FDL如何重构数据链路?FDL能否打破系统壁垒?
大家好,今天我以实操经验分享的视角,用直白、朴素、干货满满的方式,给各位零基础、刚接触数据工作的朋友讲清楚:FineDataLink 到底怎么重构数据链路,能不能真正解决企业里系统不通、数据孤岛的问题。全文只讲可落地的技术逻辑与使用方法。
在此之前,先给大家送上一份数据资料包:https://s.fanruan.com/pxb9h,里面包含FineDataLink 基础配置说明、支持数据源清单、标准任务模板,适合新手快速熟悉参数设置与规范流程,避免前期配置出错影响项目进度。当前企业数字化推进过程中,数据孤岛一直是核心阻碍。不同业务系统数据标准不一致、接口不兼容,数据流转慢、对账困难、数据不一致的情况十分常见。今天我们要讲的FineDataLink,简称FDL,是帆软推出的专业数据集成平台,它的核心价值不是简单搬运数据,而是搭建标准化、自动化、可视化的企业级数据链路,从底层解决数据不通、流程不规范的问题。
我一直强调,数据集成项目出问题,很多时候不是工具不行,而是前期基础没打牢、参数不标准、流程不统一。接下来我从技术逻辑、功能实现、规范治理三个方向,把 FineDataLink 的工作机制讲透彻,让小白也能看懂、能理解、能用上。
一、FineDataLink 的技术架构如何实现多源异构数据整合?
FineDataLink 能够适配企业复杂数据环境,核心原因是底层采用插件化驱动管理机制与统一元数据映射模型。传统数据集成需要针对不同数据库写不同适配代码,维护成本高、扩展困难;而 FineDataLink 通过内置标准化驱动与专用连接器,把各类数据源统一抽象为标准数据对象。
具体来说,FineDataLink 支持关系型数据库,包括 Oracle、MySQL、SQL Server、PostgreSQL 等,也支持 Hive、ClickHouse、Doris 等大数据组件,同时支持 RESTful API、文件等多种数据形式。用户在 FineDataLink 界面配置数据源时,系统会自动加载对应驱动插件,建立物理连接,全程屏蔽底层数据库方言差异。
例如分页查询、字段读取等操作,FineDataLink 会根据目标数据库类型自动转换为对应语法,不需要人工修改代码。这种统一接入能力,让无论多么复杂的上游系统,进入 FineDataLink 处理引擎后都变成统一规范的数据格式,为后续清洗、转换提供稳定基础。
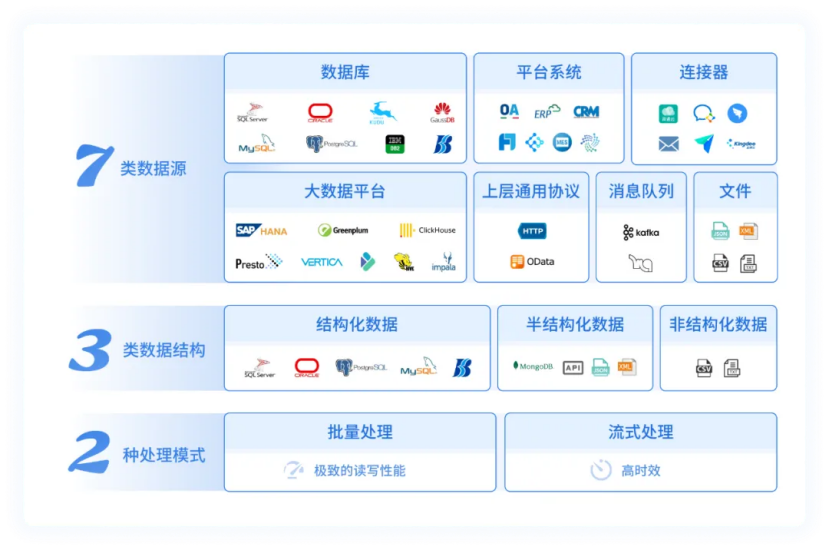
说白了,FineDataLink 做的第一件事,就是把所有异构数据 “标准化”,让不同系统、不同库、不同接口的数据,在同一套规则下进入处理流程。你懂我意思吗?源头统一了,后面的数据处理才不会乱。
二、FineDataLink 的任务调度逻辑与数据同步机制解析
数据接入完成后,最重要的就是稳定、准确、高效地完成同步。FineDataLink 的任务调度基于有向无环图(DAG)工作流引擎,用户配置数据同步任务,本质是搭建包含抽取、转换、加载的完整逻辑链条。
FineDataLink 提供多种数据同步模式,适应不同业务场景。全量同步适用于数据初始化或小量表场景。系统会读取源表全部数据,经过缓冲区处理后写入目标端,并支持事务控制,保证写入要么全部成功,要么全部回滚,确保数据一致性。
增量同步是企业日常最常用模式,FineDataLink 支持三种增量识别方式:时间戳字段、自增主键字段、日志解析(CDC)。基于时间戳与自增 ID 的方式,配置简单、资源消耗低,只需记录上一次同步位置,下次只同步新增数据;日志解析方式更底层,直接读取数据库事务日志,捕获增删改操作,可实现秒级延迟,不占用源库查询资源,适合核心业务高实时场景。
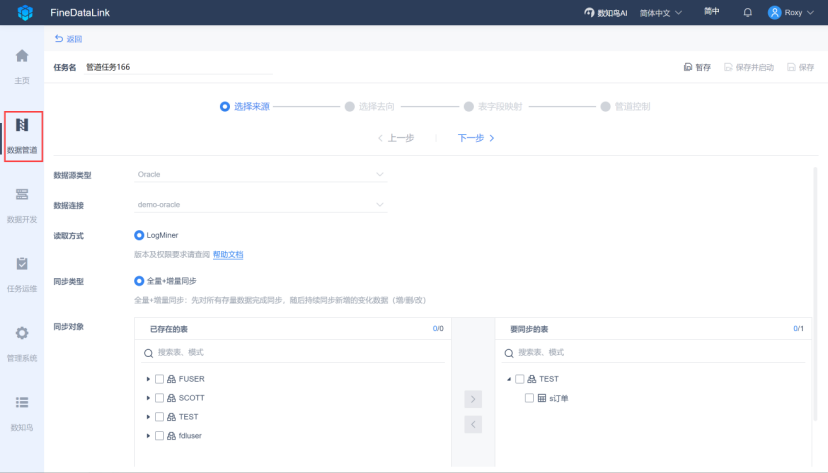
任务执行过程中,FineDataLink 具备断点续传与错误重试机制。网络波动导致任务中断时,系统会自动记录数据位点,重启后从断点继续执行,不需要从头开始。单条数据因类型不匹配、约束冲突写入失败时,可设置错误容忍度,异常数据单独存入日志表,不影响整体任务运行。

听着是不是很熟?以前手动脚本一旦中断就要重新跑,现在 FineDataLink 把这些稳定性问题全部自动化解决。
在实际操作中,如果你需要查看任务节点配置、流程搭建方式,可以免费体验:https://s.fanruan.com/ysq87,里面包含任务流完整配置步骤,能帮你快速建立直观操作认知。我一直建议新手:理论看再多,不如看一遍真实配置流程。
三、FineDataLink 如何重构企业整体数据链路?
数据链路混乱,本质是接入、处理、输出三段不贯通、不标准、不可控。FineDataLink 从流程层面重构整条数据链路,让数据从源头到输出形成闭环。
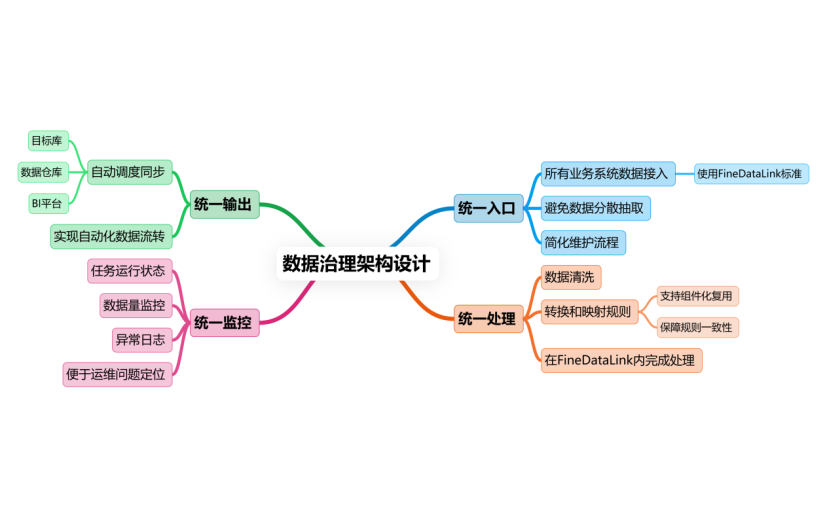
用过来人的经验告诉你,企业数据问题 90% 来自链路不规范:有人这样抽、有人那样取、有人手工改、有人脚本跑。FineDataLink 把整个链路固定化、标准化,从工具层面杜绝混乱。
简单来说,FineDataLink 重构数据链路,就是把人工、零散、不可控的数据搬运方式,替换成系统、自动、可追溯的一体化流程。
四、FineDataLink 能否打破企业系统壁垒?
这是企业最关心的问题,答案非常明确:FineDataLink 能够有效打破系统壁垒,实现跨系统数据互通。
- FineDataLink 通过统一连接器屏蔽底层协议差异,财务、ERP、CRM、MES 等独立系统不需要改造,即可完成数据对接,解决物理层面不通的问题。
- FineDataLink 统一数据标准与字段口径,让同样的字段在不同系统中含义一致、格式一致,解决逻辑层面不通的问题。
- FineDataLink 支持跨网段、混合云部署,通过代理节点实现内网与外网、本地与云端的数据安全互通,解决环境层面不通的问题。
很多企业系统壁垒并不是硬件无法连接,而是数据标准乱、处理规则不统一、权限不清晰。FineDataLink 通过元数据管理、数据血缘追踪、统一清洗规则,让数据在各系统之间可流转、可对比、可共用。我一直强调,打破系统壁垒不是 “把系统连起来” 这么简单,而是让数据能够规范、安全、准确地流动,FineDataLink 正是从这一点出发,真正实现跨系统数据融合。
五、FineDataLink 在企业数据治理中的规范化作用
除了连通与同步,FineDataLink 在数据治理中起到关键的规范化作用。
- 数据血缘可追溯。FineDataLink 记录每个字段的来源、转换规则、目标表,出现数据异常可快速反向追踪,定位问题环节。
- 数据处理规则统一。企业可将常用清洗逻辑封装为标准组件,多任务复用,确保全公司数据处理逻辑唯一。
- 权限管理精细化。FineDataLink 支持对数据源、任务、字段设置细粒度权限,开发、运维、管理员职责分离,降低人为误操作风险。
数据治理不是口号,而是靠流程与工具落地。FineDataLink 把治理要求嵌入数据链路每一步,让数据标准真正执行下去。
六、FineDataLink 常见问题 Q&A
Q1:FineDataLink 在同步亿级数据时,会不会影响源业务库的运行速度?
A:不会。FineDataLink 采用分片读取、并发控制、速率限制技术。大表可按主键分片,多线程并发读取,同时支持限制查询速率和批次大小,精确控制对源库 CPU、IO 的占用,保证业务系统稳定运行。
Q2:如果源表结构发生变化,比如加字段、删字段,FineDataLink 任务会不会直接失败?
A:加字段不会导致任务失败,未映射的新字段不会同步;删除任务依赖的字段会报错停止。FineDataLink 支持元数据一键刷新,可快速重新映射字段,适配表结构变更。
Q3:FineDataLink 只能在内部局域网使用吗?跨网络、混合云环境能不能用?
A:可以。FineDataLink 支持跨网段与混合云部署,提供数据代理节点机制,代理节点与服务端建立加密通道,传输使用 SSL/TLS 加密,同时支持 IP 白名单与最小权限配置,保证跨网络数据安全。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)