大数据引擎深入对比:Kylin、Druid与Clickhouse的优劣解析
大数据引擎简介
在大数据分析领域,不同的场景对于引擎的要求也不尽相同。KYLIN、DRUID、CLICKHOUSE作为当前备受瞩目的OLAP引擎,各自拥有独特的数据模型和索引结构,因此在性能和适用性上各有千秋。

在您深入探索本文之前,建议先对这三大引擎的基本概念和功能有所了解。
▣ KYLIN数据模型
Kylin的核心数据模型在于其将传统的二维表(如Hive表)经过处理,Cube化并存储到HBase数据库中。这一过程涉及两次关键转换。首次转换主要是将数据Cube化,这些Cube由唯一的CuboId进行标识。在Kylin中,每个节点都代表一个CuboId,它表示特定列的数据集合,例如,“A”和“B”两个维度所组成的CuboId的数据集合,其等价于一条SQL查询语句所返回的数据集合。
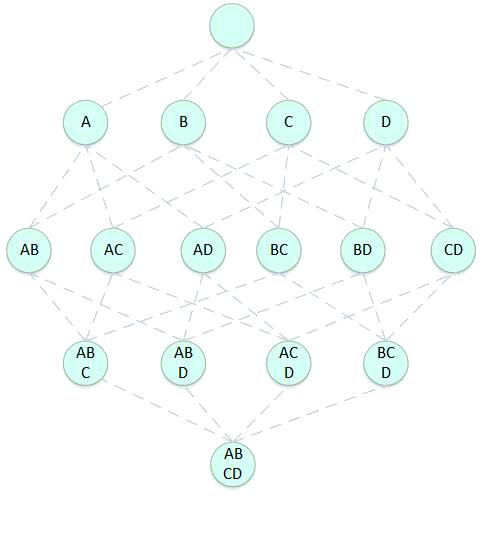
第二次转换则是将处理后的Cube数据存储至HBase数据库中。在此过程中,CuboId及维度信息被序列化至rowkey,而度量列则构成列簇。值得一提的是,数据在转换时已经进行了预聚合处理。
▣ KYLIN索引结构
由于Kylin将数据存入HBase,因此Kylin的数据索引实质上就是HBase的索引。HBase所采用的索引结构为简化的B+树,与传统的B+树不同,HFile并不涉及对数据文件的更新操作。
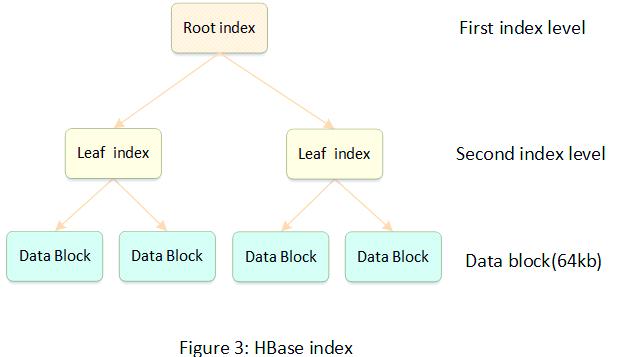
HFile的索引是依据rowkey进行排序的聚簇式索引,其索引树通常构建为二层或三层结构。与MySQL的B+树相比,HBase的索引节点尺寸更大,默认设置为64KB。在数据检索过程中,系统会利用树形结构迅速定位到特定节点,而节点内部的数据则依照rowkey有序排列,从而可以通过高效的二分查找法快速锁定目标数据。
▣ KYLIN小结
Kylin在聚合查询场景中表现出色,得益于数据预聚合技术,它能够迅速处理复杂的查询,如group-by查询,甚至可能只需扫描一条数据。然而,Kylin的查询效率会受到是否命中CuboId的影响,因此查询结果会有所波动。另一方面,HBase的索引结构与MySQL中的联合索引有些相似,其中维度在rowkey中的排序以及查询维度的组合对查询效率产生显著影响。因此,在构建Kylin表时,需要业务专家的参与以确保最佳的性能。
02DRUID引擎分析
▣ DRUID数据模型
Druid的数据模型同样注重预聚合,但其预聚合方式与Kylin有所不同。Kylin采用Cube化技术进行预聚合,而Druid则选择将所有维度进行Group-by操作。这种差异化的预聚合策略,使得两者在处理数据时各有千秋。
▣ DRUID索引结构
Druid的索引结构独具特色,它采用了一种自定义的数据结构,整体上呈现出列式存储的特点。在Druid中,每一列都拥有一个独立的逻辑文件。特别地,维度列被精心设计了索引,这些索引以 Bitmap 为核心,旨在提高查询效率。
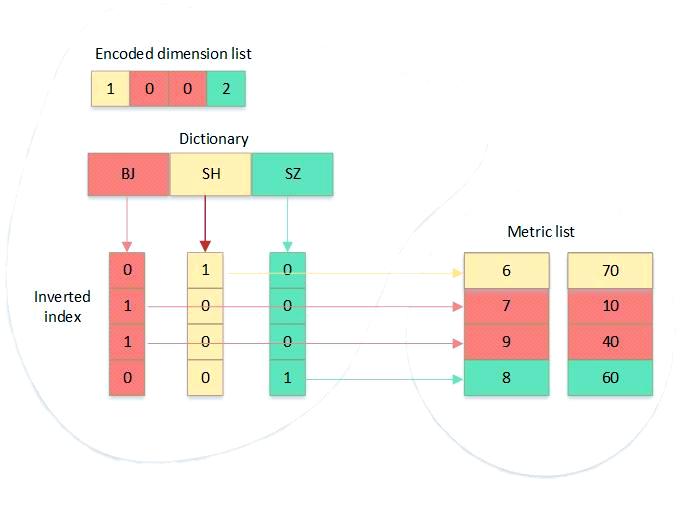
通过一个具体例子,“city”列的索引结构可见一斑。首先,该列的所有唯一值会被排序并生成一个字典。接着,针对每个唯一值,都会创建一个长度为数据集总行数的Bitmap。在这个Bitmap中,每个bit都代表对应行数据是否等于该唯一值。由于Bitmap的下标位置与行号一一对应,因此它可以被用来定位到度量列,即反向索引。
▣ DRUID小结
Druid在聚合查询场景下表现优异,但可能不适用于超高基维度的场景。它存储了全维度group-by后的数据,这类似于只存储了KYLIN Cube的Base-CuboID。由于每个维度都创建了索引,因此每个查询都能迅速完成,且查询效率相对稳定,没有像KYLIN那样的巨大波动。
03CLICKHOUSE索引结构与性能
▣ CLICKHOUSE索引结构
由于 Clickhouse 的数据模型本质上是一种二维表,我们在此主要探讨其索引结构。Clickhouse也采用了列式索引设计,即每个数据列都对应一个独立的文件。其索引策略主要包括以下步骤:
首先,系统会挑选部分列作为索引列,并确保整个数据文件中的数据都是按照这些索引列进行有序排列的,这种设计类似于MySQL中的联合索引概念。
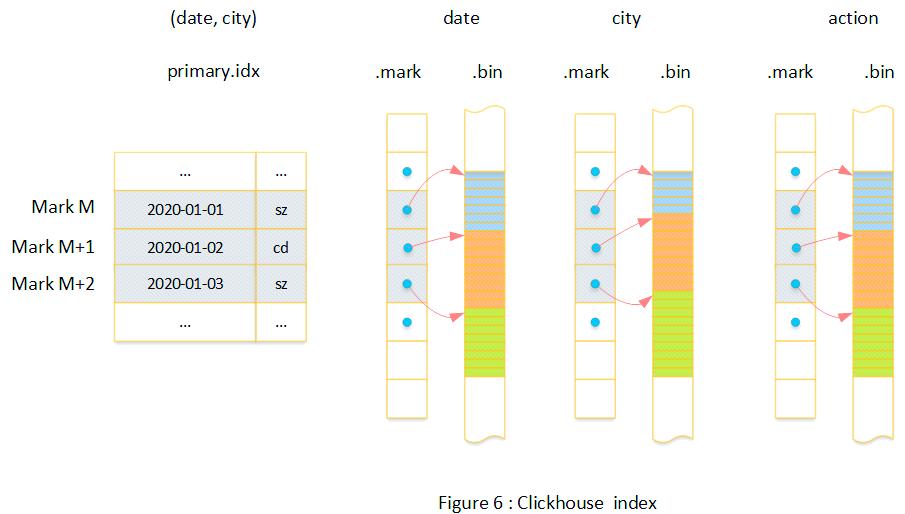
值得注意的是,这里的序号并非传统的行号,而是从零开始并持续递增的数字,Clickhouse 中将其称为 Mark’s number。
▣ CLICKHOUSE性能
虽然KYLIN和DRUID主要适用于聚合场景,但Clickhouse在多种场景下表现出色。在聚合场景下,其查询效率甚至超过了KYLIN和DRUID。然而,无论是KYLIN还是Clickhouse,建表过程都需要业务专家的深入参与,以确保查询效率的最大化。
此外,Clickhouse的索引策略在某些方面与MySQL的联合索引相似。当查询条件能够命中索引的前缀元组时,其查询效率会达到最高。但一旦查询条件无法命中前缀元组,那么系统可能不得不扫描整个表来获取数据,此时查询效率会显著下降。因此,在构建Clickhouse表时,业务专家的参与显得尤为重要。
综上所述,虽然KYLIN和DRUID主要适用于聚合场景,但Clickhouse在明细和聚合场景下都表现优异。在聚合场景下,其查询效率甚至超过了KYLIN和DRUID。然而,无论是KYLIN还是Clickhouse,建表过程都需要业务专家的深入参与,以确保查询效率的最大化。
同时,这种工具的查询效率可能受到多种因素的影响,因此在具体使用时需要仔细考虑和优化。在向量化处理方面,Clickhouse展现出了卓越的性能,而DRUID仅在少数算子中支持向量化,KYLIN则目前尚不支持向量化计算。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)