[AAAI2026]结合方向先验与空频联合域的医学图像分割解码器
在医学图像分割任务中,经典的 U-Net 及其衍生架构(如各种 Vision Transformer 变体)在全局上下文建模上已经取得了显著进展。然而,现有模型在处理极其微小的边缘细节、局部复杂纹理以及保持空间连续性时,依然存在瓶颈。特别是传统的跳跃连接(Skip Connections)往往采用简单的加法或拼接,容易将编码器中的背景噪声和冗余特征直接带入解码阶段。
在医学图像分割任务中,经典的 U-Net 及其衍生架构(如各种 Vision Transformer 变体)在全局上下文建模上已经取得了显著进展 。然而,现有模型在处理极其微小的边缘细节、局部复杂纹理以及保持空间连续性时,依然存在瓶颈 。特别是传统的跳跃连接(Skip Connections)往往采用简单的加法或拼接,容易将编码器中的背景噪声和冗余特征直接带入解码阶段 。
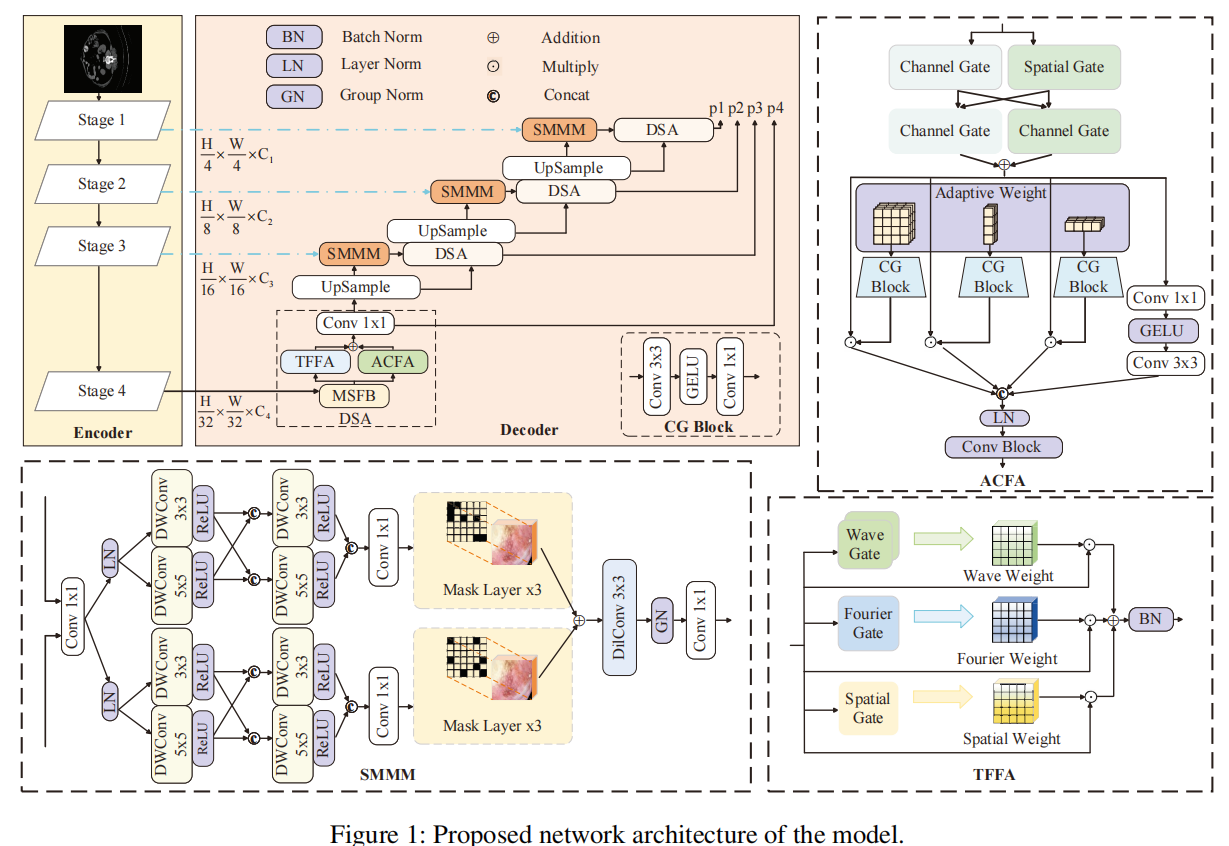
近期,发表于AAAI2026一篇题为《Decoding with Structured Awareness: Integrating Directional, Frequency-Spatial, and Structural Attention for Medical Image Segmentation》的工作提出了一种专为医学图像分割设计的新型解码器框架 。该架构并不依赖于简单堆砌 Transformer 模块,而是巧妙地引入了方向先验与**空频联合域(Spatial-Frequency Domain)**的特征调制 。
本文将深入拆解该解码器的三大核心模块(ACFA、TFFA、SMMM),并针对其底层数学逻辑与网络设计直觉进行解析。
1.研究背景
尽管视觉 Transformer (ViT) 通过自注意力机制在捕获长距离依赖方面表现出色,但它们在医疗图像中往往难以精细地建模细粒度纹理和边缘细节 。典的 U-Net 架构依赖跳跃连接(Skip Connections)来融合多尺度特征,但通常采用简单的加法或拼接操作 。这种粗糙的融合容易导致空间细节的丢失,并混入大量冗余背景信息,难以平衡全局与局部特征 。
论文的创新点非常明确,即提出了一种专为医学图像分割量身定制的新型解码器框架,试图在保持全局感知的同时,极致强化对边缘和结构细节的表达 。该框架由三大模块串联组成:
ACFA (自适应交叉融合注意力): 一种方向感知模块,强化模型对关键区域和结构朝向的响应 。
TFFA (三重特征融合注意力): 极其大胆地将空间域、傅里叶域和小波域特征进行联合表达,在保留边缘纹理的同时强化全局依赖 。
SMMM (结构感知多尺度掩码模块): 用于优化编码器和解码器之间的跳跃连接,通过显著性过滤来减少特征冗余 。
整个网络遵循经典的 Encoder-Decoder 架构 。作者没有从头训练编码器,而是直接采用在 ImageNet 上预训练的 PVTv2-b2 作为视觉特征提取器 。解码器的精髓全在于其定制化的三个核心组件:ACFA、TFFA 和 SMMM
2.核心模块详细解读
核心模块1: ACFA方向感知与特征调制的底层逻辑
为了强化模型对病灶特定边界和结构朝向的敏感度,作者提出了**自适应交叉融合注意力(ACFA)**模块 。该模块的核心在于“双重门控”与“定向张量提取”。
1. 双重门控(Dual Gating) 输入特征首先会经历通道门控和空间门控的初步提纯 :
通道维度代表了模型提取到的不同语义概念。平均池化和最大池化将二维空间信息压缩为标量,目的是在剥离空间干扰后,评估“哪些通道的语义对当前任务更重要”,从而实现全局通道权重的重分配。
空间门控的目的是生成一个二维权重图,告诉网络“哪些像素区域是病灶”。7×77\times77×7 提供了比常规 3×33\times33×3 更广阔的上下文感受野,有助于在二维平面上更平滑、准确地描绘病灶轮廓 。
2. 定向可学习张量:巧妙的几何约束 提纯后的特征在通道维度被等分为四份,其中三份分别与三个由均匀分布初始化的可学习张量(代表平面、垂直、水平方向)结合 。 这里一个刚看论文容易困惑的点:这三个张量凭什么能代表方向? 答案在于作者对其张量形状(Shape)的强制压缩配合特定的卷积维度 :
垂直张量 TensorHTensor^{H}TensorH:形状被定义为 1×C4×H×11 \times \frac{C}{4} \times H \times 11×4C×H×1。其宽度被强制压缩为 1,本质上是一个列向量。配合一维卷积 f3DWConv1df_{3}^{DWConv1d}f3DWConv1d,卷积核只能沿着高度(Y轴)滑动,迫使该分支只能学习垂直方向的像素梯度变化 。
水平张量 TensorWTensor^{W}TensorW:形状为 1×C4×1×W1 \times \frac{C}{4} \times 1 \times W1×4C×1×W。高度被压缩为 1,成为行向量。一维卷积只能沿宽度(X轴)滑动,从而对水平横向边缘极度敏感 。
平面张量 TensorHWTensor^{HW}TensorHW:形状为 1×C4×H×W1 \times \frac{C}{4} \times H \times W1×4C×H×W,保留完整二维结构,配合二维卷积提取各向同性的全局纹理 。
作者在这里的设计意图其实非常清晰,就是借鉴了 Coordinate Attention (坐标注意力) 的思想,利用张量形状的极限压缩(变成 H×1H\times1H×1 和 1×W1\times W1×W)配合广播机制,强制特征图具备“横向”和“纵向”的感知先验。
探讨: 仔细阅读论文公式 (6)、(7)、(8) 会发现,公式中直接对张量进行了卷积,遗漏了输入特征图的参与 。从网络结构图与工程实现逻辑推断,这里的真实关系应是基于广播机制的元素级乘法(Element-wise Multiplication)。以垂直张量为例,形状为 (H,1)(H, 1)(H,1) 的权重图在与形状为 (H,W)(H, W)(H,W) 的输入特征相乘时,会在 WWW 维度上触发广播(复制 WWW 份)。这意味着特征图同一行被施加相同的权重,从而强制特征图聚焦于沿 Y 轴变化的纵向结构。
核心模块2: TFFA空间、傅里叶与小波的“跨维度联合”
常规的空间卷积感受野受限,容易导致边缘平滑 。TFFA 模块极其大胆地将特征映射到三个不同的数学域,并在最后通过注意力门控进行动态权重分配融合 。
1. 空间域分支:像素级锚点 该分支仅使用 1×11\times11×1 逐点卷积提取特征 。由于后续的傅里叶和小波分支会剧烈改变特征的空间表达模式,这里的 1×11\times11×1 卷积完全不与空间邻域交互,旨在保留最原始、未被扭曲的像素级绝对位置信息,充当常规空间特征的“基底”。
2. 傅里叶分支:频率域的全局调制
傅里叶变换将图像转换到频率域,中心代表低频(轮廓),四周代表高频(边缘) 。模型使用一组可学习的权重矩阵与频率图进行按位相乘(即调制) 。在频率域中,矩阵上的任意一个点都包含了整张图像该频率的正弦波全局分布信息。因此,权重矩阵对某个频率点的放大或缩小,实际上是在全局视野下强化或抑制特定的周期性结构,从而有效弥补了卷积长距离依赖建模的不足 。
3. 小波分支:动态自适应显微镜。该分支并行引入了两种经典的连续小波函数进行多尺度频空分析 :
DoG(高斯差分):本质是一个带通滤波器,强调特定频段的细节 。其公式为:
ψa,bDog(x)=−1a(x−ba)e−(x−ba)22\psi_{a,b}^{Dog}(x)=-\frac{1}{\sqrt{a}}(\frac{x-b}{a})e^{-\frac{(\frac{x-b}{a})^{2}}{2}}ψa,bDog(x)=−a1(ax−b)e−2(ax−b)2 。
Mexican Hat(墨西哥帽小波):公式为 :
ψa,bMH(x)=23aπ14(1−(x−ba)2)e−(x−ba)22\psi_{a,b}^{MH}(x)=\frac{2}{\sqrt{3a}\pi^{\frac{1}{4}}}(1-(\frac{x-b}{a})^{2})e^{-\frac{(\frac{x-b}{a})^{2}}{2}}ψa,bMH(x)=3aπ412(1−(ax−b)2)e−2(ax−b)2 。
之所以选择 Mexican Hat 而非传统的 Haar 小波,是因为医学图像的病灶边缘往往是平缓过渡的软边界。Mexican Hat 通过平滑后求二阶导数寻找边缘过零点,其平缓振荡的形态不仅能有效抑制医学噪声,也更契合病灶灰度的衰减模式 。
公式中的 aaa 为尺度参数(控制小波变宽或变窄,即感受野大小),bbb 为平移参数(控制滤波器空间中心) 。作者将两者设定为可学习参数,意味着网络可以在训练中自动寻找最匹配当前病灶尺寸的感受野,并微调滤波器中心使其精准对齐边界 。
核心模块3:SMMM针对跳跃连接的结构感知掩码
为了防止编码器中的背景噪声直接流入解码器,SMMM 在跳跃连接处设计了一个“智能过滤器” 。
1. 1×11\times11×1 卷积的通道对齐 来自编码器和解码器的特征由于语义深度不同,首先通过平行的 1×11\times11×1 卷积处理 。这起到了“通道对齐”的作用,将处于不同语义空间的特征投影到共享的特征维度上,并激活隐藏在通道深处的空间线索。
2. 显著性掩码(Saliency Masking)的生成 随后,特征通过 3×33\times33×3 和 5×55\times55×5 深度可分离卷积扩大感受野 。接着,模块使用三种不同的通道门控滤波器提取特征,并通过 Softmax 激活函数进行归一化处理 。这就计算出了一个介于 [0,1][0, 1][0,1] 之间的空间显著性权重图。将该掩码乘回原特征,即可强迫网络只保留高响应的病灶区域,抑制背景冗余 。
3. 尾部的空洞卷积强化 过滤相加后的特征,最后穿过一个空洞率(Dilation Rate)为 2 的空洞卷积 。在跳跃连接的末端,前序的掩码过滤可能导致特征碎片化;引入空洞卷积可以在不压缩特征图分辨率的前提下,成倍扩大感受野,将局部的边界信息重新织回全局上下文中,极大提升对复杂几何边界的捕捉能力 。
3.实验结果
作者在一个固定编码器(ImageNet 预训练的 PVTv2-b2)的配合下进行了验证 :
Synapse (多器官): 平均 DSC 达到 83.92%,在脾脏 (92.46%)、右肾 (86.47%) 和左肾 (89.26%) 等边界复杂的器官上取得了最佳表现 。
ISIC 2017 & 2018 (皮肤病变): DSC 分别达到 91.40% 和 90.71%,优于众多对比模型(如 EMCAD, LKA 等)。
ACDC (心脏): 平均 DSC 达到 92.75% 。
4.批判性分析
这篇文章在“频空联合”的切入点上绝对令人眼前一亮,但有几个细节值得探讨:
1、baseline缺失,在医学图像分割领域(尤其是 Synapse 和 ACDC 这类经典数据集),nnU-Net 已经是公认的、必须对比的行业标杆。论文对比了大量的 Transformer 模型(TransUNet, Swin-Unet, EMCAD 等),却通篇未提 nnU-Net。那模型在与极致优化的纯 CNN 架构对比时是否真的具有优势?
2、论文在公式 (12) 中声称 DoG 和 Mexican Hat 小波的尺度参数 aaa 和平移参数 bbb 是“可学习的 (learnable)”。但在离散的特征张量上,如何对经典的连续小波函数求导并进行反向传播?这种可学习机制在 PyTorch 中具体是如何实现的?计算开销有多大?论文对此只字未提。
3、论文在 Table 8 中声称完整模型(包含 TFFA)的计算复杂度仅为 18.29 GMac 。然而,快速傅里叶变换 (FFT) 在深度学习框架中的实际推理速度极度受限于显存带宽和张量重排(Memory bound),GMac 指标无法反映其真正的延迟开销。除了理论计算量(GMac)和参数量(Params),增加实际环境下的吞吐量(Frames Per Second, FPS)或单张图像的推理时间对比很有必要。
4、ACFA 模块中用于方向引导的 Tensor 竟然使用的是 [0,1][0,1][0,1] 之间的均匀分布初始化 f[0,1]Uniformf_{[0,1]}^{Uniform}f[0,1]Uniform 。对于这种旨在捕获深层结构特征的敏感参数,为何采用如此随意的初始化方式?是否有数学直觉支撑?
5.小结
这篇论文巧妙地利用信号处理理论(小波+傅里叶)赋能了深度解码器,结构设计非常漂亮。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)