一文秒杀发布架构
本文摘要:文章发布系统采用分库分表设计,使用雪花算法生成唯一ID,并通过异步审核流程(MQ/Kafka)提升性能。审核阶段结合自动与人工审核,采用DFA算法实现敏感词过滤,Tesseract-OCR进行图片识别。内容存储使用MinIO对象存储和Freemarker模板引擎实现静态化展示。系统集成ElasticSearch实现高效全文检索,通过Canal+MQ保持MySQL与ES数据同步。支付系统采
文章发布
流程 表设计 ID 雪花算法
超过 多数如何分库分表
异步审核-mq信息队列 kafk
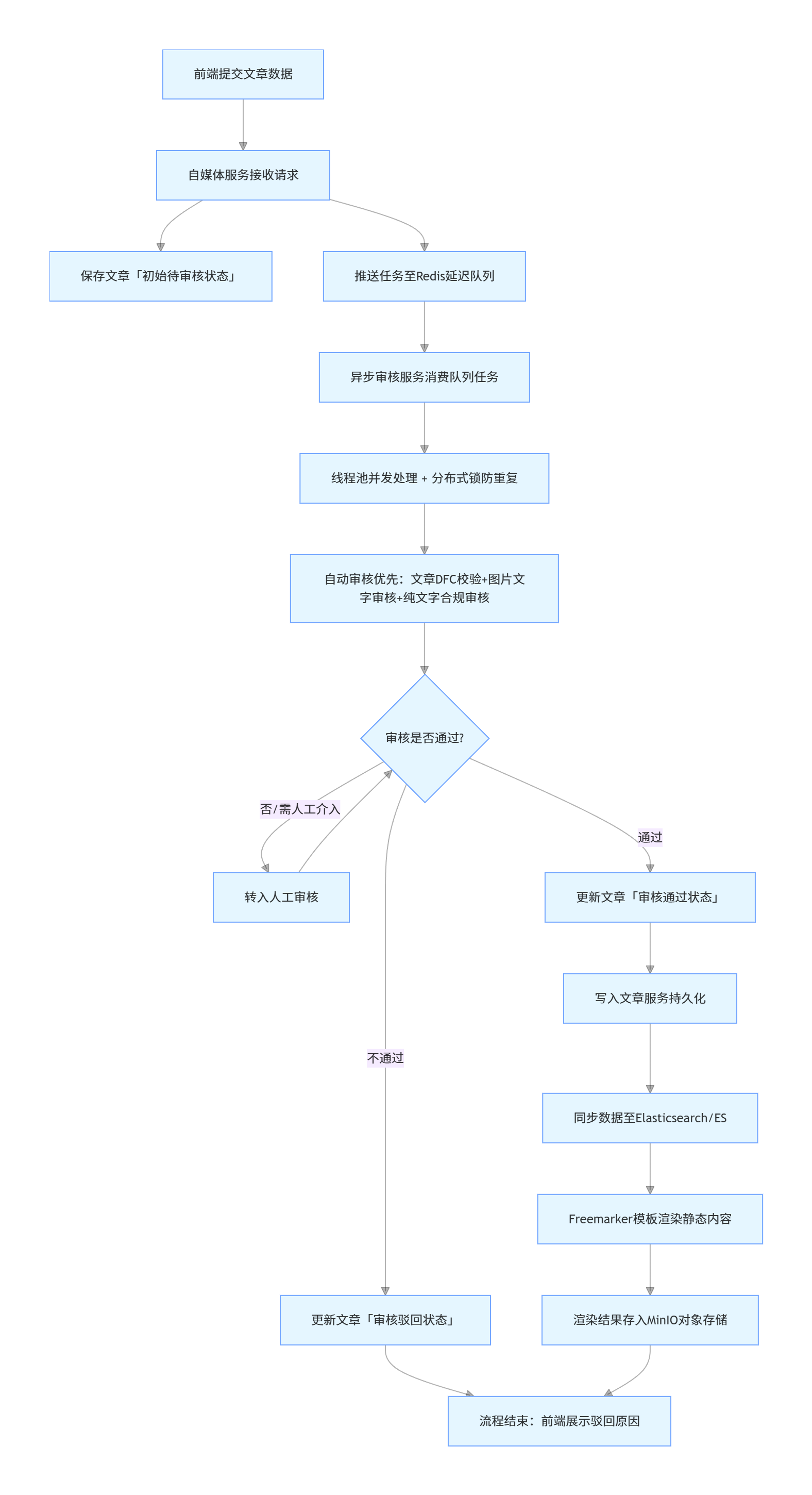
文章发布涉及以下几个阶段:前端提交 → 自动审核 → 人工审核/等待发布 → 存储/展示。
文章审核
文章异步审核
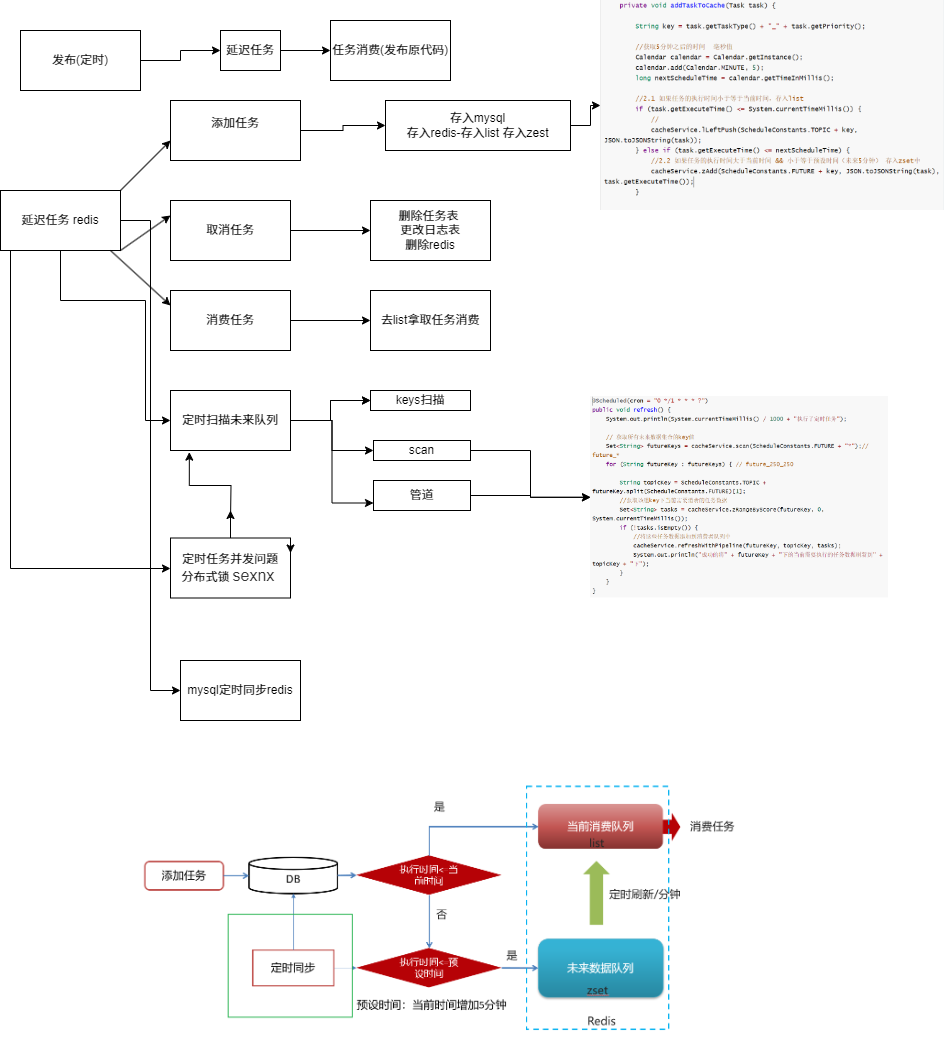
DelayQueue属于排序队列,它的特殊之处在于队列的元素必须实现Delayed接口,该接口需要实现compareTo和getDelay方法 只适合单体项目
延迟队列 redis-涉及到多线程,需要锁
RabbitMQ实现延迟任务
TTL:Time To Live (消息存活时间)
死信队列:Dead Letter Exchange(死信交换机),当消息成为Dead message后,可以重新发送另一个交换机(死信交换机)
zset数据类型的去重有序(分数排序)特点进行延迟。例如:时间戳作为score进行排序
1.为什么任务需要存储在数据库中?
延迟任务是一个通用的服务,任何需要延迟得任务都可以调用该服务,需要考虑数据持久化的问题,存储数据库中是一种数据安全的考虑。
2.为什么redis中使用两种数据类型,list和zset?
效率问题,算法的时间复杂度
3.在添加zset数据的时候,为什么不需要预加载?
任务模块是一个通用的模块,项目中任何需要延迟队列的地方,都可以调用这个接口,要考虑到数据量的问题,如果数据量特别大,为了防止阻塞,只需要把未来几分钟要执行的数据存入缓存即可。
表设计
taskinfo
CREATE TABLE taskinfo ( id BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '任务ID', task_code VARCHAR(64) NOT NULL COMMENT '任务唯一编码', task_name VARCHAR(128) NOT NULL COMMENT '任务名称', task_type VARCHAR(32) NOT NULL COMMENT '任务类型(SINGLE/CRON/DELAY等)', status TINYINT NOT NULL DEFAULT 0 COMMENT '任务状态:0-待执行 1-执行中 2-成功 3-失败 4-暂停', execute_class VARCHAR(255) NOT NULL COMMENT '执行类(全限定类名)', execute_method VARCHAR(64) NOT NULL COMMENT '执行方法名', cron_expression VARCHAR(64) DEFAULT NULL COMMENT 'cron表达式(定时任务)', delay_seconds INT DEFAULT NULL COMMENT '延迟执行秒数', retry_count INT NOT NULL DEFAULT 0 COMMENT '最大重试次数', retry_interval INT NOT NULL DEFAULT 0 COMMENT '重试间隔(秒)', last_execute_time DATETIME DEFAULT NULL COMMENT '最近一次执行时间', next_execute_time DATETIME DEFAULT NULL COMMENT '下一次执行时间', remark VARCHAR(255) DEFAULT NULL COMMENT '备注说明', create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', update_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', UNIQUE KEY uk_task_code (task_code), KEY idx_status (status), KEY idx_next_execute_time (next_execute_time) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='任务信息表';
taskinfo_logs(任务日志表)
记录每一次任务执行情况
支持失败原因、异常堆栈
与任务表一对多关系
CREATE TABLE taskinfo_logs ( id BIGINT PRIMARY KEY AUTO_INCREMENT COMMENT '日志ID', task_id BIGINT NOT NULL COMMENT '任务ID', task_code VARCHAR(64) NOT NULL COMMENT '任务编码(冗余字段,便于查询)', execute_status TINYINT NOT NULL COMMENT '执行状态:0-开始 1-成功 2-失败', execute_times INT NOT NULL DEFAULT 0 COMMENT '当前执行次数(第几次重试)', start_time DATETIME NOT NULL COMMENT '开始时间', end_time DATETIME DEFAULT NULL COMMENT '结束时间', execute_time_ms BIGINT DEFAULT NULL COMMENT '执行耗时(毫秒)', error_message VARCHAR(512) DEFAULT NULL COMMENT '错误信息', error_stack TEXT DEFAULT NULL COMMENT '异常堆栈信息', create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '日志创建时间', KEY idx_task_id (task_id), KEY idx_task_code (task_code), KEY idx_execute_status (execute_status), CONSTRAINT fk_task_log FOREIGN KEY (task_id) REFERENCES taskinfo(id) ON DELETE CASCADE ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='任务执行日志表';
/**
* mybatis-plus乐观锁支持
* @return
*/
@Bean
public MybatisPlusInterceptor optimisticLockerInterceptor(){
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
return interceptor;
}
安装redis-dcoker
CacheService封装
项目集成redis pom -添加自动配置
com.heima.common.redis.CacheService,\ CacheService 是 对 Spring Data Redis 的二次封装(Facade / 门面层),把底层 StringRedisTemplate + RedisConnection 的复杂 API,统一收敛为业务可直接调用的缓存服务。
可学习封装
Redis 本身只提供命令:
SET / GET / HSET / LPUSH / ZADD / SCAN / SETNX / EXPIRE ...
Spring Data Redis 层(Template 抽象)
核心对象 RedisConnection RedisConnectionFactory RedisTemplate StringRedisTemplate
stringRedisTemplate.opsForValue().set(key, value); stringRedisTemplate.opsForHash().put(key, field, value);
API 极多、分散在 opsForXxx
业务层要理解 Redis 数据结构
pipeline / scan / lock 仍然复杂
CacheService(二次封装层,关键)
| 封装点 | 做了什么 |
|---|---|
| 统一入口 | 所有 Redis 操作通过 CacheService |
| 语义化方法名 | set / get / hPut / lLeftPush / zAdd |
| 隐藏 opsForXxx | 业务层不感知 RedisTemplate |
| 提供高级能力 | pipeline / scan / 分布式锁 |
| 统一技术栈 | 强制 StringRedisTemplate |
stringRedisTemplate.opsForValue().set(key, value);
public void set(String key, String value) {
stringRedisTemplate.opsForValue().set(key, value);
}
隔离 RedisTemplate
后期可统一加:
-
日志
-
监控
-
限流
-
Key 前缀
HSET user:1 name Tom
cacheService.hPut("user:1", "name", "Tom");
不关心 Redis 是 Hash 还是 String。
添加任务
heima-leadnews/heima-leadnews-service/heima-leadnews-schedule
/**
* 对外访问接口
*/
public interface TaskService {
/**
* 添加任务
* @param task 任务对象
* @return 任务id
*/
public long addTask(Task task) ;
/**
* 取消任务
* @param taskId 任务id
* @return 取消结果
*/
public boolean cancelTask(long taskId);
/**
* 按照类型和优先级来拉取任务
* @param type
* @param priority
* @return
*/
public Task poll(int type,int priority);
}
TaskServiceImpl
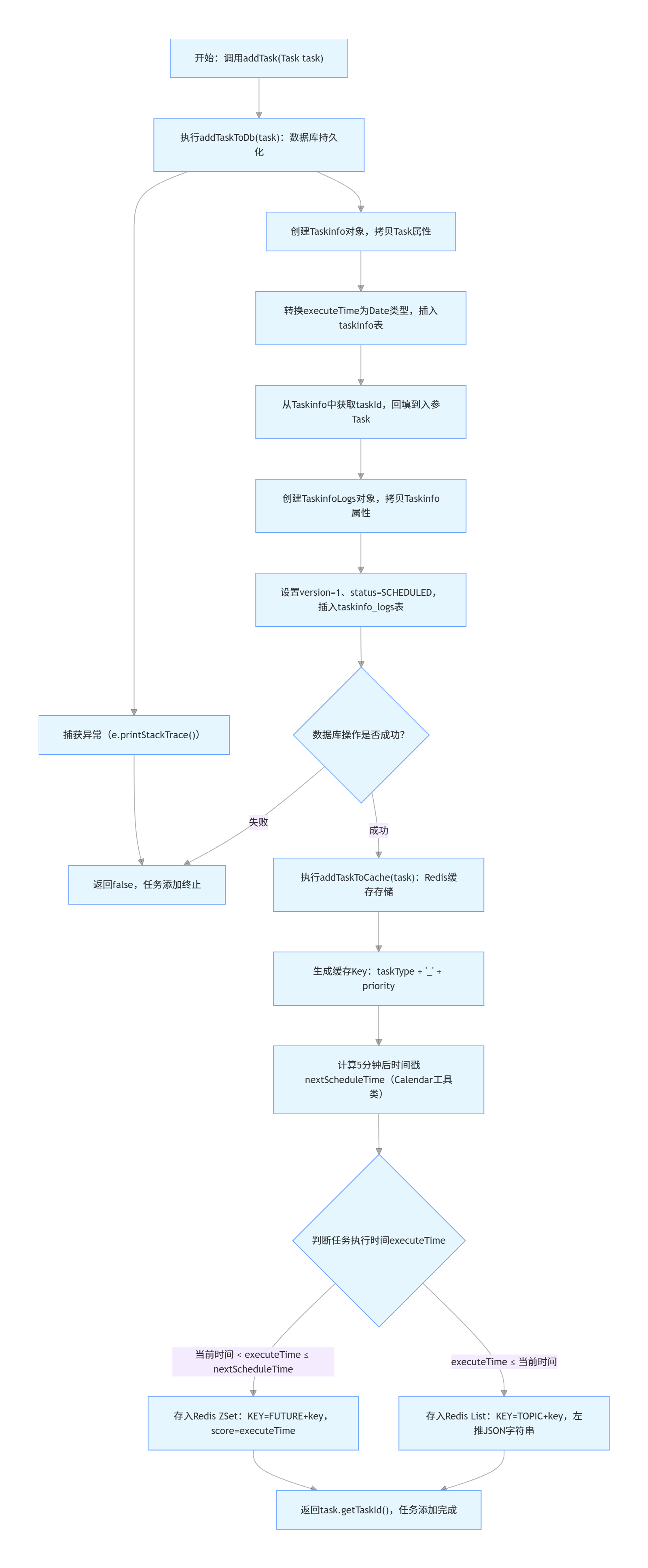
Redis 的 List 队列(TOPIC 前缀)用于存储立即执行的任务,支持消费端快速拉取;ZSet 队列(FUTURE 前缀)用于存储未来 5 分钟内执行的任务,按执行时间排序后通过定时任务刷新到 List 队列,实现延迟任务的精准调度。
同步任务 zset到list -管道技术
Set<String> futureKeys = cacheService.scan(ScheduleConstants.FUTURE + "*");
cacheService.refreshWithPipeline(futureKey, topicKey, tasks);
加锁
sexnx (SET if Not eXists) 命令在指定的 key 不存在时,为 key 设置指定的值。
这种加锁的思路是,如果 key 不存在则为 key 设置 value,如果 key 已存在则 SETNX 命令不做任何操作
A-设置key-value
b-返回失败
A-执行代码完成-删除key-value
B-设置key成功
给服务器设置key值思路-再执行代码的时候时候key值-结束代码取消key值
同步数据
任务的消费
解锁
消费任务
则 1:依赖 Redis 单条命令的原子性
成立的操作:
-
SET / GET -
INCR / DECR -
LPUSH / RPOP -
ZADD / ZREM -
HSET / HGET
提供远程的feign接口,在heima-leadnews-feign-api编写类如下
消费任务
@Scheduled(fixedRate = 1000)
@Override
@SneakyThrows
public void scanNewsByTask(){
//去远程poll即可
}
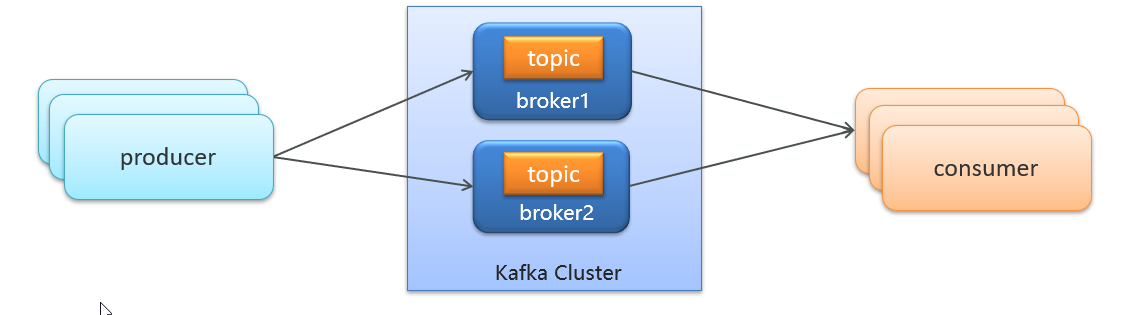
Kafka上下架
A B C
Bkafka
A ->B->c
特点
| Kafka | MQ | |
|---|---|---|
| 存储 | 磁盘顺序写 | 内存 + 磁盘 |
| 是否持久化 | 默认全部持久化 | 可配置 |
| 是否可回溯 | ✅(按 offset) | ❌(消费即删除) |
| 维度 | Kafka | MQ |
|---|---|---|
| 本质 | 日志 | 消息 |
| 消息是否删除 | 不删(到期) | 消费即删 |
| 是否支持重放 | 天然支持 | 困难 |
| 吞吐 | 极高 | 中 |
| 延迟 | 稍高 | 更低 |
| 业务友好度 | 偏底层 | 偏业务 |
| 学习成本 | 高 | 低 |
Kafka 追求高吞吐量,适合产生大量数据的互联网服务的数据收集业务
emm,回头了解了解
看代码方面
敏感词系统
| 方案 | 说明 |
|---|---|
| 数据库模糊查询 | 效率太低 |
| String.indexOf("")查找 | 数据库量大的话也是比较慢 |
| 全文检索 | 分词再匹配 |
| DFA算法 | 确定有穷自动机(一种数据结构) |
//从内容中提取纯文本内容和图片 //2.审核文本内容 阿里云接口 //自管理的敏感词过滤 //3.审核图片 阿里云接口 //4.审核成功,保存app端的相关的文章数据 //回填article_id
本地审核Dfa
选用 DFA 的原因在于: 它能够在不依赖数据库、不引入全文检索系统的前提下,以 O(n) 的时间复杂度完成多关键词匹配,性能稳定、可预测,适合高并发实时校验场景。
| 需求 | 正确方案 |
|---|---|
| 实时校验 | DFA / AC |
| 内容拦截 | DFA |
| 敏感词过滤 | DFA |
| 搜索 | ES |
| 召回 / 推荐 | ES |
| 离线分析 | ES / Spark |

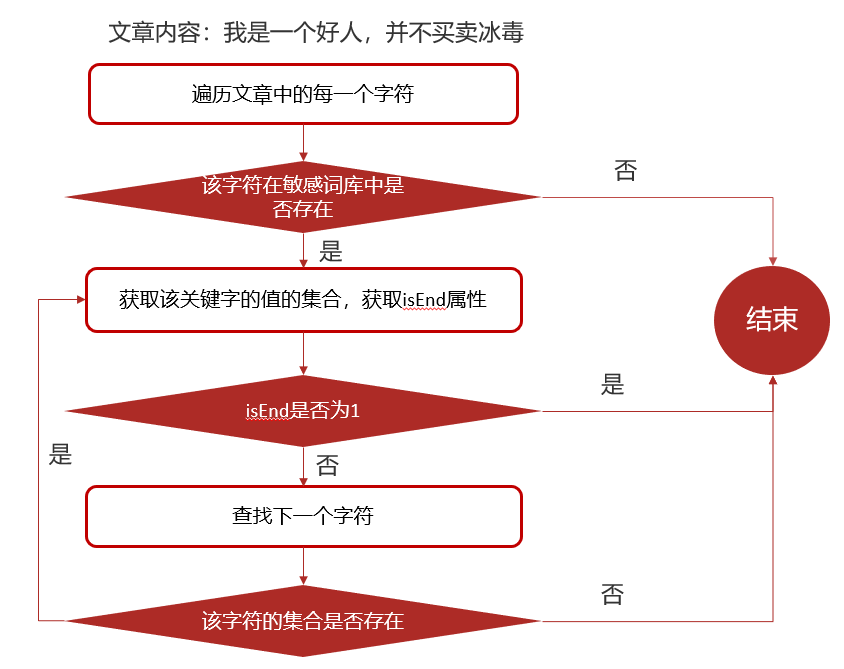
先准备好 “闯关地图”:要找的敏感词是 “病毒”,所以地图只有一条路 —— 先走到 “病”,再走到 “毒” 就算成功。
开始逐个检查句子里的字:
-
先看 “我”:不是地图的第一个字 “病”,跳过;
-
再看 “是”“个”“小”“画”“家”“,”:都不是 “病”,全跳过;
-
看到 “病”:刚好是地图第一步,赶紧看下一个字 “毒”;
-
看到 “毒”:刚好是地图第二步(终点),马上发现 “病毒” 这个敏感词;
-
最后看剩下的 “害”“怕”:都不是地图的开头,检查完啦。
DFA 找敏感词得一个字挨着一个字按顺序凑成敏感词
@Autowired
private WmSensitiveMapper wmSensitiveMapper;
/**
* 自管理的敏感词审核
* @param content
* @param wmNews
* @return
*/
private boolean handleSensitiveScan(String content, WmNews wmNews) {
boolean flag = true;
//获取所有的敏感词
List<WmSensitive> wmSensitives = wmSensitiveMapper.selectList(Wrappers.<WmSensitive>lambdaQuery().select(WmSensitive::getSensitives));
List<String> sensitiveList = wmSensitives.stream().map(WmSensitive::getSensitives).collect(Collectors.toList());
//初始化敏感词库-dfa模式
SensitiveWordUtil.initMap(sensitiveList);
//查看文章中是否包含敏感词-dfa-进行查找
Map<String, Integer> map = SensitiveWordUtil.matchWords(content);
if(map.size() >0){
updateWmNews(wmNews,(short) 2,"当前文章中存在违规内容"+map);
flag = false;
}
return flag;
}
SensitiveWordUtil
图片审核
| 方案 | 说明 |
|---|---|
| 百度OCR | 收费 |
| Tesseract-OCR | Google维护的开源OCR引擎,支持Java,Python等语言调用 |
| Tess4J | 封装了Tesseract-OCR ,支持Java调用 |
<dependency> <groupId>net.sourceforge.tess4j</groupId> <artifactId>tess4j</artifactId> <version>4.1.1</version> </dependency>
导入中文字体库, 把资料中的tessdata文件夹拷贝到自己的工作空间下
public class Application {
public static void main(String[] args) {
try {
//获取本地图片
File file = new File("D:\\26.png");
//创建Tesseract对象
ITesseract tesseract = new Tesseract();
//设置字体库路径
tesseract.setDatapath("D:\\workspace\\tessdata");
//中文识别
tesseract.setLanguage("chi_sim");
//执行ocr识别
String result = tesseract.doOCR(file);
//替换回车和tal键 使结果为一行
result = result.replaceAll("\\r|\\n","-").replaceAll(" ","");
System.out.println("识别的结果为:"+result);
} catch (Exception e) {
e.printStackTrace();
}
}
}
用到再说,有就行
阿里云审核超时
自行查看文档
保底处理
定时任务扫描审核异常文章
接口超时处理:
-
阿里云审核接口超时
-
人工审核超时
触发重试逻辑或人工提醒
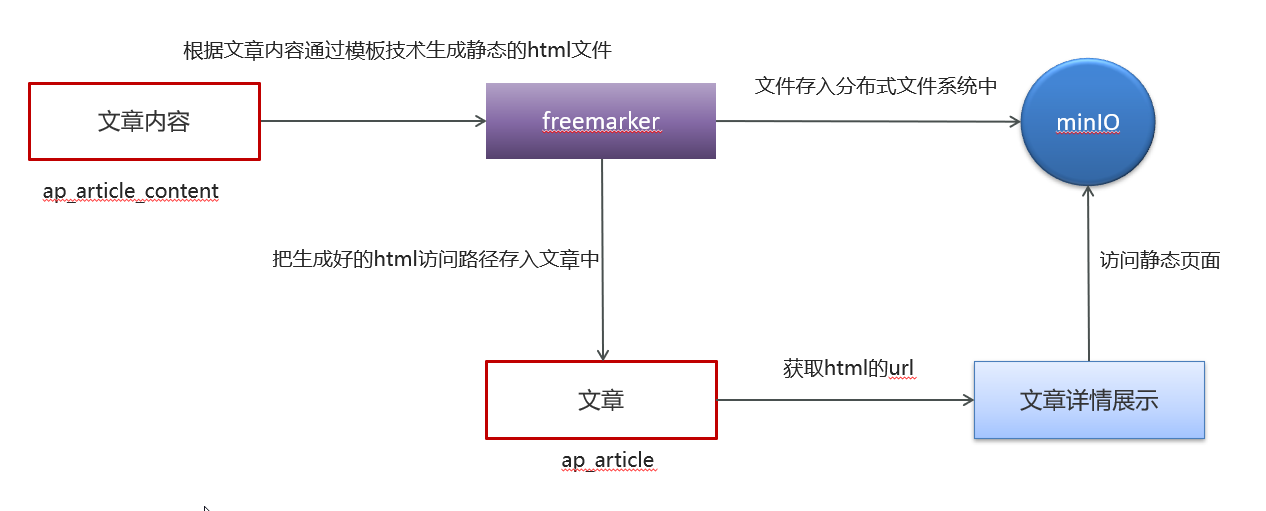
minio+freemaker 文章展示技术
┌───────────────┐ │ 客户端 │ Web / App / 小程序 └───────▲───────┘ │ HTTP ┌───────┴───────────────┐ │ API 网关 / BFF 层 │ └───────▲───────────────┘ │ ┌───────┴───────────────┐ │ 文章服务(Article) │ │ - 文章元数据 │ │ - 文章状态 │ │ - 模板选择 │ └───────▲───────────────┘ │ ┌───────┴─────────────────────────┐ │ 内容渲染子系统(核心) │ │ - FreeMarker 模板引擎 │ │ - 静态化生成 │ │ - HTML 管理 │ └───────▲───────────────▲─────────┘ │ │ ┌───────┴───────┐ ┌───┴─────────┐ │ MinIO │ │ MySQL │ │ HTML / 图片 │ │ 文章元数据 │ └───────────────┘ └──────────────┘
MinIO 用于存储文章大文本、图片、附件
Freemarker 用于动态生成文章HTML模板
HTML 可直接 CDN 缓存
不走数据库,极大减压
支持大文件、并发读
Freemarker 代码仓库
https://gitee.com/laomaodu/freemarker-demo
MinIO
MinIO 是面向非结构化数据的高性能对象存储,适合静态内容、大文件和微服务文件解耦场景,尤其适合私有化与高并发读场景。
| 维度 | MinIO | 本地磁盘 | OSS / S3 |
|---|---|---|---|
| 扩展性 | 高 | 低 | 高 |
| 成本 | 低 | 低 | 高 |
| 私有化 | 支持 | 支持 | 不支持 |
| 运维 | 简单 | 简单 | 无 |
| 性能 | 高 | 中 | 高 |
-
bucket – 类比于文件系统的目录
-
Object – 类比文件系统的文件
-
Keys – 类比文件名
数据保护-Minio Erasure Code(纠删码)-即便损坏一半以上的driver,但是仍然可以从中恢复。
高性能-
可扩容-不同MinIO集群可以组成联邦,并形成一个全局的命名空间,并跨越多个数据中心
docker部署 -spring继承
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream("D:\\list.html");;
//1.创建minio链接客户端
MinioClient minioClient = MinioClient.builder().credentials("minio", "minio123").endpoint("http://192.168.200.130:9000").build();
//2.上传
PutObjectArgs putObjectArgs = PutObjectArgs.builder()
.object("list.html")//文件名
.contentType("text/html")//文件类型
.bucket("leadnews")//桶名词 与minio创建的名词一致
.stream(fileInputStream, fileInputStream.available(), -1) //文件流
.build();
minioClient.putObject(putObjectArgs);
System.out.println("http://192.168.200.130:9000/leadnews/ak47.jpg");
} catch (Exception ex) {
ex.printStackTrace();
}
封装
https://gitee.com/laomaodu/java-composition-tool
不是啥好封装
@Test
public void testUpdateImgFile() {
try {
FileInputStream fileInputStream = new FileInputStream("E:\\tmp\\ak47.jpg");
String filePath = fileStorageService.uploadImgFile("", "ak47.jpg", fileInputStream);
System.out.println(filePath);
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
实际操作
ES
| 作用 | 说明 | 典型价值 |
|---|---|---|
| 全文检索 | 分词 + 倒排索引 | 比 like 快几个数量级 |
| 多条件组合查询 | must / should / filter | 支撑复杂检索 |
| 模糊搜索 | 拼写纠错、前缀、近似匹配 | 搜索体验好 |
| 高并发查询 | 查询与写入分离 | 抗流量能力强 |
| 实时索引 | 秒级可搜索 | 近实时系统 |
| 聚合分析 | terms / avg / max | 统计、报表 |
| 排序与权重 | relevance score | 智能排序 |
ElasticSearch(ES)索引文章,支持搜索功能
两种同步,一种类似于监听,
| 维度 | 代码直写 ES | Canal + MQ 同步 ES |
|---|---|---|
| 数据写入时机 | 同步 / 业务内 | 异步 |
| 业务代码复杂度 | ❌ 高(侵入业务) | ✅ 低(解耦) |
| MySQL 是否是唯一数据源 | ❌ 否 | ✅ 是 |
| ES 与 MySQL 一致性 | 强一致(理论) | 最终一致 |
| 失败处理 | 复杂(补偿、回滚) | 简单(MQ 重试) |
| 系统解耦 | ❌ 强耦合 | ✅ 高度解耦 |
| 扩展性 | ❌ 差 | ✅ 很好 |
| 并发 / 削峰 | ❌ 无 | ✅ MQ 天然削峰 |
| ES 宕机影响 | ❌ 直接影响业务 | ✅ 不影响写库 |
| 适合数据量 | 小 | 中 / 大 / 超大 |
mysql -cancl-mq-mq接收上传es
代码上传成功,然后再到es
发布流程与ES索引无耦合,异步更新
ID分库分表
CREATE TABLE user ( id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自增主键', uuid CHAR(36) NOT NULL COMMENT '全局唯一标识,适用于分库分表', )
不想多少,见架构设计,同时这个还可以干啥呢
还可以冷热分离数据
因为某些文章基本这辈子不看了
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0 Mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法
@TableId(value = "id",type = IdType.ID_WORKER) private Long id;
mybatis-plus: mapper-locations: classpath*:mapper/*.xml # 设置别名包扫描路径,通过该属性可以给包中的类注册别名 type-aliases-package: com.heima.model.article.pojos global-config: datacenter-id: 1 workerId: 1
分库分表本质就是在一次 SQL 执行前,动态决定:
用 哪个数据库连接(DataSource)
用 哪张真实表(table_xx)
而 MyBatis / MyBatis-Plus 本身并不具备分库分表能力,真正做到“动态切换”的,是 拦截器 + 路由规则 + ThreadLocal 上下文。
在 SQL 真正发送到数据库之前,通过拦截器计算路由规则,动态替换 DataSource 和表名。
Service ↓ Mapper 方法 ↓ MyBatis 生成 MappedStatement ↓ Executor ↓ DataSource 获取 Connection ↓ JDBC 执行 SQL
Mapper ↓ 【分库分表拦截器】 → 决定库 → 决定表 ↓ Executor ↓ 正确的 DataSource + 正确的 SQL
评论开发
评论表设计
设计好处
流程开发
mingodb
文章查询
为什么使用es
es的使用 -优势
文章发布--异步-es -
涉及到mysql--es的同步操作
| 作用 | 说明 | 典型价值 |
|---|---|---|
| 全文检索 | 分词 + 倒排索引 | 比 like 快几个数量级 |
| 多条件组合查询 | must / should / filter | 支撑复杂检索 |
| 模糊搜索 | 拼写纠错、前缀、近似匹配 | 搜索体验好 |
| 高并发查询 | 查询与写入分离 | 抗流量能力强 |
| 实时索引 | 秒级可搜索 | 近实时系统 |
| 聚合分析 | terms / avg / max | 统计、报表 |
| 排序与权重 | relevance score | 智能排序 |
ElasticSearch(ES)索引文章,支持搜索功能
两种同步,一种类似于监听,
| 维度 | 代码直写 ES | Canal + MQ 同步 ES |
|---|---|---|
| 数据写入时机 | 同步 / 业务内 | 异步 |
| 业务代码复杂度 | ❌ 高(侵入业务) | ✅ 低(解耦) |
| MySQL 是否是唯一数据源 | ❌ 否 | ✅ 是 |
| ES 与 MySQL 一致性 | 强一致(理论) | 最终一致 |
| 失败处理 | 复杂(补偿、回滚) | 简单(MQ 重试) |
| 系统解耦 | ❌ 强耦合 | ✅ 高度解耦 |
| 扩展性 | ❌ 差 | ✅ 很好 |
| 并发 / 削峰 | ❌ 无 | ✅ MQ 天然削峰 |
| ES 宕机影响 | ❌ 直接影响业务 | ✅ 不影响写库 |
| 适合数据量 | 小 | 中 / 大 / 超大 |
mysql -cancl-mq-mq接收上传es
代码上传成功,然后再到es
发布流程与ES索引无耦合,异步更新
文章热点
文章分值计算算法
实时计算kafka stream
大数据flink
历史搜索
| 存储 | 是否推荐 | 适用场景 |
|---|---|---|
| Redis | ⭐⭐⭐⭐⭐ | 用户搜索历史、最近 N 条 |
| MySQL | ⭐⭐⭐⭐ | 长期存储、统计 |
| Elasticsearch | ⭐⭐⭐ | 模糊搜索、关键词分析 |
| MongoDB | ⭐⭐ | 文档型、灵活但收益不大 |
| 本地文件 | ❌ | 不可扩展 |
用户搜索 ↓ 写 Redis(ZSet,实时) ↓ 发送 MQ / 异步任务 ↓ 落 MySQL(持久化、分析)
Redis + MySQL + ES
热词/推荐系统分离
支付系统
支付怎么涉及,用了什么涉及模式
支付系统的核心是:支付单隔离、状态机驱动、幂等处理、异步回调、最终一致性。
文章展示
文章内容基本固定,有必要次次回表吗,我们用了什么技术
freemarker+minio
文章上下架
纯纯使用kafka
如何热部署的
jenkins

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)