filebeat 版本: 7.17.11kibana 版本:7.17.11logstash 版本:7.17.11kafka 版本:2.13-2.4.0(版本低于2.8 单节点也需要Zookeeper)Zookeeper 版本:3.8.5ip安装的应用ES Kibana。
ES 版本:7.17.11
JDK 版本: 1.8.0_211
filebeat 版本: 7.17.11
kibana 版本:7.17.11
logstash 版本:7.17.11
kafka 版本:2.13-2.4.0(版本低于2.8 单节点也需要Zookeeper)
Zookeeper 版本:3.8.5
|
ip |
安装的应用 |
|
192.168.116:128 |
ES Filebeat |
|
192.168.116.129 |
ES Logstash |
|
192.168.116.130 |
ES Kibana |
|
192.168.116.131 |
Zookeeper kafka |
安装
所有节点安装jdk 1.8.0_211
#>>> 解压jdk到指定目录
$ tar xf jdk-8u211-linux-x64.tar -C /usr/local/
#>>> 创建软链接
$ cd /usr/local/
$ ln -s jdk1.8.0_211/ java
#>>> 声明Java环境变量
$ cat >> /etc/profile.d/jdk.sh <<-EOF
#!/bin/bash
export JAVA_HOME=/usr/local/java
export PATH=\$PATH:\$JAVA_HOME/bin
EOF
#>>> 重新加载配置文件
$ source /etc/profile.d/jdk.sh
#>>> 测试java
$ java -version
java version "1.8.0_211"
Java(TM) SE Runtime Environment (build 1.8.0_211-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.211-b12, mixed mode)安装ES
#>>> 创建用于启动ES的用户
$ useradd es
$ id es
uid=1000(elasticsearch) gid=1000(elasticsearch) 组=1000(elasticsearch)
#>>> 创建ES数据目录和日志目录存放目录
$ mkdir -p /opt/{data,logs}
$ install -d /opt/{data,logs}/es -o es -g es
#>>> 解压es安装包到指定目录
$ tar xf elasticsearch-7.17.11-linux-x86_64.tar.gz -C /opt/
#>>> 更改目录名
$ cd /opt/ && mv elasticsearch-7.17.11 es
#>>> 创建ES环境变量
$ vim >> /etc/profile.d/es.sh <<-EOF
#! /bin/bash
export ES_HOME=/opt/es
export PATH=\$PATH:\$ES_HOME/bin
EOF
#>>> 重新加载环境变量
$ source /etc/profile.d/es.sh
#>>> 修改elasticsearch属主和数组
$ chown -R es,es /opt/es
#>>> 修改es需要的limits参数(重新连接会话框才能成功加载参数)
$ cat >> /etc/security/limits.d/elk.conf <<-EOF
* soft nofile 65535
* hard nofile 131070
EOF
#>>> 查看limits参数是否加载
$ ulimit -Sn
65535
$ ulimit -Hn
131070
#>>> 修改内核参数
$ cat > /etc/sysctl.d/elk.conf <<EOF
vm.max_map_count = 262144
EOF
#>>> 加载内核参数
$ sysctl -f /etc/sysctl.d/elk.conf
vm.max_map_count = 262144
$ sysctl -q vm.max_map_count
vm.max_map_count = 262144
#>>> 修改堆内存大小(最大设置为32G,要么内存的一半)
$ vim /opt/elasticsearch-7.17.11/config/jvm.options
···
-Xms256m
-Xmx256m
···#>>> elk01修改配置文件
$ egrep -v "^(#|$)" /opt/es/config/elasticsearch.yml
cluster.name: study-elk-cluster #集群名称
node.name: elk01 #节点名称
path.data: /opt/data/es # 指定数据目录
path.logs: /opt/logs/es # 指定日志目录
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.116.128","192.168.116.129","192.168.116.130"]
cluster.initial_master_nodes: ["192.168.116.128","192.168.116.129","192.168.116.130"]
ingest.geoip.downloader.enabled: false#>>> elk02修改配置文件
$ egrep -v "^(#|$)" /opt/es/config/elasticsearch.yml
cluster.name: study-elk-cluster
node.name: elk02
path.data: /opt/data/es
path.logs: /opt/logs/es
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.116.128","192.168.116.129","192.168.116.130"]
cluster.initial_master_nodes: ["192.168.116.128","192.168.116.129","192.168.116.130"]
ingest.geoip.downloader.enabled: false#>>> elk03修改配置文件
$ egrep -v "^#|^$" /opt/es/config/elasticsearch.yml
cluster.name: study-elk-cluster
node.name: elk03
path.data: /opt/data/es
path.logs: /opt/logs/es
network.host: 0.0.0.0
discovery.seed_hosts: ["192.168.116.128","192.168.116.129","192.168.116.130"]
cluster.initial_master_nodes: ["192.168.116.128","192.168.116.129","192.168.116.130"]
ingest.geoip.downloader.enabled: false启动ES
#>>> 所有节点添加elk启动脚本
$ cat > /usr/lib/systemd/system/es.service <<EOF
[Unit]
Description=ELK
After=network.target
[Service]
Type=forking
ExecStart=/opt/es/bin/elasticsearch -d
Restart=no
User=es
Group=es
LimitNOFILE=131070
[Install]
WantedBy=multi-user.target
EOF
#>>> 所有节点重新加载并启动
$ systemctl daemon-reload
$ systemctl restart es
#>>> 测试集群
[root@elk01 ~]# curl 192.168.116.128:9200/_cat/nodes
192.168.116.130 62 64 1 0.31 0.13 0.07 cdfhilmrstw * elk03
192.168.116.128 38 46 21 0.48 0.16 0.09 cdfhilmrstw - elk01
192.168.116.129 43 64 1 0.02 0.04 0.08 cdfhilmrstw - elk02安装Kibana(elk03节点)
#>>> 安装kibana
$ yum localinstall -y kibana-7.17.11-x86_64.rpm
#>>> 备份配置文件
$ cd /etc/kibana/
$ cp kibana.yml kibana.yml.bak
#>>> 修改kibana配置文件
$ egrep -v "^(#|$)" kibana.yml
server.port: 5601
server.host: "0.0.0.0"
server.name: "study-elk-kibana"
elasticsearch.hosts: ["http://192.168.116.128:9200","http://192.168.116.129:9200","http://192.168.116.130:9200"]
i18n.locale: "zh-CN"
#>>> 启动Kibana
$ systemctl enable --now kibana
#>>> 游览器IP+5601访问Logstash安装(elk02节点)
#>>> 安装Logstash
$ yum localinstall -y logstash-7.17.11-x86_64.rpm
#>>> 创建软连接
$ ln -s /usr/share/logstash/bin/logstash /usr/bin/logstashFilebeat安装(elk01)
参考文档:https://www.elastic.co/guide/en/beats/filebeat/7.17/index.html
# Step 1:elk01主机安装Filebeat
$ yum localinstall -y filebeat-7.17.11-x86_64.rpm测试Filebeat输出数据至Elasticsearch集群
官方链接:
https://www.elastic.co/guide/en/beats/filebeat/7.17/elasticsearch-output.html#elasticsearch-output
#>>> 编写Filebeat配置文件
$ vim filebeat-config/06-log-nginx-access-es.yml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
tags: ["nginx_access"]
fields:
log_type: nginx_access
fields_under_root: true
# 输出至ES集群
output.elasticsearch:
# ES集群地址
hosts: ["http://192.168.174.140:9200","http://192.168.174.141:9200","http://192.168.174.142:9200"]
#>>> 启动Filebeat实例
$ filebeat -e -c /root/filebeat-config/06-log-nginx-access-es.yml安装Zookeeper
$ tar xf apache-zookeeper-3.8.5-bin.tar.gz -C /usr/local && cd /usr/local
$ mv apache-zookeeper-3.8.5-bin/ zookeeper
#>>> 配置zk环境变量
$ cat /etc/profile.d/zookeeper.sh
#!/bin/bash
export ZK_HOME=/usr/local/zookeeper
export PATH=$PATH:$ZK_HOME/bin
#>>> 重新加载环境变量
$ source /etc/profile.d/zookeeper.sh
# 创建zk数据存放目录
$ mkdir -p /usr/local/data/zk
#>>> 修改zk的配置文件
$ cp /usr/local/zookeeper/conf/zoo_sample.cfg /usr/local/zookeeper/conf/zoo.cfg
$ egrep -v "^(#|$)" /usr/local/zookeeper/conf/zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/data/zk
clientPort=2181
#>>> 启动Zookeeper
$ /usr/local/zookeeper/bin/zkServer.sh start
$ /usr/local/zookeeper/bin/zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: standalone #显示standlone表示启动成功安装kafka
$ tar xf kafka_2.13-2.4.0.tgz -C /usr/local/
$ cd /usr/local
$ mv kafka_2.13-2.4.0/ kafka
$ cat /etc/profile.d/kafka.sh #配置环境变量
#!/bin/bash
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#>>> 重新加载环境变量
$ source /etc/profile.d/kafka.sh
#>>> 创建数据目录
$ mkdir /usr/local/data/kafka -p
修改kafka的配置文件
$ egrep -v "^(#|$)" /usr/local/kafka/config/server.properties
broker.id=0
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://192.168.116.131:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/usr/local/data/kafka/
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.116.131:2181/kafka
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
#>>>启动kafka
$ /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
$ ps -ef | grep kafka #看是否有kafka的进程
#也可以创建一个topic验证是否成功
$ /usr/local/kafka/bin/kafka-topics.sh --create --bootstrap-server 192.168.116.131:9092 --topic test_topic --partitions 1 --replication-factor 1
$ /usr/local/kafka/bin/kafka-topics.sh --list --bootstrap-server 192.168.116.131:9092
test_topic测试
将日志从filebeat收集到kafka中
[root@elk01 ~]# cat filebeat-out-kafka.yml
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/access.log
json.keys_under_root: true
output.kafka:
hosts: ["192.168.116.131:9092"]
topic: "test-kafka-topic"将日志从kafka收集到logstash并转发给ES
[root@elk02 ~]# cat ctgkafka.conf
input {
kafka {
bootstrap_servers => "192.168.116.131:9092"
topics => ["test-kafka-topic"] # 消费的Kafka Topic
group_id => "test-kafka" # 消费者组ID
auto_offset_reset => "latest" # 新增:从最新日志开始消费
codec => json { # 解析JSON格式日志
charset => "UTF-8"
}
}
}
filter {
mutate {
remove_field => ["agent","ephemeral_id","ecs","@version","tags","input","log","offset"]
}
if [log_type] == "nginx_access" {
geoip {
source => "clientip" # 解析客户端IP的地理位置(需确保日志中有clientip字段)
}
useragent {
source => "http_user_agent" # 解析浏览器UA
target => "study_user_agent"
}
} # 补充:修复if语句的闭合括号(原配置可能缺失)
}
output {
# 1. 输出到ES集群(核心配置)
elasticsearch {
hosts => ["192.168.116.128:9200", "192.168.116.129:9200", "192.168.116.130:9200"] # 替换为你的ES集群节点IP:端口
index => "nginx-log-%{+YYYY.MM.dd}" # 按日期创建ES索引(方便Kibana按时间筛选)
document_type => "_doc" # ES 7+ 版本固定为_doc
}
# 2. 保留控制台输出(调试用)
stdout { codec => rubydebug }
}在kibana展示
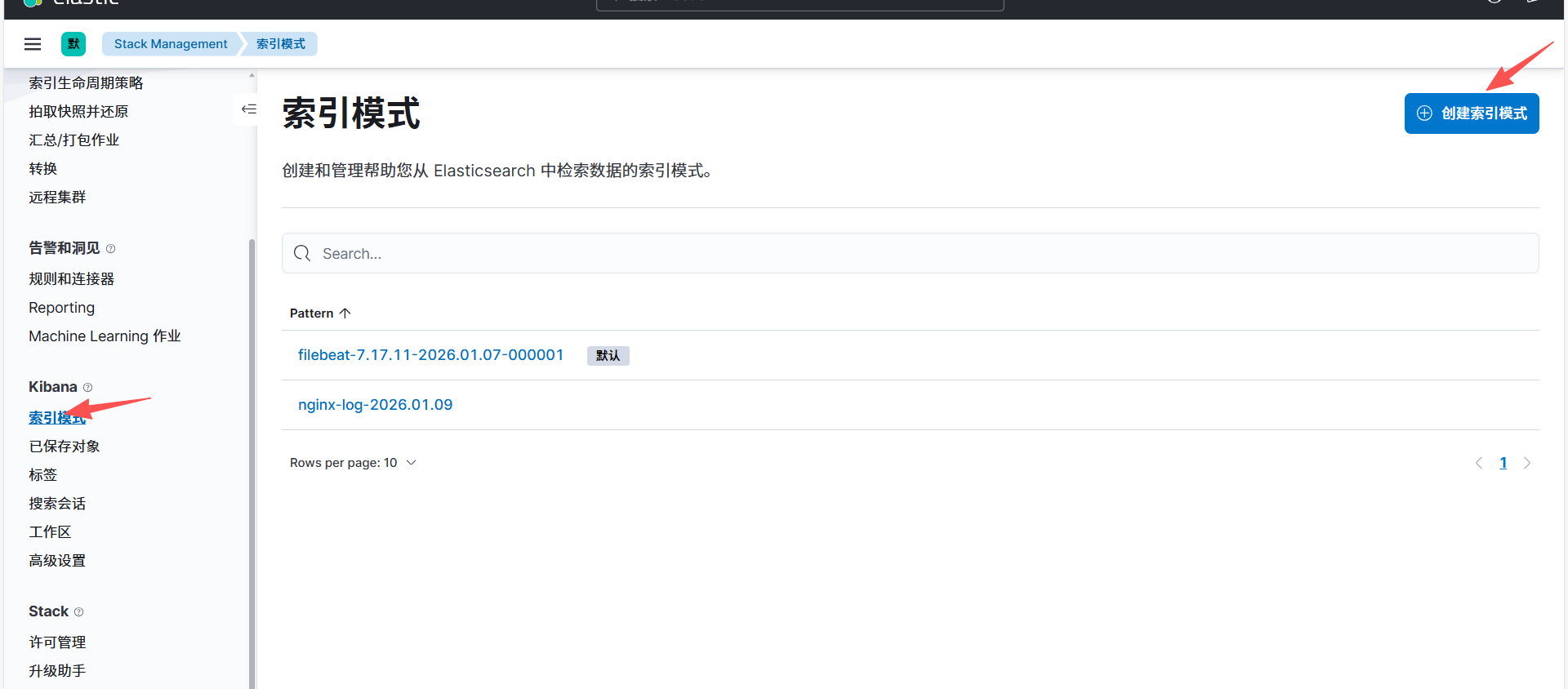
在 Kibana 中创建 “索引模式”
索引模式是 Kibana 关联 ES 索引的桥梁,需匹配 ES 中存储日志的索引名称(比如之前配置的nginx-log-*):
进入 Kibana 页面,点击左侧菜单栏的 Stack Management(堆叠管理);
在 “Kibana” 分类下,选择 Index Patterns(索引模式);
点击右上角 Create index pattern(创建索引模式);创建索引
查看是否创建成功
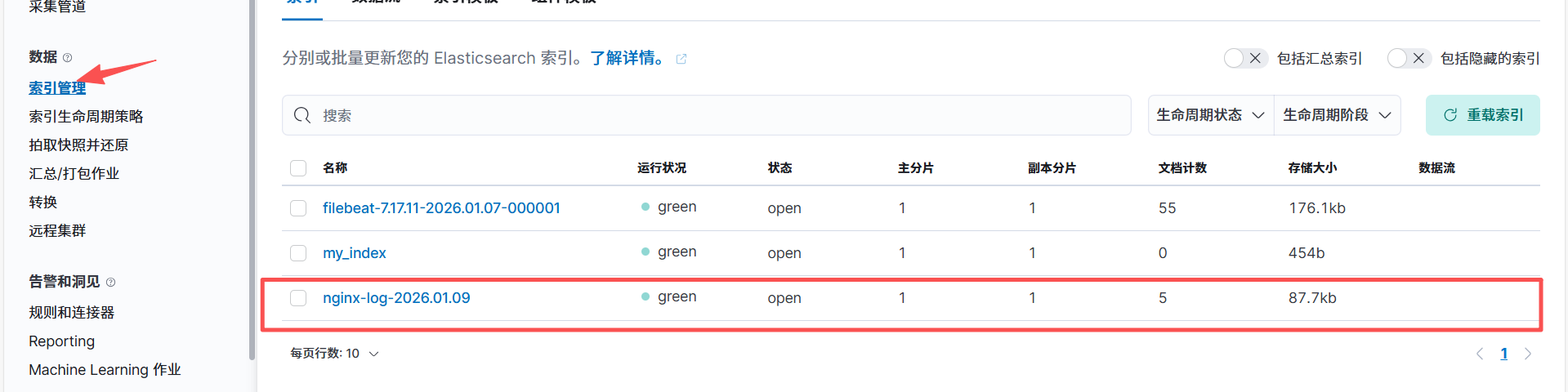
查看数据
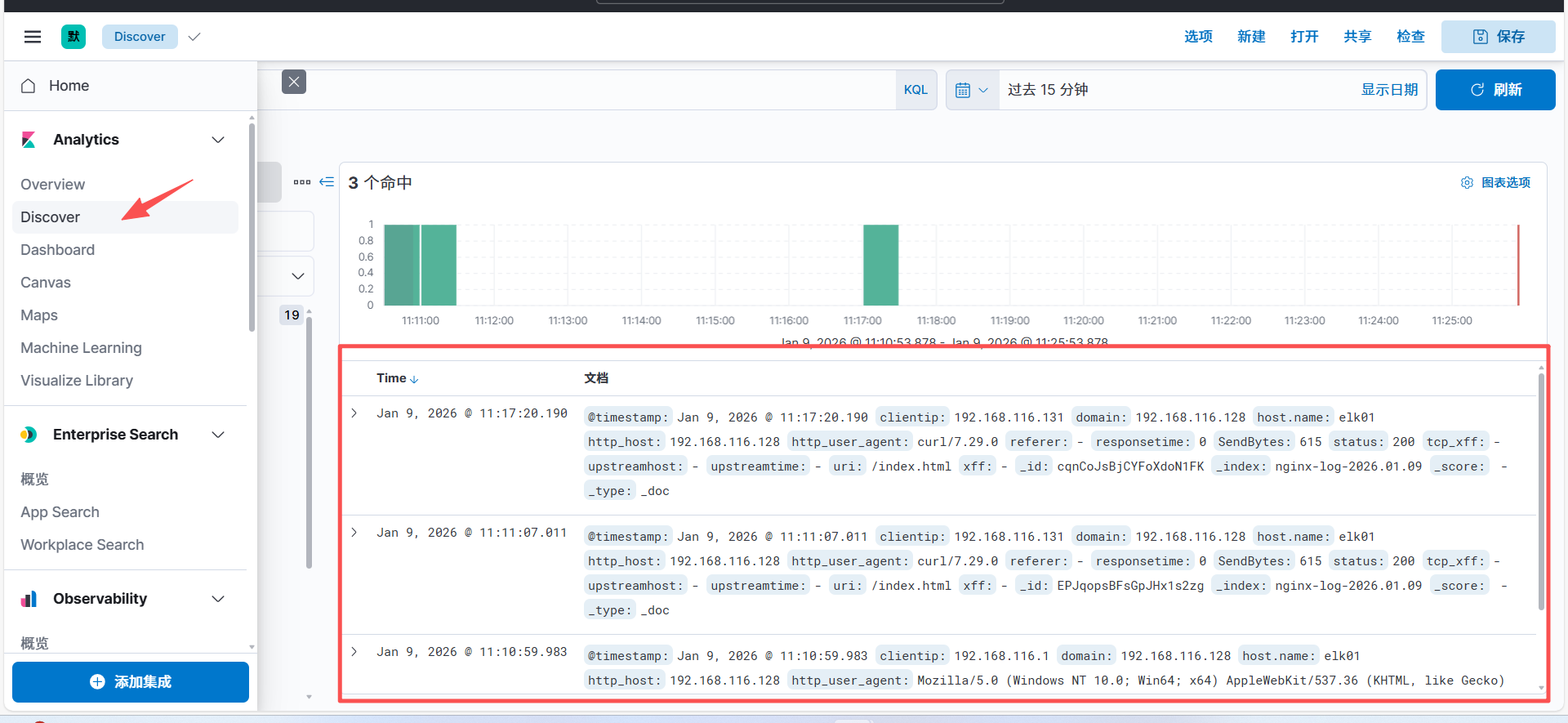
从filebeat收集到kafka(后台运行)
[Unit]
Description=Filebeat (后台采集Nginx日志发送到Kafka)
After=network.target
Wants=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/filebeat/filebeat -c /root/filebeat-out-kafka.yml
ExecStop=/usr/local/filebeat/filebeat stop
Restart=on-failure
RestartSec=5
StandardOutput=journal+console
StandardError=journal+console
[Install]
WantedBy=multi-user.target启动命令
systemctl daemon-reload #重载systemd配置
systemctl start filebeat #启动Filebeat
systemctl status filebeat #验证运行状态验证是否真的后台采集并发送日志
# 1. 查看 Filebeat 进程是否后台运行
ps -ef | grep filebeat
# 2. 实时查看 Filebeat 运行日志(确认无报错、正常发送到 Kafka)
journalctl -u filebeat -f
# 3. 登录 Kafka 服务器,验证 Topic 是否收到日志
/opt/kafka_2.13-2.4.0/bin/kafka-console-consumer.sh --bootstrap-server 192.168.116.131:9092 --topic test-kafka-topic --from-beginningjournalctl -u filebeat -f #查看filebeat日志启动kafka时遇到的问题
[2026-01-12 22:21:11,455] WARN [AdminClient clientId=adminclient-1] Connection to node -1 (/192.168.116.131:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)
[2026-01-12 22:21:12,362] WARN [AdminClient clientId=adminclient-1] Connection to node -1 (/192.168.116.131:9092) could not be established. Broker may not be available. (org.apache.kafka.clients.NetworkClient)你看到的这个 WARN 日志核心问题是:客户端(比如 Filebeat/Logstash/Kafka 命令行工具)无法连接到 192.168.116.131:9092 的 Kafka Broker,提示 “Broker 可能不可用”
[2026-01-12 22:25:30,561] INFO jute.maxbuffer value is 4194304 Bytes (org.apache.zookeeper.ClientCnxnSocket)
[2026-01-12 22:25:30,566] INFO zookeeper.request.timeout value is 0. feature enabled= (org.apache.zookeeper.ClientCnxn)
[2026-01-12 22:25:30,568] INFO [ZooKeeperClient Kafka server] Waiting until connected. (kafka.zookeeper.ZooKeeperClient)
[2026-01-12 22:25:36,571] INFO [ZooKeeperClient Kafka server] Closing. (kafka.zookeeper.ZooKeeperClient)
[2026-01-12 22:25:50,611] INFO Opening socket connection to server kafka/192.168.116.131:2181. Will not attempt to authenticate using SASL (unknown error) (org.apache.zookeeper.ClientCnxn)
[2026-01-12 22:25:50,617] INFO Socket connection established, initiating session, client: /192.168.116.131:54828, server: kafka/192.168.116.131:2181 (org.apache.zookeeper.ClientCnxn)
[2026-01-12 22:25:50,624] INFO Session establishment complete on server kafka/192.168.116.131:2181, sessionid = 0x100000cc10b0006, negotiated timeout = 6000 (org.apache.zookeeper.ClientCnxn)
[2026-01-12 22:25:50,739] INFO Session: 0x100000cc10b0006 closed (org.apache.zookeeper.ZooKeeper)
[2026-01-12 22:25:50,739] INFO EventThread shut down for session: 0x100000cc10b0006 (org.apache.zookeeper.ClientCnxn)
[2026-01-12 22:25:50,741] INFO [ZooKeeperClient Kafka server] Closed. (kafka.zookeeper.ZooKeeperClient)
[2026-01-12 22:25:50,743] ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
kafka.zookeeper.ZooKeeperClientTimeoutException: Timed out waiting for connection while in state: CONNECTING
at kafka.zookeeper.ZooKeeperClient.$anonfun$waitUntilConnected$3(ZooKeeperClient.scala:259)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.scala:18)
at kafka.utils.CoreUtils$.inLock(CoreUtils.scala:253)
at kafka.zookeeper.ZooKeeperClient.waitUntilConnected(ZooKeeperClient.scala:255)
at kafka.zookeeper.ZooKeeperClient.<init>(ZooKeeperClient.scala:113)
at kafka.zk.KafkaZkClient$.apply(KafkaZkClient.scala:1858)
at kafka.server.KafkaServer.createZkClient$1(KafkaServer.scala:375)
at kafka.server.KafkaServer.$anonfun$initZkClient$2(KafkaServer.scala:393)
at kafka.server.KafkaServer.$anonfun$initZkClient$2$adapted(KafkaServer.scala:391)
at scala.Option.foreach(Option.scala:437)
at kafka.server.KafkaServer.initZkClient(KafkaServer.scala:391)
at kafka.server.KafkaServer.startup(KafkaServer.scala:207)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:44)
at kafka.Kafka$.main(Kafka.scala:84)
at kafka.Kafka.main(Kafka.scala)
[2026-01-12 22:25:50,745] INFO shutting down (kafka.server.KafkaServer)
[2026-01-12 22:25:50,751] INFO shut down completed (kafka.server.KafkaServer)
[2026-01-12 22:25:50,752] ERROR Exiting Kafka. (kafka.server.KafkaServerStartable)
[2026-01-12 22:25:50,754] INFO shutting down (kafka.server.KafkaServer)Kafka 连接 ZooKeeper 超时
先查看Zookeeper是否启动
清理Zookeeper临时数据 (解决会话异常)
grep "dataDir" conf/zoo.cfg
找到后删除该目录下的所有内容
后启动kafka,带日志输出
bin/kafka-server-start.sh -daemon config/server.properties
tail -f logs/server.log
集群ID不匹配
[2026-01-12 22:48:46,580] INFO Session establishment complete on server kafka/192.168.116.131:2181, sessionid = 0x100003412b40001, negotiated timeout = 6000 (org.apache.zookeeper.ClientCnxn)
[2026-01-12 22:48:46,580] INFO [ZooKeeperClient Kafka server] Connected. (kafka.zookeeper.ZooKeeperClient)
[2026-01-12 22:48:46,801] INFO Cluster ID = h8T4NRPDSV2S5d6K_4U_sQ (kafka.server.KafkaServer)
[2026-01-12 22:48:46,813] ERROR Fatal error during KafkaServer startup. Prepare to shutdown (kafka.server.KafkaServer)
kafka.common.InconsistentClusterIdException: The Cluster ID h8T4NRPDSV2S5d6K_4U_sQ doesn't match stored clusterId Some(ffxYy3QcQ4KdtzYz-1fByQ) in meta.properties. The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.
at kafka.server.KafkaServer.startup(KafkaServer.scala:220)
at kafka.server.KafkaServerStartable.startup(KafkaServerStartable.scala:44)
at kafka.Kafka$.main(Kafka.scala:84)
at kafka.Kafka.main(Kafka.scala)
[2026-01-12 22:48:46,815] INFO shutting down (kafka.server.KafkaServer)
[2026-01-12 22:48:46,819] INFO [ZooKeeperClient Kafka server] Closing. (kafka.zookeeper.ZooKeeperClient)
[2026-01-12 22:48:46,922] INFO Session: 0x100003412b40001 closed (org.apache.zookeeper.ZooKeeper)
[2026-01-12 22:48:46,923] INFO [ZooKeeperClient Kafka server] Closed. (kafka.zookeeper.ZooKeeperClient)
[2026-01-12 22:48:46,926] INFO EventThread shut down for session: 0x100003412b40001 (org.apache.zookeeper.ClientCnxn)
[2026-01-12 22:48:46,933] INFO shut down completed (kafka.server.KafkaServer)
[2026-01-12 22:48:46,934] ERROR Exiting Kafka. (kafka.server.KafkaServerStartable)
[2026-01-12 22:48:46,944] INFO shutting down (kafka.server.KafkaServer)这是 Kafka 重启后常见的「元数据冲突」问题 ——Kafka 本地存储的集群 ID 和 ZooKeeper 中记录的集群 ID 不一致,导致 Kafka 认为自己要加入错误的集群,从而启动失败。
删除本地元数据文件
# 1. 进入Kafka的数据目录(先查配置文件确认路径)
# 查看server.properties中的log.dirs配置(Kafka数据存储路径)
grep "log.dirs" /opt/kafka_2.13-2.4.0/config/server.properties
# 示例输出:log.dirs=/tmp/kafka-logs(替换为你的实际路径)
# 2. 删除meta.properties文件
rm -rf /tmp/kafka-logs/meta.properties
# 3. 可选:清理Kafka旧数据(避免残留冲突,测试环境推荐)
rm -rf /tmp/kafka-logs/*清理Zookeeper中旧的kafka数据元数据
# 1. 进入ZooKeeper客户端
/opt/zookeeper-3.8.0/bin/zkCli.sh
# 2. 在ZK客户端中删除Kafka相关节点(执行以下命令)
rmr /kafka
# 退出ZK客户端
quit后台启动用logstash从kafka消费日志并转发给ES
$ vi /etc/systemd/system/logstash.service
[Unit]
Description=logstash
After=network.target kafka.service elasticsearch.service
Wants=kafka.service elasticsearch.service
[Service]
Type=simple
User=root
Group=root
# Load env vars from /etc/default/ and /etc/sysconfig/ if they exist.
# Prefixing the path with '-' makes it try to load, but if the file doesn't
# exist, it continues onward.
EnvironmentFile=-/etc/default/logstash
EnvironmentFile=-/etc/sysconfig/logstash
ExecStart=/usr/share/logstash/bin/logstash -f /root/ctgkafka.conf
ExecStop=/usr/share/logstash/bin/logstash stop
Restart=on-failure
RestartSec=5
Environment="LS_HEAP_SIZE=1g"
StandardOutput=journal+console
StandardError=journal+console
WorkingDirectory=/
Nice=19
LimitNOFILE=16384
# When stopping, how long to wait before giving up and sending SIGKILL?
# Keep in mind that SIGKILL on a process can cause data loss.
TimeoutStopSec=infinity
[Install]
WantedBy=multi-user.target
[Unit]
Description=Logstash (消费Kafka数据转发到ES)
After=network.target kafka.service elasticsearch.service # 依赖Kafka、ES,确保先启动
Wants=kafka.service elasticsearch.service
[Service]
Type=simple
User=root # 生产环境建议创建logstash专用用户(useradd -r logstash)
# 核心:指定Logstash可执行文件路径 + 你的ctgkafka.conf配置文件路径
ExecStart=/usr/share/logstash/bin/logstash -f /root/ctgkafka.conf
ExecStop=/usr/share/logstash/bin/logstash stop
Restart=on-failure # 进程崩溃自动重启
RestartSec=5 # 重启间隔5秒
# 解决Logstash启动内存不足问题(关键!默认内存可能不够)
Environment="LS_HEAP_SIZE=1g"
# 日志输出到系统日志,方便排查
StandardOutput=journal+console
StandardError=journal+console
[Install]
WantedBy=multi-user.target启动
# 1. 重载systemd配置(修改服务文件后必须执行)
systemctl daemon-reload
# 2. 启动Logstash(后台运行,无终端阻塞)
systemctl start logstash
# 3. 设置开机自启(服务器重启后自动后台运行)
systemctl enable logstash
# 4. 验证运行状态(正常应显示 active(running))
systemctl status logstash验证
# 1. 查看Logstash后台进程
ps -ef | grep logstash | grep -v grep
# 2. 实时查看Logstash运行日志(确认无报错、正常消费Kafka数据)
journalctl -u logstash -f
# 3. 验证ES是否收到数据(查看按日期生成的nginx-log索引)
curl http://192.168.116.128:9200/nginx-log-$(date +%Y.%m.%d)/_count
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)