金融保险理赔流程自动化回归测试的体系化实践
摘要:金融保险理赔自动化测试框架解决了传统回归测试的三大痛点:效率低下、覆盖不足和环境依赖。通过用例原子化分解、动态数据治理和智能回归策略,实现理赔流程高效验证。某寿险公司应用后,缺陷率下降72%,测试人力减少83%,规则覆盖率达98.6%。未来将结合LLM自动生成用例、混沌工程和实时监控持续优化测试体系。该方案显著提升了金融保险领域的测试效能和质量保障能力。(149字)
一、行业痛点与测试挑战
金融保险理赔流程具备多系统耦合性(核心业务系统+风控引擎+支付网关)、业务规则复杂性(保单条款/免赔计算/反欺诈规则)及数据敏感性(客户隐私/交易流水),传统回归测试面临三大瓶颈:
-
迭代效率低下:手工验证单次理赔流程需2-3人日,敏捷迭代周期压缩至1周
-
场景覆盖不足:精算规则组合超200种,人工仅能覆盖核心路径
-
环境依赖过重:银行通道/医院数据接口的Mock成本占总测试时长60%
二、自动化回归测试框架设计(技术栈图谱)
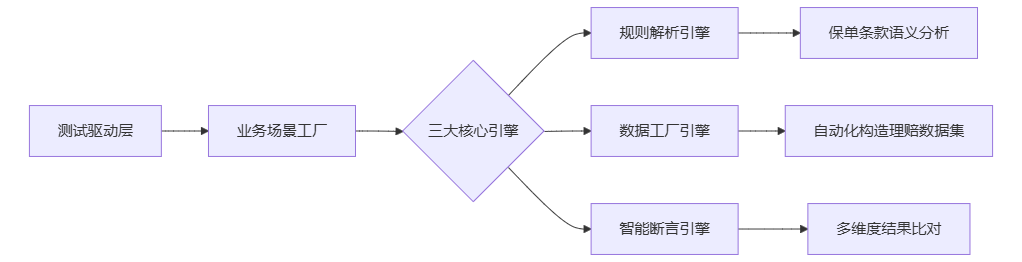
三、关键实施路径
3.1 测试用例原子化分解
# 理赔受理原子用例示例
def test_claim_submission():
# 构造测试数据
policy = DataFactory.create_policy(type="重疾险", status="生效中")
claim = ClaimBuilder(policy).set_diagnosis("恶性肿瘤").build()# 执行自动化流程
result = WorkflowEngine.execute("理赔受理", claim)# 智能断言
AssertionEngine.verify(
result.status == "审核中",
result.audit_rule_fired == ["重大疾病标准"],
log_validation=True
)3.2 动态数据治理方案
|
数据类型 |
生成策略 |
脱敏要求 |
|---|---|---|
|
被保人信息 |
基于规则的模板生成 |
GDPR/《个人金融信息保护法》 |
|
医疗诊断记录 |
HL7标准数据模型驱动 |
HIPAA兼容加密 |
|
银行交易流水 |
支付网关沙箱环境捕获 |
PCI DSS L1认证 |
3.3 智能回归策略矩阵
| 变更类型 | 回归范围判定模型 | 自动化执行权重 |
|---------------|-------------------------|--------------|
| 费率表更新 | 影响度分析引擎 → 关联用例库 | P0(100%) |
| 风控规则新增 | 决策树依赖分析 → 路径组合 | P1(85%+) |
| 界面组件优化 | 视觉对比工具+DOM嗅探 | P2(30%) |
四、落地成效与持续优化
某头部寿险公司实施案例:
-
缺陷拦截率提升:生产环境理赔逻辑缺陷下降72%
-
资源消耗优化:回归测试人力从12人·日/次→2人·日/次
-
覆盖深度突破:精算规则组合覆盖率达98.6%
持续改进方向:
-
基于LLM的测试用例自生成:将保单条款自动转化为Gherkin脚本
-
混沌工程注入:模拟医院系统中断/支付通道超时等故障场景
-
实时监测量化:通过Prometheus+Granfa监控测试资产健康度
精选文章:

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献393条内容
已为社区贡献393条内容

所有评论(0)