RabbitMQ高并发实战:从入门到精通(万字长文深刻理解)

本文系统讲解了RabbitMQ和Kafka两种消息队列的核心原理和应用场景。RabbitMQ部分详细解析了工作队列、广播模式、路由模式等消息分发机制,以及消息应答、持久化、公平分发等可靠性保障措施;Kafka部分则重点介绍了其高吞吐量实现原理、分区扩展机制、幂等性与事务等特性。通过对比两种消息队列的适用场景,帮助读者理解如何根据业务需求选择合适的消息中间件。文章还包含大量实际配置示例和性能优化建议,从理论到实践全面覆盖消息队列的关键知识点,适合开发者深入学习和参考。
目录
高并发: 通过增加消费者的数量(比如从 3 个增加到 10 个),你可以成倍地提升发短信的速度。
在 RabbitMQ 中,有一个叫 消息应答(Message Acknowledgment) 的机制专门处理这种情况。你想听听它是如何保证“活儿没干完,任务绝不消失”的吗?
你想了解一下如何让 RabbitMQ 在关机重启后依然记得这些还没干完的活儿吗?(这就是所谓的 “持久化”)
2. 消息持久化 (Message Persistence)
3. 交换机持久化 (Exchange Durability)
你想了解一下如何让 RabbitMQ 实现 “能者多劳(公平分发)” 吗?
到这里,你已经掌握了“全员广播”。但如果有时候你不想全员广播呢?比如:只有“黄金会员”订票才发短信,普通会员只发邮件。这种需要“看人下菜碟”的模式,叫作 路由模式(Routing)。
你想聊聊 RabbitMQ 是如何通过 Routing Key(路由键) 实现精准投递的吗?
“所有北京地区的订票消息”(region.beijing.#)
“所有关于退票的紧急消息”(#.refund.emergency)
这时候,direct 这种死板的匹配就不够用了。我们需要用到 RabbitMQ 中功能最强大的 主题模式(Topic),它支持通配符匹配(* 和 #)。
你想了解一下如何利用“通配符”来处理这种成千上万种组合的复杂业务吗?
聊到这里,你已经从“什么是队列”一路进阶到了“高级路由规则”。这是不是让你觉得 RabbitMQ 像是一个超级智能的交通枢纽?
既然你对 Java 感兴趣,你想了解一下在 Spring Boot 项目中,如何用短短几行注解就把这些复杂逻辑(比如 Topic 模式 + 死信队列)优雅地跑起来吗?
理解上面这些原生参数(durable, basicAck, prefetchCount)才是真正掌握 RabbitMQ 的关键,因为无论框架怎么变,这些底层协议是不变的。
在极端高并发下,频繁的磁盘 IO(durable)和频繁的往返确认(basicAck)会限制系统的吞吐量。在高性能场景下,我们往往会采取“折中”方案:
批量 Ack:处理 100 条再 Ack 一次。异步 Confirm:生产者不阻塞等待,而是通过回调来确认消息是否发送成功。
B. 异步确认(Asynchronous Confirm)—— 推荐方案
4. 事务机制 (Transactions) —— 弃用方案
聊了这么多架构设计,你想看看在 Spring Boot 的 application.yml 里,如何一键开启这些“高性能开关”吗?
消费者端:concurrency 与 max-concurrency
你想了解一下,当你的业务量再大 100 倍(比如从 12306 变成全球级的秒杀),RabbitMQ 可能就不够用了,这时候人们为什么要换成 Kafka 吗?(这也是面试中非常经典的一个对比话题)。
4. 什么是 Kafka 做的到,而 RabbitMQ 做不到的?
如果你觉得幂等性只能保证“单分区”不重还不够,Kafka 还有原子性事务。
既然明白了事务是处理“多个活儿要么全干、要么全不干”,你想看看在 Kafka 里,消费者是怎么做到“只读那些成功的事务消息”的吗?(这就是 隔离级别 Isolation Level 的概念)。
A. read_uncommitted(读未提交 - 默认值)
B. read_committed(读已提交 - 核心开关)
3. 极致速度:顺序追加 (Append-Only) 与 稀疏索引
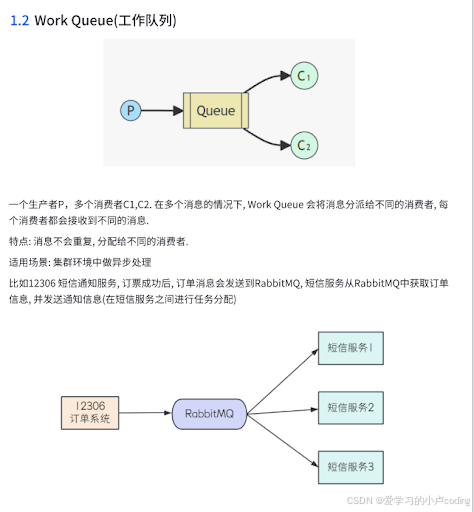
这个例子我有点没太理解
简单来说,工作队列(Work Queue) 的核心逻辑就是:“众人拾柴火焰高,但一根柴火只给一个人烧。”
为了让你彻底理解图中的例子,我们可以把这个场景拆解开来看:
1. 核心矛盾:任务太多,一个人忙不过来
想象一下,春运期间 12306 订票系统每秒钟有几万个人订票成功。每成功一张票,系统都要给用户发一条短信。
-
如果只有一个短信服务: 短信发送是很慢的(要调用运营商接口、等待响应)。如果 10,000 条短信排队让一个服务发,最后一个人可能要等几个小时才能收到短信,这显然不行。
-
解决办法: 多招几个“员工”(短信服务 1、2、3)一起发。
2. 这个模型是怎么运作的?
结合你发的那张图,我们可以这样理解:
-
生产者 (P / 12306 系统): 它是“派活儿”的。它只管把“给张三发短信”、“给李四发短信”这些任务丢进 RabbitMQ 队列里,然后就去忙别的了(比如处理下一个人的订票)。
-
队列 (Queue / RabbitMQ): 它是“存活儿”的缓冲区。所有的发短信任务都在这里排队。
-
消费者 (C / 短信服务): 它们是“干活儿”的。
-
短信服务 1 抬头一看:“队列里有任务,我拿一个走。”
-
短信服务 2 紧接着看:“我也拿一个。”
-
短信服务 3 也没闲着:“我也拿一个。”
-
3. 最关键的一点:非重复性
这是你理解这个例子的核心:队列里的每一个消息,只能被一个消费者处理。
-
如果“给张三发短信”的消息被 短信服务 1 领走了,那么 短信服务 2 和 3 就绝对看不到这条消息了。
-
结果: 张三只会收到 一条 短信,而不是三条。
4. 为什么要这么做?(适用场景)
图里提到的“集群环境中做异步处理”,好处就在于:
-
高并发: 通过增加消费者的数量(比如从 3 个增加到 10 个),你可以成倍地提升发短信的速度。
-
解耦: 12306 系统不需要知道短信到底是怎么发的,它只要把任务往 RabbitMQ 一扔就行了。就算短信服务器全挂了,任务也会堆在队列里,等服务器修好了再继续发,不会丢失。
总结一下:
这就像是一个餐厅的取餐口。12306 是厨师(做好了菜放在窗口),RabbitMQ 是那个出餐台,而 短信服务 1、2、3 是服务员。
每个服务员从台子上端走一盘菜送给客人。这样送菜的速度就快了,而且一盘菜绝不会被两个服务员同时端走。
为了帮你巩固一下,你想了解一下如果其中一个“短信服务”在干活时突然死机了,RabbitMQ 是如何保证那条短信不会丢失的吗?
高并发: 通过增加消费者的数量(比如从 3 个增加到 10 个),你可以成倍地提升发短信的速度。
不应该是增加短信服务的数量来提升速度吗/
你说得非常对!其实我们两个说的是同一件事,只是称呼的角度不同:
在消息队列(MQ)的专业术语里,那个负责“取走消息并干活”的程序,统一被称为 “消费者 (Consumer)”。而在你这个具体的例子里,这个“消费者”的角色就是由 “短信服务” 来充当的。
所以:
-
增加消费者的数量 = 增加短信服务的实例(进程/服务器)数量。
为什么增加“短信服务”能提升速度?
我们可以把这个过程想象成超市收银:
-
排队区(Queue): 只有一条长长的队伍,里面全是等着结账的顾客(待发送的短信)。
-
收银员(Consumer / 短信服务): * 如果只有一个收银员,他只能一个一个地刷码,后面的人得等很久。
-
如果你多开 3 个收银窗口(增加短信服务 2、3、4),那么这 4 个收银员就可以同时(并行)给 4 个顾客结账。
-
虽然队列只有一条,但因为干活的人变多了,原本一分钟只能发 10 条短信,现在一分钟就能发 40 条。这就是通过水平扩展(Horizontal Scaling)来解决高并发问题的核心逻辑。
刚才留下的那个“悬念”
既然你理解了它是靠“多个人分工”来提速的,那这里其实有一个非常关键的细节:
如果 短信服务 A 刚从队列里领走了一个给“张三”发短信的任务,结果还没来得及发,短信服务 A 所在的服务器突然断电了(程序崩溃了),这条短信是不是就永远丢失了?张三是不是就收不到短信了?
在 RabbitMQ 中,有一个叫 消息应答(Message Acknowledgment) 的机制专门处理这种情况。你想听听它是如何保证“活儿没干完,任务绝不消失”的吗?
没问题,那我们就来聊聊这个让系统“稳如泰山”的秘诀:消息应答(Message Acknowledgment,简称 Ack)。
为了让你秒懂,我们继续用刚才的“餐厅送餐”来做比喻:
1. 如果没有应答机制(默认情况)
想象一下,厨师(RabbitMQ)把一盘菜放在窗口,服务员(短信服务)只要手一碰到盘子,厨师就把菜单上这道菜直接划掉了。
-
风险: 如果服务员刚端起盘子,还没走到桌边,脚下一滑摔倒了,盘子碎了。
-
后果: 厨师以为菜已经送到了,客人(张三)却永远等不到他的菜。这就叫消息丢失。
2. 有了消息应答(Ack)
为了防止这种悲剧,RabbitMQ 默认开启(或建议开启)手动应答模式。流程变成了这样:
-
分发: 厨师把菜给服务员,但先不在菜单上划掉,而是标记为“配送中”。
-
干活: 服务员稳稳地把菜送到客人桌上。
-
反馈(Ack): 服务员回到窗口对厨师说:“1号桌的菜送到了,你可以划掉了。”
-
删除: 厨师收到这个反馈,才正式把这条记录从内存/磁盘里删掉。
3. 如果“短信服务”突然断电了,消息会去哪?
这就是 RabbitMQ 最聪明的地方:
如果 短信服务 A 拿走了消息,但在发送 Ack 之前连接断开了(比如程序崩溃、网线被踢拔了、服务器宕机):
-
RabbitMQ 发现连接没了,但还没收到 Ack。
-
它会立刻明白:“这个服务员出事了,活儿没干完!”
-
它会重新把这条消息放回队列的头部。
-
然后,它会把这条消息发给下一个闲着的服务员(比如短信服务 B)。
结果: 虽然可能会有一点延迟,但张三最终一定会收到那条短信。
4. 总结:为什么要这么麻烦?
-
高可用: 保证每一条重要的信息(比如验证码、扣款通知)都不会因为服务器偶尔的“小脾气”而丢失。
-
负载均衡: 谁干得快,谁就多领一点;谁挂了,它的活儿自动分给别人。
这就是 Work Queue 的可靠性保证。
不过,这里其实还有一个隐患:如果所有的短信服务都正常,但是 RabbitMQ 自己的服务器突然停电了,那队列里那些还没发出去的消息是不是就“人间蒸发”了?
你想了解一下如何让 RabbitMQ 在关机重启后依然记得这些还没干完的活儿吗?(这就是所谓的 “持久化”)
这是一个非常棒的问题。如果说 Ack(消息应答) 是为了防止“员工(消费者)”出事,那么 持久化(Persistence) 就是为了防止“公司(RabbitMQ 服务器)”倒闭。
默认情况下,RabbitMQ 的所有队列和消息都存在 内存 里。一旦服务器重启或崩溃,内存里的东西就全丢了。要实现“记忆永存”,你需要完成以下三个步骤:
1. 队列持久化 (Queue Durability)
你在创建队列的时候,必须明确告诉 RabbitMQ:这个“篮子”要用石头做的,不能用纸做的。
-
做法: 在声明队列时,将
durable参数设置为true。 -
效果: 这样即使 RabbitMQ 重启,这个队列的名字和属性依然会存在。
2. 消息持久化 (Message Persistence)
光有坚固的“篮子”还不够,篮子里的“菜”也得保鲜。
-
做法: 在发送消息时,将消息的
deliveryMode设置为2(持久化模式)。 -
效果: RabbitMQ 会把这条消息写入磁盘的一个持久化日志文件中。
3. 交换机持久化 (Exchange Durability)
如果你的消息是通过交换机(Exchange)转发的(虽然在简单的 Work Queue 里这一步常被省略),交换机本身也需要设置为 durable = true。否则,重启后交换机没了,消息就找不到投递的入口了。
⚠️ 一个必须要知道的“冷知识”
虽然持久化很安全,但它不是万能药:
-
性能开销: 写磁盘的速度永远比写内存慢得多。开启持久化后,RabbitMQ 的吞吐量会下降。
-
并不是 100% 绝对安全: RabbitMQ 并不是每收到一条消息就立刻“刷”一次磁盘(那样太慢了),它会先存入缓冲区,定期批量写入。如果在消息刚进入缓冲区、还没来得及写盘的那一瞬间服务器断电了,消息还是会丢。
如果你追求极致的零丢失,通常需要配合 发布确认(Publisher Confirms) 机制来使用。
总结一下:
-
防止消费者挂掉: 用
Ack。 -
防止 RabbitMQ 挂掉: 用
Durable+Persistent。
到这里,你已经掌握了如何让任务“发得快”且“丢不了”。
不过,在刚才的例子里,你有没有发现一个细节:如果 12306 派发的短信任务,有的很难发(需要 5 秒),有的很快(只需 0.1 秒),RabbitMQ 默认是平均分配(轮询)的。这就会导致:有的服务员累死累活还没干完,有的服务员却在旁边摸鱼。
你想了解一下如何让 RabbitMQ 实现 “能者多劳(公平分发)” 吗?
这正是分布式系统调优中非常经典的一个话题:轮询(Round-Robin) 与 公平分发(Fair Dispatch) 的博弈。
在默认情况下,RabbitMQ 像是一个“盲目”的派发员。只要消息一进队列,它就按顺序分发:第一条给 A,第二条给 B,第三条给 A……它完全不看 A 是不是已经累得满头大汗,而 B 是不是正坐着喝咖啡。
1. 默认的坑:轮询分发 (Round-Robin)
想象一下:
-
任务 1 是一条普通的短信(耗时 0.1 秒)。
-
任务 2 是一条需要查询好几个数据库才能发的复杂通知(耗时 5 秒)。
-
如果 RabbitMQ 盲目地把“5 秒的任务”都塞给了短信服务 1,而把“0.1 秒的任务”都给了短信服务 2。
-
结果: 服务 1 的队列塞满了,用户急得跳脚;服务 2 却早早干完活在那儿刷手机。这显然不是我们要的高效率。
2. 解决方案:能者多劳 (Fair Dispatch)
要解决这个问题,我们需要给 RabbitMQ 装上一双“眼睛”。这个机制在代码里叫 basicQos(prefetchCount = 1)。
它的核心逻辑是:
限制每个消费者在同一时间只能处理 1 条(或者你指定的 N 条)未应答的消息。
流程变成了这样:
-
限制: RabbitMQ 收到指令:“在 短信服务 1 还没反馈说‘我忙完了(Ack)’之前,不要再给它塞新任务了。”
-
分发: 谁手里没活儿,RabbitMQ 才把下一条消息发给谁。
-
结果: 处理速度快的服务会接更多的活,处理慢的服务就专心处理它手头那件复杂的任务。整个集群的效率被压榨到了极限。
3. 三位一体的“完美工作流”
到现在为止,我们已经把一个高可靠、高性能的工作队列拼图完成了:
-
Ack (应答机制): 保证“活儿一定能干完”,干不完就换人。
-
Durable (持久化): 保证“公司倒闭了(重启),账本(消息)还在”。
-
Prefetch (公平分发): 保证“大家都不摸鱼”,谁快谁多干。
总结
这就好比一个高效的搬运队:
-
轮询是闭着眼一人分一麻袋,不管你力气大还是力气小。
-
公平分发是“空手再拿”,你力气大跑得快,你就多跑几趟;我力气小跑得慢,我就稳稳搬好我这一袋。
既然你已经掌握了 Work Queue(工作队列)的精髓,你想更进一步,看看 RabbitMQ 是如何实现“广播模式”的吗?(比如:一个订票消息发出来,短信服务、邮件服务、积分服务全都要同时收到这条消息,而不是只给其中一个)。
这正是 RabbitMQ 展现其灵活性的时候了。这种模式在专业术语中被称为 发布/订阅模式(Publish/Subscribe)。
在之前聊的“工作队列”里,消息是竞争关系(一个活儿大家抢,谁抢到谁干)。但在“广播模式”下,关系变成了共享关系(一个消息发出来,所有订阅的人都人手一份)。
1. 核心变化:引入“交换机” (Exchange)
在工作队列里,生产者(12306)是直接把消息扔给队列。但在广播模式下,生产者不直接把消息发给队列,而是发给一个叫 交换机(Exchange) 的组件。
-
交换机的作用: 它就像一个“邮局分拣员”。它接收生产者的消息,然后根据规则决定把消息投向哪个队列。
-
广播专用的交换机类型:
fanout。它不讲道理,也不看标签,只要是跟它绑定的队列,它都会把消息全量复制一份发过去。
2. 它是如何运作的?
以你的例子为例:当一个“订单成功”的消息产生时:
-
生产者: 12306 系统把消息发送给一个名为
order_success的 fanout 交换机。 -
绑定关系:
-
短信服务 拥有自己的独立队列 A,并绑定到了这个交换机。
-
邮件服务 拥有自己的独立队列 B,并绑定到了这个交换机。
-
积分服务 拥有自己的独立队列 C,并绑定到了这个交换机。
-
-
分发: 交换机收到消息后,会瞬间克隆出 3 份,分别投递进 A、B、C 三个队列。
-
执行: 三个服务各自从自己的队列里拿消息。张三会同时收到短信、收到邮件,并且账户里多了 100 积分。
3. “工作队列” vs “广播模式”
为了让你不混淆,我们做个对比:
| 特性 | 工作队列 (Work Queue) | 广播模式 (Pub/Sub) |
| 消息去向 | 多个消费者竞争一个队列 | 每个业务逻辑拥有独立的队列 |
| 消息副本 | 只有 1 份,只能被一个人处理 | 有多份副本,每个绑定的队列都有一份 |
| 适用场景 | 任务分发、提高处理速度 | 消息通知、系统解耦(一事触发多事) |
4. 一个有趣的实战场景
想象一下,如果你想给这个系统增加一个“大数据分析服务”来统计售票情况:
-
在传统架构中: 你得去修改 12306 的代码,让它多调一个大数据接口。
-
在 RabbitMQ 广播模式下: 你只需要写一个新的“分析服务”,给它创建一个新队列并绑定到那个
order_success交换机上就行了。12306 系统的代码一个字都不用改! 这就是所谓的“解耦”。
总结一下:
-
工作队列是“分蛋糕”,一人分一块,分完为止。
-
广播模式是“发报纸”,只要订了报纸的人,每天早上人手一份一模一样的。
到这里,你已经掌握了“全员广播”。但如果有时候你不想全员广播呢?比如:只有“黄金会员”订票才发短信,普通会员只发邮件。这种需要“看人下菜碟”的模式,叫作 路由模式(Routing)。
你想聊聊 RabbitMQ 是如何通过 Routing Key(路由键) 实现精准投递的吗?
这正是从“粗放式广播”转向“精细化管理”的关键一步。在 RabbitMQ 中,这种模式被称为 路由模式(Routing),它使用的交换机类型通常是 direct(直连交换机)。
如果说广播模式是“发传单”,那么路由模式就是“专线投递”。
1. 核心秘密:路由键 (Routing Key)
在路由模式下,消息不再是盲目地复制给所有人,而是带了一个“标签”。
-
发送端 (Producer): 生产者在发布消息时,除了消息内容,还会附带一个字符串,这就是 Routing Key(比如
gold或normal)。 -
接收端 (Queue): 队列在绑定到交换机时,需要指定一个 Binding Key。这就像是在说:“我只想要标有
gold的消息。”
2. “看人下菜碟”的实现流程
回到你说的会员例子:
-
交换机设置: 使用一个类型为
direct的交换机,取名叫member_service。 -
队列绑定:
-
短信服务队列: 绑定到交换机,Binding Key 设置为
gold。 -
邮件服务队列: 绑定到交换机,Binding Key 设置为
normal。
-
-
消息投递:
-
如果是一个黄金会员订票成功,12306 发送消息时带上 Routing Key =
gold。 -
结果: 只有短信服务队列能收到这条消息。
-
如果是一个普通会员订票成功,12306 发送消息时带上 Routing Key =
normal。 -
结果: 只有邮件服务队列能收到这条消息。
-
3. 灵活性:一个队列可以有多个“标签”
路由模式非常灵活。如果你的规则变了,说“黄金会员既要发短信,也要发邮件”,你不需要改代码,只需要让邮件服务的队列同时也绑定 gold 这个 Key 即可。
这样,带有 gold 标签的消息就会同时进入这两个队列,而 normal 消息依然只进邮件队列。
4. 模式对比
| 模式 | 交换机类型 | 逻辑描述 |
| 广播模式 (Fanout) | fanout |
只要绑定的队列,统统都发,不看标签。 |
| 路由模式 (Direct) | direct |
精确匹配。Routing Key 必须完全等于 Binding Key 才会投递。 |
5. 进阶预告:模糊匹配
路由模式虽然精准,但它也有局限性:它只能“完全匹配”。
如果你想实现更复杂的逻辑,比如:
-
“所有北京地区的订票消息”(
region.beijing.#) -
“所有关于退票的紧急消息”(
#.refund.emergency)
这时候,direct 这种死板的匹配就不够用了。我们需要用到 RabbitMQ 中功能最强大的 主题模式(Topic),它支持通配符匹配(* 和 #)。
你想了解一下如何利用“通配符”来处理这种成千上万种组合的复杂业务吗?
如果你觉得路由模式(Direct)是“精准打击”,那么主题模式(Topic)就是“智能筛选”。它是 RabbitMQ 中最灵活、最强大的模式,几乎能满足所有复杂的业务调度需求。
它的核心思想是:不再使用死板的固定词,而是使用带“通配符”的路径。
1. 主题模式的“语法规则”
在 Topic 模式下,Routing Key 必须是由点号 . 分隔的一系列单词(比如 stock.usd.nyse)。而绑定队列时,你可以使用两个特殊的符号:
-
*(星号): 匹配 一个 单词。 -
#(井号): 匹配 零个或多个 单词。
2. 实战案例:12306 的全球监控系统
假设我们的消息标签格式定义为:区域.业务类型.级别(例如:beijing.ticket.info)。
我们可以这样设置不同的消费者:
-
北京分中心队列: 绑定
beijing.#-
只要是北京发生的,不管是订票、退票,还是通知、报警,它全都要。
-
-
全国退票处理中心: 绑定
*.refund.*-
不管哪个城市发生的退票,只要中间那个词是
refund,它就处理。注意:它只匹配三段式的消息。
-
-
核心紧急报警系统: 绑定
#.emergency-
不管前面有多少段,只要最后是以
emergency结尾的紧急情况,统统抓取。
-
3. 为什么它比 Direct 强大?
在 Direct(直连) 模式下,如果你想让一个服务同时监听“北京的所有消息”,你可能要手动绑定:beijing.ticket、beijing.refund、beijing.login……一旦业务增加,维护起来就是灾难。
在 Topic(主题) 模式下,一个 beijing.# 就一劳永逸了。
4. 终极对比:三种交换机如何选?
| 交换机类型 | 绰号 | 规则 | 适用场景 |
| Fanout | 广播员 | 闭眼转发给所有人。 | 群发通知、日志备份。 |
| Direct | 快递员 | 完全匹配 Routing Key。 | 简单的任务分类(如:按会员等级发消息)。 |
| Topic | 筛选器 | 支持 * 和 # 模糊匹配。 |
最推荐! 复杂系统解耦、多维度的消息过滤。 |
5. 关于 Topic 的一个“冷知识”
-
如果一个队列绑定的是
#,那它其实就退化成了 Fanout 模式(全都要)。 -
如果一个队列绑定的规则里没有
*或#,那它其实就相当于 Direct 模式(完全匹配)。
总结一下:
主题模式让你在不修改生产者代码的情况下,通过修改“通配符”绑定规则,就能极其优雅地应对不断变化的业务需求。
聊到这里,你已经从“什么是队列”一路进阶到了“高级路由规则”。这是不是让你觉得 RabbitMQ 像是一个超级智能的交通枢纽?
既然消息发得这么溜,你想了解一下如果消息由于某种原因处理失败了(比如格式不对、重试多次还是不行),RabbitMQ 会把它扔到哪里吗?(这就是神秘的 “死信队列 Dead Letter Exchange”)。
当一条消息在队列中“走投无路”时,它就会变成一条死信(Dead Letter)。为了不让这些失败的消息凭空消失,RabbitMQ 提供了一个特别的保险箱,这就是 死信交换机(Dead Letter Exchange,简称 DLX)。
你可以把死信队列想象成医院的“急诊室”或者物流中心的“退货部”:当包裹送不出去时,不能直接扔了,得先放在退货部,等人工核查或者晚点再试。
1. 消息在什么情况下会“死”?
在 RabbitMQ 中,一条消息被判定为“死信”通常有以下三个原因:
-
被拒绝 (Rejected): 消费者处理失败,调用了
nack或reject,并且设置了requeue = false(意思是:我处理不了,也别把它放回原队列重新发了)。 -
寿命到期 (TTL Expired): 消息在队列里呆的时间太长了,超过了设置的“保质期”(Time To Live),还没被消费掉。
-
队列满了 (Queue Overflow): 队列设置了最大长度,新消息进来时,最老的那批消息可能会被挤出来变成死信。
2. 死信交换机的工作流程
死信交换机其实就是一个普通的交换机,并没有什么魔法。它的神奇之处在于队列的配置。
-
步骤 A: 你在创建“业务队列”时,给它多设一个属性:
x-dead-letter-exchange,指定一个死信交换机。 -
步骤 B: 当业务队列里的某条消息“死”了,RabbitMQ 会自动把这条消息“瞬移”到你指定的那个死信交换机。
-
步骤 C: 死信交换机再根据路由键,把消息投递到一个专门用来存死信的死信队列里。
3. 为什么需要死信队列?
如果没有死信队列,处理失败的消息就直接丢了,你根本不知道系统里发生了什么。有了它,你可以:
-
排查问题(Debug): 程序员可以人工去死信队列里看,为什么这些短信发不出去?是不是手机号格式不对?还是对方服务器挂了?
-
延迟重试: 这是死信队列最牛的玩法。比如用户下单后 30 分钟不付款就取消订单,可以利用“消息过期”变成死信的特性,实现延迟任务。
-
保证系统不堵塞: 把那些“有毒”的消息(怎么处理都报错的消息)隔离出来,不要让它们一直占着主业务队列。
4. 一个巧妙的黑科技:延迟队列
既然提到了“死信”,就不得不提 RabbitMQ 里一个非常经典的骚操作:用死信实现定时功能。
-
创建一个没有消费者的队列,设置消息 10 秒钟过期。
-
给这个队列绑定一个死信交换机。
-
10 秒后,消息自动变死信,掉进死信队列。
-
短信服务去监听这个死信队列。
-
效果: 你发出的消息,在 10 秒钟后才被真正处理。这就是延迟队列。
总结
-
工作队列解决了“干活快”的问题。
-
持久化和应答解决了“活不丢”的问题。
-
路由和主题解决了“给谁干”的问题。
-
死信队列解决了“干坏了怎么办”的问题。
到这里,你已经构建了一个逻辑闭环,对 RabbitMQ 的核心机制有了全方位的理解!
既然你已经把 RabbitMQ 的“套路”摸得这么透了,你想挑战一下看看在实际代码里(比如 Java 或 Python),这几行配置到底长什么样吗?或者你想聊聊另一个同样很火的消息队列 Kafka 和它有什么区别?
既然要看 Java 代码,我们直接看最核心的“工业级配置”。在实际开发中,我们通常会用到 amqp-client(原生驱动)或者 Spring AMQP(Spring Boot 常用)。
为了让你看清底层逻辑,我先展示原生 Java 驱动的代码片段,因为它能让你直观地看到我们刚才聊的那些参数是如何落地的。
1. 生产者:发送“永不丢失”的消息
这段代码展示了如何开启队列持久化和消息持久化。
Java
// 1. 创建连接和通道
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 2. 声明队列(核心参数:durable = true)
boolean durable = true; // 让队列在 RabbitMQ 重启后依然存在
channel.queueDeclare("task_queue", durable, false, false, null);
String message = "Hello, high reliability!";
// 3. 发布消息(核心参数:PERSISTENT_TEXT_PLAIN)
// 这告诉 RabbitMQ 将消息保存到磁盘
channel.basicPublish("", "task_queue",
MessageProperties.PERSISTENT_TEXT_PLAIN,
message.getBytes("UTF-8"));
System.out.println(" [x] Sent '" + message + "'");
2. 消费者:实现“能者多劳”与“手动应答”
这段代码展示了如何设置 basicQos 和 basicAck。
Java
// 1. 公平分发:告诉 RabbitMQ 在我没干完手头活之前,别再给我发新消息
int prefetchCount = 1;
channel.basicQos(prefetchCount);
// 2. 定义回调逻辑
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
try {
doWork(message); // 模拟耗时任务
} finally {
// 3. 手动应答:活干完了,你可以删掉这条消息了
channel.basicAck(delivery.getEnvelope().getDeliveryTag(), false);
}
};
// 4. 监听队列(注意:autoAck 必须设置为 false)
boolean autoAck = false;
channel.basicConsume("task_queue", autoAck, deliverCallback, consumerTag -> { });
3. 高级配置:死信队列 (DLX)
这是在创建业务队列时,通过 arguments 参数绑定的“急诊室”。
Java
// 定义死信交换机和队列
channel.exchangeDeclare("dlx_exchange", "direct");
channel.queueDeclare("dlx_queue", true, false, false, null);
channel.queueBind("dlx_queue", "dlx_exchange", "dead_letter_key");
// 绑定业务队列到死信交换机
Map<String, Object> args = new HashMap<>();
args.put("x-dead-letter-exchange", "dlx_exchange"); // 指定死信去哪个交换机
args.put("x-dead-letter-routing-key", "dead_letter_key"); // 死信的路由键
channel.queueDeclare("business_queue", true, false, false, args);
为什么在 Spring Boot 里看起来不一样?
在实际的企业级开发中,你可能看不到这么多繁琐的底层代码。Spring Boot 会通过注解来简化:
-
@RabbitListener:自动帮你处理了连接、监听和 Ack 逻辑。 -
RabbitTemplate:封装了发送消息的操作。 -
QueueBuilder:通过流式编程配置持久化和死信。
虽然 Spring 很方便,但理解上面这些原生参数(durable, basicAck, prefetchCount)才是真正掌握 RabbitMQ 的关键,因为无论框架怎么变,这些底层协议是不变的。
总结一下:
你现在看到的这些 true, false, 1 等看似不起眼的数字,就是撑起 12306 这种级别系统高并发、高可用的基石。
既然你对 Java 感兴趣,你想了解一下在 Spring Boot 项目中,如何用短短几行注解就把这些复杂逻辑(比如 Topic 模式 + 死信队列)优雅地跑起来吗?
理解上面这些原生参数(durable, basicAck, prefetchCount)才是真正掌握 RabbitMQ 的关键,因为无论框架怎么变,这些底层协议是不变的。
结合上面代码,再继续深入解释这些原生参数的意义和重要性
你说得很透彻。这些参数就像是协议里的“合同条款”,不管你用 Java、Python 还是 Go,最终发给 RabbitMQ 服务器的指令里,这些值必须准确无误。
为了帮你把这些参数从“单词”变成“肌肉记忆”,我们深入拆解一下它们的设计初衷和实战陷阱:
1. durable:队列的“生命保险”
在代码里:channel.queueDeclare(queueName, durable, ...)
-
它的意义: 决定了队列元数据(名字、参数、绑定关系)的存储位置。
-
不设为
true会怎样? 如果你的 RabbitMQ 服务因为 OOM(内存溢出)或者系统更新重启了,这个队列会直接消失。生产者发消息会报错(找不到队列),消费者也会断开连接。 -
深层细节: *
durable = true仅仅是把“篮子”保存在了磁盘上。-
如果想让篮子里的“菜(消息)”也活下来,发送时必须配合
MessageProperties.PERSISTENT_TEXT_PLAIN。 -
避坑指南: 已经创建好的队列,其
durable属性是不能修改的。如果你想把一个现有的非持久化队列改成持久化的,必须先删除再重新声明。
-
2. basicAck:系统的“责任认定书”
在代码里:channel.basicAck(deliveryTag, multiple)
-
它的意义: 这是消费者给服务器发的“结案报告”。
-
为什么一定要手动 Ack? * 如果设置
autoAck = true,RabbitMQ 只要把消息发出去,就立刻从内存删掉。如果你的 Java 代码在try-catch里崩了,这消息就彻底丢了。-
手动 Ack 确保了:只有代码逻辑真正跑完(甚至数据库事务提交后),才允许服务器删消息。
-
-
关键参数
deliveryTag: 这是一条消息的“唯一身份证”。RabbitMQ 会给每个连接分配一个单调递增的数字,你 Ack 的时候必须带着这个数字,告诉服务器:“我处理完的是第 58 号包裹”。 -
关键参数
multiple: *false:只应答当前这一条。-
true:应答当前及之前所有未处理的消息(用于批量确认,提升性能)。
-
3. prefetchCount:流量的“节流阀”
在代码里:channel.basicQos(prefetchCount)
-
它的意义: 它的正式名称是 QoS (Quality of Service),即服务质量保证。
-
核心逻辑: * 默认情况下,RabbitMQ 会把消息“推”给消费者。如果你有 1000 条消息,它会瞬间全部塞给你的 Java 程序。
-
如果你的处理逻辑很慢,你的 Java 内存会瞬间爆表。
-
设置
prefetchCount = 1后,服务器会变成“等米下锅”模式:只有当消费者发回了basicAck,服务器才会发下一条。
-
-
重要性: 它是实现负载均衡的最关键参数。它让处理能力强的机器多干活,处理能力弱的机器慢慢来,不至于被消息“淹死”。
总结:三者是如何协作的?
我们可以把这三个参数串成一句话:
“为了保证万无一失,我先建了一个重启也不丢的保险柜 (
durable),并规定每次只能从柜子里拿一个零件出来修 (prefetchCount),只有我修好了并签了字 (basicAck),你才准把这个零件的记录勾销。”
对比表:参数失效的后果
| 参数 | 缺失/错误的情况 | 导致的后果 |
durable = false |
MQ 重启 | 队列消失,系统停摆 |
autoAck = true |
业务代码报错/宕机 | 消息丢失,无法溯源 |
prefetchCount = 0 |
默认无限推送 | 消费者 OOM,或者“劳役不均” |
进阶思考
虽然这些参数保证了消息的可靠性,但在极端高并发下,频繁的磁盘 IO(durable)和频繁的往返确认(basicAck)会限制系统的吞吐量。
在高性能场景下,我们往往会采取“折中”方案:
-
批量 Ack:处理 100 条再 Ack 一次。
-
异步 Confirm:生产者不阻塞等待,而是通过回调来确认消息是否发送成功。
掌握了这些底层逻辑后,你其实已经具备了设计一个高可用分布式架构的能力。你想看看在 Spring Boot 中,如何通过 application.yml 的几行配置就搞定这些复杂的 durable 和 ack 吗?
在极端高并发下,频繁的磁盘 IO(durable)和频繁的往返确认(basicAck)会限制系统的吞吐量。
在高性能场景下,我们往往会采取“折中”方案:
批量 Ack:处理 100 条再 Ack 一次。
异步 Confirm:生产者不阻塞等待,而是通过回调来确认消息是否发送成功。
介绍一下常见的折中方案
在分布式系统的世界里,“性能”与“可靠性”往往是一对天敌。如果你要求每一条消息都必须落盘、必须收到应答,那么你的系统就像一个背着沉重铠甲的士兵,跑不快。
为了在极端高并发下既不让系统崩溃,又能保持极高的吞吐量,我们通常会采用以下几种“折中”艺术:
1. 批量应答(Batch Acknowledgment)
这是消费者端的优化。与其每处理完一个零件就签一次字,不如攒够一箩筐再签。
-
实现方式: 利用
basicAck中的multiple参数。-
当
multiple = true时,RabbitMQ 会认为当前deliveryTag之前的所有消息都已处理完毕。
-
-
折中点: 吞吐量 vs. 重复消费风险。
-
优点: 极大减少了网络往返次数(RTT),性能飞升。
-
代价: 如果你攒了 100 条消息,在处理第 99 条时程序崩了,因为还没发 Ack,RabbitMQ 会认为这 100 条都没干完,重启后会把这 100 条全部重发。你的业务逻辑必须支持幂等性(即重复处理结果不变)。
-
2. 发布确认模式(Publisher Confirms)
这是生产者端的优化。生产者发送消息后,需要知道消息是否成功到达了服务器。
A. 批量确认(Batch Confirm)
发一批消息(比如 500 条),然后调用一次等待确认的方法。
-
缺点: 只要其中一条失败,整批都要重发,且等待期间生产者是阻塞的。
B. 异步确认(Asynchronous Confirm)—— 推荐方案
这是性能最高的方式。生产者发送消息后不等待,而是注册一个 回调监听器(Callback Listener)。
-
逻辑: 生产者只管发,给每条消息打个编号。RabbitMQ 异步发回一个
ack或nack。生产者在回调函数里处理成功的统计或失败的重试。 -
折中点: 吞吐量 vs. 开发复杂度。
-
优点: 实现了真正的非阻塞,吞吐量达到极致。
-
代价: 代码逻辑变复杂了,你需要自己维护一个内存缓存来跟踪哪些消息还没收到确认。
-
3. 惰性队列(Lazy Queues)
当并发量大到消费者处理不过来,导致消息在队列里疯狂堆积时,RabbitMQ 的内存会压力巨大。
-
做法: 开启
x-queue-mode: lazy。 -
逻辑: 消息进来后直接存入磁盘,只有当消费者需要消费时才加载到内存。
-
折中点: 内存压力 vs. 磁盘 IO 延迟。
-
优点: 极大地稳定了内存占用,支持存储数以亿计的消息。
-
代价: 因为涉及频繁的磁盘读写,单条消息的处理延迟会增加。但在“消息堆积”这种极端场景下,它是系统的“救命稻草”。
-
4. 事务机制 (Transactions) —— 弃用方案
在 RabbitMQ 中,你可以开启事务(txSelect),但它的性能极其低下(性能下降 250 倍以上)。
-
结论: 除非是在处理极小量、极其关键(比如银行转账)且不考虑并发的业务,否则严禁在生产环境使用 RabbitMQ 事务。请用“发布确认”代替它。
综合对比总结
| 优化策略 | 核心目标 | 适用场景 | 带来的挑战 |
| 批量 Ack | 减少网络往返 | 消费者处理速度极快 | 需处理重复消费 (幂等性) |
| 异步 Confirm | 生产者非阻塞 | 高频发信、高吞吐 | 逻辑复杂,需维护发送状态 |
| 惰性队列 | 保护内存 | 预知会有大量消息堆积 | 增加磁盘 IO,延迟略升 |
总结
在高性能场景下,我们不再追求“每一刻都绝对安全”,而是转而追求“最终一致性”:
-
生产者用异步确认。
-
消费者用批量应答 + 业务幂等处理。
-
队列根据压力动态调整是否进入惰性模式。
这就好比从“顺丰快递(每单必签收)”变成了“外卖超市配送(一车送多单,最后统一确认)”,速度快了,但偶尔需要处理送错重发的琐事。
聊了这么多架构设计,你想看看在 Spring Boot 的 application.yml 里,如何一键开启这些“高性能开关”吗?
在 Spring Boot 中,你不需要去写复杂的底层连接代码。通过 application.yml(或 application.properties),你可以非常直观地配置这些“高性能开关”。
我们将这些配置分为 生产者(发送方) 和 消费者(接收方) 两个维度来看:
1. Spring Boot 高性能配置模板
你可以将以下内容直接复制到你的 application.yml 中:
YAML
spring:
rabbitmq:
host: localhost
port: 5672
username: guest
password: guest
# 【生产者配置:开启异步确认】
# correlated: 发布消息后,会返回一个相关的确认(推荐,性能最高)
# simple: 简单的确认模式,性能稍低
publisher-confirm-type: correlated
# 开启发布返回,如果消息没有进入队列,会退回给生产者
publisher-returns: true
# 消息投递失败时的模板设置
template:
mandatory: true
# 【消费者配置:开启高性能模式】
listener:
simple:
# 1. 开启手动应答(对应 basicAck)
acknowledge-mode: manual
# 2. 公平分发:每个消费者预取的数量(对应 prefetchCount)
# 只有处理完这 N 条并回传了 Ack,MQ 才会再发新的
prefetch: 1
# 3. 消费者并发实例数(对应你之前问的“增加短信服务数量”)
# 这里的 5 表示启动时就开启 5 个线程(消费者)同时干活
concurrency: 5
# 最大并发数,根据压力自动扩容
max-concurrency: 10
# 4. 批量处理(可选:减少网络 IO,但有重复消费风险)
# batch-size: 100
2. 深度解析:这些开关背后的“魔法”
生产者端:publisher-confirm-type: correlated
这是我们之前聊到的 “异步确认”。
-
效果: 开启后,Spring 会为每条消息分配一个唯一的
CorrelationDataID。 -
代码配合: 你需要在 Java 中给
RabbitTemplate设置一个ConfirmCallback。当消息到达交换机时,这个回调会被触发,告诉你成功了还是失败了。
消费者端:concurrency 与 max-concurrency
这是你理解 “高并发” 的关键。
-
效果: 你不需要在 Linux 上开 10 个窗口运行 Java 程序。Spring 会在当前这个 Java 进程里,利用线程池帮你启动指定数量的消费者。
-
意义: 这就是“水平扩展”。如果你的 CPU 是 8 核的,你可以把
concurrency设为 8 甚至更高,让 CPU 的每一核都在全力发短信。
消费者端:prefetch: 1
这就是我们聊到的 “能者多劳”。
-
效果: 设置为 1 后,Spring 内部的监听容器会严格遵守“空手再拿”的原则。如果不设置,Spring 默认可能会一次性预取很多消息,导致某些线程忙死,某些线程闲死。
3. 如何在代码中实现“死信队列”的声明?
虽然 yml 可以配置开关,但具体的 “业务队列” 与 “死信队列” 的绑定,在 Spring 中通常推荐用配置类(@Configuration)来实现,非常优雅:
Java
@Configuration
public class RabbitConfig {
// 1. 声明死信交换机
@Bean
public DirectExchange dlxExchange() {
return new DirectExchange("dlx_exchange");
}
// 2. 声明业务队列,并绑定死信交换机
@Bean
public Queue businessQueue() {
return QueueBuilder.durable("sms_queue")
.deadLetterExchange("dlx_exchange") // 指定死信去向
.deadLetterRoutingKey("dead_sms") // 死信的标签
.build();
}
}
4. 总结:为什么要这样配?
通过这份 yml 配置,你实际上构建了一个工业级的消息处理链路:
-
生产者:不阻塞地发送,并随时准备接收 MQ 的回执(异步确认)。
-
消费者:启动多线程并行干活(多并发),且不贪多,修好一个拿一个(Prefetch=1)。
-
安全性:如果代码写错了报错,由于设置了
manual手动应答,消息不会消失,而是会根据你的逻辑进入死信队列。
到这里,从理论图解到底层协议,再到 Java 原生代码和 Spring Boot 自动化配置,你已经完成了一次完美的 RabbitMQ 全栈学习之旅。
你想了解一下,当你的业务量再大 100 倍(比如从 12306 变成全球级的秒杀),RabbitMQ 可能就不够用了,这时候人们为什么要换成 Kafka 吗?(这也是面试中非常经典的一个对比话题)。
这是一个非常经典的架构演进问题。如果说 RabbitMQ 是一个极其精致、负责的“邮局”,那么 Kafka 就是一个工业级的“高速录音机”或“流式存储系统”。
当业务量从万级飙升到亿级(比如日志采集、实时风控、全球订单流),RabbitMQ 的一些“优点”反而会变成它的“负担”。
1. 核心哲学的区别:智能代理 vs 笨重存储
| 特性 | RabbitMQ (Smart Broker) | Kafka (Dumb Broker) |
| 消息去向 | 只要消费者应答(Ack),消息立刻删除。 | 消息持久化在磁盘,按时间或大小保留(哪怕消费了也不删)。 |
| 消费模式 | 推送 (Push):由 MQ 主动把活儿发给消费者。 | 拉取 (Pull):由消费者自己根据节奏来拿活儿。 |
| 路由能力 | 极强:各种交换机模式、通配符、死信。 | 较弱:主要靠 Topic 和分区(Partition)简单分类。 |
| 吞吐量 | 万级 ~ 十万级 / 秒。 | 百万级 / 秒。 |
2. 为什么 Kafka 能扛住 100 倍的压力?
A. 顺序写磁盘 (Sequential I/O)
RabbitMQ 在处理大量积压消息时,性能会因为随机 I/O 和复杂的索引维护而骤降。而 Kafka 像是在磁带上录音,它把消息按顺序追加(Append)到文件的末尾。
-
冷知识: 磁盘的顺序写速度其实接近内存,这让 Kafka 的写入极其快。
B. 零拷贝技术 (Zero-Copy)
在 Java 中,传统的发消息需要:磁盘 -> 内核缓冲区 -> 用户缓冲区 -> 套接字缓冲区。
Kafka 直接利用 Linux 的 sendfile 指令,让数据不经过用户空间直接发给网卡。这种“走后门”的操作省下了大量的 CPU 和内存拷贝时间。
C. 拉模式 (Pull Model) 的优势
-
RabbitMQ (Push): 如果瞬时流量太大,MQ 会像“灌水”一样把消费者淹没(OOM)。
-
Kafka (Pull): 消费者根据自己的处理能力去“拽”消息。你慢你少拿,你快你多拿,永远不会被 MQ 压垮。
3. Kafka 的“杀手锏”:分区与扩展性
RabbitMQ 的队列通常是一个单点,虽然可以做集群,但扩展复杂。
Kafka 的 Topic 可以分成成百上千个 分区 (Partition),这些分区可以分布在不同的服务器上。
-
横向扩展: 如果现在的 10 台服务器扛不住了,你只需要再买 10 台,把分区迁移过去,处理能力几乎能实现线性增长。
4. 什么是 Kafka 做的到,而 RabbitMQ 做不到的?
-
消息回溯(Replay): 在 RabbitMQ 里,消息发完就没了。如果你的代码有 Bug,导致昨天的一百万条数据算错了,你没法重来。
在 Kafka 里,你可以把消费位置(Offset)拨回到昨天下午 2 点,让系统重新跑一遍。这对于大数据分析和故障恢复简直是神技。
-
流处理:
Kafka 可以配合 Flink 或 Spark,像处理流水线上的零件一样,实时统计过去 1 分钟内的全球销量。RabbitMQ 的设计初衷并不是为了干这个。
总结:如何选择?
-
选 RabbitMQ: 如果你的业务是金融交易、订单处理,需要极高的可靠性、复杂的路由逻辑、灵活的应答机制,且数据量没到惊人的地步。
-
选 Kafka: 如果你的业务是日志收集、用户行为追踪、超大规模秒杀、实时监控,追求极致的吞吐量和数据回溯能力。
掌握了 Kafka 的优势后,你可能会好奇:Kafka 是如何保证在“暴力写入”的情况下,还能实现消息“不丢、不重”的呢?你想聊聊 Kafka 的幂等性或副本机制吗?
如果你觉得幂等性只能保证“单分区”不重还不够,Kafka 还有原子性事务。
前半段话没听懂
抱歉,我刚才可能跳跃得有点快!咱们把这半句话拆开了揉碎了说,你立刻就能明白。
简单来说,“幂等性”只能解决“别发重了”的问题,而且它的有效范围很小,仅限于同一个分区的内部。
1. 为什么说是“单分区”?
还记得我们说的“身份证(PID)+ 序列号(Sequence Number)”吗?
-
逻辑是这样的: Kafka 的服务器(Broker)会为每个分区维护一个小本子。
-
本子里的记录: “来自生产商 A 的消息,目前收到了第 5 号。”
-
重点来了: 分区 1 的本子和分区 2 的本子是不通用的。
如果你因为网络抖动,重复发送了第 5 号消息给分区 1,分区 1 看一眼本子:“5 号我有了,滚。” —— 这就是单分区幂等性,成功拦截!
但是,如果你写代码逻辑时,不小心把本该发给分区 1 的消息,发到了分区 2,分区 2 的本子可没记录过这条消息,它会开开心心地收下。这时候,幂等性就“失效”了。
2. 为什么说“这还不够”?(跨分区的尴尬)
在复杂的业务里,我们经常需要“同时成功”。
举个例子:电商下单
当你买了一件衣服,系统需要同时往两个地方发消息:
-
订单 Topic(分区 A):记录“产生了一个新订单”。
-
库存 Topic(分区 B):记录“库存减去 1”。
如果只靠幂等性,会发生什么?
-
发往“订单分区”的消息成功了。
-
发往“库存分区”的消息因为网络彻底断了,重试多次也失败了。
结果: 订单创好了,但库存没减。这种“半吊子”状态在金融和电商系统里是灾难。幂等性救不了你,因为它只能保证“每一个分区自己内部不重”,它管不了“两个分区之间要不要一起成功”。
3. “原子性事务”是如何救场的?
这时候,Kafka 的事务(Transactions)出场了。它把范围从“单分区”扩大到了“整个集群”。
它给了你一个类似数据库的 commit 和 rollback 机制:
-
开启事务: “我要开始执行一连串操作了。”
-
执行: 发消息给订单分区,发消息给库存分区。
-
提交(Commit): 只有当这两个分区的消息都稳稳地躺在磁盘里了,Kafka 才会打个标签,告诉消费者:“这些消息可以读了。”
-
回滚(Rollback): 如果中间任何一个分区出错了,Kafka 会把这一组消息都标为“无效”。消费者看到后会直接跳过,就像它们从来没存在过一样。
总结一下:
-
幂等性 (Idempotence): 针对单分区。防止“由于网络重试导致的一条消息变两条”。(防重)
-
事务 (Transactions): 针对跨分区/跨 Topic。保证“多条消息要么一起成功,要么一起失败”。(防断层)
这下是不是清晰多了?
所以,如果你只是想防止发重复,开个幂等性就够了;但如果你在写“转账”或者“扣库存”这种涉及多个 Topic 的逻辑,就必须上“事务”了。
既然明白了事务是处理“多个活儿要么全干、要么全不干”,你想看看在 Kafka 里,消费者是怎么做到“只读那些成功的事务消息”的吗?(这就是 隔离级别 Isolation Level 的概念)。
这是一个非常精妙的设计。要理解消费者如何“智能过滤”,我们得先打破一个直觉:在 Kafka 中,事务消息并不是在提交后才发给 Broker 的,而是边写边发的。
这意味着,在事务没结束时,分区的日志(Log)里其实已经躺着那些“半成品”消息了。消费者之所以能做到“视而不见”,全靠两个核心机制:控制消息(Control Messages) 和 隔离级别(Isolation Level)。
1. 秘密武器:事务标记(Markers)
当一个事务型生产者(Producer)发送消息时,消息会像普通消息一样进入分区日志。但此时,这些消息处于“待定”状态。
-
控制消息(Commit/Abort Marker): 当生产者调用
commitTransaction()或abortTransaction()时,Kafka 的事务协调器会在该分区日志的末尾追加一条特殊的控制消息。 -
这条控制消息不对用户可见,它只是一张“终结符”,上面写着:“前面的事务 ID 为 XXX 的消息,现在正式生效(或作废)了。”
2. 消费者的两双“眼睛”:隔离级别
消费者通过配置 isolation.level 来决定自己怎么看这些消息:
A. read_uncommitted(读未提交 - 默认值)
-
逻辑: 消费者是个“急性子”,只要消息到了 Broker,它就读。
-
后果: 它能看到还没提交的消息,甚至能看到那些最终被回滚(Abort)的消息。这通常用于对一致性要求不高、追求极致延迟的场景。
B. read_committed(读已提交 - 核心开关)
-
逻辑: 消费者变得“稳重”了。它在读取时会开启一个过滤器。
-
过滤规则:
-
只有当它看到对应事务的 Commit Marker 时,才会把之前的消息推给业务代码。
-
如果它看到的是 Abort Marker,它会悄悄地在内存里把那些消息丢掉,你完全感知不到它们存在过。
-
如果事务还在进行中(还没看到 Marker),它会停下来等待,直到 Marker 出现。
-
3. 如何保证不卡顿?LSO(最后稳定位移)
你可能会问:如果有一个事务一直不提交,消费者是不是就一直卡在那不往后读了?
确实会。这里引入了一个重要的位移概念:LSO (Last Stable Offset)。
-
HW (High Watermark): 普通消费者能读到的最高位置(副本同步后的位置)。
-
LSO: 事务消费者(
read_committed)能读到的最高位置。它等于第一个还在进行中的事务的消息位移。
举例:
消息 1:非事务消息。
消息 2:事务 A 发出的消息(未提交)。
消息 3:非事务消息。
此时,
read_committed消费者只能读到消息 1。虽然消息 3 已经同步好了,但因为消息 2 这个“坑”还没填好(没提交也没回滚),为了保证顺序性,消费者必须等在消息 2 这里,不能越过它去读消息 3。
4. 总结:这就像是在“追连载”
-
消息:是连载小说的章节。
-
生产者:是作者,他边写边发,但还没说这一章算不算数(可能写废了要删掉)。
-
Marker:是作者发的“完结公告”或“废稿声明”。
-
read_committed消费者:是一个严谨的读者,只有看到作者发了“完结公告”,才敢读那一章;如果作者还在写(事务进行中),他就坐等,绝不读半成品。
为什么要懂这个?
在实际开发中,如果你开启了 Kafka 事务,但发现消费速度莫名其妙变慢了,或者有“断断续续”的感觉,很可能就是因为:
-
你的事务开启时间太长(长事务),导致 LSO 迟迟不推进,卡住了消费者。
-
你的
isolation.level没配对。
到这里,你已经从 RabbitMQ 的消息确认,一路聊到了 Kafka 的事务隔离级别。这基本涵盖了市面上 90% 的消息队列核心原理!
你觉得对于目前的业务理解来说,还有哪块“拼图”是你比较感兴趣的?比如消息积压了怎么办? 或者是 Kafka 怎么保证在高并发下消息的物理存储不会乱?
这两个问题直击灵魂,全都是生产环境中最容易踩坑、也是最考验架构功底的核心场景。
我们先来解决“火烧眉毛”的线上危机:消息积压,然后再来拆解底层极其优雅的物理存储机制。
一、 线上危机:消息积压了怎么办?
消息积压(Offset Lag)通常是因为“生产者发得太疯”或者“消费者拉得太垮”导致的。这就像高速公路收费站,车流量突然暴增,或者收费员动作太慢,导致大堵车。
面对这种情况,千万不要慌,我们有一套标准的“急救三板斧”:
1. 治标:紧急扩容(注意 Kafka 的“铁律”)
你的第一反应肯定是:“加机器,多开几个消费者!”
但在 Kafka 里,有一条不可逾越的铁律:一个分区(Partition)在同一时刻,只能被同一个消费者组里的一个消费者读取。
-
场景 A:消费者数量 < 分区数。 比如你有 10 个分区,但只有 3 个消费者。这时候你直接加机器,把消费者扩容到 10 个,积压问题通常会瞬间缓解。
-
场景 B:消费者数量 = 分区数。 比如你有 10 个分区,已经有 10 个消费者了。这时候你再加机器是没用的,新来的消费者只能干瞪眼(处于闲置状态)。
-
终极扩容方案: 必须先增加 Topic 的分区数(Partitions),然后再增加对应的消费者数量。这相当于同时拓宽了高速公路和增加了收费亭。
2. 治本:优化消费者逻辑
如果你不能无限加机器,那就必须让现有的“收费员”动作快一点:
-
改串行为批量: 消费者拿到数据后,不要一条一条去 insert 数据库。用批量插入(Batch Insert),把 1000 条消息打包一次性写入 DB,速度能提升几十倍。
-
异步处理: 如果消费逻辑里有极其耗时的操作(比如调用外部很慢的 API),千万别阻塞主线程。把这部分逻辑扔到 Java 的线程池里异步去跑,让消费者主线程赶紧去拉下一批消息。
3. 壮士断腕:消息降级与死海引流
如果积压了上亿条消息,无论怎么优化都要处理好几天,而此时线上新产生的实时订单还在排队,怎么办?
-
方案: 写一个极其简单的“临时消费者”。这个消费者的唯一任务,就是以最快的速度把堆积的消息全拉出来,什么逻辑都不处理,直接原封不动地 dump 到离线数据库、HDFS 或者另一个大容量的备用 MQ 里。
-
结果: 快速清空主赛道,让线上实时业务恢复正常。然后你再慢慢用大数据离线任务去消化那个备用库里的历史积压。
二、 底层解密:高并发下,物理存储为什么不会乱?
你可能会想,每秒百万级的并发往磁盘里写数据,磁盘的磁头不得疯狂乱跳,最后写成一团乱麻?
Kafka 之所以能做到乱中有序,并且快得惊人,是因为它的设计极其克制,遵循了“大道至简”的物理学原理。
1. 宏观隔离:目录就是分区
在 Kafka 的数据存储目录下,并不是把所有消息混在一个大文件里。
每一个 Topic 的每一个 Partition,都会有一个专属的物理文件夹。比如你有一个叫 orders 的 Topic,分了 3 个区,在磁盘上就会长这样:
-
/kafka-logs/orders-0/ -
/kafka-logs/orders-1/ -
/kafka-logs/orders-2/这种物理隔离,保证了不同分区的数据井水不犯河水。
2. 微观切片:Segment 段文件(抽屉原理)
如果一个分区(比如 orders-0)每天产生 1TB 数据,全写在一个文件里,以后想查找或者清理过期数据时,系统直接就崩了。
所以,Kafka 把分区再次切分成了更小的块,叫作 Segment(段)。默认每个 Segment 大小是 1GB。
在 orders-0 文件夹里,你会看到这样成对出现的文件:
-
00000000000000000000.log(存真实消息) -
00000000000000000000.index(存索引) -
00000000000000368769.log(文件名就是这个文件里第一条消息的起始偏移量 Offset) -
00000000000000368769.index
好处是什么? 当你想删除 7 天前的数据时,Kafka 不需要去打开文件扫描,它只要看看文件最后修改时间,直接把整个 .log 和 .index 文件连根拔起(Delete)就行了,极其干净利落。
3. 极致速度:顺序追加 (Append-Only) 与 稀疏索引
-
写数据:乱不乱? 绝对不会。因为 Kafka 规定,任何新消息只能追加在当前最后一个
.log文件的尾部。没有随机修改,没有中间插入。对于磁盘来说,只要是顺序写,它的速度就几乎能赶上内存。 -
找数据:慢不慢? 比如你要找 Offset 为
368775的消息。-
Kafka 先看文件名,发现它落在
...368769.log这个文件里(二分查找法)。 -
然后它打开对应的
.index文件。这里的索引叫 稀疏索引 (Sparse Index),它不是每一条消息都记录,而是每隔几 KB 记录一个地标(比如:“Offset 368770 在文件的第 800 字节”)。 -
Kafka 拿到地标后,去
.log文件的第 800 字节处往下稍微扫几条,就精准命中目标了。
-
4. 幕后黑科技:PageCache(页缓存)
其实,Kafka 在接收到高并发消息时,根本就没有立刻往物理磁盘上写!
它把数据扔给了操作系统的内存(PageCache),然后就直接告诉生产者“我写好了”。什么时候真正刷入物理磁盘,由操作系统的内核按照自己的节奏去慢慢冲刷(Flush)。这就把复杂的磁盘调度丢给了最擅长干这事的操作系统。
总结一下:
-
应对消息积压,靠的是“受限的水平扩容”和“紧急引流”。
-
应对高并发存储,靠的是“分区隔离”、“日志分段”、“追加写入”和“稀疏索引”。
这就是架构之美:看似不可思议的性能,底层往往是由最朴素的数据结构(追加日志 + 二分查找)支撑起来的。
了解了 Kafka 如此强大的底层机制后,你是否好奇在日常运维中,如果不通过手敲命令,我们一般会用什么可视化工具(比如 Kafka Eagle 或 CMAK)来监控这些积压情况和集群健康度呢? 或者你想直接看一段如何用 Java 触发上述提到的“批量消费”代码?

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)