基于声纹识别与声纹特征提取的智能语音识别技术
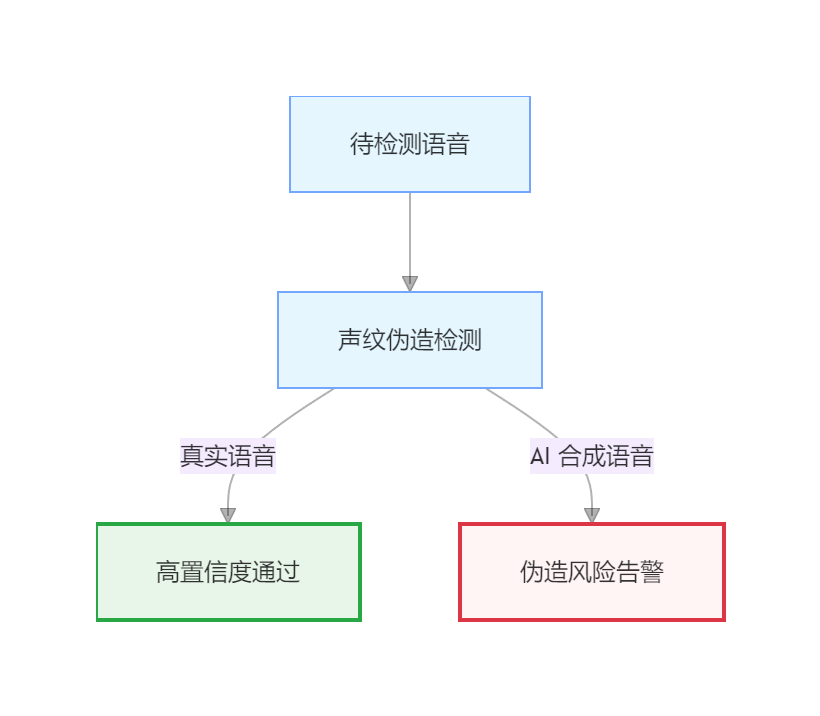
针对AI合成语音的检测方案。采用多特征融合策略,结合传统声学特征(MFCC、LPC)和深层声纹特征(x-vector等),从声纹提取和伪造检测两个维度构建识别能力。针对合成语音,系统采用"传统规则+深度学习"的混合方法:先用频谱异常、韵律节奏等规则快速筛选,再通过CNN/LSTM/Transformer等深度模型进行精细检测。方案注重实际部署,通过捕捉声学细节的人工痕迹,在保证
在 AI 语音识别场景中,语音往往并非自然通话环境采集,而是经过 TTS 合成、语音克隆或多次转码处理。这类语音在内容上高度逼真,但在声学层面仍然存在可被识别的“人工痕迹”。
因此,熙瑾会悟系统,从声纹特征提取和伪造语音检测两个层面入手,构建一套可实际部署的智能语音识别与检测能力。
一、整体技术思路
系统整体流程如下:
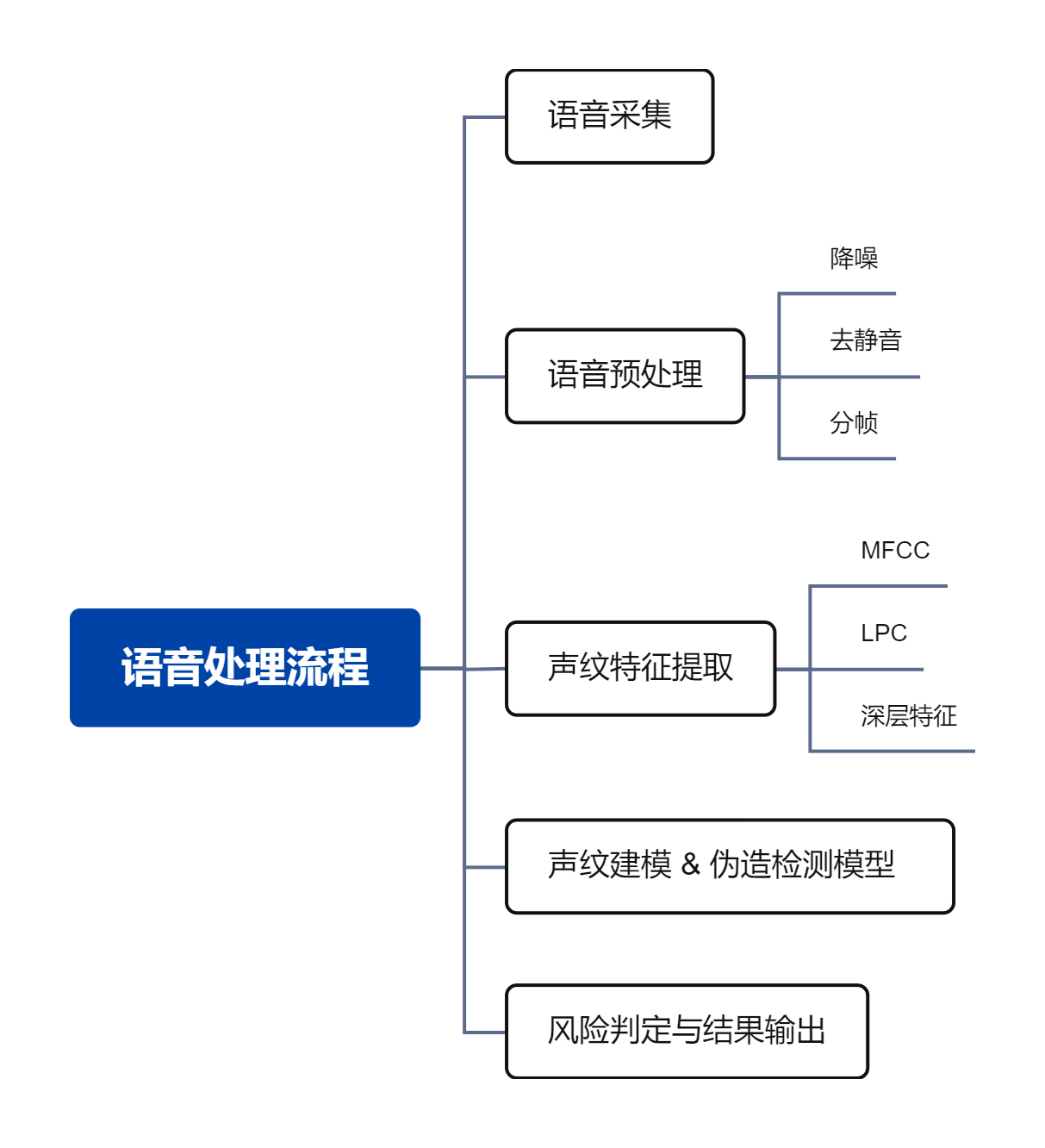
其中,声纹特征提取是整个系统的基础,直接决定后续识别和检测的效果。
二、声纹特征提取实现
在工程实现中,我们采用多特征融合策略,而不是依赖单一声学特征。
-
传统声学特征
-
MFCC(梅尔倒谱系数)
主要用于刻画人耳感知的频谱特性,对说话人音色、共振峰变化较为敏感。工程上一般提取 13~40 维,并结合一阶、二阶差分。 -
LPC(线性预测系数)
用于建模声道特性,对语音生成机制较敏感,能补充 MFCC 在低频段的信息不足问题。
-
-
深层声纹特征
-
基于 CNN / ResNet 的声纹嵌入模型(如 x-vector、ECAPA-TDNN)
-
输入通常为 Mel-Spectrogram 或 Fbank 特征
-
输出为固定维度的说话人向量,用于后续比对或分类
-
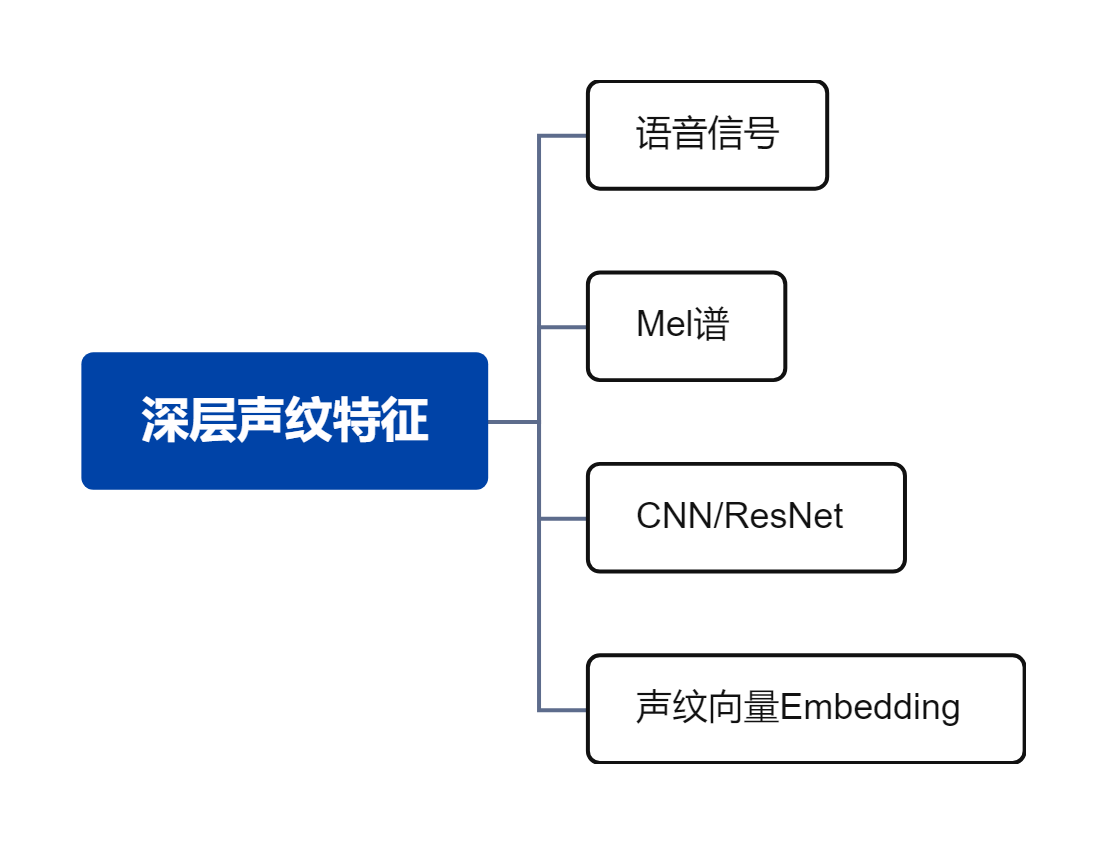
深层特征在区分真实人声与合成语音方面表现更稳定,适合大规模部署。
三、AI 合成语音与语音克隆检测
针对常见的 AI 合成语音,本方案采用“传统特征 + 深度模型”组合方式:
-
传统检测方法
-
频谱过于平滑、能量分布异常
-
韵律节奏不自然(停顿位置固定、语速一致)
-
高频噪声模式不符合真实人声特性
-
这些规则可作为第一层快速筛选,降低系统负载。
-
深度学习检测模型
-
CNN / LSTM / Transformer 结构,用于时序建模
-
输入为原始波形或频谱特征
-
输出真实 / 伪造的概率评分
-
-
端到端伪造检测模型
-
引入 ASVspoof 系列模型(如 LCNN、AASIST)
-
WaveFake 等直接基于波形的检测模型
-
可针对主流 TTS、语音克隆算法进行专项训练
-
熙瑾会悟并不是简单地“听声音、做判断”,而是从声音背后的声学细节入手,去分辨声音。系统一方面通过多种声纹特征的融合,尽可能还原真实人声的自然差异,另一方面结合深度模型与规则检测,专门捕捉 TTS 和语音克隆中常见却不易察觉的人工痕迹。这样做的好处是,既能保证识别的准确性,又能兼顾系统的稳定性和落地性。整体方案不追求炫技,而是强调可部署、可扩展,能够在真实业务场景中长期稳定运行。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)