PostgreSQL数据库与PgVector向量插件基础使用
·
1.Ubantu部署安装软件
1.1 软件安装
# 更新系统包
sudo apt update && sudo apt upgrade -y
# 安装必要依赖(编译工具、PostgreSQL依赖、libpq等)
sudo apt install -y build-essential git postgresql postgresql-server-dev-all libpq-devbuild-essential:提供编译所需的 gcc、make 等工具;postgresql:基础 PostgreSQL 数据库(PgVector 依赖 PostgreSQL 11+,Ubuntu 默认源的版本满足);postgresql-server-dev-all:PostgreSQL 扩展开发所需的头文件;libpq-dev:客户端连接 PostgreSQL 的依赖。
1.2 确认软件状态
# 查看服务状态
sudo systemctl status postgresql
# 若未启动,手动启动并设置开机自启
sudo systemctl start postgresql
sudo systemctl enable postgresql1.3 PgVector插件安装
# 克隆仓库(建议放到 /usr/local/src 目录)
sudo git clone https://github.com/pgvector/pgvector.git /usr/local/src/pgvector
cd /usr/local/src/pgvector# 编译(使用 PostgreSQL 的 pg_config 定位编译路径)
make
# 安装(需要 root 权限)
sudo make install1.4 创建用户与数据库
创建postgres系统用户:
sudo -u postgres psql创建数据库并启用pgvector插件:
-- 1. 创建测试数据库(可自定义名称,如 vector_db)
CREATE DATABASE vector_db;
-- 2. 连接到新建的数据库
\c vector_db;
-- 3. 创建 pgvector 扩展(核心步骤,启用向量功能)
CREATE EXTENSION vector;
-- 4. 验证扩展是否创建成功
\dx; -- 列出所有已安装的扩展,能看到 vector 即成功输出中会包含如下内容:
List of installed extensions
Name | Version | Schema | Description
---------+---------+------------+------------------------------
vector | 0.5.1 | public | vector data type and indexes1.5 测试PgVector功能
-- 1. 创建表(包含 id 和 3 维向量字段)
CREATE TABLE embeddings (
id SERIAL PRIMARY KEY,
vec vector(3) -- 定义 3 维向量,维度可自定义(如 1536 对应 OpenAI 嵌入)
);
-- 2. 插入向量数据
INSERT INTO embeddings (vec) VALUES
('[1,2,3]'),
('[4,5,6]'),
('[7,8,9]');
-- 3. 查询向量(计算与 [2,3,4] 的欧氏距离并排序)
SELECT id, vec, vec <-> '[2,3,4]' AS distance
FROM embeddings
ORDER BY distance;输出结果会按距离从小到大排序,示例:
id | vec | distance
----+---------+-------------------
1 | [1,2,3] | 1.7320508075688772
2 | [4,5,6] | 3.464101615137755
3 | [7,8,9] | 8.660254037844387<-> 是 PgVector 内置的欧氏距离运算符,还支持 <#>(内积)、<=>(余弦距离)等。
1.6 配置远程连接与密码修改
默认 PostgreSQL 只允许本地连接,需修改 Ubuntu 上的配置
修改 pg_hba.conf(信任远程连接):
sudo vim /etc/postgresql/$(ls /etc/postgresql)/main/pg_hba.conf添加一行(允许任意 IP 访问,生产环境建议限定具体 IP):
host all all 0.0.0.0/0 md5修改 postgresql.conf(监听所有地址):
sudo vim /etc/postgresql/$(ls /etc/postgresql)/main/postgresql.conflisten_addresses = '*' # 默认为 localhost,改为 *设置 postgres 用户密码:
sudo -u postgres psql
# 在PostgreSQL终端执行
ALTER USER postgres WITH PASSWORD '你的新密码';
\q重启 PostgreSQL 生效:
sudo systemctl restart postgresql2.SpringBoot集成
2.1 连接
Maven依赖(向量数据库的两种整合方式):
<!-- 自动整合 PGVector 向量存储 -->
<!-- <dependency>-->
<!-- <groupId>org.springframework.ai</groupId>-->
<!-- <artifactId>spring-ai-starter-vector-store-pgvector</artifactId>-->
<!-- <version>1.0.0-M7</version>-->
<!-- </dependency>-->
<!-- 手动整合 PGVector 向量存储 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
</dependency>
配置文件:
spring:
# 数据库连接配置
datasource:
url: jdbc:postgresql://你的Ubuntu服务器IP:5432/vector_db # 替换为实际IP和数据库名
username: postgres # 默认用户名
password: 你的postgres密码 # 需设置postgres用户密码(后续讲)
driver-class-name: org.postgresql.Driver2.2 基础操作案例
实体类:
package com.example.demo.entity;
import javax.persistence.*;
import lombok.Data;
@Data
@Entity
@Table(name = "embeddings") // 对应 PostgreSQL 中的 embeddings 表
public class Embedding {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY) // 对应 SERIAL 主键
private Long id;
@Column(name = "vec") // 向量字段,PgVector 中存储为字符串格式(如 "[1,2,3]")
private String vec; // 注意:PgVector 的 vector 类型在 Java 中用 String 接收/传递
}数据层接口:
package com.example.demo.repository;
import com.example.demo.entity.Embedding;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.query.Param;
import java.util.List;
public interface EmbeddingRepository extends JpaRepository<Embedding, Long> {
// 自定义查询:根据目标向量计算欧氏距离并排序(核心向量查询)
@Query(value = "SELECT e FROM Embedding e ORDER BY e.vec <-> :targetVec")
List<Embedding> findByVecOrderByDistance(@Param("targetVec") String targetVec);
// 也可写原生SQL(更灵活)
@Query(value = "SELECT * FROM embeddings ORDER BY vec <-> :targetVec LIMIT 10", nativeQuery = true)
List<Embedding> findTop10ByVec(@Param("targetVec") String targetVec);
}测试:
package com.example.demo;
import com.example.demo.entity.Embedding;
import com.example.demo.repository.EmbeddingRepository;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
public class EmbeddingTest {
@Autowired
private EmbeddingRepository embeddingRepository;
// 测试插入向量数据
@Test
public void testInsert() {
Embedding embedding = new Embedding();
embedding.setVec("[1,2,3]"); // 设置 3 维向量
embeddingRepository.save(embedding);
Embedding embedding2 = new Embedding();
embedding2.setVec("[4,5,6]");
embeddingRepository.save(embedding2);
}
// 测试向量相似度查询
@Test
public void testQuery() {
// 查询与 [2,3,4] 最相似的向量(按欧氏距离排序)
List<Embedding> list = embeddingRepository.findByVecOrderByDistance("[2,3,4]");
for (Embedding e : list) {
System.out.println("ID: " + e.getId() + ", 向量: " + e.getVec());
}
}
}2.3 SpringAI集成PgVector做向量数据库
2.3.1 依赖与配置
ai:
dashscope:
api-key:
chat:
opentions:
model: qwen-max
vectorstore:
pgvector:
index-type: HNSW
dimensions: 1536 #向量维度
distance-type: COSINE_DISTANCE
max-document-batch-size: 10000 # Optional: Maximum number of documents per batch
<!-- 自动整合 PGVector 向量存储 -->
<!-- <dependency>-->
<!-- <groupId>org.springframework.ai</groupId>-->
<!-- <artifactId>spring-ai-starter-vector-store-pgvector</artifactId>-->
<!-- <version>1.0.0-M7</version>-->
<!-- </dependency>-->
<!-- 手动整合 PGVector 向量存储 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store</artifactId>
</dependency>2.3.2 基于PgVector做向量数据库
-- 创建带维度的表(1536 维,根据你的嵌入模型调整)
CREATE TABLE public.vector_store (
id VARCHAR(255) PRIMARY KEY,
content TEXT,
metadata JSONB,
embedding VECTOR(1536) -- 维度必须和嵌入模型一致
);
import jakarta.annotation.Resource;
import org.springframework.ai.document.Document;
import org.springframework.ai.embedding.EmbeddingModel;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.ai.vectorstore.pgvector.PgVectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import java.util.List;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgDistanceType.COSINE_DISTANCE;
import static org.springframework.ai.vectorstore.pgvector.PgVectorStore.PgIndexType.HNSW;
// 为方便开发调试和部署,临时注释,如果需要使用 PgVector 存储知识库,取消注释即可
@Configuration
public class PgVectorVectorStoreConfig {
@Resource
private LoveAppDocumentLoader loveAppDocumentLoader;
@Bean
public VectorStore pgVectorVectorStore(JdbcTemplate jdbcTemplate, EmbeddingModel dashscopeEmbeddingModel) {
VectorStore vectorStore = PgVectorStore.builder(jdbcTemplate, dashscopeEmbeddingModel)
.dimensions(1536) // Optional: defaults to model dimensions or 1536
.distanceType(COSINE_DISTANCE) // Optional: defaults to COSINE_DISTANCE
.indexType(HNSW) // Optional: defaults to HNSW
.initializeSchema(true) // Optional: defaults to false
.schemaName("public") // Optional: defaults to "public"
.vectorTableName("vector_store") // Optional: defaults to "vector_store"
.maxDocumentBatchSize(10000) // Optional: defaults to 10000
.build();
// 加载文档
List<Document> documents = loveAppDocumentLoader.loadMarkdowns();
vectorStore.add(documents);
return vectorStore;
}
}
2.3.3 向量Embed测试
import jakarta.annotation.Resource;
import org.junit.jupiter.api.Assertions;
import org.junit.jupiter.api.Test;
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
import java.util.Map;
@SpringBootTest
class PgVectorVectorStoreConfigTest {
@Resource
private VectorStore pgVectorVectorStore;
@Test
void pgVectorVectorStore() {
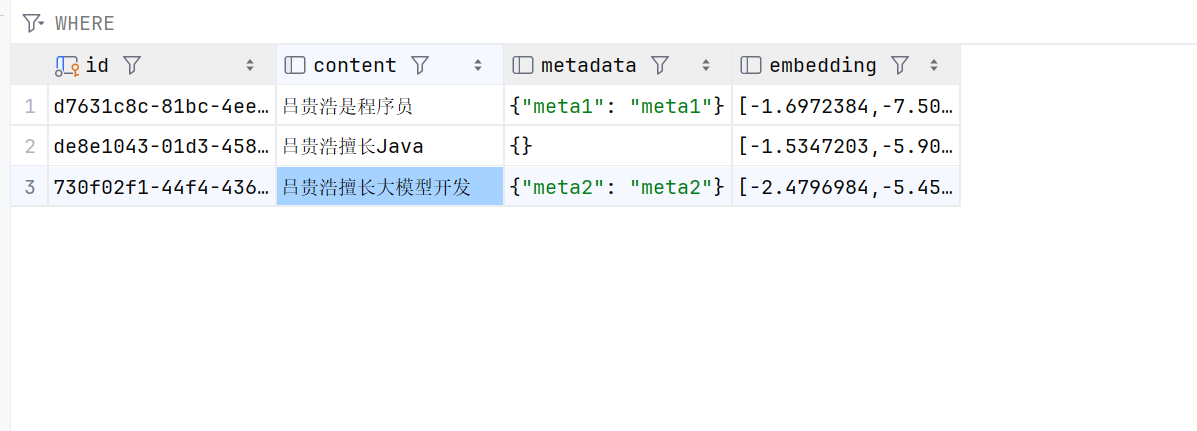
List<Document> documents = List.of(
new Document("吕贵浩是程序员", Map.of("meta1", "meta1")),
new Document("吕贵浩擅长Java"),
new Document("吕贵浩擅长大模型开发", Map.of("meta2", "meta2")));
// 添加文档
pgVectorVectorStore.add(documents);
// 相似度查询
List<Document> results = pgVectorVectorStore.similaritySearch(SearchRequest.builder().query("吕贵浩是谁").topK(3).build());
Assertions.assertNotNull(results);
}
}
数据库存储:
2.3.4 Agent集成测试
@Resource
private VectorStore pgVectorStore;
public String doChatWithRag(String message, String chatId) {
ChatResponse chatResponse=chatClient.prompt()
.user(message)
.advisors(spec -> spec.param(ChatMemory.CONVERSATION_ID, chatId))
.advisors(new MyLoggerAdvisor())
//RAG
// .advisors(new QuestionAnswerAdvisor(loveAppVectorStore))
//云上RAG
// .advisors(loveAppRagCloudAdvisor)
//PgRAG
.advisors(new QuestionAnswerAdvisor(pgVectorStore))
.call()
.chatResponse();
String content=chatResponse.getResult().getOutput().getText();
log.info("content: {}", content);
return content;
}
@Test
void doChatWithRag() {
String chatId = UUID.randomUUID().toString();
String message = "吕贵浩是谁?";
String answer= loveApp.doChatWithRag(message, chatId);
Assertions.assertNotNull(answer);
}

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)