Aho-Corasick算法
Aho-Corasick算法摘要: Aho-Corasick算法是一种高效的多模式字符串匹配算法,广泛应用于敏感词过滤、入侵检测等场景。该算法通过构建Trie树存储所有模式串,并引入失败指针实现状态转移,能在单次文本扫描中完成所有模式匹配。时间复杂度为O(n+m+z),其中n为文本长度,m为模式串总长度,z为匹配数。文中展示了C#实现的关键部分,包括Trie节点构建、失败指针设置等核心逻辑。算法特
Aho-Corasick算法
文章目录
前言
在开发过程中经常会遇到文字匹配的需求,比如你在玩王者荣耀的时候,队友太坑了,你打字问候了他的母亲,王者荣耀的文字交流框就会警告让你不要骂人,这就是Aho-Corasick算法的实际应用。接下来我们就一起来看看这个算法他是怎么实现的吧。
一、何为Aho-Corasick算法?它的作用是什么?
Aho-Corasick算法是一种经典的多模式字符串匹配算法,用于在一个文本串中同时查找多个模式串的所有出现位置
主要作用
- 高效的多模式匹配:
在文本处理、搜索引擎、生物信息学、网络安全(如病毒特征码检测)等领域,常需从一段文本中同时检测成千上万个关键词或模式。Aho-Corasick算法通过一次扫描文本即可完成所有模式串的匹配,效率远高于逐个匹配每个模式串。 - 核心思想:
1、基于 Trie(字典树) 存储所有模式串。
2、通过 失败指针(Fail指针) 实现状态转移,类似于KMP算法的“部分匹配表”,但扩展至多模式场景。当匹配失败时,借助失败指针跳转到其他可能匹配的状态,避免重复扫描文本。 - 时间复杂度优势:
1、预处理阶段:构建Trie和失败指针,复杂度与所有模式串总长度成正比。
2、匹配阶段:仅需扫描文本一次,时间复杂度为 O(n + m + z),其中 n是文本长度,m是模式串总长度,z是匹配总数。
应用场景
- 敏感词过滤:检测文本中是否包含大量预设敏感词。
- 入侵检测系统(IDS):匹配网络数据包中的攻击特征。
- DNA序列分析:查找多个特定序列片段。
- 拼写检查、代码语法分析等需快速匹配多个模式的场景。
二、代码实现
下面我们采用C# 代码进行实现,这里使用的是dotnet8
这里可能看起来会有点抽象,后面我们会采用图的方式来讲解它的数据流转过程。
internal sealed class KeywordMatcher
{
private readonly record struct PatternInfo(string Pattern, string Original);
private readonly ushort[] _dict;
private readonly int[] _first;
private readonly IntDictionary[] _nextIndex;
private readonly int[] _end;
private readonly int[] _resultIndex;
private readonly int[] _keywordLengths;
private readonly IDictionary<string, List<int>> _originalSourceMap;
private readonly PatternInfo[] _patterns;
private readonly bool[] _isPlainKeyword; // 标记 source 中的每个关键词是否为普通关键词(不含 *)
public KeywordMatcher(IEnumerable<string> keywords)
{
this._originalSourceMap = new Dictionary<string, List<int>>();
var plainKeywords = new List<string>();
var wildcardPatterns = new List<PatternInfo>();
// 1. 分离普通关键词和通配符模式
foreach (string keyword in keywords)
{
if (keyword.Contains('*'))
{
// 通配符模式:生成正则表达式,并记录子串映射
var pattern = new PatternInfo(keyword.Replace("*", ".{0,10}"), keyword);
wildcardPatterns.Add(pattern);
var itemKeys = keyword.Split('*', StringSplitOptions.RemoveEmptyEntries);
foreach (var itemKey in itemKeys)
{
if (!this._originalSourceMap.TryGetValue(itemKey, out var list))
{
list = new List<int>();
}
list.Add(wildcardPatterns.Count - 1);
this._originalSourceMap[itemKey] = list;
}
}
else
{
plainKeywords.Add(keyword);
}
}
this._patterns = wildcardPatterns.ToArray();
// 2. 构建 source 列表(用于 AC 自动机)
// 顺序:先所有普通关键词(去重),再通配符子串中不存在于普通关键词的部分(去重)
var sourceList = new List<string>();
var plainSet = new HashSet<string>(plainKeywords);
sourceList.AddRange(plainSet); // 普通关键词
var wildcardSubstrings = new HashSet<string>(this._originalSourceMap.Keys);
foreach (var sub in wildcardSubstrings)
{
if (!plainSet.Contains(sub))
sourceList.Add(sub);
}
var source = sourceList; // IEnumerable<string>
// 标记每个关键词是否为普通关键词
this._isPlainKeyword = new bool[source.Count];
for (int i = 0; i < source.Count; i++)
{
this._isPlainKeyword[i] = plainSet.Contains(source[i]);
}
// 3. 构建 AC 自动机(与原逻辑一致)
this._keywordLengths = GenerateKeywordLength(source);
var allNode = GenerateAllNodes(source, out var root);
root.Failure = root;
this._dict = GenerateDict(allNode);
this._first = GenerateFirst(allNode);
this._nextIndex = GenerateIndexs(allNode, root, out var resultIndex2, out var isEndStart);
var (ResultIndex, End) = GenerateResultIndex(resultIndex2, isEndStart);
this._resultIndex = ResultIndex;
this._end = End;
}
private static int[] GenerateKeywordLength(IEnumerable<string> source)
{
var lengths = new int[source.Count()];
int index = 0;
foreach (var item in source)
{
lengths[index++] = item.Length;
}
return lengths;
}
private static IDictionary<int, List<TrieNode>> ParseNodeLayers(IEnumerable<string> keywords, out TrieNode root)
{
root = new TrieNode();
var allNodeLayers = new Dictionary<int, List<TrieNode>>();
int kindex = 0;
foreach (string p in keywords)
{
var nd = root;
for (int j = 0; j < p.Length; j++)
{
nd = nd.Add((char)p[j]);
if (nd.Layer == 0)
{
nd.Layer = j + 1;
if (!allNodeLayers.TryGetValue(nd.Layer, out var trieNodes))
{
trieNodes = new List<TrieNode>();
allNodeLayers[nd.Layer] = trieNodes;
}
trieNodes.Add(nd);
}
}
nd.SetResults(kindex++);
}
return allNodeLayers;
}
private static List<TrieNode> GenerateAllNodes(IEnumerable<string> keywords, out TrieNode root)
{
var allNodeLayers = ParseNodeLayers(keywords, out root);
var allNode = new List<TrieNode> { root };
foreach (var trieNodes in allNodeLayers)
{
foreach (var nd in trieNodes.Value)
{
allNode.Add(nd);
}
}
for (int i = 1; i < allNode.Count; i++)
{
SetNode(allNode[i], i, root);
}
return allNode;
}
private static void SetNode(TrieNode nd, int i, TrieNode root)
{
nd.Index = i;
TrieNode? r = nd.Parent?.Failure;
char c = nd.Char;
while (r != default && !r.m_values.ContainsKey(c))
{
r = r.Failure;
}
nd.Failure = r == default ? root : r.m_values[c];
foreach (var result in nd.Failure.Results ?? Enumerable.Empty<int>())
{
nd.SetResults(result);
}
}
private static (int[] ResultIndex, int[] End) GenerateResultIndex(List<int> resultIndex2, List<bool> isEndStart)
{
var resultIndex = new List<int>();
var end = new List<int>();
for (int i = isEndStart.Count - 1; i >= 0; i--)
{
if (isEndStart[i])
{
end.Add(resultIndex.Count);
}
if (resultIndex2[i] > -1)
{
resultIndex.Add(resultIndex2[i]);
}
}
end.Add(resultIndex.Count);
return (resultIndex.ToArray(), end.ToArray());
}
private IntDictionary[] GenerateIndexs(List<TrieNode> allNodes, TrieNode root, out List<int> resultIndex2, out List<bool> isEndStart)
{
resultIndex2 = [];
isEndStart = [];
var _nextIndex2 = new IntDictionary[allNodes.Count];
for (int i = allNodes.Count - 1; i >= 0; i--)
{
var dict = new Dictionary<ushort, int>();
var result = new List<int>();
var oldNode = allNodes[i];
if (oldNode.m_values != null)
{
foreach (var item in oldNode.m_values)
{
var key = (char)this._dict[item.Key];
var index = item.Value.Index;
dict[key] = index;
}
}
if (oldNode.Results != null)
{
foreach (var item in oldNode.Results)
{
if (result.Contains(item) == false)
{
result.Add(item);
}
}
}
oldNode = oldNode.Failure;
while (oldNode != root)
{
if (oldNode?.m_values != null)
{
foreach (var item in oldNode.m_values)
{
var key = (char)_dict[item.Key];
var index = item.Value.Index;
if (dict.ContainsKey(key) == false)
{
dict[key] = index;
}
}
}
if (oldNode?.Results != null)
{
foreach (var item in oldNode.Results)
{
if (result.Contains(item) == false)
{
result.Add(item);
}
}
}
oldNode = oldNode?.Failure;
}
_nextIndex2[i] = new IntDictionary(dict);
if (result.Count > 0)
{
for (int j = result.Count - 1; j >= 0; j--)
{
resultIndex2.Add(result[j]);
isEndStart.Add(false);
}
isEndStart[isEndStart.Count - 1] = true;
}
else
{
resultIndex2.Add(-1);
isEndStart.Add(true);
}
allNodes[i].Dispose();
allNodes.RemoveAt(i);
}
return _nextIndex2;
}
private int[] GenerateFirst(List<TrieNode> allNodes)
{
var first = new int[char.MaxValue + 1];
foreach (var item in allNodes[0].m_values ?? new Dictionary<char, TrieNode>())
{
var key = (char)_dict[item.Key];
first[key] = item.Value.Index;
}
return first;
}
private static ushort[] GenerateDict(List<TrieNode> allNodes)
{
var keywords = string.Concat(allNodes.Skip(1).Select(n => n.Char));
var dictionary = SumKeywordCount(keywords);
var list = ParseCharList(dictionary);
var dict = new ushort[char.MaxValue + 1];
for (int i = 0; i < list.Count; i++)
{
dict[list[i]] = (ushort)(i + 1);
}
return dict;
}
private static IDictionary<char, int> SumKeywordCount(string keywords)
{
var dictionary = new Dictionary<char, int>();
foreach (var item in keywords)
{
if (dictionary.ContainsKey(item))
dictionary[item] += 1;
else
dictionary[item] = 1;
}
return dictionary;
}
private static IList<char> ParseCharList(IDictionary<char, int> dictionary)
{
var list = new List<char>();
var flag = false;
foreach (var item in dictionary.OrderByDescending(q => q.Value).Select(q => q.Key))
{
if (flag)
list.Add(item);
else
list.Insert(0, item);
flag = !flag;
}
return list;
}
/// <summary>
/// 组合匹配(支持通配符 * )
/// 例如:[a*b] 可匹配 "acssb", "awwb"
/// </summary>
public IEnumerable<string> CombinMatching(string source)
{
var matchedKeywords = new ConcurrentBag<string>();
var matchedKeywordMap = new Dictionary<string, List<int>>();
foreach (var result in this.FindAll(source))
{
if (!this._originalSourceMap.TryGetValue(result.Keyword, out var list))
continue;
if (!matchedKeywordMap.TryGetValue(result.Keyword, out var indexList))
indexList = new List<int>();
indexList.AddRange(list);
matchedKeywordMap[result.Keyword] = indexList;
}
Parallel.ForEach(matchedKeywordMap.Values.SelectMany(v => v).Distinct(), item =>
{
try
{
var patternInfo = this._patterns[item];
if (Regex.IsMatch(source, patternInfo.Pattern))
matchedKeywords.Add(patternInfo.Original);
}
catch (Exception) { }
});
return matchedKeywords.Distinct();
}
/// <summary>
/// 包含匹配(仅普通关键词,不含通配符拆分子串)
/// 例如关键词 ["abc","ab"],输入 "abc" 会返回 "abc","ab"
/// </summary>
public IEnumerable<string> SingleMatching(string source)
{
return this.FindAll(source)
.Where(r => _isPlainKeyword[r.Index])
.Select(r => r.Keyword);
}
/// <summary>
/// 最长匹配(仅普通关键词,不含通配符拆分子串)
/// 例如关键词 ["abc","ab"],输入 "abc" 只返回 "abc"
/// </summary>
public IEnumerable<string> LongestMatching(string source)
{
var results = FindAll(source).Where(r => _isPlainKeyword[r.Index]).ToList();
if (results.Count == 0)
return Array.Empty<string>();
bool[] keep = new bool[results.Count];
for (int i = 0; i < results.Count; i++)
{
keep[i] = true;
for (int j = 0; j < results.Count; j++)
{
if (i == j) continue;
if (results[j].Start <= results[i].Start && results[j].End >= results[i].End)
{
keep[i] = false;
break;
}
}
}
var matched = new HashSet<string>();
for (int i = 0; i < results.Count; i++)
if (keep[i]) matched.Add(results[i].Keyword);
return matched;
}
/// <summary>
/// 判断文本是否包含任意普通关键词(不含通配符拆分子串)
/// </summary>
public bool ContainsAny(string text)
{
var p = 0;
var txt = text.AsSpan();
for (int i = 0; i < txt.Length; i++)
{
var t = _dict[txt[i]];
if (t == 0)
{
p = 0;
continue;
}
if (p == 0 || !_nextIndex[p].TryGetValue(t, out int next))
next = _first[t];
if (next != 0)
{
for (int j = _end[next]; j < _end[next + 1]; j++)
{
var index = _resultIndex[j];
if (_isPlainKeyword[index])
return true;
}
}
p = next;
}
return false;
}
private List<WordsSearchResult> FindAll(string text)
{
var result = new List<WordsSearchResult>();
var p = 0;
var txt = text.AsSpan();
for (int i = 0; i < txt.Length; i++)
{
var t = _dict[txt[i]];
if (t == 0)
{
p = 0;
continue;
}
if (p == 0 || _nextIndex[p].TryGetValue(t, out int next) == false)
next = _first[t];
if (next != 0)
{
for (int j = _end[next]; j < _end[next + 1]; j++)
{
var index = _resultIndex[j];
var len = _keywordLengths[index];
var st = i + 1 - len;
var r = new WordsSearchResult(ref text, st, i, index);
result.Add(r);
}
}
p = next;
}
return result;
}
internal sealed class WordsSearchResult
{
private readonly string _text;
private string? _keyword;
private string? _matchKeyword;
public int Start { get; private set; }
public int End { get; private set; }
public string Keyword
{
get
{
if (_keyword == default)
_keyword = _text[Start..(End + 1)];
return _keyword;
}
}
public int Index { get; private set; }
public string MatchKeyword
{
get
{
if (_matchKeyword == default)
_matchKeyword = _keyword ?? _text[Start..(End + 1)];
return _matchKeyword;
}
}
public WordsSearchResult(ref string text, int start, int end, int index)
{
_text = text;
End = end;
Start = start;
Index = index;
}
public override string ToString()
{
if (MatchKeyword != Keyword)
return Start.ToString() + "|" + Keyword + "|" + MatchKeyword;
return Start.ToString() + "|" + Keyword;
}
}
internal readonly struct IntDictionary
{
public ushort[] Keys => _keys;
public int[] Values => _values;
private readonly ushort[] _keys;
private readonly int[] _values;
private readonly int _last;
public IntDictionary(ushort[] keys, int[] values)
{
_keys = keys;
_values = values;
_last = keys.Length - 1;
}
public IntDictionary(Dictionary<ushort, int> dict)
{
var keys = dict.Select(q => q.Key).OrderBy(q => q).ToArray();
var values = new int[keys.Length];
for (int i = 0; i < keys.Length; i++)
values[i] = dict[keys[i]];
_keys = keys;
_values = values;
_last = keys.Length - 1;
}
public bool TryGetValue(ushort key, out int value)
{
value = 0;
if (_last == -1) return false;
if (_keys[0] == key)
{
value = _values[0];
return true;
}
else if (_last == 0 || _keys[0] > key)
return false;
if (_keys[_last] == key)
{
value = _values[_last];
return true;
}
else if (_keys[_last] < key)
return false;
var index = this.FindKeyIndex(key);
if (index.HasValue)
{
value = _values[index.Value];
return true;
}
return false;
}
private int? FindKeyIndex(ushort key)
{
int left = 1, right = _last - 1;
while (left <= right)
{
int mid = (left + right) >> 1;
int d = _keys[mid] - key;
if (d == 0) return mid;
else if (d > 0) right = mid - 1;
else left = mid + 1;
}
return default;
}
}
internal sealed class TrieNode
{
public int Index { get; set; }
public int Layer { get; set; }
public bool End => this.Results != default;
public char Char { get; set; }
public List<int> Results { get; set; }
public Dictionary<char, TrieNode> m_values { get; set; }
public TrieNode? Failure { get; set; }
public TrieNode? Parent { get; set; }
public bool IsWildcard { get; set; }
public int WildcardLayer { get; set; }
public bool HasWildcard { get; set; }
public TrieNode()
{
Results = new List<int>();
m_values = new Dictionary<char, TrieNode>();
}
public TrieNode Add(char c)
{
if (!m_values.TryGetValue(c, out var node))
{
node = new TrieNode
{
Parent = this,
Char = c
};
m_values[c] = node;
}
return node;
}
public void SetResults(int index)
{
Results.Add(index);
}
public void Dispose()
{
Results?.Clear();
m_values?.Clear();
}
}
}
三、数据流转过程
数据预热
首先在构造这个对象的时候就会传入一个字符串集合,也就是IEnumerable<string> keywords
- 处理通配符
比如传入的list里存储的是:abc,bcd,ab*d
- 处理包含通配符 的关键词(如 abcd),将其转换为正则表达式模式(如 ab.{0,10}cd),并记录原始关键词。
- 将通配符关键词拆分为多个子关键词(如 ab, cd),并建立子关键词到原始模式索引的映射 (_originalSourceMap),用于后续的组合匹配。
- 最终得到一个纯净的、去重后的关键词列表 (source),用于构建核心匹配树。
- 构建Trie树

- 以所有预处理后的关键词构建一棵 Trie树(前缀树)。每个节点(TrieNode)代表一个字符,从根节点到某个节点的路径构成一个关键词或关键词前缀。
- 为每个节点标记其所在层级 (Layer),并将代表关键词结尾的节点记录其对应的关键词索引 (Results)
对应代码是:
var allNode = GenerateAllNodes(source, out var root);
- 构建失败指针 (SetNode)

- 这是Aho-Corasick算法的核心。它为Trie树中每个节点建立一个 Failure 指针(失败转移函数)。
- 其含义是:当在当前节点匹配失败时,应该跳转到哪个节点继续尝试匹配。这个指针的构建使得匹配过程在失败时无需回退文本指针,从而实现了单次扫描文本。
- 构建原则是:一个节点的失败指针指向其父节点的失败指针所指向的节点中,具有相同字符的子节点。这实质上是在寻找当前路径的最长可匹配后缀。
对应代码:
root.Failure = root;
- 数据压缩和结构优化

- 字符字典 (_dict): 将所有在关键词中出现的字符映射到一个紧凑的、连续的整数范围内(从1开始)。这大幅减少了后续数组访问的内存开销,并提高了缓存友好性。未出现的字符映射为0。
- 首字符跳转表 (_first): 一个数组,下标是压缩后的字符值,内容是直接可以从根节点跳转到的下一个节点索引。用于快速启动或重置匹配状态。
- 状态转移表 (_nextIndex): 一个IntDictionary数组。_nextIndex[p]表示在状态节点 p时,根据输入字符 t应该转移到哪个下一个节点。IntDictionary内部使用有序数组和二分查找实现键值查找,平衡了速度和内存。
- 结果索引与边界数组 (_resultIndex, _end): 这两个数组配合工作,用于快速获取某个状态节点匹配到的所有关键词索引。_end[next]到 _end[next+1]定义了在状态next时,匹配到的关键词索引在 _resultIndex数组中的范围。
对应代码
this._keywordLengths = GenerateKeywordLength(source);
var allNode = GenerateAllNodes(source, out var root);
root.Failure = root;
this._dict = GenerateDict(allNode);
this._first = GenerateFirst(allNode);
this._nextIndex = GenerateIndexs(allNode, root, out var resultIndex2, out var isEndStart);
var (ResultIndex, End) = GenerateResultIndex(resultIndex2, isEndStart);
当以上步骤走完之后,这个对象也就创建成功了,对应的数据也预热完成了,接下来我们看看它匹配的逻辑
内容匹配
例如我们输入文本:xabcyzabc
调用代码如下:
var factory2 = new KeywordMatcher(["abc", "bcd","ab*d"]);
var keys2 = factory2.SingleMatching("xabcyzabc");
Console.WriteLine("命中:{0}", string.Join(",", keys2));
输出结果为:
以匹配命中abc以图形方式解释: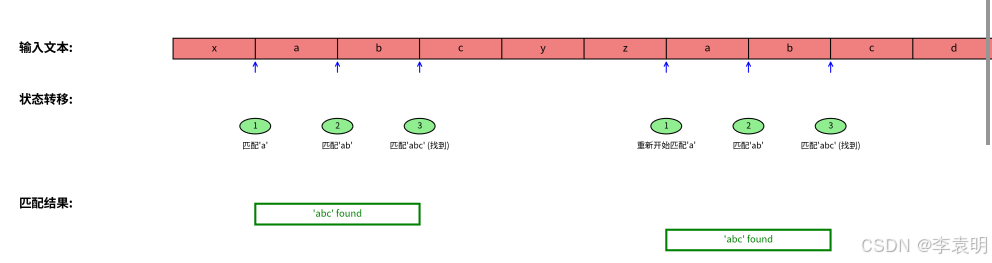
优缺点
优点
- 单次扫描文本(O(n)事件复杂度)
- 无回溯(文本指针不回退)
- 高效数据结构(数组+二分查找)
- 适合多关键字同时匹配
缺点
无法进行近似匹配
例如
我们传入待匹配集合里存储:abc d;中间多了个空格
传入字符串为abcd就会出现匹配不上的情况
调用代码
var factory2 = new KeywordMatcher(["abc d"]);
var keys2 = factory2.SingleMatching("abcd");
Console.WriteLine("命中:{0}", string.Join(",", keys2));
输出结果
总结
以上就是我今天的分享内容,感谢您的支持。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)