Kafka- flume报错:org.apache.flume.ChannelFullException: The channel has reached it‘s capacity.
在测试环境进行数据清洗,将原始日志数据经flume、kafka发送至HDFS,测试一亿条数据时,flume到HDFS出现问题。原因是HDFS Sink接收速度小于source速度,或channel内存小致数据溢出。通过调整channel内存大小、设置超时时间解决问题。
场景还原:
在测试环境进行数据清洗,由原始日志数据发送至HDFS,过程为:
原始日志文件–>flume->kafka->flume->HDFS
今天测试一亿条数据时出现问题,问题发生位置在flume->HDFS,问题整体描述如下:
ERROR kafka.KafkaSource: KafkaSource EXCEPTION, {}
org.apache.flume.ChannelFullException: The channel has reached it's capacity. This might be the result of a sink on the channel having too low of batch size, a downstream system running slower than normal, or that the channel capacity is just too low. [channel=c2]
at org.apache.flume.channel.file.FileChannel$FileBackedTransaction.doPut(FileChannel.java:505)
at org.apache.flume.channel.BasicTransactionSemantics.put(BasicTransactionSemantics.java:93)
at org.apache.flume.channel.BasicChannelSemantics.put(BasicChannelSemantics.java:80)
at org.apache.flume.channel.ChannelProcessor.processEventBatch(ChannelProcessor.java:191)
at org.apache.flume.source.kafka.KafkaSource.doProcess(KafkaSource.java:311)
at org.apache.flume.source.AbstractPollableSource.process(AbstractPollableSource.java:60)
at org.apache.flume.source.PollableSourceRunner$PollingRunner.run(PollableSourceRunner.java:133)
at java.lang.Thread.run(Thread.java:748)
问题原因分析
主要看一下这一句:
org.apache.flume.ChannelFullException: The channel has reached it's
capacity. This might be the result of a sink on the channel having too
low of batch size, a downstream system running slower than normal, or
that the channel capacity is just too low. [channel
译文:
这可能是由于通道上的接收器批大小过低、下游系统运行速度比正常慢,或者通道容量过低造成的。
分析:
日志打出来的很清楚了,意思就是HDFS Sink 接受的速度小于source的速度,还有一种可能就是channel的内存较小,导致数据溢出.所以根据日志在CDH中进行参数调整,将上述问题的情况调整一下.
操作步骤
调整channel的内存大小,设置超时时间,对大数据量进行缓冲.
参数 说明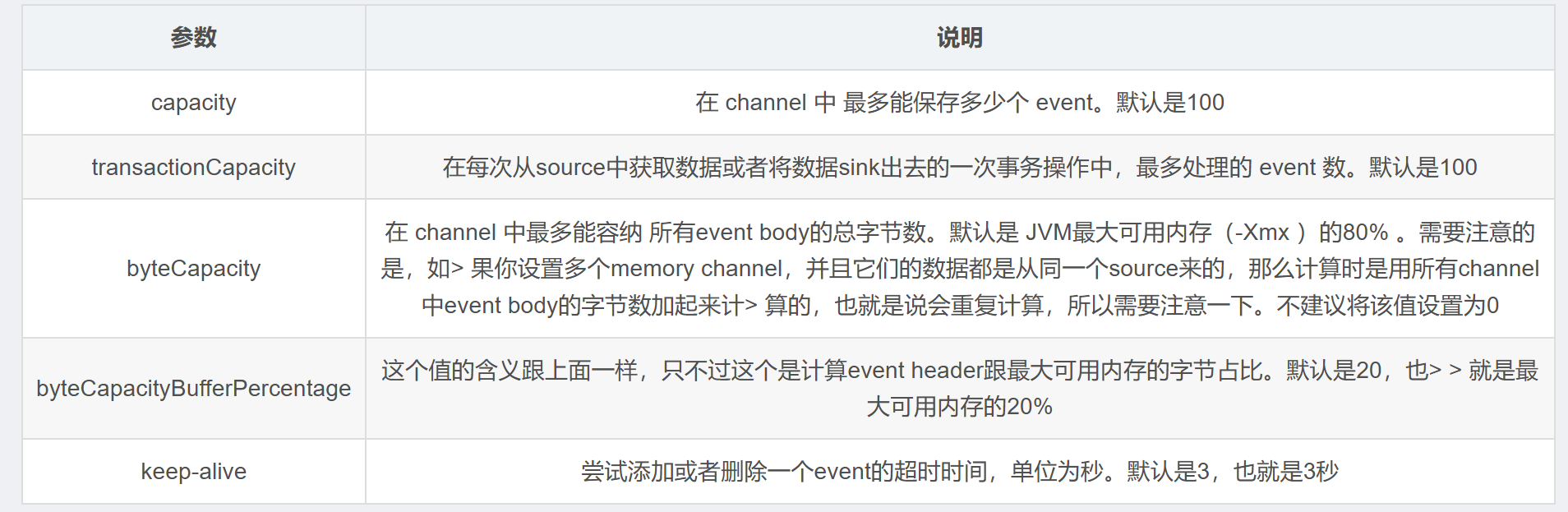
我的设置如下:
通道支持事务的最大大小
a1.channels.c1.transactionCapacity=1000000
#添加或者删除一个event的超时时间,单位为秒,默认是3
a1.channels.c1.keep-alive=60
#添加event,最多保存多少个event,默认是100
a1.channels.c1.capacity=1000000
C2也进行了如上配置,最后flume没报错,并且开始上传一亿条数据.
总结
在数据量大的时候,我们需要清楚flume以及kafka的运行机制,并且要知道flume的吞吐量,
比如说一亿条数据,采用flume的默认event保存机制100条是完全不够支撑的,
将超时时间换做60s给予缓冲,使用1000000的event来进行存储则可以解决面对的问题.
第二种解决办法(未尝试)
从java最大内存大小入手
修改java最大内存大小
vi bin/flume-ng
JAVA_OPTS="-Xmx2048m"
把jvm的堆空间设置大一点,防止flume本身的配置满足要求,但是堆大小不满足
参考链接
参考一:http://blog.leanote.com/post/rocketeer/Kafka%E7%9A%84%E4%B8%80%E6%AC%A1%E6%95%85%E9%9A%9C%E5%A4%84%E7%90%86
参考二:https://blog.csdn.net/qq_38262266/article/details/108683060

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)