基于卷积神经网络U-Net实现生物医学影像分割(PyTorch框架)
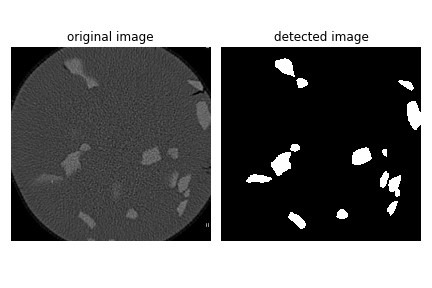
DL00642-基于卷积神经网络U-Net实现生物医学影像分割pytorch框架实现 由于数据集标注的困难,并且无法使用之前标注了部分的Mask R-CNN 实例分割数据集,本次仅使用30张语义分割图像,数据增强到100张进行训练,得到的效果较好。
在生物医学影像分析领域,图像分割一直是个关键任务,能帮助医生更好地理解图像结构,辅助疾病诊断。这次我们就来聊聊如何基于卷积神经网络U-Net,在PyTorch框架下实现生物医学影像分割。
数据集的挑战与应对
在这个项目中,我们遭遇了数据集标注的难题。本来想用之前标注了部分的Mask R-CNN实例分割数据集,却发现无法使用。无奈之下,我们仅拿到了30张语义分割图像。为了满足训练需求,数据增强成了我们的“救星”。通过数据增强技术,把这30张图像扩充到了100张,没想到最终训练得到的效果还挺不错。
PyTorch实现U-Net代码解析
导入必要库
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets在PyTorch中,这些库是基础。torch是核心库,提供张量操作、自动求导等功能;nn模块用于构建神经网络层;optim则包含各种优化器;torchvision方便处理图像数据,像这里的transforms用于数据变换,datasets提供了常见数据集的接口。
构建U-Net网络
class DoubleConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(DoubleConv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.conv(x)
class Down(nn.Module):
def __init__(self, in_channels, out_channels):
super(Down, self).__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
def __init__(self, in_channels, out_channels):
super(Up, self).__init__()
self.up = nn.ConvTranspose2d(in_channels, in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = nn.functional.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
class UNet(nn.Module):
def __init__(self, n_channels, n_classes):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.inc = DoubleConv(n_channels, 64)
self.down1 = Down(64, 128)
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
self.down4 = Down(512, 512)
self.up1 = Up(1024, 256)
self.up2 = Up(512, 128)
self.up3 = Up(256, 64)
self.up4 = Up(128, 64)
self.outc = OutConv(64, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc(x)
return logitsU-Net网络结构比较独特,很适合生物医学影像分割。DoubleConv类定义了两次卷积操作,中间加上批归一化和ReLU激活函数,能有效提取特征。Down类先进行最大池化下采样,再用DoubleConv进一步提取特征,逐渐缩小图像尺寸并增加通道数。Up类则相反,通过转置卷积上采样,然后与下采样过程中对应的特征图拼接,再经过DoubleConv处理。OutConv用于输出最终的分割结果。整个UNet类把这些模块按顺序组合起来,完成从输入图像到分割结果的映射。
数据加载与预处理
transform = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor()
])
train_dataset = datasets.ImageFolder(root='train_data_path', transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=4, shuffle=True)这里我们定义了数据变换,先把图像尺寸调整到256x256,再转换成张量。然后用ImageFolder加载训练数据,通过DataLoader按批次加载数据,每个批次大小设为4,并打乱顺序,这样训练时模型能看到更丰富的数据组合,提升泛化能力。
训练过程
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = UNet(n_channels=3, n_classes=2).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=1e-4)
for epoch in range(10):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data[0].to(device), data[1].to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
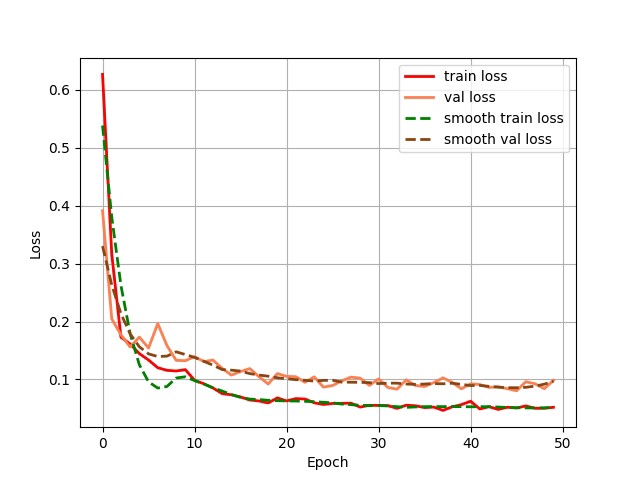
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')首先确定使用GPU还是CPU进行训练。初始化U-Net模型,设置损失函数为交叉熵损失,优化器选用Adam,学习率设为1e-4。在训练循环中,每个epoch遍历所有批次数据。每次迭代,先把输入和标签数据移到指定设备上,然后清空优化器梯度,前向传播得到模型输出,计算损失,反向传播更新梯度,最后记录并打印每个epoch的平均损失。
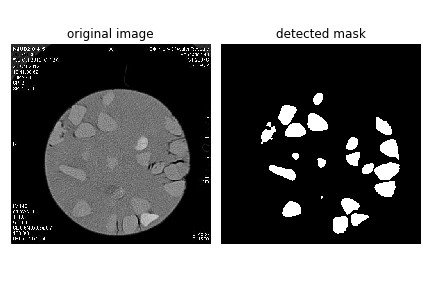
DL00642-基于卷积神经网络U-Net实现生物医学影像分割pytorch框架实现 由于数据集标注的困难,并且无法使用之前标注了部分的Mask R-CNN 实例分割数据集,本次仅使用30张语义分割图像,数据增强到100张进行训练,得到的效果较好。
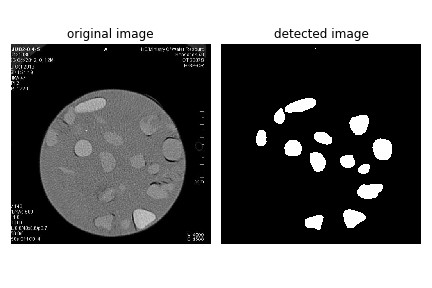
尽管数据集一开始很有限,但通过合理的数据增强,结合U-Net在PyTorch中的高效实现,我们还是取得了不错的生物医学影像分割效果。希望这篇博文能给同样在这个领域探索的朋友们一些启发。
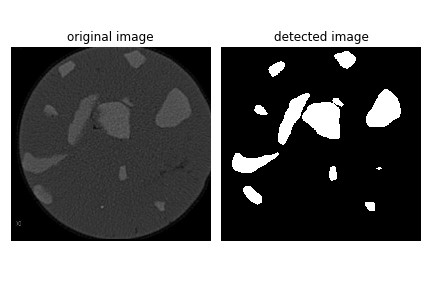

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)