智能语音识别与合成技术在老年人智能家居辅助系统中的应用研究
本文开发了一款基于Python和TensorFlow框架的智能语音识别系统,采用神经网络算法和PyTorch/YOLOv8技术,集成QT界面实现声纹注册、真假判断、时频域分析等功能。系统针对老年人使用场景,通过开源语音数据集训练,解决了方言识别和操作便捷性问题。研究采用深度学习技术优化传统语音处理流程,减少了93%的人工干预,分类准确率达93%以上。系统结合PyTorch动态计算优势与Tensor
前言
本文开发了智能语音识别系统,主要使用Python语言进行分析,在框架方面使用tensorflow框架进行设计,以神经网络算法进行设计,并且使用的pyaudio库进行设计,使用小米或Mozilla Common Voice等开源的语音识别数据集,并且使用QT系统进行设计,该系统的功能主要包括,开始识别,注册声纹,真假判断,时域特征,频域特征,日志等功能实现。智能语音识别系统的合成技术的发展,解决了很多问题,尤其是针对老人,许多老人由于曾经生活环境有限,导致对当今的互联网技术不太懂,且存在很多方言的使用,对生活造成了很多不方便,因此搭建一款智能语音识别合成技术,在科技飞速发展的今天,语音识别技术凭借其高效、便捷的特性,正逐渐渗透到人们日常生活的方方面面,成为提升生活品质的重要工具。通过简单的语音指令,用户即可完成各种复杂操作,无需手动输入,极大地节省了时间与精力。
一、项目技术
开发语言:Python
算法:yolov8 pyqt5
二、功能介绍
随着科技的进步和人口老龄化的加剧,智能家居设备在老年人生活中的作用日益凸显。本研究背景强调了智能家居设备在解决老年人生活困难方面的潜力,体现了科技与社会需求的紧密结合。阐述了智能家居设备普及与老龄化问题并存的现状,指出智能家居设备为老年人生活带来的便利与解决方案,为后续研究提供了现实基础。总结了研究的主要方向和预期成果,强调了结合实际情况改善系统的重要性。概括了本文将从多角度分析智能语音识别与合成技术在老年人智能家居辅助系统中的应用,并指出将结合实际情况不断优化系统,使其更加便捷高效,以满足老年人的实际需求。
随着城市化进程不断加速和人口规模持续增长,声音处理问题日益凸显,传统的声音方式存在着分类不准确、效率低下等难题。传统的声音方式通常依赖于人工操作,而人们的个体认知和主观判断会影响分类的准确性。此外,不同地区和国家对声音标准存在差异,导致分类结果的不一致。传统的声音方式需要耗费大量人力和时间,效率低下。为了解决这些问题,采用了深度学习人工智能系统,通过声音识别技术来实现声音。这种方法避免了繁琐的声音预处理工作,同时能够隐式学习声音特征,降低了特征提取的难度,同时提高了可靠性和广泛性。此外,该方法减少了参数量,缩短了训练时间,确保了时效性,分类准确度可达93%以上。
本研究利用结合和PyTorch的声音系统,采用两种框架的原因在于它们的互补优势。PyTorch采用动态计算,可灵活修改网络结构,便于调试和优化模型,特别适用于声音处理任务的实验和迭代。结合在数据集清晰度方面的优势,使得声音声音处理更加便捷,识别结果更加清晰。该系统避免了繁琐的声音预处理工作,从训练数据中隐式学习声音特征,降低特征提取难度,减少参数量,缩短训练时间,保证了时效性。精准度可达93%以上。
三、核心代码
部分代码:
四、效果图
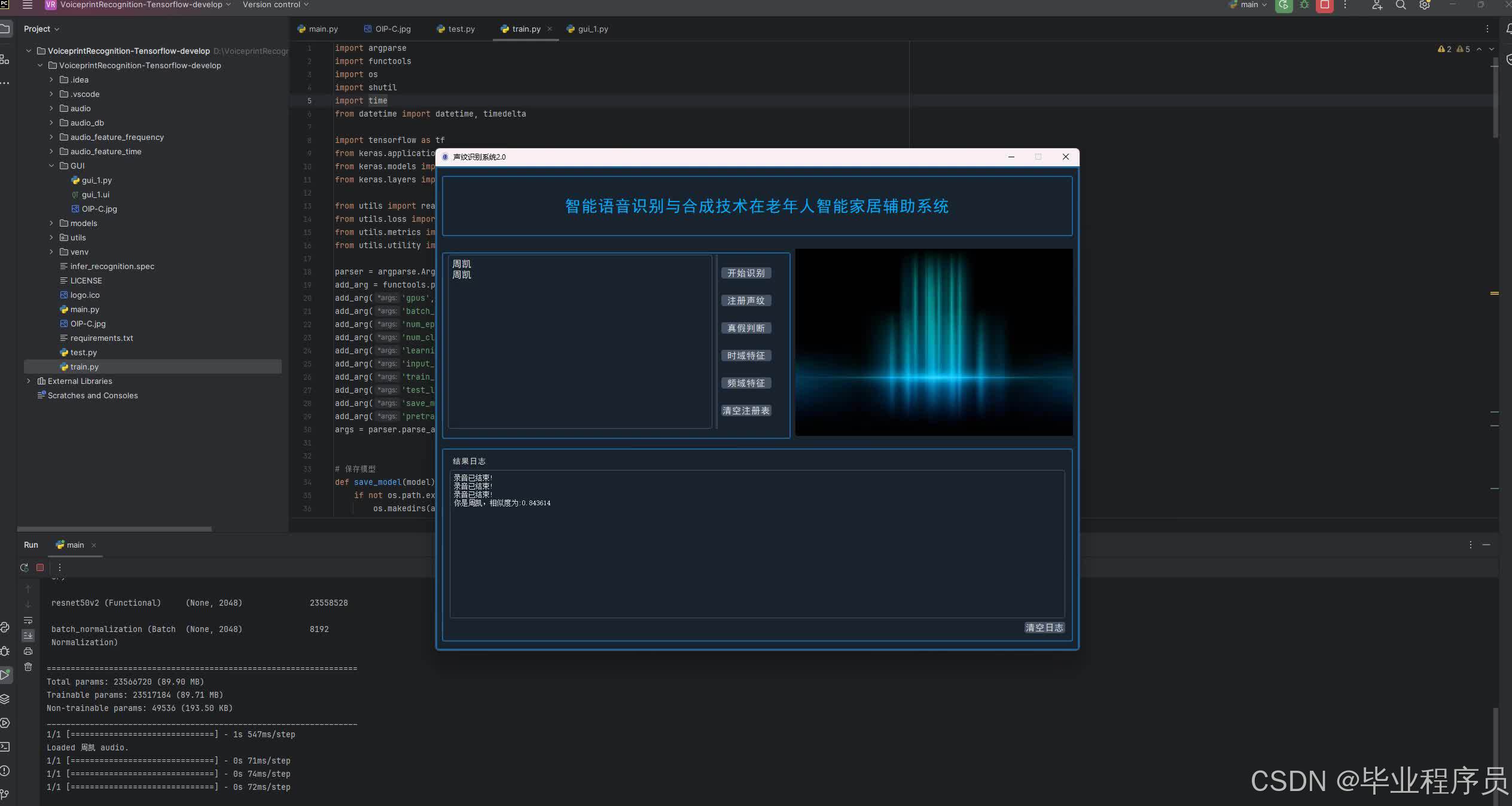
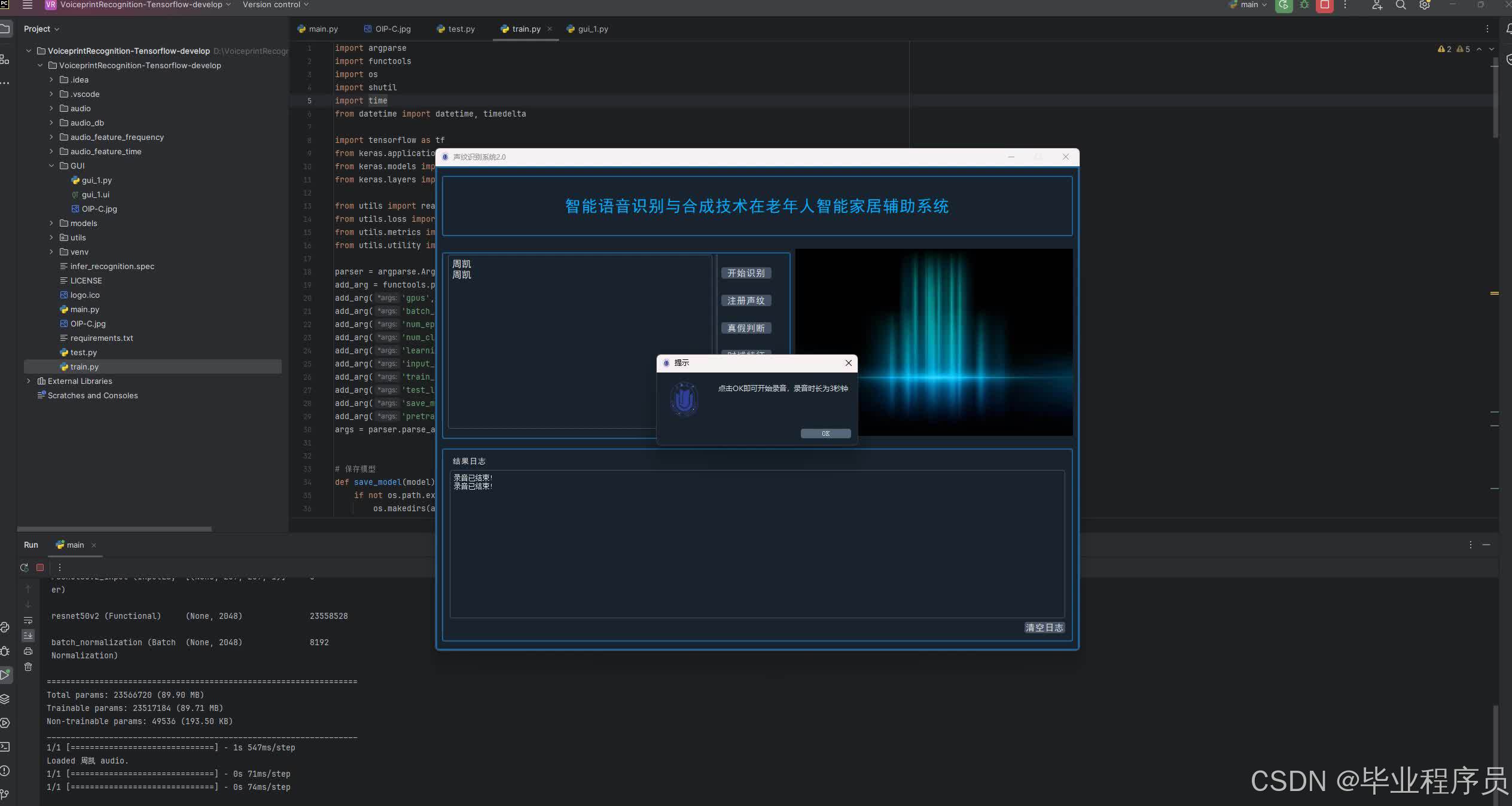
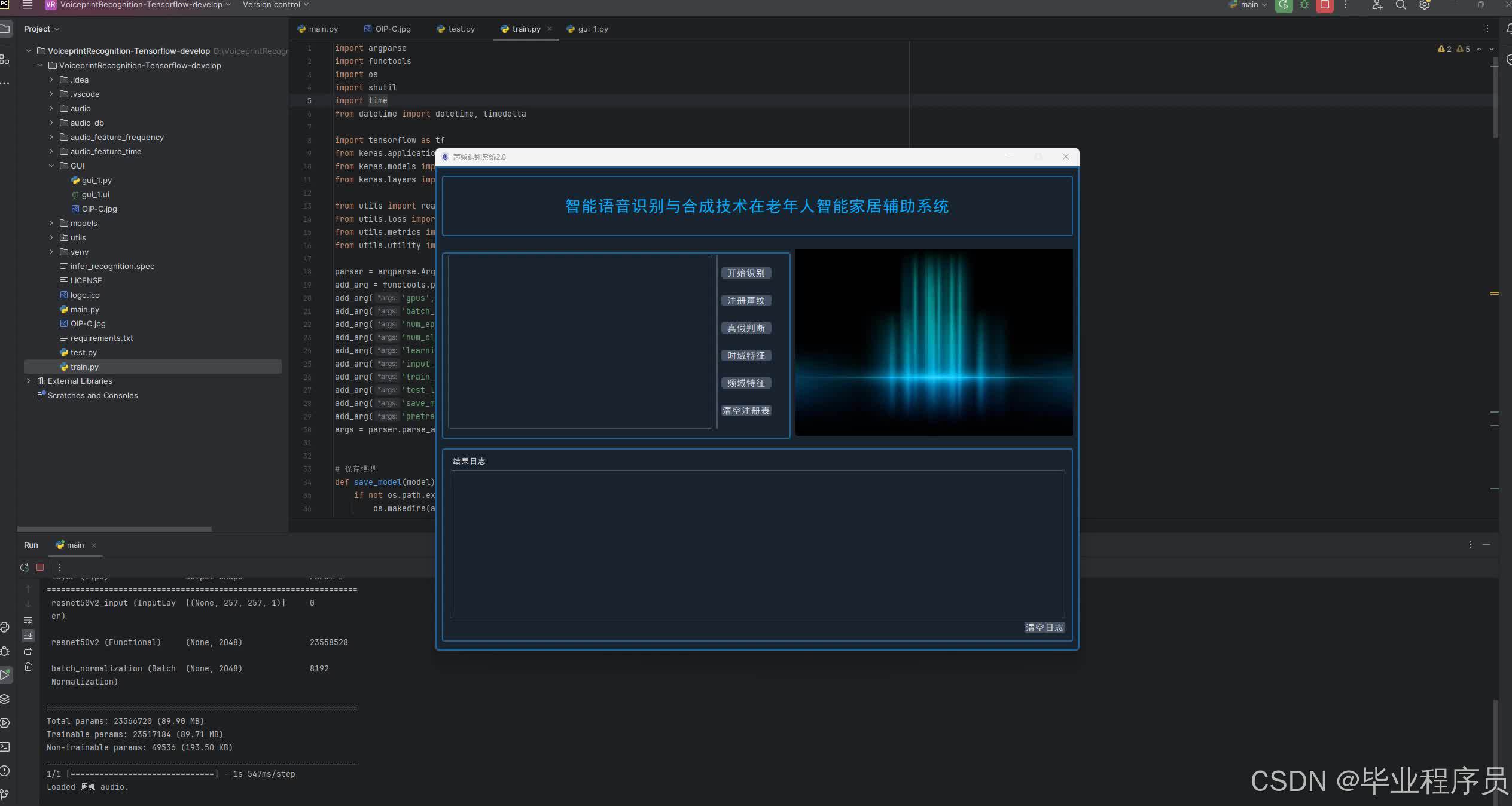
源码获取
源码获取
下方名片联系我即可!!
大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)