工业时序数据治理新选择:TDengine 引领国产数据库的实战路径
对于工业企业而言,技术选型的核心在于平衡 “短期切换成本” 与 “长期数字化收益”—— 实践证明,选择深度适配工业场景的国产时序数据库,是推动企业数字化转型的关键战略决策。某省级电力公司实践显示,采用国产化时序数据库后,数据主权可控性评分从 62 分提升至 91 分(满分 100)。某能源集团实测显示,存储 1 亿条光伏逆变器数据时,TDengine 平均查询响应时间(230ms)较 Influx
工业制造领域正经历前所未有的数据爆发。根据工信部《2024 年工业互联网产业发展报告》,单个智能工厂日均数据量已从 2019 年的 TB 级攀升至 2024 年的 PB 级,其中 90% 以上为设备传感器与控制系统产生的时序数据。以电力行业为例,特高压变电站单台变压器每秒可生成超 2000 条运行数据,区域电网年数据增量突破 50PB;汽车制造行业中,单条智能产线 300 余台机器人日均产生日志数据超 80TB。
这一增长由三大驱动力共同推动:一是工业物联网(IIoT)终端普及,全球工业传感器装机量已突破 500 亿;二是智能制造对实时监控需求升级,从设备状态监测延伸至全流程质量追溯;三是 AI 算法在预测性维护中的广泛应用,要求长期保留历史数据用于模型训练。
时序数据高写入、高查询及复杂生命周期管理的特性,使传统数据库方案难以满足需求。例如,某汽车焊装车间采用 MySQL 存储机器人运行数据,当数据量超过 5000 万条后,单表查询延迟从毫秒级飙升至秒级,且无法承载 1000 + 并发写入。相比之下,时序数据库通过时间序列优化存储(如时间分片)、列式压缩(压缩率可达 10:1)及预计算聚合等技术,天然适配工业场景。
在工业应用中,时序数据库的核心价值体现在:
- 实时处理:支持毫秒级写入与复杂聚合查询,满足设备实时监控需求;
- 历史回溯:高效存储多年历史数据,为工艺优化与故障分析提供支撑;
- 降本增效:通过生命周期管理自动清理无效数据,显著降低存储成本。
自 2023 年《数据安全法》修订后,关键信息基础设施的数据处理需严格遵循 “安全可控” 原则。在电力、轨道交通等领域,外资数据库采购审批通过率较 2020 年下降 60%。国产时序数据库不仅满足合规要求,更具备场景深度适配能力:如 TDengine 针对电力行业 “四遥” 数据(遥测、遥信、遥控、遥调)开发专用数据模型,而国际通用型产品需额外适配开发。
从产业生态看,国产数据库已形成从芯片到应用的完整链条。TDengine 通过与华为鲲鹏、飞腾芯片的兼容性认证,可部署于全国产化服务器集群,有效规避国际供应链风险。某省级电力公司实践显示,采用国产化时序数据库后,数据主权可控性评分从 62 分提升至 91 分(满分 100)。
- 关系型数据库(MySQL/PostgreSQL)
- 存储效率低:行式存储导致时序数据压缩率仅 2:1-3:1,某化工厂使用 MySQL 存储 3 年数据后,存储成本超出预期 4 倍;
- 写入性能差:事务机制引发高并发场景下的锁等待,某风电场在风机满发时,MySQL 写入失败率达 15%;
- 查询效率低:缺乏原生时间索引,设备 3 个月运行趋势查询需全表扫描,耗时超 10 秒。
- 文档型数据库(MongoDB)
- 聚合能力弱:虽支持 JSON 存储,但复杂时间窗口计算(如滑动平均)需客户端二次处理,增加网络开销;
- 扩展性不足:分片机制对时序数据适配性差,某智能制造园区扩展至 10 个分片后,数据均衡耗时长达 8 小时。
- 通用大数据平台(HBase/Spark)
- 运维复杂:需部署 ZooKeeper、HDFS 等组件,某汽车工厂 HBase 集群需 3 名专职运维人员,年人力成本超 60 万元;
- 实时性差:批处理架构导致查询延迟通常在秒级以上,无法满足设备实时告警需求。
以 TDengine 为代表的时序数据库通过四大核心技术实现突破:
- 原生时序数据模型:以设备 ID、测点、时间作为三维主键,贴合工业数据结构,减少 30% 的 JOIN 操作;
- 列存 + 分区技术:自动按时间分区存储,某光伏电站逆变器数据压缩率达 15:1,存储成本降低 87%;
- 预计算引擎:自动生成分钟 / 小时级聚合结果,某电网调度系统负荷预测查询速度从 5 秒降至 300 毫秒;
- 边缘 - 云端协同架构:边缘节点预聚合后同步至云端,某轨道交通集团带宽消耗减少 60%。
这些技术带来显著业务价值:某整车厂引入 TDengine 后,设备故障检出率从 82% 提升至 99%,停机时间缩短 35%;某新能源电站运维成本降低 28%,数据延迟导致的发电损失减少 90%。
- 数据迁移复杂度:从 MySQL 迁移至 TDengine 需处理 schema 转换与历史数据清洗,某食品加工厂迁移 1.2TB 数据耗时 56 小时,期间需双系统并行;
- 应用适配成本:API 接口差异(SQL+REST vs 原生时序 API)导致代码改造,某智能制造平台 200 + 查询接口改造耗时 3 人周;
- 人才储备缺口:时序数据库运维需掌握时间窗口优化、分区策略等新技能,某电子代工厂人均培训成本约 2 万元。
- 初期性能调优:默认配置可能无法匹配业务需求,某钢铁厂因未优化压缩算法,初期存储效率仅达预期 60%;
- 生态兼容性:部分工业软件(如 SCADA 系统)仅支持 Oracle 接口,某化工厂集成适配成本增加 15 万元;
- 长期维护成本:版本升级可能引发兼容性问题,TDengine 从 2.x 升级至 3.x 时,某电力用户因自定义函数不兼容,修复耗时 2 天。
- 分阶段迁移:优先在非核心业务(如设备离线分析)试点,某汽车零部件厂采用此策略将风险降低 70%;
- 构建双写机制:过渡期内同时写入新旧系统确保数据一致性,某风电场双写方案运行 3 个月后平稳切换;
- 选择原厂服务:TDengine 迁移工具可自动化完成 80% 转换工作,专业团队可缩短 50% 迁移周期。
- 从 MySQL 迁移至 TDengine:某省级电网配电自动化系统迁移后,存储容量从 12TB 降至 1.5TB(压缩率 8:1),单终端历史查询速度提升 12 倍,年运维成本减少 42 万元。
- 从 MongoDB 迁移至 TDengine:某智能机床设备云平台切换后,写入成功率从 92% 提升至 99.99%,仪表盘加载时间从 3 秒降至 400ms,支持设备数从 5000 台扩展至 2 万台。
- 从 InfluxDB 迁移至 TDengine:某锂电池工厂产线监控系统迁移后,集群扩容时间从小时级缩短至分钟级,跨时间聚合查询速度提升 8 倍,年 License 成本降低 60%。
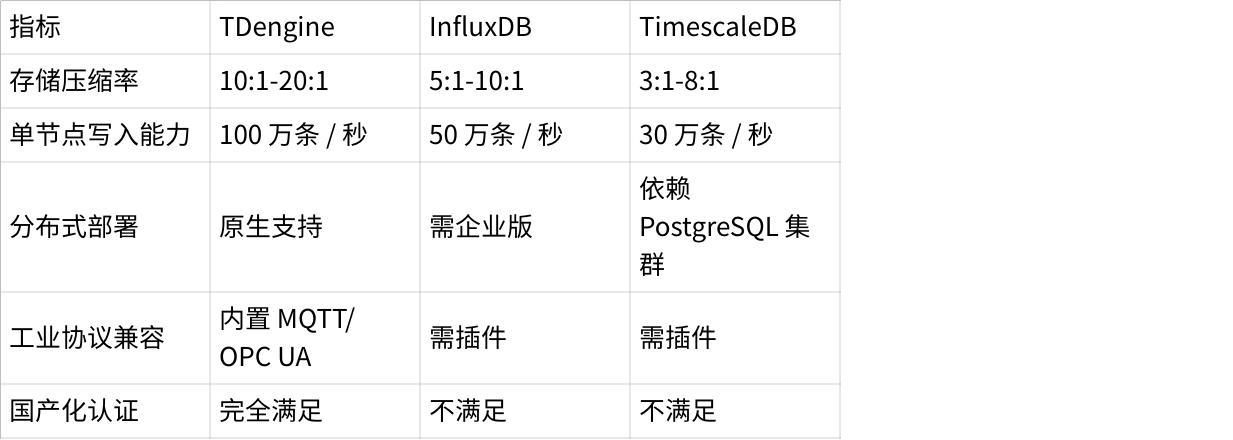
点击图片可查看完整电子表格
某能源集团实测显示,存储 1 亿条光伏逆变器数据时,TDengine 平均查询响应时间(230ms)较 InfluxDB(890ms)快 3 倍,较 TimescaleDB(1.2s)快 5 倍。
- 场景匹配度:电力行业关注 “四遥” 数据处理能力,智能制造侧重产线数据聚合效率,TDengine 行业数据包可快速验证适配性;
- 成本测算:3 年周期内,TDengine 总拥有成本(TCO)较国际厂商低 40%-60%,主要节省于存储硬件与 License 费用;
- 服务响应:选择具备本地化技术团队的厂商,TDengine 在全国 12 城设技术支持中心,平均故障响应 < 4 小时;
- 长期演进:TDengine 近两年发布 15 个版本,持续新增边缘计算、AI 集成等功能,技术迭代远超部分国际竞品。
在工业数字化转型的关键阶段,时序数据库已从技术选项转变为核心基础设施。TDengine 等国产时序数据库凭借技术创新与场景深耕,不仅突破传统方案的性能瓶颈,更在数据安全与成本控制上建立显著优势。对于工业企业而言,技术选型的核心在于平衡 “短期切换成本” 与 “长期数字化收益”—— 实践证明,选择深度适配工业场景的国产时序数据库,是推动企业数字化转型的关键战略决策。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)