别再整段Prompt缓存了:拆成稳定层+动态层,命中率轻松翻倍
大模型降本的关键在于合理拆分Prompt结构,而非简单开启缓存功能。应将上下文分为固定层(系统提示、工具说明)、半稳定层(业务规则、知识前缀)和动态层(实时数据、用户输入),仅缓存前两层。缓存键设计需包含模型版本、知识库哈希等元数据以确保准确性。随着多模型部署,缓存治理需统一接入层管理。147AI等工具可帮助标准化缓存策略,实现成本优化。核心原则是"先分层再缓存",通过结构化设
做大模型降本,很多人第一反应是“把 Prompt 缓一下”。
真到线上以后才发现,缓存不是开关题,而是结构题。
真正影响命中率和账单的,往往不是“缓存有没有开”,而是“上下文有没有拆开”。 这篇直接讲可落地做法,不绕概念。
为什么整段 Prompt 做缓存,效果通常一般
一个典型请求,往往长这样:
[system prompt]
[tool definitions]
[business rules]
[knowledge prefix]
[retrieved context]
[chat history]
[latest user question]
如果你把整段内容当成一个整体,希望它被稳定复用,现实里大概率不会太理想。
因为这段内容里,真正稳定的只是一部分:
system prompt往往几天都不改tool definitions相对稳定business rules常按版本更新knowledge_prefix可能按批次更新retrieved context和latest user question变化很快
后半段一变,整段复用价值就会明显下降。
2. 正确做法:按稳定程度拆三层
更适合工程落地的方式,是直接做上下文分层。
- 固定层:系统提示词、角色约束、工具说明、输出格式要求。
- 半稳定层:长期知识前缀、业务规则、版本化说明、更新不频繁的大段资料。
- 动态层:检索结果、会话尾部、用户最新输入、实时状态数据。
拆完以后,策略就会简单很多:
缓存固定层和半稳定层,动态层实时拼接。
一个最小可行的请求结构
如果你现在就要改代码,我更建议把请求先整理成这种结构:
{
"stable_context": {
"system": "...",
"tools": "...",
"knowledge_prefix": "..."
},
"dynamic_context": {
"retrieval": "...",
"chat_tail": "...",
"user_input": "..."
}
}
这样做的好处很直接:哪些内容值得缓存、哪些内容该实时拼,以及后续日志、命中率统计、成本归因都会更清楚。
主流模型的缓存能力,现在该怎么理解
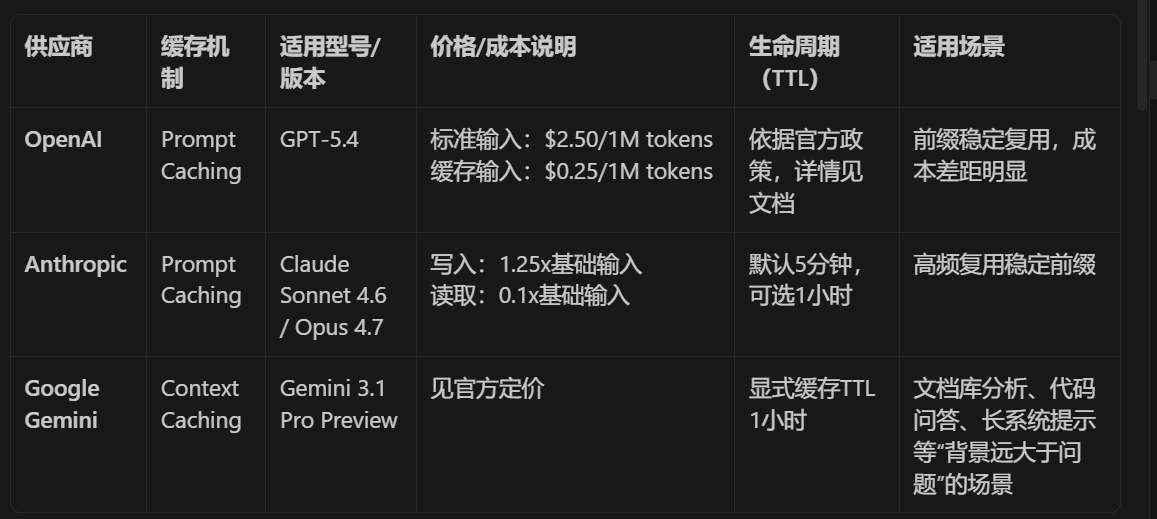
所以别把缓存理解成“所有内容都打折”, 它更像是在奖励你把重复前缀设计对。
缓存键怎么设计更稳
别只拿 prompt_text 当 key。
更稳一点的做法,是把缓存对象拆出来单独标识:
cache_key:
model: claude-sonnet-4-6
prompt_version: v2026-04-22
tools_version: tools-v3
knowledge_hash: kb_9f2a1c
locale: zh-CN
这样有两个直接好处:
- 规则变化后缓存能自然失效,不容易读到旧内容;
- 多模型环境里也更方便对账,知道到底是哪一层在省钱。
为什么缓存做到后面,会变成治理问题
单模型试验阶段,缓存看起来像一个 SDK 参数。
到了多模型线上阶段,它很快就不是了。你会马上碰到这些问题:
- OpenAI、Anthropic、Gemini 的缓存机制不同
- 命中率和成本日志分散在不同供应商
- 路由切换后,缓存收益需要重新算
- 哪段背景该缓存,会和哪类任务该走哪种模型绑在一起
这也是为什么,很多团队做到后面,都会把缓存策略放到统一接入层上治理。
147AI 在这里能解决什么
如果你本来就是多模型项目,147AI 的价值不只是“把模型接通”,而是让缓存这件事更容易标准化:
- 统一入口、
- 兼容 OpenAI 风格接口、
- 多模态纳入同一套治理体系、
- 日志与成本归因更便于统一观察。
再加上专线优化、人民币结算、按量计费,以及价格从官方定价一半起,
缓存优化带来的收益也更容易体现在真实账单上。
结尾
Prompt 缓存最怕的,不是不会配参数,而是没做上下文分层。
先拆层,再缓存;先管稳定背景,再研究动态内容。
这个顺序走对了,降本和提速才更像工程结果,而不是碰运气。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)