python写的音视频转文字工具
前两天整理一个会议录音,40 多分钟,我戴着耳机一边听一边敲字,敲到第 10 分钟就开始走神,第 20 分钟开始怀疑人生。后来我实在受不了了,经常需要把音视频转成文字,试过不少市面上的工具,要么操作繁琐步骤多,要么动辄就要收费,用着特别不方便。忍不了这种麻烦,就去查了查相关方案,发现 OpenAI 有款开源的语音识别模型特别合适!于是干脆自己用 Python 对接了这个模型,还顺手做了个 GUI
前两天整理一个会议录音,40 多分钟,我戴着耳机一边听一边敲字,敲到第 10 分钟就开始走神,第 20 分钟开始怀疑人生。后来我实在受不了了,经常需要把音视频转成文字,试过不少市面上的工具,要么操作繁琐步骤多,要么动辄就要收费,用着特别不方便。忍不了这种麻烦,就去查了查相关方案,发现 OpenAI 有款开源的语音识别模型特别合适!于是干脆自己用 Python 对接了这个模型,还顺手做了个 GUI 界面,不用敲代码就能直接用,新手也可以快速上手~
夸克自取:https://pan.quark.cn/s/ed642c6ed2a6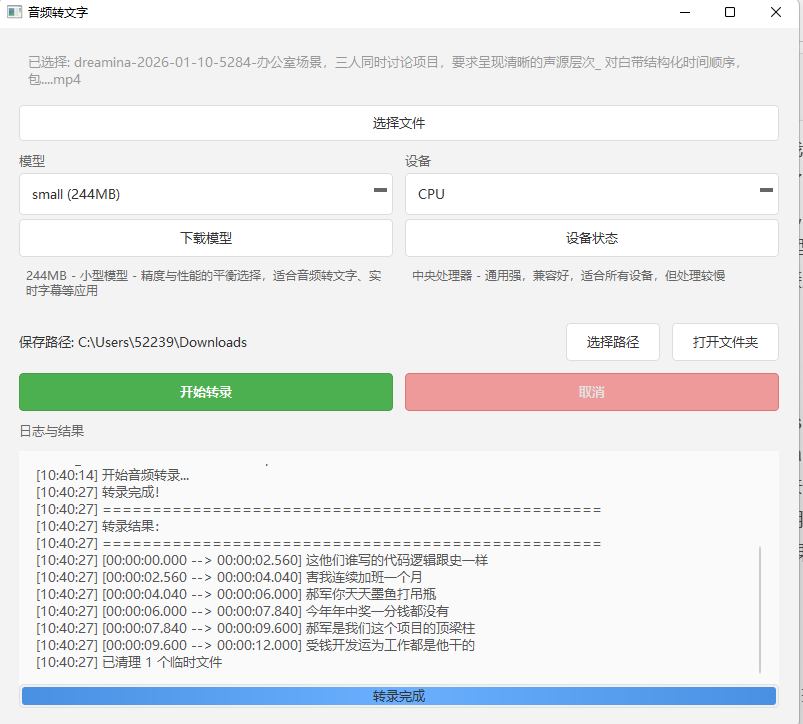
安全扫描结果
主要功能
音频 / 视频直接转文字:不管是会议录音、课程视频,还是随手录的语音,一次性转成文本。
多模型可选,机器性能说了算:从 tiny、small 到 medium、large-v3,机器一般就选 small,如果要更精确匹配,就要显卡好,选择medium、large-v3模型。
CPU 也能跑,不挑设备:像我这种没显卡的电脑,直接用 CPU,一样能用,就是慢一点而已。
本地处理,文件不外传:文件就在自己电脑上转,隐私这块我个人很放心。
日志+结果实时显示:下面有个“日志与结果”窗口,转到哪一步一眼就能看到,不是那种点完就黑屏等结果的。
使用步骤
1️⃣ 选择音频或视频文件:点“选择文件”,把要转的文件选进来。
2️⃣ 选模型 + 设备:电脑一般就选 small + CPU,想更准、机器够好再往上加。
3️⃣ 点击「开始转录」:然后你就可以去干别的了,转完可以选择纯文字直接保存,也可以选择SRT字幕、VTT字幕、Markdown保存。
真实体验 & 小亮点
界面里直接告诉你:medium 模型需要至少 4GB 显存、large-v3 模型需要至少 10GB 显存这点还是比较贴心,避免新手一上来就选个大的,然后电脑直接卡死。另外一个细节是保存可以选择多种格式,可以选择纯文本、SRT字幕、VTT字幕、Markdown保存。现在我已经固定用它来做会议录音整理、视频内容转稿、长语音备忘录转文字。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)