Kafka 核心架构深度解析:组件设计、数据流转与 ZK/KRaft 双模式
本文深度解析了Kafka的核心架构设计与数据流转机制。Kafka采用分布式无中心节点架构,包含集群服务层、消息存储层、生产消费层和元数据管理层四大功能模块,各组件协同实现高吞吐、高可用的消息传输。文章详细介绍了Broker、Topic、Partition等核心组件的职责与交互关系,并阐述了生产者-集群-消费者三层数据流转逻辑。特别对比了ZooKeeper和KRaft两种集群管理模式,指出KRaft
Kafka 核心架构深度解析:组件设计、数据流转与 ZK/KRaft 双模式
Kafka 采用分布式无中心节点的架构设计,整体围绕消息存储、生产消费、集群管理三大核心能力构建,所有组件协同工作实现高吞吐、高可用、可扩展的分布式消息传输能力,且 Kafka 2.8+ 支持ZooKeeper 模式和KRaft 模式(无 ZK)两种集群管理方式,核心架构组件一致,仅集群元数据管理模块不同。
一、Kafka 核心架构组件(全版本通用)
所有组件按功能可分为集群服务层、消息存储层、生产消费层、元数据管理层四大类,各组件职责单一、解耦设计,是 Kafka 高可用和可扩展的基础,核心组件及核心职责如下:
| 组件名称 | 核心职责 | 关键关联点 |
|---|---|---|
| Broker( 服务节点) | 集群的核心服务节点,是 Kafka 实例的最小部署单元; 负责接收生产者消息、存储消息、响应消费者拉取请求; 管理所在节点的 Partition 副本; 参与 Leader 副本选举。 |
一个集群由 N(≥3,生产环境)个 Broker 组成,无主从之分,可水平扩展; 每个 Broker 有唯一 ID 标识。 |
| Topic(主题) | 消息的逻辑分类容器,是生产者发送、消费者订阅的基本单位; 本身不存储消息,仅作为 Partition 的逻辑聚合。 |
一个 Topic 可关联多个 Partition,分区数决定了 Topic 的最大并行处理能力。 |
| Partition(分区) | 消息的物理存储最小单位,也是 Kafka 并行处理、数据分片的核心; 每个 Partition 是有序、不可变的消息日志序列,消息按发送顺序分配唯一 Offset; Partition 会分散存储在不同 Broker 上,实现负载均衡。 |
每个 Partition 有且仅有 1 个 Leader 副本、N-1 个 Follower 副本(N 为副本数,生产环境≥3)。 |
| Replica(副本) | 分为 Leader Replica(主副本)和 Follower Replica(从副本),是 Kafka 数据高可用的核心机制; Leader 负责处理该 Partition 的所有读写请求; Follower 后台持续同步 Leader 的消息日志,不处理业务请求; Leader 故障时,Follower 会被选举为新 Leader,保证数据不丢失、服务不中断。 |
副本会分散在不同 Broker 上(同一份数据不存同一节点),避免单 Broker 宕机导致数据丢失。 |
| Producer(生产者) | 消息生产端,负责向 Kafka 集群发送消息;支持指定 Topic/Partition/Key 发送,支持批量发送、消息重试、幂等性发送;内置分区器,可根据 Key 哈希或默认规则自动将消息分发到 Topic 的不同 Partition。 | 生产者仅与 Leader 副本交互,无需感知 Follower 存在,简化客户端逻辑。 |
| Consumer(消费者) | 消息消费端,负责从 Kafka 集群拉取并消费消息; 采用拉取模式(Poll),主动从 Broker 拉取消息,可灵活控制消费速率; 支持单消费、集群消费(消费者组)。 |
消费者仅与 Leader 副本交互,通过 Offset 记录消费位置。 |
| Consumer Group(消费者组,CG) | 多个消费者组成的逻辑组,是 Kafka 实现集群消费、避免重复消费的核心; 一个 Topic 的所有 Partition 会被均匀分配给组内不同消费者,一个 Partition 只能被组内一个消费者消费; 组内消费者数量≤Topic 分区数(超出的消费者会空闲)。 |
不同消费者组可独立消费同一个 Topic,互不干扰(实现多副本消费)。 |
| Offset(偏移量) | Partition 中消息的唯一递增整数标识,用于记录消费者的消费位置; 消费者消费一条消息后,会提交 Offset(自动 / 手动),标识 “该位置之前的消息已消费”; 服务重启后,消费者可通过 Offset 恢复消费。 |
Offset 可持久化存储(ZK/KRaft/ 本地),Kafka 还支持消费者组级别的 Offset 管理。 |
| Controller(控制器) | 由集群中一个 Broker 选举产生(Controller Broker),是 Kafka 集群的核心管理者; 负责集群元数据管理、Leader 副本选举、Broker 上下线状态感知、Topic/Partition 配置变更处理; 是集群的 “大脑”,所有元数据变更均由 Controller 统一协调。 |
Controller 故障时,集群会快速重新选举新 Controller,无单点故障。 |
二、Kafka 架构数据流转关系
所有组件的协同工作遵循固定的数据流规则,核心流转逻辑可概括为3 层交互,全程仅 Leader(主节点) 副本参与业务交互,Follower (从节点)仅做后台同步,简化整体架构复杂度:
1. 生产者 → Kafka 集群(消息发送)
- 生产者通过配置的 Broker 地址,获取目标 Topic 的元数据(该 Topic 有哪些 Partition,每个 Partition 的 Leader 副本在哪个 Broker 上);
- 生产者通过分区器确定消息要发送到的 Partition;
- 生产者直接向该 Partition 的Leader 副本所在 Broker 发送消息;
- Leader 副本将消息写入本地日志(磁盘顺序写),完成后向生产者返回确认(ACK);
- Follower 副本后台持续拉取 Leader 的消息日志,同步到本地,保证与 Leader 数据一致。
2. Kafka 集群 → 消费者(消息消费)
- 消费者组启动后,向 Kafka 集群发送订阅请求,获取目标 Topic 的元数据;
- Controller 为该消费者组分配 Partition(将 Topic 的 Partition 均匀分配给组内消费者);
- 消费者直接向分配到的 Partition 的Leader 副本所在 Broker 发起拉取(Poll)请求,指定要拉取的 Offset 范围;
- Broker 从 Leader 副本的日志中读取对应消息,返回给消费者;
- 消费者消费消息后,提交 Offset(自动 / 手动),告知 Kafka “该位置已消费”。
3. 集群内部(高可用与元数据管理)
- Controller 实时感知集群中 Broker 的上下线状态(通过心跳机制);
- 若某个 Broker 宕机,其管理的所有 Partition Leader 副本随之失效;
- Controller 立即为这些失效的 Partition 发起Leader 选举(从对应的 Follower 副本中选择最新的作为新 Leader);
- Controller 将新的元数据(Leader 位置、Broker 状态)同步到集群所有 Broker;
- 生产者 / 消费者重新获取元数据,后续请求直接发送到新 Leader 所在 Broker,服务无感知恢复。
三、两种集群管理模式(架构差异)
Kafka 架构的核心变化集中在元数据存储和Controller 依赖上,分为早期的 ZooKeeper 模式和 2.8+ 推出的 KRaft 模式(Kafka Raft),二者核心组件不变,仅元数据管理层不同,KRaft 模式是官方推荐的未来趋势,简化部署、提升稳定性。
1. 传统 ZooKeeper 模式(Kafka < 2.8 主流,2.8+ 兼容)
核心架构:Kafka 集群 + 独立 ZooKeeper 集群
元数据存储与职责划分:
ZooKeeper:作为外部元数据存储,负责存储所有集群元数据(Broker 列表、Topic/Partition 配置、Controller 选举信息、消费者组 Offset、Leader 副本信息等);同时负责Controller 选举(通过 ZK 临时节点实现)。
Kafka Controller:仅负责元数据执行(Leader 选举、Partition 分配、Broker 状态管理),元数据的读取 / 写入需依赖 ZooKeeper。
缺点:
引入外部依赖,增加部署和维护成本(需单独搭建 ZK 集群);
ZK 成为潜在性能瓶颈,高并发下元数据读写会影响 Kafka 性能;
多集群协同,故障排查复杂度提升。
图解:
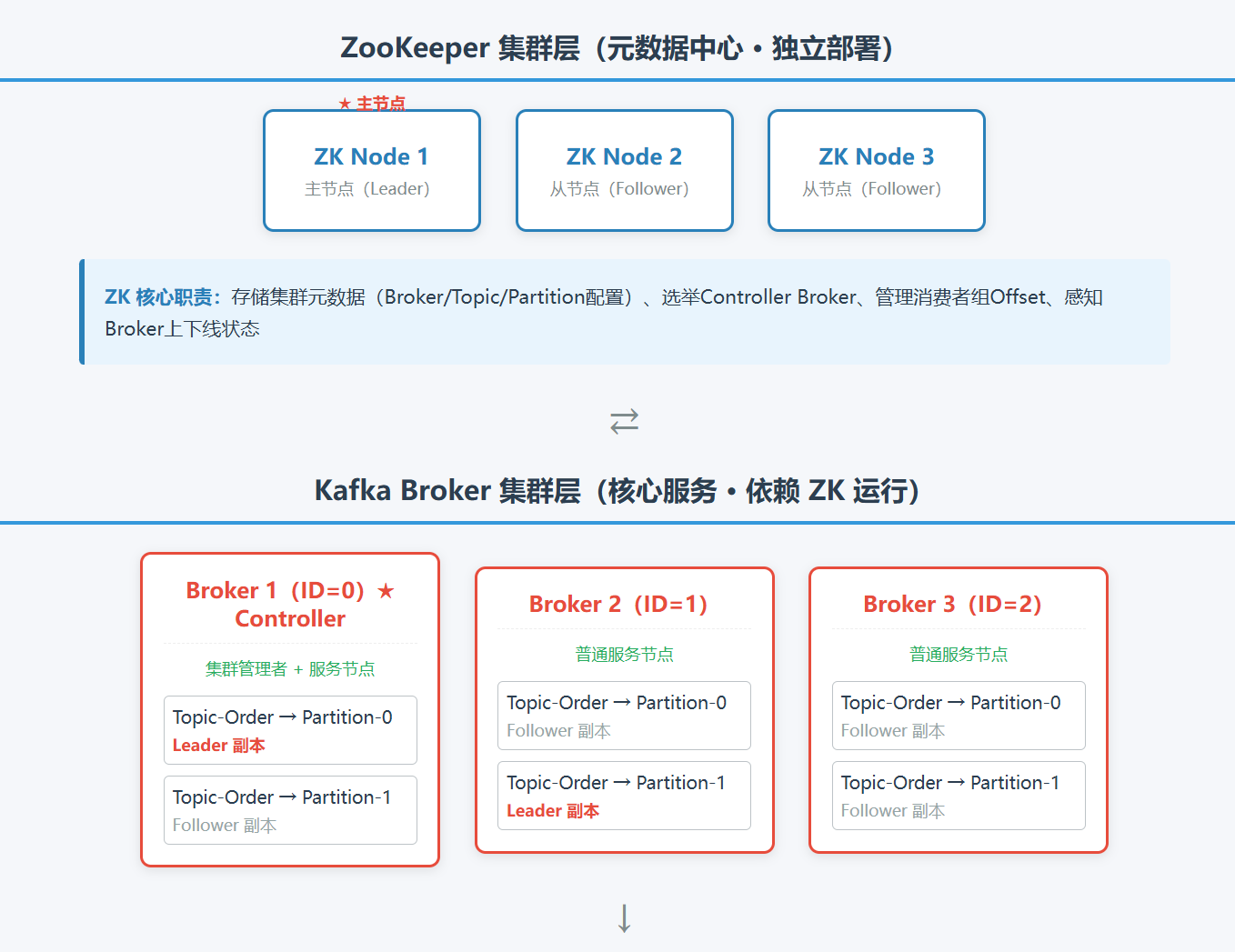
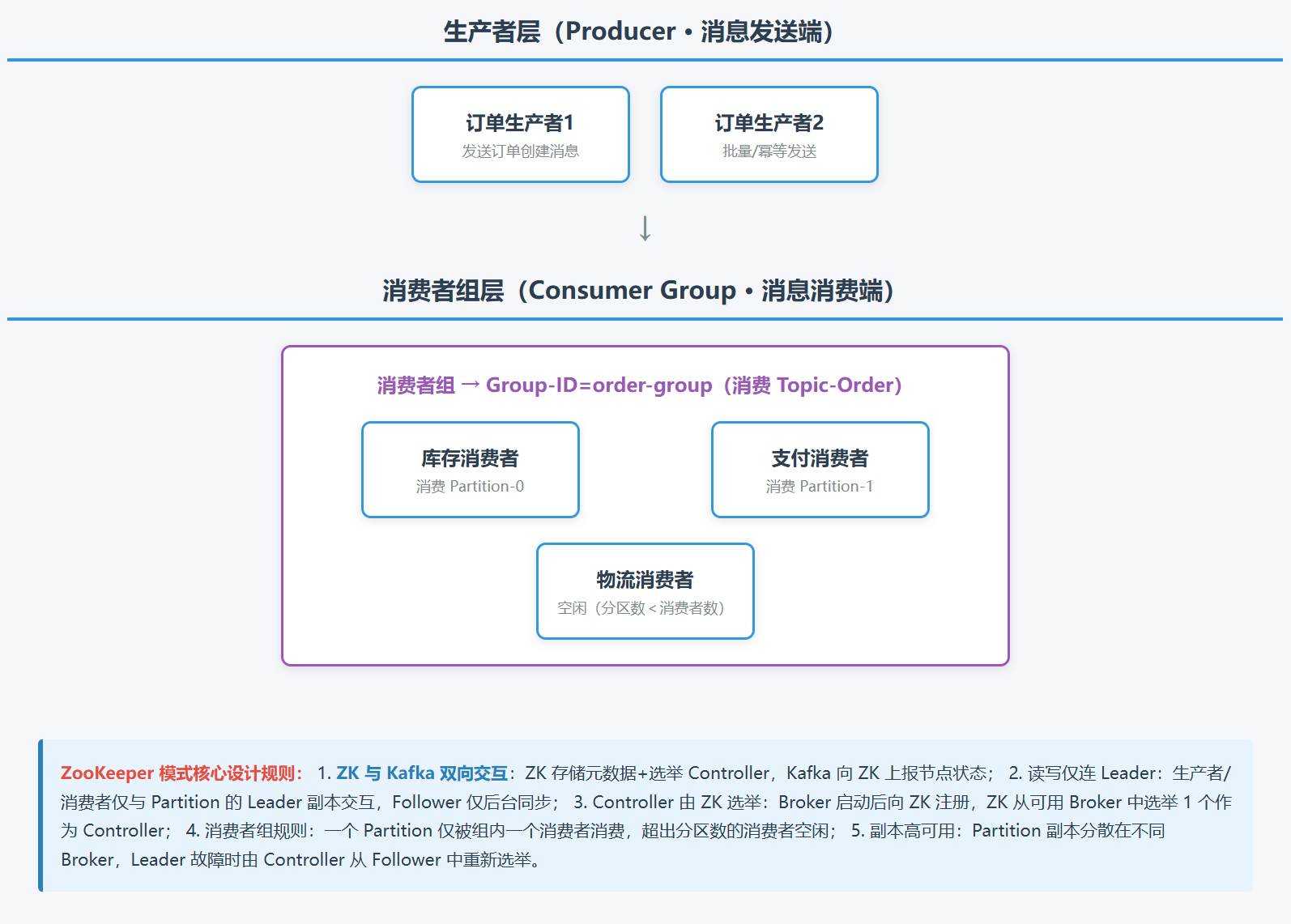
2. 新一代 KRaft 模式(Kafka 2.8+ 推出,官方推荐)
核心架构:纯 Kafka 集群(无外部依赖)
核心改进:基于 Raft 协议实现内置元数据管理
移除 ZooKeeper 依赖,Kafka 自身实现Raft 共识协议,将元数据存储在 Kafka 内部的专用 Topic(__cluster_metadata) 中;
集群分为3 种角色(可由 Broker 兼任),替代 ZK 的功能:
- Controller Node:参与 Raft 共识,负责元数据存储、Controller 选举、集群管理(核心角色,至少 3 个节点保证高可用);
- Broker Node:负责消息存储、生产消费交互(普通服务节点);
- Combined Node:同时承担 Controller Node 和 Broker Node 角色(生产环境推荐,简化部署,一台 Broker 可同时做控制器和服务节点)。
优点:
- 无外部依赖,部署和维护更简单;
- 元数据读写性能提升,消除 ZK 瓶颈;
- 集群架构更统一,故障排查更高效;
- 支持更大规模的集群扩展(百万级 Partition)。
图解:
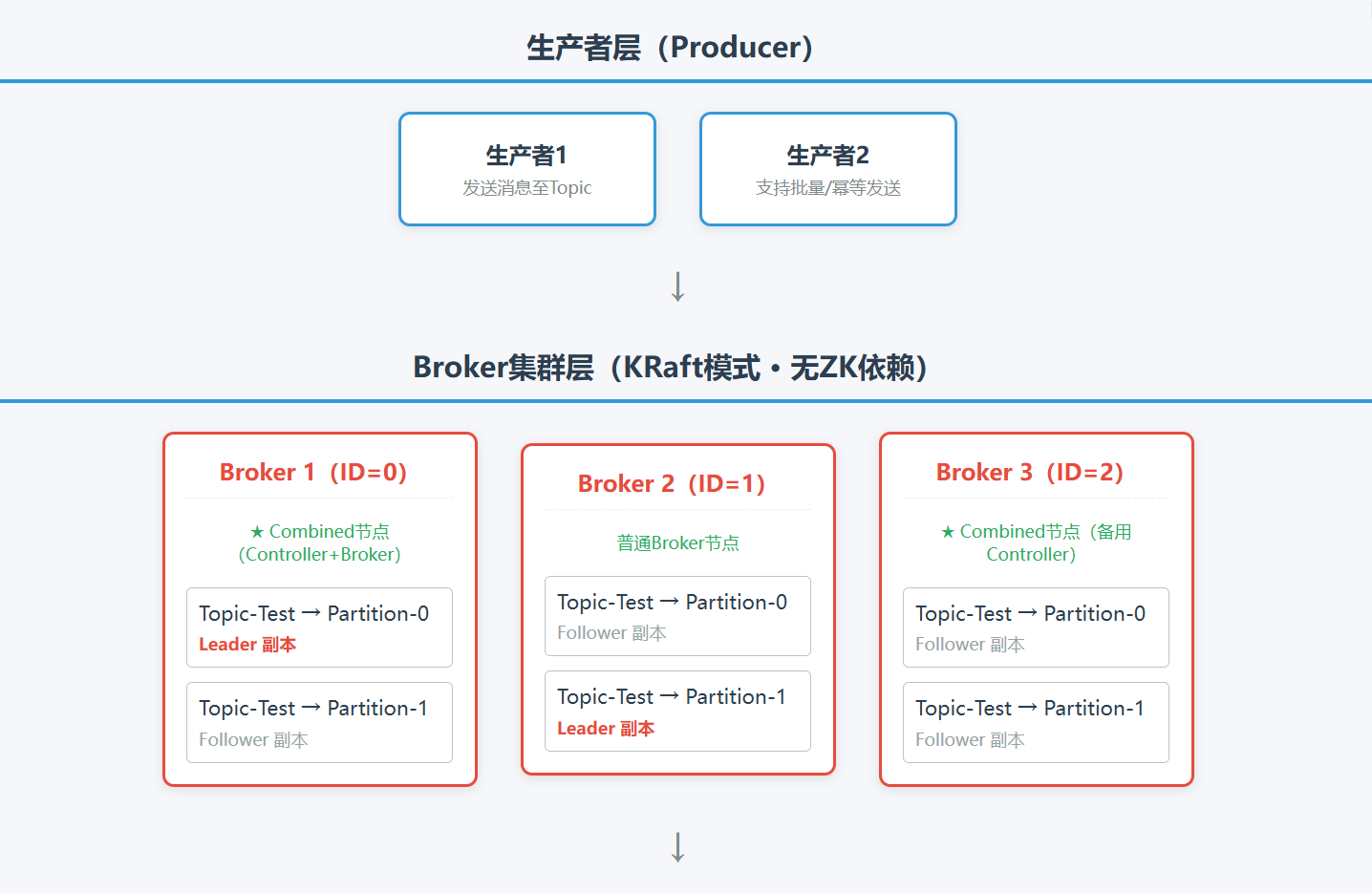
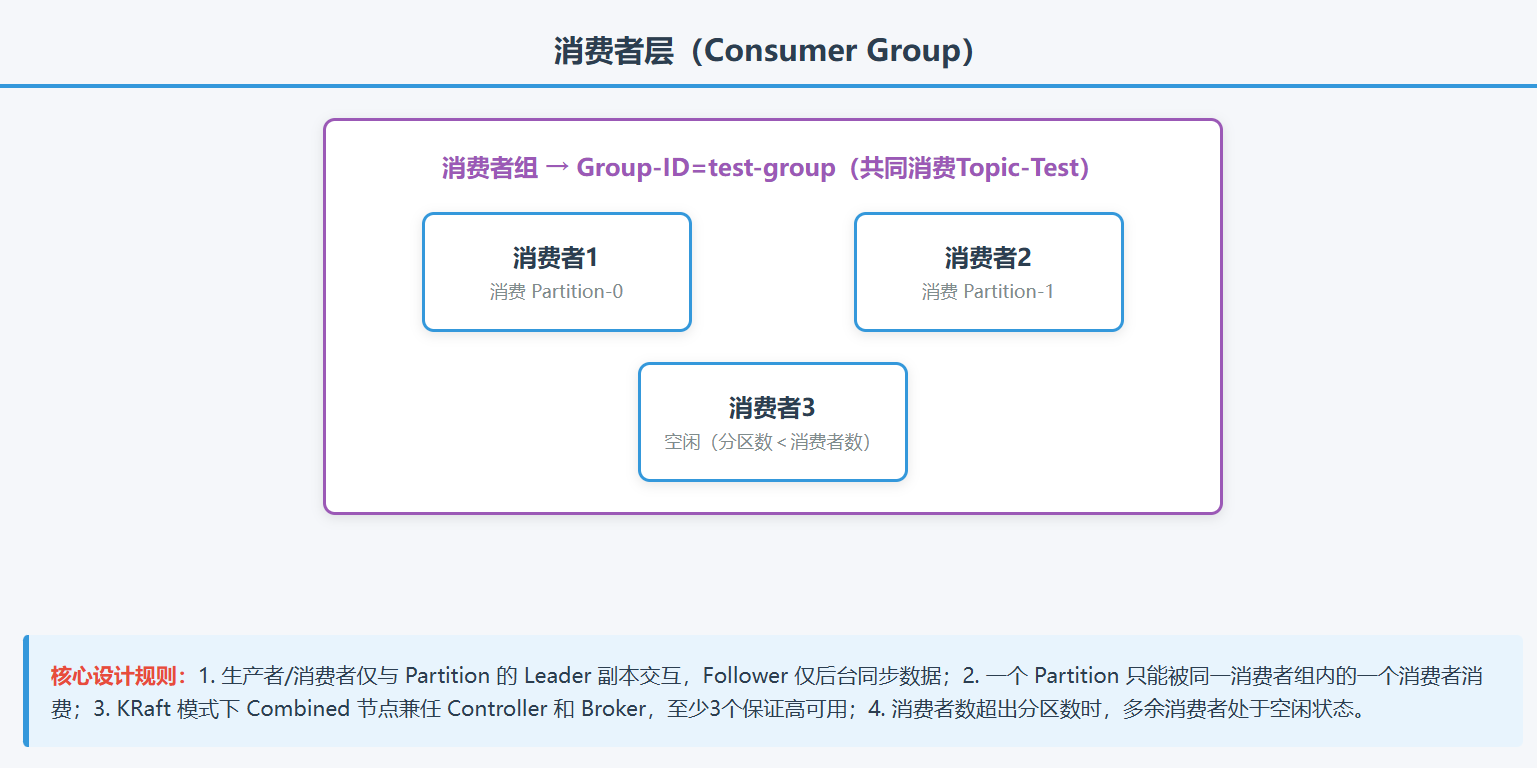
四、Kafka 架构核心设计亮点(架构优势的根源)
Kafka 之所以能实现高吞吐、低延迟、高可用、易扩展,核心源于架构设计的四大亮点,也是其与其他消息队列的核心区别:
- Leader/Follower 分离设计:Leader 处理所有读写请求,Follower 仅做后台同步,避免多副本竞争,提升读写性能;同时副本分散存储,保证数据高可用。
- Partition 分片机制:Topic 按 Partition 分片存储在不同 Broker 上,实现数据分布式存储;结合消费者组的 Partition 分配规则,实现生产 / 消费的并行处理,吞吐能力随 Partition 数和 Broker 数线性扩展。
- 无中心节点 + 水平扩展:集群中所有 Broker 对等,无主从节点,新增 Broker 后,Controller 会自动将 Partition 副本分配到新 Broker,无需停机,实现无缝水平扩展。
- 仅与 Leader 交互:生产者、消费者均只与 Leader 副本交互,无需感知 Follower 副本和集群拓扑,大幅简化客户端逻辑,降低开发和维护成本。
五、Kafka 架构总结
- 核心架构:分布式无中心节点,由 Broker 集群为核心,搭配生产消费端、控制器、副本机制,实现消息的存储、传输和高可用;
- 存储核心:Topic(逻辑)+ Partition(物理)+ Replica(高可用),Partition 是分片和并行的最小单位,Leader 是读写的唯一入口;
- 消费核心:消费者组 + Offset,保证集群消费不重复,消费位置可恢复;
- 管理核心:Controller 控制器,是集群的 “大脑”,负责所有元数据管理和故障恢复;
,Leader 是读写的唯一入口; - 消费核心:消费者组 + Offset,保证集群消费不重复,消费位置可恢复;
- 管理核心:Controller 控制器,是集群的 “大脑”,负责所有元数据管理和故障恢复;
- 部署模式:支持 ZK 模式(兼容旧版本)和 KRaft 模式(无外部依赖,官方推荐),核心架构不变。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 29
29 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)