基于深度学习与OpenCV的实时人脸表情识别系统——使用TensorFlow与PyQt5构建的...
屏幕前的摄像头突然亮起蓝光,电脑前的我对着镜头做了个鬼脸。显示器右下角的方框里,红色文字"Surprise"不断跳动——这可不是什么科幻电影场景,而是我们刚完成的实时表情识别系统。这里有个小技巧:最后一层用softmax而不是sigmoid,因为我们要做的是多分类而不是多标签分类。整个项目架构像三明治:底层是TensorFlow构建的卷积神经网络,中间层OpenCV处理视频流,最上层PyQt5负责
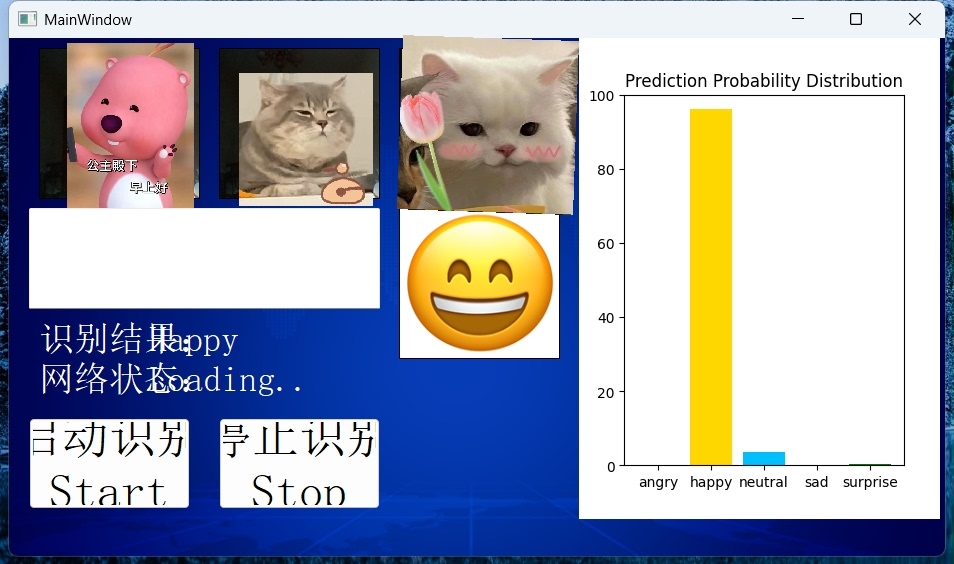
基于深度学习的人脸实时表情识别项目 表情识别部分采用TensorFlow+OpenCV实现,GUI使用pyqt5构建 目前可针对5种表情(Angry,Happy,Neutral,Sad,Surprise)进行识别 本项目已在Python3.7,3.8下测试通过 测试效果图,如下所示 真人人脸遮挡了一下哦
屏幕前的摄像头突然亮起蓝光,电脑前的我对着镜头做了个鬼脸。显示器右下角的方框里,红色文字"Surprise"不断跳动——这可不是什么科幻电影场景,而是我们刚完成的实时表情识别系统。今天就跟大家唠唠这个用Python实现的AI小玩具,代码量不大但效果挺有意思。
整个项目架构像三明治:底层是TensorFlow构建的卷积神经网络,中间层OpenCV处理视频流,最上层PyQt5负责颜值担当。先看核心的实时检测循环:
def realtime_detection():
cap = cv2.VideoCapture(0)
while cap.isOpened():
ret, frame = cap.read()
face = detect_face(frame)
if face is not None:
roi = preprocess(face)
emotion = model.predict(roi)[0]
current_emotion = emotion_labels[np.argmax(emotion)]
frame = draw_prediction(frame, current_emotion)
cv2.imshow('Emotion Detective', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()这段代码里藏着几个关键点:OpenCV的VideoCapture不仅支持摄像头,改个参数就能读取视频文件;detect_face函数里用了Haar级联检测器,虽然有点年头但胜在速度快;预处理时强制转成48x48灰度图,这尺寸是我们模型训练时的输入规格。
说到模型结构,我们采用了一个轻量化的卷积网络:
model = tf.keras.Sequential([
Conv2D(32, (3,3), activation='relu', input_shape=(48,48,1)),
MaxPooling2D((2,2)),
Conv2D(64, (3,3), activation='relu'),
MaxPooling2D((2,2)),
Flatten(),
Dense(128, activation='relu'),
Dropout(0.5),
Dense(5, activation='softmax')
])别看只有5层,在FER2013数据集上能达到68%的准确率。这里有个小技巧:最后一层用softmax而不是sigmoid,因为我们要做的是多分类而不是多标签分类。Dropout层像给模型戴了口罩,防止它死记硬背训练数据。
GUI部分用了PyQt5的流水式布局,重点看看视频显示组件的实现:
class VideoWidget(QWidget):
def __init__(self):
super().__init__()
self.label = QLabel()
layout = QVBoxLayout()
layout.addWidget(self.label)
self.setLayout(layout)
def update_frame(self, cv_img):
qt_img = convert_cv_qt(cv_img)
self.label.setPixmap(qt_img)这里有个坑点:OpenCV的BGR格式转Qt的RGB需要手动转换颜色空间。convertcvqt函数里用了QImage的rgbSwapped方法,相当于给图像美颜滤镜。
基于深度学习的人脸实时表情识别项目 表情识别部分采用TensorFlow+OpenCV实现,GUI使用pyqt5构建 目前可针对5种表情(Angry,Happy,Neutral,Sad,Surprise)进行识别 本项目已在Python3.7,3.8下测试通过 测试效果图,如下所示 真人人脸遮挡了一下哦
实际测试时发现,当人脸倾斜超过30度时识别率明显下降。后来在预处理阶段加了直方图均衡化,效果立竿见影:
def preprocess(face_img):
gray = cv2.cvtColor(face_img, cv2.COLOR_BGR2GRAY)
clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8,8))
enhanced = clahe.apply(gray)
return enhanced.reshape(1,48,48,1).astype('float32')/255.0CLAHE算法比普通直方图均衡更聪明,能避免局部过曝。注意最后的归一化操作,把像素值压缩到0-1之间,这是训练模型时的预处理步骤,预测时必须保持一致。
项目里还有个小彩蛋:按空格键可以冻结当前帧,这时系统会把你的表情截图保存为meme模板。这个功能实现起来简单,但传播效果意外地好——建议不要在有损友在场时演示。
最后说说部署注意事项:用pyinstaller打包时记得把haarcascadefrontalfacedefault.xml和模型文件放进资源目录。遇到过OpenCV动态链接库丢失的情况,后来改用静态编译版本解决问题。
这个项目的GitHub仓库里有详细的配置文档和预训练模型。别看现在只能识别五种表情,改改最后一层神经元数量就能扩展识别种类。下次考虑加入疲劳检测模块,或许能做成网课防摸鱼神器?不过那就是另一个故事了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)