Densely Connected Parameter-Efficient Tuning for Referring Image Segmentation
但它们提出的模块(如 Bridger,Xu et al., 2023;一些开创性工作(如 ETRIS 和 BarleRIa,Wang et al., 2023)尝试以参数高效的方式微调 CLIP(Radford et al., 2021)以用于指代表达图像分割,但仍面临若干局限:(i)这些方法主要依赖于在骨干网络早期阶段进行多模态特征融合,未能充分利用更全面的全局特征,从而导致性能不够理想。Zhu
Abstract
在计算机视觉领域,参数高效调优(Parameter-Efficient Tuning,PET)正日益取代传统的“预训练 + 全量微调”范式。PET 尤其受到大规模基础模型的青睐,因为它能够降低迁移学习成本并提升硬件资源利用效率。然而,现有的 PET 方法主要针对单模态优化而设计。尽管一些开创性研究已进行了初步探索,但仍停留在对齐编码器(如 CLIP)这一层面,缺乏对非对齐编码器(misaligned encoders)的深入研究。面对非对齐编码器时,这些方法往往表现不佳,原因在于它们在微调过程中无法有效对齐多模态特征。为此,本文提出 DETRIS:一种参数高效调优框架,通过在每一层与所有前序层之间建立稠密互连来增强低秩视觉特征的传播,从而实现有效的跨模态特征交互,并适配非对齐编码器。我们还建议引入文本适配器(text adapters)以提升文本特征表示。该方法简单而高效,在具有挑战性的基准上进行评估时,仅需更新 0.9%–1.8% 的骨干网络参数,即可显著超越当前最先进方法。
1 Introduction
指代表达图像分割(Referring Image Segmentation,RIS)旨在根据自然语言描述,预测图像中目标对象的分割掩膜。与语义分割不同,语义分割是将图像中的每个像素从预定义类别集合中分配一个标签;而 RIS 则需要对语言与视觉内容进行更细致的理解,以准确定位并分割出描述所指的对象。RIS 任务具有重要意义,因为它能够有效弥合自然语言描述与细粒度视觉感知之间的鸿沟(Ji 等,2024)。这一能力对于推动人工智能领域的发展至关重要,尤其是在自动驾驶/自主系统、基于图像的检索以及人机交互等方向。RIS 的复杂性主要来自于:模型需要解释任意长度的上下文,并理解开放世界词表——其中包含大量的物体名称、属性描述以及位置指代等信息(Li 等,2024b)。同时,对被指代对象进行精确分割的要求,使得这一密集预测任务成为视觉语言理解领域最具挑战性的任务之一。
在计算机视觉领域,扩展基础模型规模(Radford et al., 2021;Li et al., 2022b;Ma et al., 2022b;Oquab et al., 2023;Fang et al., 2023)正变得愈发重要。这类模型利用大规模数据集学习更加全面的视觉特征。规模扩展不仅增强了模型识别视觉数据中细微差异的能力,也显著提升了其泛化性能。随着参数量增加并接触更广泛的数据分布,这些模型能够更好地应对多样且复杂的视觉任务(Ma et al., 2022a;He et al., 2023, 2024a;Fang et al., 2024;Zhuang et al., 2025),展现出对真实世界应用至关重要的鲁棒性(He et al., 2024b)。
然而,这些模型的预训练任务与下游应用的具体需求之间往往存在差距。如何通过高效的适配来弥合这一差距,是一个极具挑战性的问题。近期研究(Wang et al., 2022;Ding et al., 2022;Yang et al., 2022;Liu, Ding, and Jiang, 2023a;Li et al., 2023)表明,对强大的预训练模型进行微调能够有效提升指代表达图像分割(Referring Image Segmentation)的性能。但一个普遍的难点在于:为了适应密集预测任务,这类方法通常需要全量微调。这一过程会调整大量在预训练阶段已被优化过的参数,从而可能导致宝贵的预训练知识被削弱或遗忘(Kim et al., 2022;Liu, Ding, and Jiang, 2023a;Liu et al., 2023a;Wu et al., 2024)。此外,这些方法往往需要为每个数据集分别维护一套针对预训练模型的微调参数,进而带来显著的部署与存储成本。随着预训练模型规模持续增长——其参数量已从数亿级扩展到万亿级(Li et al., 2022a;Zhou et al., 2022;Chen et al., 2022b;Sun et al., 2023)——这一问题将变得尤为突出。
已发展出多种参数高效调优方法,以在运行效率与模型性能之间取得更优平衡(Gao et al., 2021;Chen et al., 2022a;Zhou et al., 2022;Wang et al., 2023;Li et al., 2024a;Liu et al., 2024a,c)。然而,尽管已有这些工作贡献,现有方法的适用范围仍较为受限,主要被用于单模态任务(Guo, Rush, and Kim, 2020;Houlsby et al., 2019;Chen et al., 2022c)或较为简单的分类问题(Gao et al., 2021;Chen et al., 2022a;Zhou et al., 2022)。对于密集预测任务以及多模态之间更细粒度、更复杂的交互机制,相关研究仍存在明显空白。一些开创性工作(如 ETRIS 和 BarleRIa,Wang et al., 2023)尝试以参数高效的方式微调 CLIP(Radford et al., 2021)以用于指代表达图像分割,但仍面临若干局限:(i)这些方法主要依赖于在骨干网络早期阶段进行多模态特征融合,未能充分利用更全面的全局特征,从而导致性能不够理想。(ii)此外,现有的参数高效模块(如 Bridger,Xu et al., 2023;以及 GST,Wang et al., 2023)在多尺度建模方面能力有限。这些方法往往直接融合两种模态的信息,难以捕获不同尺度下视觉数据的完整复杂性。
我们的方法通过引入一种简单而高效的方案来回答这一问题:该方案通过多尺度建模并融合全局先验信息,提升预训练视觉语言模型在下游适配过程中的有效性。具体而言,我们提出一种名为 Dense Aligner 的适配器,可无缝集成到预训练模型中,以支持密集预测任务。Dense Aligner 包含两个定制模块:(i)稠密混合卷积模块,用于从中间层提取多尺度语义特征;(ii)交叉对齐(cross-aligner)模块,用于促进视觉特征与文本特征之间的信息交换。其次,我们提出引入 文本适配器(text adapters) 来增强文本编码器,并进一步利用增强后的文本特征提升视觉与语言特征之间的对齐效果。
我们的框架基于双编码器(dual encoder)架构。不同于以往依赖高度对齐编码器(如 CLIP)的参数高效微调(PEFT)方法,我们支持将 DINO(Oquab et al., 2023)作为视觉编码器。选择 DINO 作为视觉主干主要基于以下几点考虑:(i)DINO 的自监督学习方式具有更强的泛化能力,相较于 CLIP(Radford et al., 2021),在密集预测任务中往往更具优势。(ii)由于 DINO 缺乏多模态预训练,尤其缺少视觉—文本对齐能力,使其难以直接应用于指代表达图像分割任务。正是这一不足凸显了我们所提出模块的重要性:它能够显著提升模型能力,尤其是在增强视觉—语言对齐以及执行密集预测任务方面。
我们的主要贡献如下:
-
我们将强大的预训练模型 DINO 引入 RIS 任务,并提出一种参数高效的视觉—文本对齐微调策略,无需复杂的结构设计。
-
我们提出一种简单而高效的适配器 Dense Aligner,可无缝集成到预训练骨干网络中,用于增强并交互其中间层特征,从而改善 DINO 与语言的对齐能力,并提升其在密集预测任务上的表现。
-
实验结果表明,在仅更新骨干网络 0.9%–1.8% 参数的情况下,我们的方法在指代表达图像分割任务上显著超过了当前最先进的全量微调方法。
2 Related Work
参数高效调优(Parameter Efficient Tuning,PET)旨在以尽可能少的参数调整,将预训练模型适配到新任务上,从而简化迁移过程。随着模型规模不断扩大,PET 成为将大模型部署给单个用户的一种切实可行的解决方案。现有 PET 方法主要可分为三类:(i)仅更新模型中新增的参数或输入相关的参数(Houlsby et al., 2019;Li and Liang, 2021;Zhou et al., 2022);(ii)以稀疏方式仅更新模型中少量参数(Guo, Rush, and Kim, 2020;Zaken, Ravfogel, and Goldberg, 2021;Liu et al., 2024b);(iii)对需要更新的权重进行低秩分解(Hu et al., 2021;Karimi Mahabadi, Henderson, and Ruder, 2021;Hao et al., 2023)。然而,在计算机视觉领域,将 PET 应用于下游任务的研究主要集中在分类与生成任务上。如何高效更新并将预训练所学的知识空间迁移到密集预测任务中,仍然是一个重大挑战。一些开创性工作如 ETRIS(Xu et al., 2023)和 BarleRIa(Wang et al., 2023)尝试利用适配器(adapter)对 CLIP(Radford et al., 2021)进行微调以用于指代表达图像分割任务。但它们提出的模块(如 Bridger,Xu et al., 2023;GST,Wang et al., 2023)在捕获多尺度视觉特征的复杂性方面仍显不足。
指代表达图像分割(Referring Image Segmentation,RIS)旨在对由自然语言描述所指代的目标对象进行分割。这要求模型能够全面地关联多样的视觉内容与语言信号。Transformer 模型的出现推动了通过注意力机制在不同模态之间进行特征融合的范式变革(Yang et al., 2022;Liu, Ding, and Jiang, 2023a;Yan et al., 2023;Liu et al., 2023a)。其中,MDETR(Kamath et al., 2021)和 VLT(Ding et al., 2022)通过引入多模态注意力交互与查询表示,在多种视觉语言(Vision-Language, VL)任务上展现出卓越性能。受益于 CLIP 强大的图文对齐能力,CRIS(Wang et al., 2022)、ETRIS(Xu et al., 2023)以及 UniLSeg(Liu et al., 2023b)聚焦于句子—像素对齐,以充分挖掘丰富的多模态对应关系。然而,现有方法主要将重点放在解码阶段的视觉—语言交互设计上,忽视了对预训练骨干网络潜力的充分挖掘。为此,我们提出 DETRIS:一个借助参数高效模块对不同模态特征进行对齐的框架,从而促进骨干网络的多尺度、全面更新。与现有的全量微调方法相比,所提出的方法在显著降低训练计算开销的同时,仍能取得具有竞争力的性能。
3 Methodology
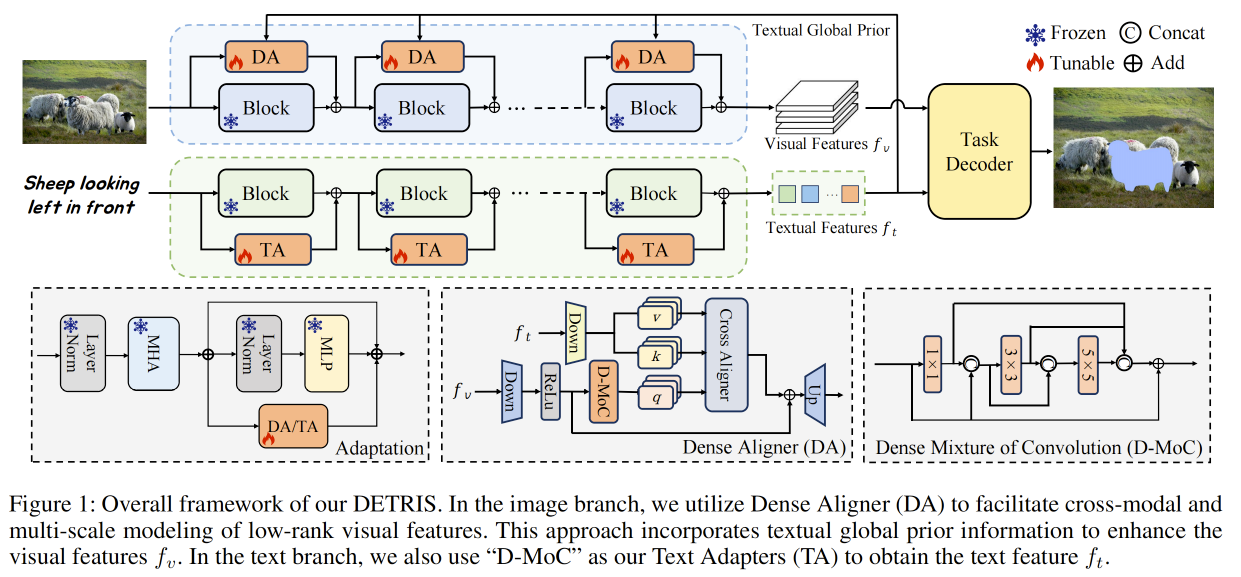
3.1 Framework Overview
所提出模型的整体框架如图 1 所示。我们的方法冻结预训练骨干网络的参数,以确保参数高效性。该模型的核心设计理念是 Dense Aligner:其旨在促进跨模态特征之间的交互,并将密集预测的先验信息注入到预训练骨干网络中。同时,我们在文本编码器中引入 文本适配器(text adapters),以增强更细粒度的图像—文本对齐能力。
3.2 Image & Text Feature Extraction
视觉编码器。 本工作采用带寄存器(registers)的蒸馏版 DINOv2(Oquab et al., 2023)作为骨干网络。该模型基于 ViT-B/14,并已在自监督训练任务上进行了充分预训练。具体而言,对于输入图像,我们使用加入 Dense Aligner 的 DINOv2 来提取图像特征。我们选取若干中间层以及最后一层的输出作为分层(层级化)的视觉特征
,用于后续的密集预测模块。
文本编码器。 对于输入的指代表达 (T),我们采用 CLIP(Radford et al., 2021)预训练的文本 Transformer 来提取文本特征。具体而言,我们使用加入文本适配器(text adapters)的 CLIP 文本编码器来提取词级文本特征 以及句子级特征
,以引导指代表达图像分割任务。
鉴于编码器所包含的参数量十分庞大,并且为了避免宝贵的预训练知识在微调过程中被削弱或遗忘,我们在微调阶段冻结编码器的全部参数,以实现参数高效的下游任务适配。
3.3 Local & Global Feature Interaction
如第 1 节所述,尽管 DINOv2 具备很强的泛化能力,并且在更依赖视觉能力的任务上相较于 CLIP 更具优势,但由于缺乏多模态预训练,DINOv2 在 RIS 下游任务中缺少视觉—文本对齐能力。为了解决这一问题并增强模型的多尺度建模能力,我们设计并引入 Dense Aligner 来增强视觉主干网络。训练过程中,视觉主干网络参数保持冻结,仅对 Dense Aligner 的参数进行训练。
Dense Aligner。 如图 1 所示,所提出的 Dense Aligner 与以往的适配器设计存在显著差异:我们在其中引入了稠密混合卷积模块(dense mixture of convolution modules)。此外,我们还在激活层与上投影(up-projection)层之间集成了一个交叉对齐模块(cross-aligner module)。这种设计增强了模型提取密集图像特征的能力,并提升了其多模态融合能力。
在稠密混合卷积模块中,我们采用一种多分支卷积结构,以在多尺度上有效建模低秩视觉特征并捕获多尺度先验信息。该模块依次进行线性投影与非线性激活,然后使用、
和
的卷积核,并逐步融合前序层的输出以实现渐进式集成。为保持高效并降低计算开销,我们在 (3\times3) 与 (5\times5) 卷积之前加入
卷积以压缩通道维度。


文本适配器(Text Adapter)。 鉴于 CLIP 文本编码器提取的文本特征与 DINO 的视觉特征之间存在差异,我们引入文本适配器来增强文本编码器,从而实现文本与视觉特征的细粒度对齐。与 Dense Aligner 类似,我们采用**稠密混合卷积(Dense mixture of Convolution, D-MoC)**作为文本适配器,以更好地捕获多尺度文本信息,并增强视觉与文本特征之间的对齐效果。然而,与使用二维卷积(2D convolutions)的 Dense Aligner 不同,我们的文本适配器采用专为文本序列处理设计的一维卷积(1D convolutions)。这种设计能够更有效地建模并整合文本特征,在优化序列文本表示的同时,使其与整体模型架构更好地兼容,从而提升对齐能力。
 3.4 The Referring Image Segmentation Head
3.4 The Referring Image Segmentation Head


3.5 Training Objective
遵循 CRIS(Wang et al., 2022)的做法,我们采用文本到视觉的对比学习损失(记为 (L_{\text{con}}))作为模型的训练目标,以优化由文本生成的特征与其对应视觉像素之间的对齐关系。该对比损失旨在同时实现两点:一方面强化文本特征与其对应视觉像素之间的关联;另一方面将这些文本特征与无关的视觉元素区分开来。文本到像素的对比损失可用如下数学形式表示:
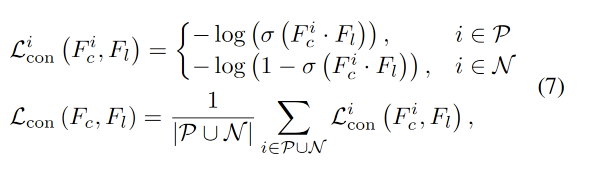
其中,(P) 和 (N) 分别表示真实标注(ground truth)中类别为 1 与类别为 0 的像素集合,(\sigma) 表示 Sigmoid 函数。因此,该损失会对特征之间的错误对齐进行惩罚,并鼓励模型将文本描述与其对应的视觉表征正确匹配起来。
4 Experiments
4.1 Datasets
我们在实验中采用了三个具有挑战性的指代表达图像分割(Referring Image Segmentation, RIS)基准数据集:
-
RefCOCO(Kazemzadeh et al., 2014)是指代表达图像分割领域最常用的基准之一。该数据集包含 19,994 张图像,为 50,000 个目标标注了 142,210 条指代表达,这些数据通过一个“双人游戏”机制从 MSCOCO 数据集中采集而来。数据集被划分为四个子集:120,624 个训练样本、10,834 个验证样本、5,657 个 test A 样本以及 5,095 个 test B 样本。表达的平均长度为 3.6 个单词,并且每张图像至少包含两个目标。
-
RefCOCO+(Kazemzadeh et al., 2014)包含 19,992 张图像中的 49,856 个目标,对应 141,564 条指代表达。数据集同样被划分为四个子集:120,624 个训练样本、10,758 个验证样本、5,726 个 test A 样本以及 4,889 个 test B 样本。值得注意的是,RefCOCO+ 通过剔除某些绝对位置词(absolute location words),使其相较于 RefCOCO 更具挑战性。
-
G-Ref(Yu et al., 2016)包含 26,711 张图像中的 54,822 个目标,对应 104,560 条指代表达。G-Ref 的表达由 Amazon Mechanical Turk 采集,平均长度为 8.4 个单词,通常包含更多与位置和外观相关的描述词。我们在 G-Ref 上同时报告 Google 与 UMD 两种划分方式下的实验结果。
4.2 Implementation Details

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)