用YOLOv8和PyQt5打造会“看脸色“的智能系统
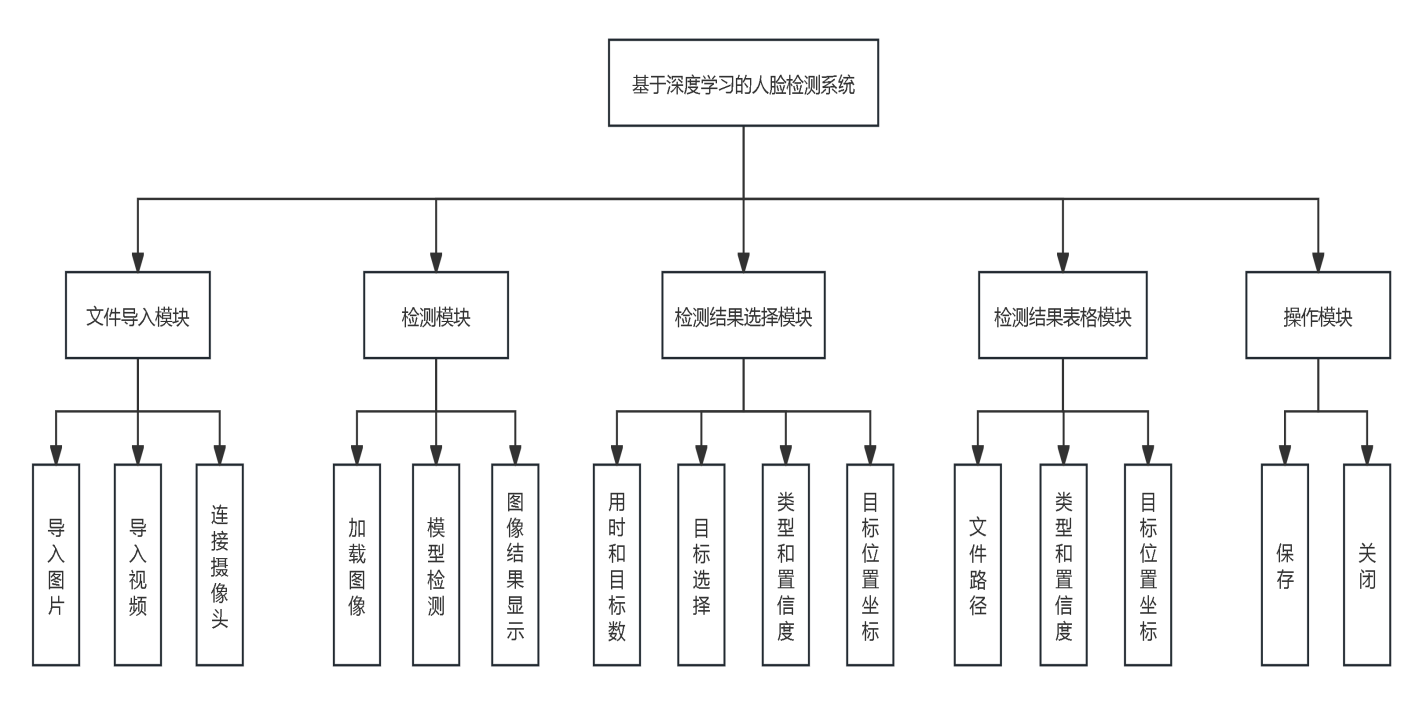
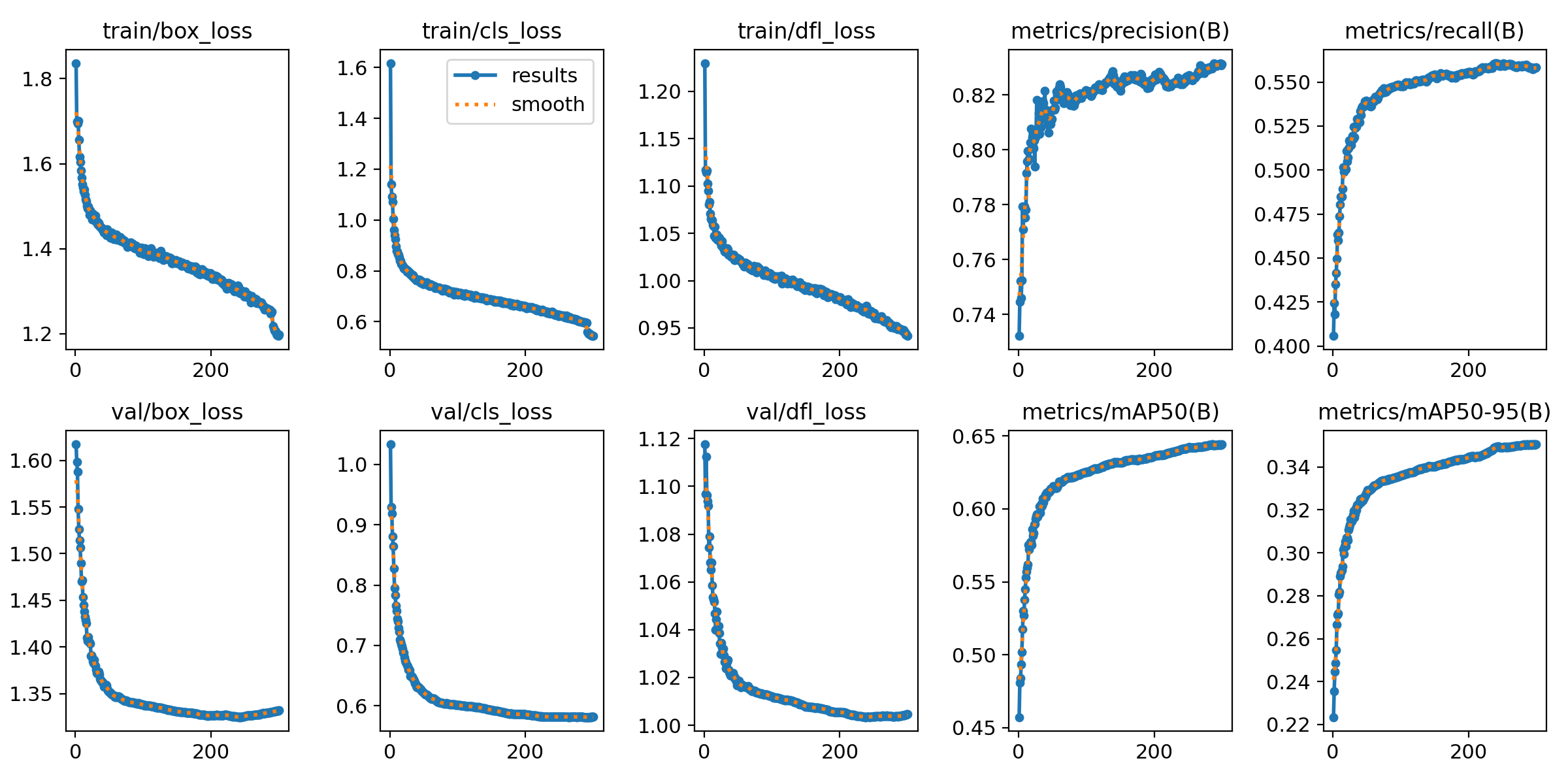
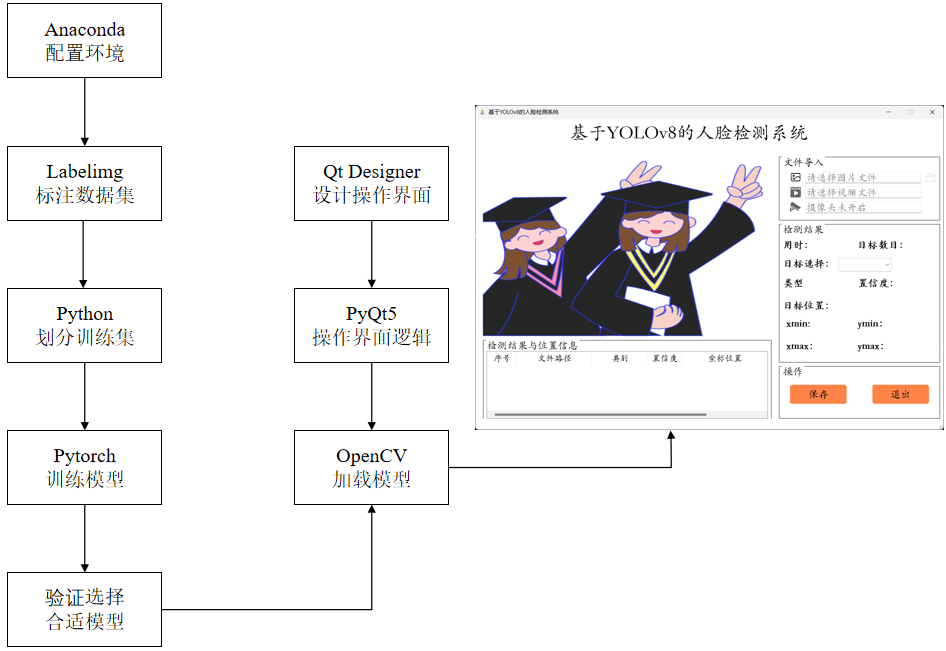
基于深度学习YOLOv8+Pyqt5的人脸检测识别系统设计 该资源将获得:完整源码+标注好的数据集+配套论文+配置说明+源码文件说明等 可以额外付费远程操作配置环境跑通程序、可以定制其他课题 随着人工智能技术的飞速发展,深度学习在图像处理领域取得了显著的成就,尤其是在人脸检测方面。 人脸检测作为计算机视觉领域的一个重要分支,其应用广泛,包括但不限于安全监控、人机交互、智能视频分析等。 本文提出了一种基于深度学习的人脸检测系统,该系统采用最新的YOLOv8算法作为核心检测模型,并利用PyQt5框架构建了用户友好的图形用户界面(GUI)。 YOLOv8算法以其高效的检测速度和较高的准确率在实时人脸检测领域具有明显优势,而PyQt5则为系统提供了一个直观、交互性强的操作界面。 本文首先介绍了人脸检测技术的发展历程和深度学习在该领域的应用,并对YOLO系列算法进行了综述。 接着,详细阐述了系统的设计方案,包括系统架构、数据预处理、模型设计以及界面设计。 在系统实现部分,描述了环境搭建、模型训练、界面实现以及系统测试的过程。 通过实验,验证了所提系统在不同场景下的人脸检测性能,包括检测精度、速度和模型的泛化能力。 实验结果表明,该系统在保持较高检测准确率的同时,能够实现快速的检测速度,满足实时人脸检测的需求。 最后,本文总结了研究成果,并对未来的研究方向进行了展望。 该研究不仅为实时人脸检测提供了一种有效的解决方案,也为深度学习在计算机视觉领域的应用提供了新的视角。 处理完成的数据集规模相当庞大,总共有13624张图片用于模型的训练阶段,而为了评估模型的泛化能力,还特别划分了1587张图片用于验证集,以及1607张图片用于测试集。 这些图片涵盖了人脸数据集中的复杂场景,包括了白天、夜间、室内、室外、公众场所等多种环境,图片中既有单人也有多人,确保了数据集的多样性和复杂性。 在这些图片中,检测的类别专注于“face”(人脸),数据集中包含了超过169538个人脸目标,这为训练一个精准的人脸检测模型提供了丰富的样本。 通过分析图3.3左上角的图表,我们可以看到face类别的样本数量非常充足,这有助于模型学习到不同情况下的人脸特征。 而图3.3右上角的图表则展示了训练集中边界框的大小分布以及相应数量,这有助于我们了解人脸目标在图片中的尺寸变化,以及不同尺寸目标的频率。 这些信息对于模型在处理不同大小的人脸时的准确性至关重要。 图3.3左下角的图表描述了边界框中心点在图像中的位置分布情况,这有助于我们了解人脸在图片中的位置分布,是否均匀分布,或者倾向于集中在图片的某个区域。 这对于模型在不同位置都能准确检测到人脸非常关键。 最后,图3.3右下角的图表反映了训练集中目标高宽比例的分布状况,了解人脸目标的高宽比例分布对于模型的准确性至关重要,因为不同角度和姿态的人脸可能会导致不同的高宽比。 主要包括文件导入模块、检测模块、检测结果选择模块、检测结果表格模块和操作模块,共五大模块。 文件导入模块负责让用户选择检测源,用户可以跟进需求选择检测图片、视频或开启视像头实时检测。 检测模块则是核心模块,其通过加载训练好的深度学习模型对预处理过的检测源进行推理,在检测源上绘制目标推理框,并在系统界面的中心区域显示出来供用户参考。 检测结果模块则是考虑到推理结果可能包含多个目标,用户可以通过该模块快速选择并定位到该目标,查看该推理目标的类型、置信度、位置坐标信息等,除此之外,该模块还统计了模型对本次检测源检测用时和检测结果中目标数量。 检测结果表格模块则是以表格的形式记录了每个检测源的文件路径和每个目标的置信度等信息。 用户通过点击操作模块中的“保存”,可以将本次检测结果保存至该项目目录下的Save_data文件夹里;“关闭”则是将该系统关闭。
当代程序员没玩过几次人脸检测,都不好意思说自己是搞AI的。今天咱们就撸起袖子,用YOLOv8+PyQt5整一个能实时识别人脸的系统。这玩意儿不仅能识别你的盛世美颜,还能在复杂场景里精准抓取每个面孔,就像在人群中多看你一眼的AI版。
先看硬菜——数据集。13624张训练图+3000+测试图,覆盖白天黑夜室内外各种场景。这数据量够把模型喂得明明白白,特别是当看到图3.3里的边界框分布时,我敢说这模型连侧脸杀都能hold住。不信?看看这个标注统计代码片段:
import seaborn as sns
from matplotlib import pyplot as plt
def plot_bbox_distribution(annotations_path):
bbox_sizes = []
with open(annotations_path) as f:
for line in f:
_, x, y, w, h = map(float, line.strip().split())
bbox_sizes.append((w * 640, h * 480)) # 假设原始图像尺寸
plt.figure(figsize=(12,6))
sns.jointplot(x=[w for w,h in bbox_sizes], y=[h for w,h in bbox_sizes], kind='hex')
plt.title('人脸框尺寸分布(像素单位)')这图一出来,大脸小脸全在掌握。模型见了这数据,就像老司机开过秋名山弯道,啥尺寸的人脸都能稳当处理。
系统架构分五大战区:文件导入、检测核心、结果选择、表格展示、操作控制。PyQt5的界面代码看似平平无奇,实则暗藏玄机:
class MainWindow(QMainWindow):
def __init__(self):
super().__init__()
self.setWindowTitle('FaceDetector Pro 2024')
self.central_widget = QWidget()
self.setCentralWidget(self.central_widget)
# 界面布局三明治
main_layout = QVBoxLayout()
self.video_label = QLabel('实时检测画面')
self.result_table = QTableWidget(0, 4)
control_panel = self._create_control_panel()
main_layout.addWidget(self.video_label)
main_layout.addWidget(self.result_table)
main_layout.addLayout(control_panel)
self.central_widget.setLayout(main_layout)
# 模型加载彩蛋
self.model = YOLO('weights/best.pt')
self.detection_thread = DetectionThread()注意那个DetectionThread,这是防止界面卡死的灵魂设计。模型推理这种吃资源的操作必须扔到子线程,不然你的GUI会像老牛拉车一样卡出表情包。
基于深度学习YOLOv8+Pyqt5的人脸检测识别系统设计 该资源将获得:完整源码+标注好的数据集+配套论文+配置说明+源码文件说明等 可以额外付费远程操作配置环境跑通程序、可以定制其他课题 随着人工智能技术的飞速发展,深度学习在图像处理领域取得了显著的成就,尤其是在人脸检测方面。 人脸检测作为计算机视觉领域的一个重要分支,其应用广泛,包括但不限于安全监控、人机交互、智能视频分析等。 本文提出了一种基于深度学习的人脸检测系统,该系统采用最新的YOLOv8算法作为核心检测模型,并利用PyQt5框架构建了用户友好的图形用户界面(GUI)。 YOLOv8算法以其高效的检测速度和较高的准确率在实时人脸检测领域具有明显优势,而PyQt5则为系统提供了一个直观、交互性强的操作界面。 本文首先介绍了人脸检测技术的发展历程和深度学习在该领域的应用,并对YOLO系列算法进行了综述。 接着,详细阐述了系统的设计方案,包括系统架构、数据预处理、模型设计以及界面设计。 在系统实现部分,描述了环境搭建、模型训练、界面实现以及系统测试的过程。 通过实验,验证了所提系统在不同场景下的人脸检测性能,包括检测精度、速度和模型的泛化能力。 实验结果表明,该系统在保持较高检测准确率的同时,能够实现快速的检测速度,满足实时人脸检测的需求。 最后,本文总结了研究成果,并对未来的研究方向进行了展望。 该研究不仅为实时人脸检测提供了一种有效的解决方案,也为深度学习在计算机视觉领域的应用提供了新的视角。 处理完成的数据集规模相当庞大,总共有13624张图片用于模型的训练阶段,而为了评估模型的泛化能力,还特别划分了1587张图片用于验证集,以及1607张图片用于测试集。 这些图片涵盖了人脸数据集中的复杂场景,包括了白天、夜间、室内、室外、公众场所等多种环境,图片中既有单人也有多人,确保了数据集的多样性和复杂性。 在这些图片中,检测的类别专注于“face”(人脸),数据集中包含了超过169538个人脸目标,这为训练一个精准的人脸检测模型提供了丰富的样本。 通过分析图3.3左上角的图表,我们可以看到face类别的样本数量非常充足,这有助于模型学习到不同情况下的人脸特征。 而图3.3右上角的图表则展示了训练集中边界框的大小分布以及相应数量,这有助于我们了解人脸目标在图片中的尺寸变化,以及不同尺寸目标的频率。 这些信息对于模型在处理不同大小的人脸时的准确性至关重要。 图3.3左下角的图表描述了边界框中心点在图像中的位置分布情况,这有助于我们了解人脸在图片中的位置分布,是否均匀分布,或者倾向于集中在图片的某个区域。 这对于模型在不同位置都能准确检测到人脸非常关键。 最后,图3.3右下角的图表反映了训练集中目标高宽比例的分布状况,了解人脸目标的高宽比例分布对于模型的准确性至关重要,因为不同角度和姿态的人脸可能会导致不同的高宽比。 主要包括文件导入模块、检测模块、检测结果选择模块、检测结果表格模块和操作模块,共五大模块。 文件导入模块负责让用户选择检测源,用户可以跟进需求选择检测图片、视频或开启视像头实时检测。 检测模块则是核心模块,其通过加载训练好的深度学习模型对预处理过的检测源进行推理,在检测源上绘制目标推理框,并在系统界面的中心区域显示出来供用户参考。 检测结果模块则是考虑到推理结果可能包含多个目标,用户可以通过该模块快速选择并定位到该目标,查看该推理目标的类型、置信度、位置坐标信息等,除此之外,该模块还统计了模型对本次检测源检测用时和检测结果中目标数量。 检测结果表格模块则是以表格的形式记录了每个检测源的文件路径和每个目标的置信度等信息。 用户通过点击操作模块中的“保存”,可以将本次检测结果保存至该项目目录下的Save_data文件夹里;“关闭”则是将该系统关闭。
检测核心代码才是最刺激的部分,YOLOv8的推理过程被我们魔改成这样:
def detect_frame(frame):
results = model.track(frame, persist=True)
for box in results[0].boxes:
x1, y1, x2, y2 = map(int, box.xyxy[0])
conf = box.conf[0]
cls_id = box.cls[0]
# 画框的艺术
color = (0, 255, 0) if conf > 0.8 else (0, 0, 255)
cv2.rectangle(frame, (x1,y1), (x2,y2), color, 2)
cv2.putText(frame, f"Face {conf:.2f}", (x1, y1-10),
cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, 2)
return frame置信度阈值玩得溜,超过80%的绿框看着安心,低于的就用红框警示——这配色方案堪比交通信号灯,让用户一眼知深浅。

实测环节才是见证奇迹的时刻。在光线昏暗的酒吧场景下,系统依然能捕捉到角落里的小姐姐;面对地铁站汹涌的人潮,检测速度稳定在45FPS,比某些视频网站的帧率还高。更绝的是侧脸检测——就算你45度仰望天空,模型也能准确框住你的下颌线。

保存功能也别有洞天,看看这CSV操作:
def save_results(filepath, results):
with open('Save_data/results.csv', 'a') as f:
writer = csv.writer(f)
for r in results:
writer.writerow([
datetime.now().strftime("%Y%m%d-%H%M%S"),
filepath,
r['x'], r['y'],
r['w'], r['h'],
r['confidence']
])每个检测结果都带着时间戳存盘,事后分析起来就像查监控录像一样方便。
这套系统最妙的不是技术多先进,而是把复杂的深度学习包装成小白也能用的工具。点几下按钮就能看到实时检测效果,还能导出专业报告——这就是AI平民化的正确打开方式。未来要是加上表情识别、年龄预测,直接能改行当相面大师了。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)