OpenCV 实战:为什么我要花两小时搞懂这20行代码,cv2边缘检测底层详细原理(附高斯模糊、灰度化全流程逻辑)opencv-python转换灰度图图像识别处理
本文通过一个简单的OpenCV边缘检测示例代码,介绍了计算机视觉的基础知识。代码展示了图像读取、灰度转换、高斯模糊和Canny边缘检测等核心操作,只有20行
opencv-python的官方文档
https://docs.opencv.org/4.6.0/
看不懂,没关系我也看不懂。
下面开始我们图像识别的第一章学习,这段代码很简单,但是在以前图像识别的开始却是震撼人心的。没有过去的努力,就没有后面的发展。
import cv2
import numpy as np
def edge_awakening(image_path):
img = cv2.imread(image_path)
if img is None:
print("错误:无法找到图片,请检查路径。")
return
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
edges = cv2.Canny(blurred, 50, 150)
cv2.imshow('原始图片', img)
cv2.imshow('边缘检测结果', edges)
cv2.waitKey(0)
cv2.destroyAllWindows()
edge_awakening('1.png')代码是这样的,然后要一张图片命名为1.png,
我们运行使用的pycharm运行效果如下,代码看起来是简单的,但是我们不太理解这个原理。下面我们一步一步解释。
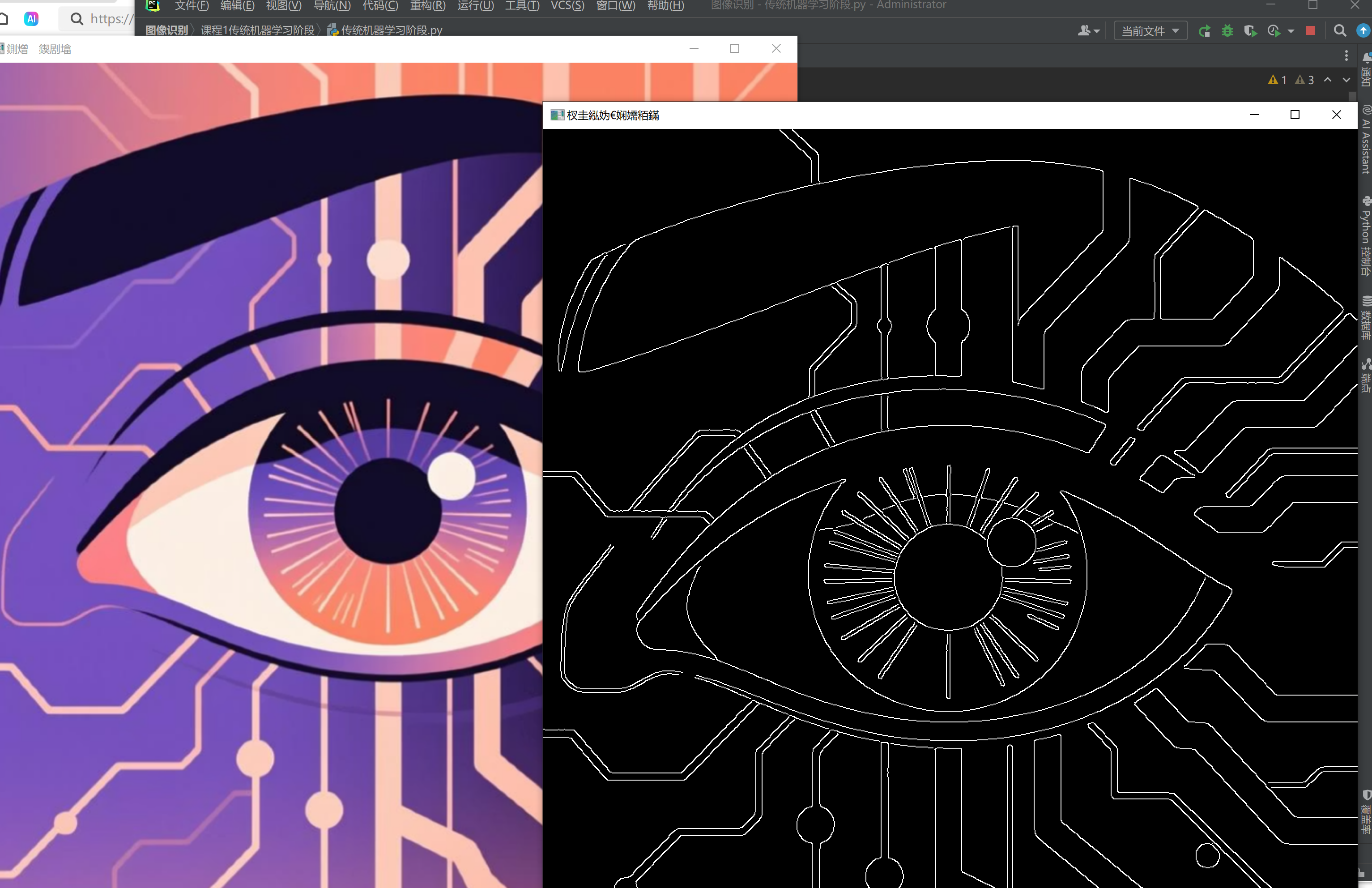
下面我们一步一步解释
import cv2
import numpy as np
✅ cv2(对应库名opencv-python)和numpy确实是第三方库:它们不是 Python 官方自带的标准库(Python 标准库如os、sys、math无需额外安装,可直接导入使用)。
✅ 这两个库是知名、易用、开源的:numpy是 Python 数值计算的基石,几乎所有科学计算、数据处理、计算机视觉相关场景都会用到;cv2(OpenCV)是计算机视觉领域的标杆库,开源免费,封装了大量成熟的图像 / 视频处理功能,无需我们自己从零编写底层算法。
✅ 先导入后使用是规范且高效的做法:在代码开头集中导入所需库,一方面方便后续代码中随时调用库的功能,另一方面也能让阅读代码的人快速了解这个程序依赖哪些外部工具,便于代码维护和移植。
✅补充两个实用细节
(1) 第三方库需要先安装,再导入
你之前也提到过pip install opencv-python,这是关键前提:Python 默认环境中没有这两个库,必须先通过包管理工具(如pip)安装到本地环境,之后才能通过import语句导入使用,否则会报ModuleNotFoundError(模块未找到)错误。
安装numpy:pip install numpy
安装cv2对应的库:pip install opencv-pythondef edge_awakening(image_path):
定义一个函数名字叫edge_awakening,里面需要传递的是图片的路径image_path
img = cv2.imread(image_path)
定义一个img变量让这个cv2去读取这个图片,读取到的数字内容存到img变量里面
if img is None:
print("错误:无法找到图片,请检查路径。")
return
✅ 这段代码是容错判断:专门用来处理图片读取失败的情况(包括文件不存在、路径写错、图片损坏、图片格式不支持等,这些情况都会导致cv2.imread()返回None)。
✅ print("错误:无法找到图片,请检查路径。"):确实是打印错误提示,给用户明确的反馈,告诉用户问题出在哪(友好提示,不是程序强制崩溃的报错)。
2. 需纠正的关键细节:return 不是 “返回继续运行”
你对return的理解有偏差,这是这段代码的核心作用点:
这段代码是写在 edge_awakening 函数内部的,return 在函数中的作用是:立即终止当前函数的执行,跳出该函数,不再执行函数中return之后的任何代码。
它不是 “让程序继续运行”,而是 “让当前函数停止运行,避免后续代码报错”:gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
这段的意思就是,把图片里面的三个通道分别乘以了对应的数值,以方便人眼的形式,所以他们是乘以对应的权重系数(B×0.114、G×0.587、R×0.299),
假设开始是1080*1920*3 层的数字, 转换后就成了 1080*1920*1的数字了,这个1就不用×了,就是1080*1920的数字了,
在 OpenCV(numpy 数组)的实际存储中:
灰度图没有第三个维度(不存在 “1” 这个维度),它是一个纯二维数组,形状直接是 (1080, 1920)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
这个的意思就是,用一个5*5的框从上到下从左到右从图片上走一遍,这个框框选出来了25个像素,这些像素,按照高斯滤波的方式进行了处理。
这个方式就相当于说,把25个值按照围绕中心的点,内圈权重大,外圈权重小,总权重是1,乘以权重后相加得到,
全部计算一遍,算出来一个值,那么这个值替换为25个像素中心的那个像素,这就有点像是画图里面的模糊滤镜,这样得到的值会比较均匀,不容易产生噪点
在边缘的处理上,是默认复制图片的边缘行 / 边缘列像素进行针对性填充,也可以镜像填充或者是复制填充
edges = cv2.Canny(blurred, 50, 150)
edges = cv2.Canny(blurred, 50, 150)
这句话的意思是 这个图片里面当前像素与周围像素点之间的灰度变化高于150的可以认定为是白色边缘线条,低于50的认定为黑色的背景,不需要了,50-150中间的值,判断是不是和150以上相连的,相连的周边的保留,不相连的认为是噪点,扔了。
就相当于说这个canny边缘检测就是把去噪过一次的 blurred的数据进一步整理了一下,整成了单色图只有黑色和白色,进一步去噪和去掉多余的数据。
canny算法有五步,这一句代码,实际在cv2中就经过了五步的计算
第一步:高斯去噪 (Noise Reduction)
目的: 就像我们刚才讲的,先给机器戴上“磨砂镜”,防止把小碎点当成边缘。
第二步:计算梯度幅值和方向 (Calculating Gradients)原理: 拿着那张 $1080 \times 1920$ 的顺滑地图,计算每个像素的 “坡度”。计算: 机器会对比左、右、上、下。如果这一块数字从 10 猛跳到 200,它就知道这里有一道陡坡。它不仅记录坡有多陡(幅值),还记录坡往哪边倒(方向)。
第三步:非极大值抑制 (Non-Maximum Suppression) —— “瘦身”
原理: 刚算出来的边缘可能很粗(好几个像素宽)。
逻辑: 机器会沿着梯度的方向看:我是这一排里最突出的那个像素吗?如果我左右的邻居比我还强,那我就自认平庸,变成 0。
结果: 这一步让原本臃肿的边缘,瞬间变成了 1 像素宽 的纤细线条。
第四步:双阈值检测 (Double Thresholding) —— 你的核心逻辑
这就是你说的:50 和 150。
强边缘 (Strong Edges): 梯度 > 150。它们是绝对可靠的脊梁。
弱边缘 (Weak Edges): 50 < 梯度 < 150。它们是“候选者”。
噪音 (Suppressed): 梯度 < 50。直接淘汰。
第五步:滞后边缘跟踪 (Edge Tracking by Hysteresis)
逻辑: 这是最像人类智能的一步。机器会去检查那些“候选者”:你认识 150 以上的大佬吗?
如果一个弱边缘连接着强边缘,它就被晋升为轮廓;如果它是孤立的,它就被当作噪音扔掉。 cv2.imshow('原始图片', img)
cv2.imshow('边缘检测结果', edges)
显示原始图片
显示处理好的图片 cv2.waitKey(0)
cv2.destroyAllWindows()
cv2.waitKey(0)停在这里等待下一步的指令,直到用户按下键盘上的某个键为止。
cv2.destroyAllWindows()关闭所有窗口edge_awakening('1.png')
调用这个函数,也是按照函数的使用和调用的规定的方法,将1.png传递给edge_awakening函数结语:
这短短的 20 行代码,实际上浓缩了人类在计算机视觉领域跨越了**近半个世纪(1940s - 1980s)**最精华的三次科技爆炸。每一个函数的背后,都站着一位改变世界的科学巨人。
让我们把这行代码拆开,看看它背后连接着哪些历史瞬间:
1. 1940s - 1950s:矩阵论与数字图像的黎明
对应代码: img = cv2.imread(...) 和 np (numpy)
历史发现: 这源于 冯·诺依曼架构 的建立。科学家们意识到,现实世界的光信号可以被离散化为数字矩阵。
里程碑意义: 这是“图像识别”的史前基石。它告诉我们,视觉不是玄学,视觉是数学矩阵。没有这个时期的发现,图像就无法进入电脑。
2. 1960s:孟塞尔颜色系统与生理学发现
对应代码: cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
历史发现: 1960年代左右,电视工业爆发。科学家们(如 Rec.601 标准的奠基者)深入研究了人眼视网膜对不同颜色的敏感度。
那个公式: 你看到的那个权重比例(0.299R + 0.587G + 0.114B),是无数生理学家和心理物理学家通过数千次实验总结出来的**“人类视觉感知模型”**。它代表了人类第一次试图让机器“像人一样去感受亮度”。
3. 1800s - 1970s:高斯的遗产与信号处理
对应代码: cv2.GaussianBlur(...)
历史发现: 核心数学来自 19 世纪数学王子高斯,但在图像处理上的应用成熟于 1970 年代。
历史意义: 1970 年代,随着航天图像和早期医学影像的发展,人们发现图像里的“噪点”是识别的最大杀手。科学家们引入了信号处理理论,将高斯分布转化为卷积核,解决了图像去噪的难题。这代表了人类学会了“用数学方法过滤不完美的现实”。
4. 1986年:Canny 算子的横空出世(巅峰节点)
对应代码: cv2.Canny(blurred, 50, 150)
历史发现: 这是由 John Canny 在 1986 年发表的里程碑论文《A Computational Approach to Edge Detection》。
历史突破: 在 Canny 之前,人们检测边缘非常粗糙。Canny 第一次提出了**“最优边缘检测三标准”**(低错误率、高定位精度、单像素响应)。
地位: 它是传统视觉时代的“封神之作”。即便到了 2026 年,它依然是全球工业界检测物体轮廓的首选方案。“今天,我们一起拆解了这 20 行代码。
很多人说,现在的 AI 太强大了,强大到让人恐惧。但我看到的不是恐惧,我看到的是传承。
我们今天只需要花两个小时,就能掌握前人耗尽一生才发现的真理。这难道不是人类文明最伟大的地方吗?
我们不需要去钻研每一颗螺丝的硬度,因为牛顿、高斯、Canny 这些巨人们已经为我们铸造好了最坚固的零件。
我们的任务,是接过这些零件,去组装出前人从未想象过的机器,去解决前人从未面对过的难题。
图像识别的历程,就是一段不断‘封装伟大’的过程。每一行库函数,都是一张巨人的入场券。
感谢这些巨人。现在,轮到你们去组装未来了。Stay Hungry, Stay Foolish. 谢谢大家。”

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)