Go + PostgreSQL 搞定向量存储:手把手实现RAG 基础引擎
RAG 这个技术在这几年的热度都一直非常不错,到目前为止 RAG 应该算是开发 AI 应用的必备技能了
最近一直在看 AI 相关的内容, RAG 这个技术在这几年的热度都一直非常不错,到目前为止 RAG 应该算是开发 AI 应用的必备技能了,刚好上篇文章都提到使用 sqlc + goose 来开发应用,所以趁这个机会把调用 embeeding 模型把文本转换成向量使用 sqlc 来存储到 pgvector 并且召回这个最基础的 RAG 功能的代码自己动手实现一遍。
什么是 RAG?
RAG 的全称是 检索增强生成。
是一种将 信息检索 与 大语言模型生成 相结合的先进技术架构。
大模型的知识内容只停留在训练使用的数据,对于一些新的数据或者用户独有的数据并不了解,这个时候 RAG 就派上用场了。
它解决了大模型的知识时效性和专有数据访问两大难题。
假设一个场景,比如我需要让 AI 知道我的公众号叫什么名字,我可以把我自己的公众号信息做成一个文档,然后把这个文档直接放到和 AI 对话的上下文当中,这样 AI 就了解了我的微信公众号的信息并且能够结合这些信息来回答我的问题。
开发实践
本篇文章是 AI 开发最基础的入门代码示例测试。
所有涉及到的技术有 docker/docker-compose、go、sqlc、goose、postgresql + pgvector 插件以及 azure 的 openai 相关模型的 API(这个可以使用国内的模型也行)。
最终的代码示例都放在我的 github 仓库:
https://github.com/DimplesY/sqlc_pgvector
环境准备
sqlc 和 goose 这两个工具的安装可以去看之前的文章,这里我直接贴出 pgvector 的 docker-compose 文件让我们能够快速的在本地启动数据库。
compose.yaml 文件如下:
services:
pgvector:
image: pgvector/pgvector:pg16
container_name: pgvector
restart: unless-stopped
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=db
- TZ=Asia/Shanghai
ports:
- "5432:5432"
volumes:
- $PWD/docker/postgres/db/:/var/lib/postgresql/
.env 文件如下:
GOOSE_DRIVER=postgres
GOOSE_DBSTRING=postgres://postgres:postgres@localhost:5432/db
GOOSE_MIGRATION_DIR=./sql/schema
AZURE_OPENAI_ENDPOINT=
AZURE_OPENAI_API_VERSION=
AZURE_OPENAI_API_KEY=
使用 sqlc init 命令来初始化我们的项目配置,修改内容如下所示:
version: "2"
sql:
- engine: "postgresql"
queries: "./sql/queries"
schema: "./sql/schema"
gen:
go:
package: "database"
out: "./internal/db"
sql_package: "pgx/v5"
emit_json_tags: true
emit_prepared_queries: true
创建数据库
这里我把知识库相关的内容都定义到一个名为 document 的表当中,使用 goose create create_document_table sql。
-- +goose Up
-- +goose StatementBegin
CREATE EXTENSION IF NOT EXISTS vector; -- 启用 vector 拓展
CREATE TABLE document (
id SERIAL PRIMARY KEY,
title VARCHAR(255) NOT NULL, -- 文档标题
content TEXT, -- 文档内容
embedding VECTOR(3072), -- 向量
metadata JSON, -- 元信息
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP, -- 创建时间
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP -- 更新时间
);
-- +goose StatementEnd
-- +goose Down
-- +goose StatementBegin
DROP TABLE document;
-- +goose StatementEnd
需要注意的地方是必须要在 +goose up 的代码块当中启用 vector 的 PostgreSQL 的拓展,要不然数据库迁移会失败。
编写创建和召回的 SQL
-- name: CreateDocument :one
INSERT INTO document (title, content, embedding, metadata)
VALUES ($1, $2, $3, $4)
RETURNING id, title, content, embedding, metadata, created_at, updated_at;
-- name: SearchSimilarDocuments :many
SELECT
id,
title,
content,
embedding,
metadata,
created_at,
updated_at,
(1 - (embedding <=> $1)) as similarity_score
FROM document
ORDER BY embedding <=> $1
LIMIT $2;
上面的 sql 当中包含两个方法,一个是用来创建 document 文档,一个是用来根据向量进行数据召回,这里我只编写了一个使用最常用的余弦相似度方法来进行向量相似度的查询。
代码实践
从将文本使用 embedding model 嵌入到数据库字段当中,然后使用我们编写的 sql 方法进行向量匹配查询。
package main
import (
"context"
"encoding/json"
"fmt"
"log"
"os"
database "github.com/dimplesY/sqlc_pgvector/internal/db"
"github.com/jackc/pgx/v5"
"github.com/jackc/pgx/v5/pgtype"
"github.com/joho/godotenv"
"github.com/openai/openai-go/v3"
"github.com/openai/openai-go/v3/azure"
"github.com/pgvector/pgvector-go"
)
type EmbeddingClient struct {
Endpoint string
APIVersion string
APIKey string
PGVectorURL string
}
func (o *EmbeddingClient) Load() error {
err := godotenv.Load()
if err != nil {
return err
}
o.Endpoint = os.Getenv("AZURE_OPENAI_ENDPOINT")
o.APIVersion = os.Getenv("AZURE_OPENAI_API_VERSION")
o.APIKey = os.Getenv("AZURE_OPENAI_API_KEY")
o.PGVectorURL = os.Getenv("GOOSE_DBSTRING")
return nil
}
func (o *EmbeddingClient) NewClient() openai.Client {
return openai.NewClient(
azure.WithEndpoint(o.Endpoint, o.APIVersion),
azure.WithAPIKey(o.APIKey),
)
}
func main() {
ctx := context.Background()
var embeddingClient EmbeddingClient
err := embeddingClient.Load()
if err != nil {
log.Fatal("Error loading .env file")
}
client := embeddingClient.NewClient()
text := "测试文本"
metadata := map[string]string{
"source": "test",
}
embedding, err := client.Embeddings.New(ctx, openai.EmbeddingNewParams{
Input: openai.EmbeddingNewParamsInputUnion{
OfString: openai.String(text),
},
Model: "text-embedding-3-large",
EncodingFormat: openai.EmbeddingNewParamsEncodingFormatFloat,
})
fmt.Printf("embedding: %+v\n", len(embedding.Data[0].Embedding))
if err != nil {
panic(err)
}
conn, err := pgx.Connect(ctx, embeddingClient.PGVectorURL)
if err != nil {
panic(err)
}
queries := database.New(conn)
defer conn.Close(ctx)
// embedding 响应的数据类型默认是 float64,pgvector 类型要求 float 32
// float64 -> float32
embeddingFloat32 := make([]float32, len(embedding.Data[0].Embedding))
for i, v := range embedding.Data[0].Embedding {
embeddingFloat32[i] = float32(v)
}
metadataJSON, err := json.Marshal(metadata)
if err != nil {
panic(err)
}
document, err := queries.CreateDocument(ctx, database.CreateDocumentParams{
Title: text,
Content: pgtype.Text{
String: text,
Valid: true,
},
Embedding: pgvector.NewVector(embeddingFloat32),
Metadata: metadataJSON,
})
if err != nil {
panic(err)
}
fmt.Printf("document: %+v\n", document.Content)
similarDocuments, err := queries.SearchSimilarDocuments(ctx, database.SearchSimilarDocumentsParams{
Embedding: pgvector.NewVector(embeddingFloat32),
Limit: 10,
})
if err != nil {
panic(err)
}
for _, document := range similarDocuments {
fmt.Printf("similar document: %+v\n", document.Content)
}
}
使用 go run main.go 来运行代码,可以看到能够正确的在数据库当中搜索到前面嵌入到数据库当中的内容。
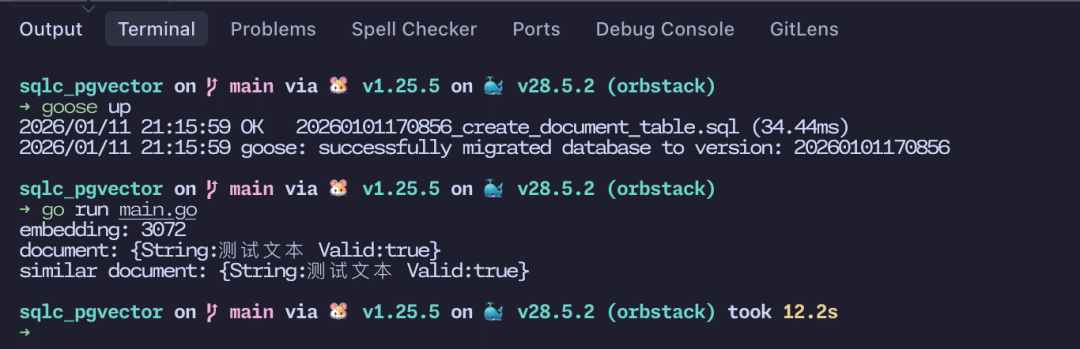
到这里我们自己实现了 AI 应用开发最基础的一个步骤,向量存储和召回,上面的代码当中主要是做测试使用,使用到大量的 panic,生产环境请替换成更佳优雅的处理方式。
想入门 AI 大模型却找不到清晰方向?备考大厂 AI 岗还在四处搜集零散资料?别再浪费时间啦!2025 年 AI 大模型全套学习资料已整理完毕,从学习路线到面试真题,从工具教程到行业报告,一站式覆盖你的所有需求,现在全部免费分享!
👇👇扫码免费领取全部内容👇👇

一、学习必备:100+本大模型电子书+26 份行业报告 + 600+ 套技术PPT,帮你看透 AI 趋势
想了解大模型的行业动态、商业落地案例?大模型电子书?这份资料帮你站在 “行业高度” 学 AI:
1. 100+本大模型方向电子书

2. 26 份行业研究报告:覆盖多领域实践与趋势
报告包含阿里、DeepSeek 等权威机构发布的核心内容,涵盖:
- 职业趋势:《AI + 职业趋势报告》《中国 AI 人才粮仓模型解析》;
- 商业落地:《生成式 AI 商业落地白皮书》《AI Agent 应用落地技术白皮书》;
- 领域细分:《AGI 在金融领域的应用报告》《AI GC 实践案例集》;
- 行业监测:《2024 年中国大模型季度监测报告》《2025 年中国技术市场发展趋势》。
3. 600+套技术大会 PPT:听行业大咖讲实战
PPT 整理自 2024-2025 年热门技术大会,包含百度、腾讯、字节等企业的一线实践:

- 安全方向:《端侧大模型的安全建设》《大模型驱动安全升级(腾讯代码安全实践)》;
- 产品与创新:《大模型产品如何创新与创收》《AI 时代的新范式:构建 AI 产品》;
- 多模态与 Agent:《Step-Video 开源模型(视频生成进展)》《Agentic RAG 的现在与未来》;
- 工程落地:《从原型到生产:AgentOps 加速字节 AI 应用落地》《智能代码助手 CodeFuse 的架构设计》。
二、求职必看:大厂 AI 岗面试 “弹药库”,300 + 真题 + 107 道面经直接抱走
想冲字节、腾讯、阿里、蔚来等大厂 AI 岗?这份面试资料帮你提前 “押题”,拒绝临场慌!

1. 107 道大厂面经:覆盖 Prompt、RAG、大模型应用工程师等热门岗位
面经整理自 2021-2025 年真实面试场景,包含 TPlink、字节、腾讯、蔚来、虾皮、中兴、科大讯飞、京东等企业的高频考题,每道题都附带思路解析:

2. 102 道 AI 大模型真题:直击大模型核心考点
针对大模型专属考题,从概念到实践全面覆盖,帮你理清底层逻辑:

3. 97 道 LLMs 真题:聚焦大型语言模型高频问题
专门拆解 LLMs 的核心痛点与解决方案,比如让很多人头疼的 “复读机问题”:

三、路线必明: AI 大模型学习路线图,1 张图理清核心内容
刚接触 AI 大模型,不知道该从哪学起?这份「AI大模型 学习路线图」直接帮你划重点,不用再盲目摸索!

路线图涵盖 5 大核心板块,从基础到进阶层层递进:一步步带你从入门到进阶,从理论到实战。

L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。

L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。

L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。

L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

L5阶段:专题集丨特训篇 【录播课】

四、资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇
2025 年想抓住 AI 大模型的风口?别犹豫,这份免费资料就是你的 “起跑线”!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)