Flink集群启动失败完整排查过程(含踩坑与解决方案)
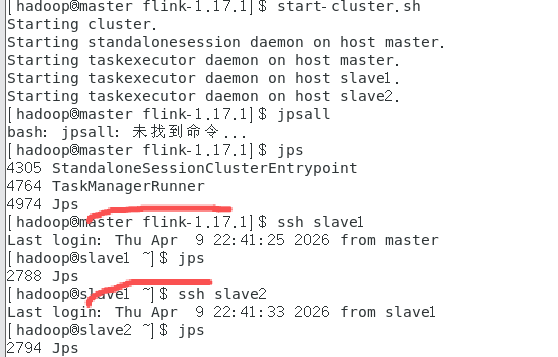
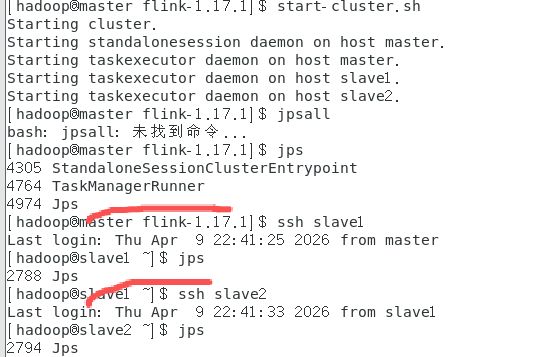
问题现象:执行start-cluster.sh后,控制台提示“Starting taskexecutor daemon on host slave1/slave2”,但登录slave1、slave2执行jps,仅能看到Jps进程,无TaskManagerRunner(TaskManager启动后秒退);但确认“架构修改”本身逻辑正确,排除架构冲突导致问题。3.slave1、slave2节点的fli
一、问题背景与初始现象
环境:3台节点(master、slave1、slave2),Flink 1.17.1,已配置SSH免密登录、hosts映射、Java环境(JDK1.8),防火墙已关闭,所有节点文件(masters、workers、flink-conf.yaml)已同步。
初始配置:
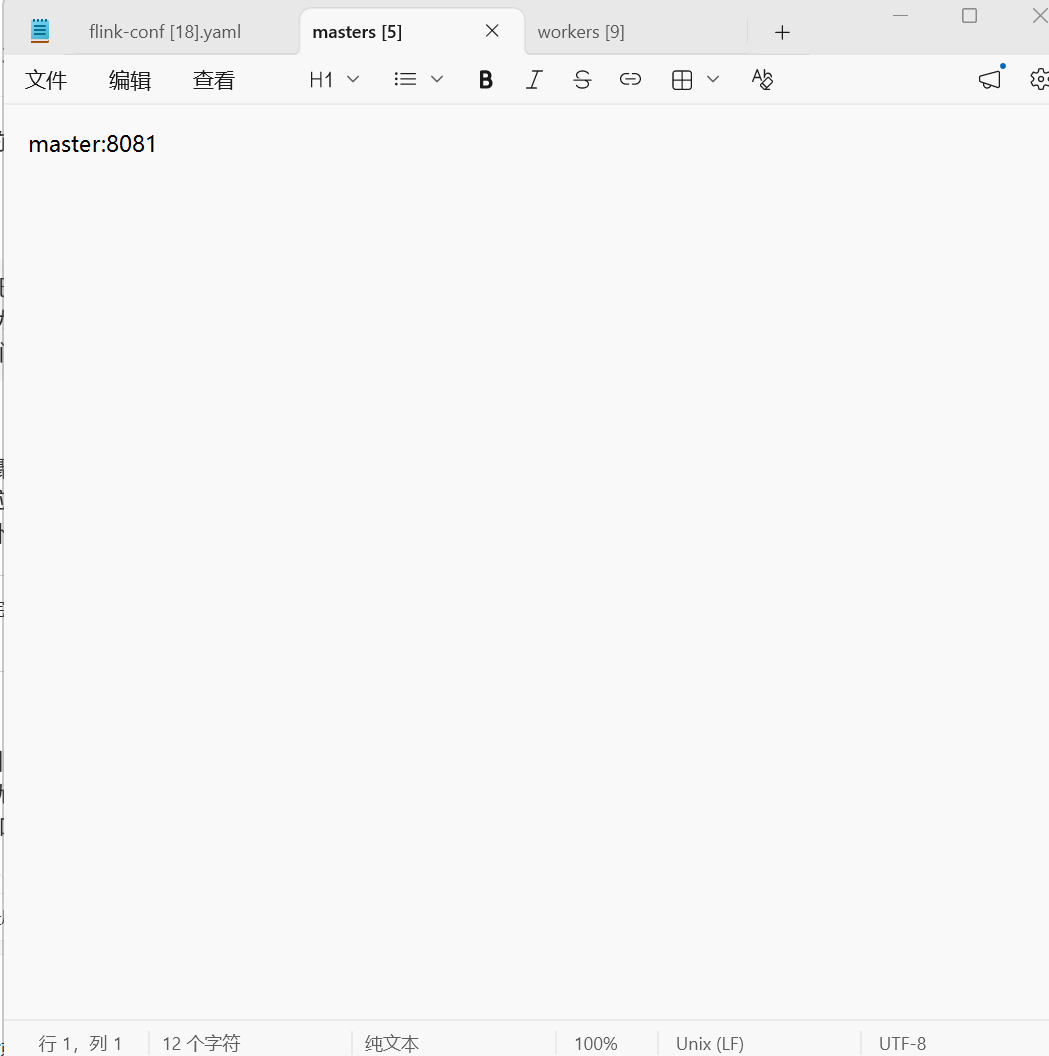
•masters文件:master:8081(三台节点一致)
•workers文件:master、slave1、slave2(三台节点一致)
•master节点flink-conf.yaml:taskmanager.host: master(未注释)
•slave1节点flink-conf.yaml:taskmanager.host: slave1
•slave2节点flink-conf.yaml:taskmanager.host: slave2
问题现象:执行start-cluster.sh后,控制台提示“Starting taskexecutor daemon on host slave1/slave2”,但登录slave1、slave2执行jps,仅能看到Jps进程,无TaskManagerRunner(TaskManager启动后秒退);master节点jps,StandaloneSessionClusterEntrypoint(JobManager)和TaskManagerRunner,但slave节点始终无TaskManager。如图
二、完整排查过程(含所有尝试,不分有效/无效)
排查步骤1:检查配置文件一致性(无效排查,配置无问题)
怀疑是masters、workers、flink-conf.yaml文件同步不彻底,或配置写错,执行以下操作:
1.在master节点查看并重新同步配置文件:
# 查看master节点配置
可以使用cat /opt/module/flink-1.17.1/conf/masters,查看主要要改成你自己的路径
可以执行cat /opt/module/flink-1.17.1/conf/workers查看,我的更习惯直接在文本编辑器里看
cat /opt/module/flink-1.17.1/conf/flink-conf.yaml | grep -E "taskmanager.host|jobmanager.rpc.address"
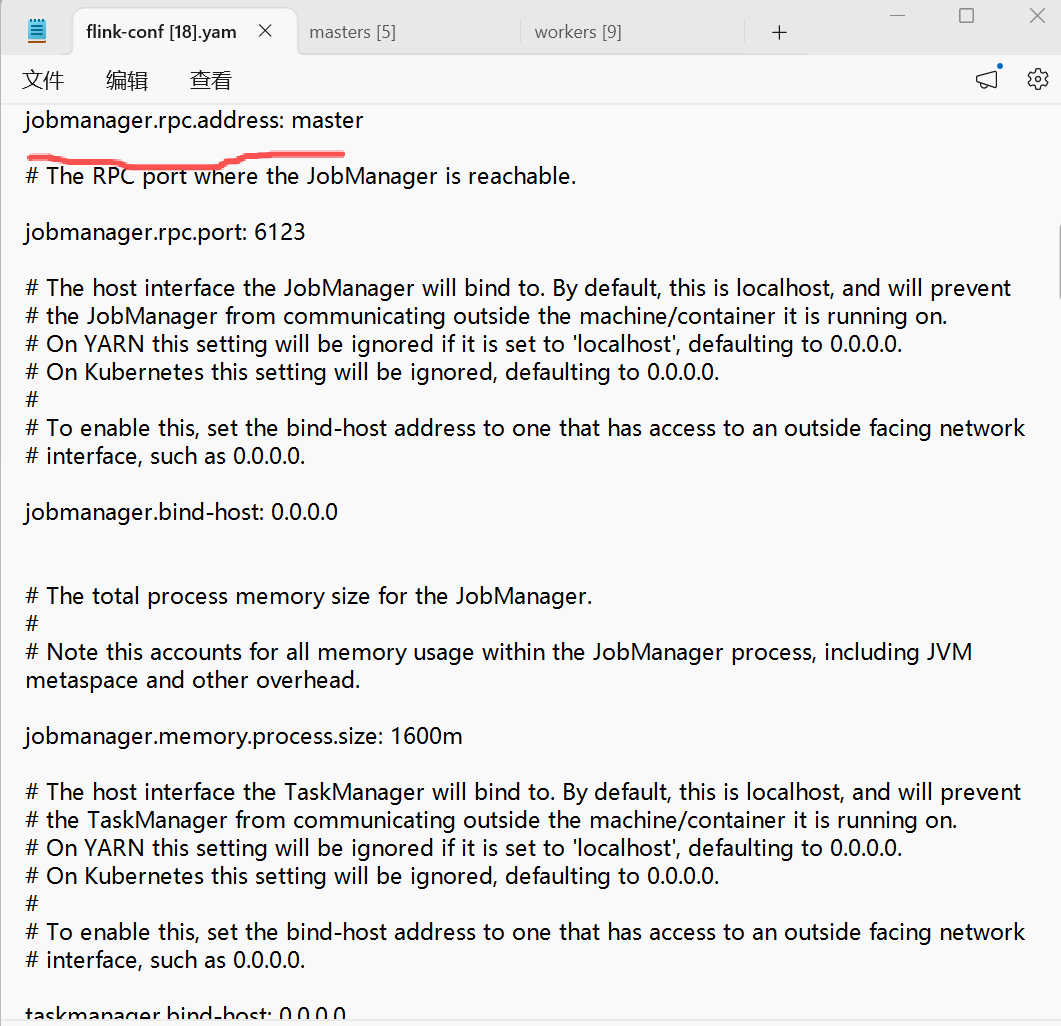
发现并没有什么问题
# 重新同步到slave1、slave2
scp /opt/module/flink-1.17.1/conf/* slave1:/opt/module/flink-1.17.1/conf/
scp /opt/module/flink-1.17.1/conf/* slave2:/opt/module/flink-1.17.1/conf/
2.验证slave1、slave2配置文件,确认与master一致,无拼写错误(如端口、主机名)。
结果!:配置文件完全一致,无错误,但slave节点TaskManager仍秒退,排查无效。
排查步骤2:怀疑配置架构存在冲突,修改集群架构推测“master既当JobManager又当TaskManager”可能导致端口、资源冲突,尝试修改为“master仅当JobManager,slave1、slave2仅当TaskManager”,操作如下:
1.修改所有节点的workers文件,删除master,仅保留slave1、slave2:
vim /opt/module/flink-1.17.1/conf/workers
 2.修改master节点的flink-conf.yaml,注释taskmanager.host: master(避免master启动TaskManager):
2.修改master节点的flink-conf.yaml,注释taskmanager.host: master(避免master启动TaskManager):
# taskmanager.host: master # 注释此行
 3.slave1、slave2节点的flink-conf.yaml保持不变(taskmanager.host分别为slave1、slave2)。
3.slave1、slave2节点的flink-conf.yaml保持不变(taskmanager.host分别为slave1、slave2)。
4.重启集群:
stop-cluster.sh
start-cluster.sh
结果:启动提示正常,但slave1、slave2节点jps仍无TaskManagerRunner,问题未解决;但确认“架构修改”本身逻辑正确,排除架构冲突导致问题。
排查步骤3:怀疑端口配置错误(无效排查,端口无问题)
偶然怀疑masters文件中端口写错(误将8081写为9092,9092为Kafka端口),执行以下检查:
1.查看masters文件,确认端口为8081(Flink默认Web UI/JobManager端口):
cat /opt/module/flink-1.17.1/conf/masters # 输出:master:8081
2.检查master节点8081端口是否被占用:
netstat -tulpn | grep 8081
# 无占用,JobManager正常监听
结果:端口配置正确,无占用,排查无效。
排查步骤4:测试远程启动TaskManager,定位启动失败原因(关键有效排查)
由于slave节点无日志生成(启动秒退,未生成日志文件),直接在master节点远程执行TaskManager前台启动命令,强制打印报错信息:
bash
ssh slave1 "/opt/module/flink-1.17.1/bin/taskmanager.sh start-foreground"
输出核心报错(红字):
2026-04-11 07:52:38,003 main ERROR Unable to create file /opt/module/flink-1.17.1/log/flink-hadoop-taskexecutor-0-slave1.log java.io.IOException: 权限不够
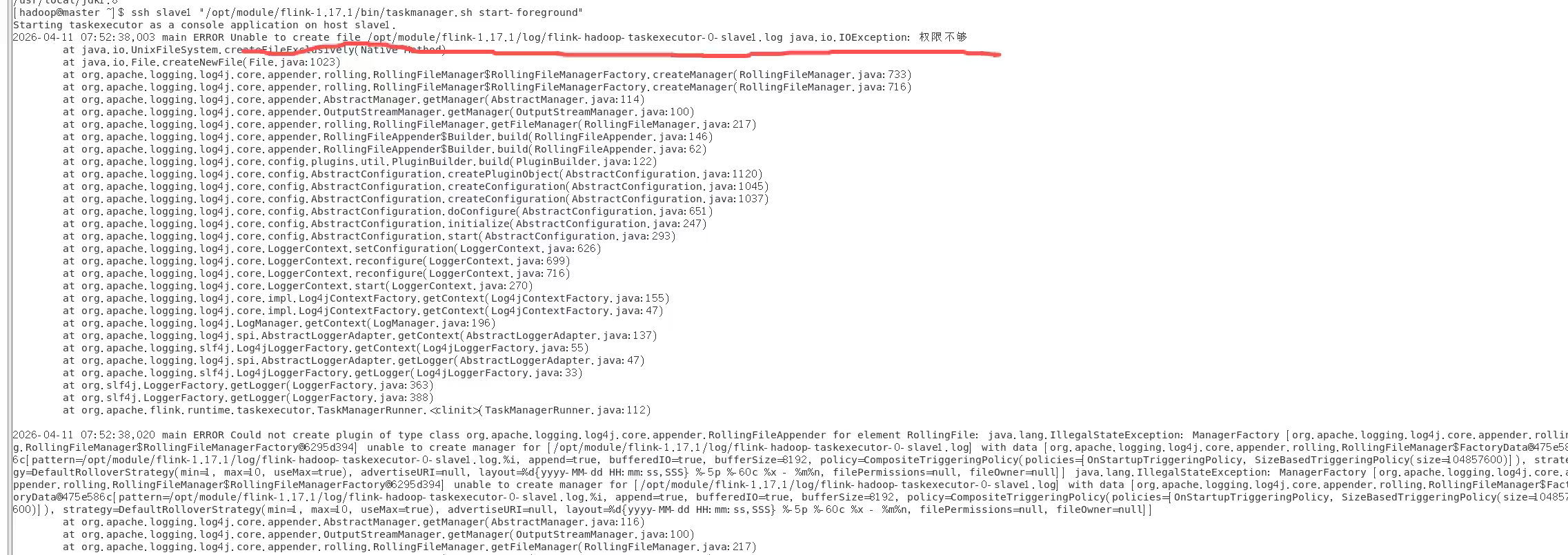
结果:明确根因——slave节点Flink日志目录权限不足,hadoop用户无法创建日志文件,导致TaskManager启动后立即退出。故可以配置权限
排查步骤5:验证Java环境远程可用性(辅助排查,排除Java问题,在三个的配置文件里面都看一下)
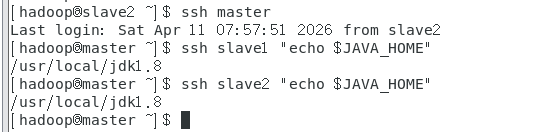
补充排查:怀疑远程SSH调用时Java环境变量失效(本地能找到Java,远程找不到),执行测试:
bash
ssh slave1 "echo \$JAVA_HOME" # 输出:/usr/local/jdk1.8
结果:Java环境变量远程正常,排除Java环境导致的启动失败。
总结:授权日志目录权限,最终解决问题(有效排查,彻底解决)
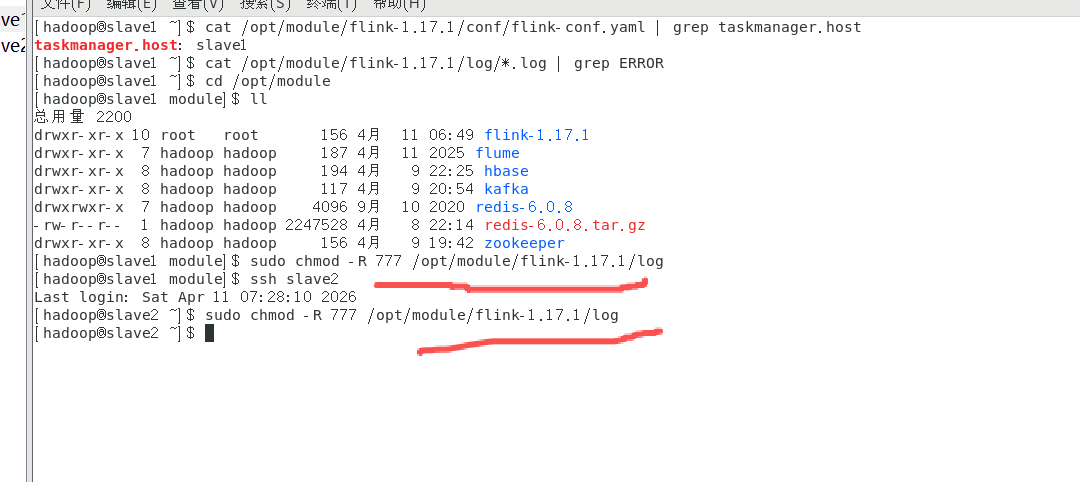
根据步骤4的报错,确认日志目录权限不足,执行授权操作(因上级目录已为hadoop用户,直接授权log目录即可):
1.在slave1、slave2节点分别授权:
chmod -R 755 /opt/module/flink-1.17.1/log
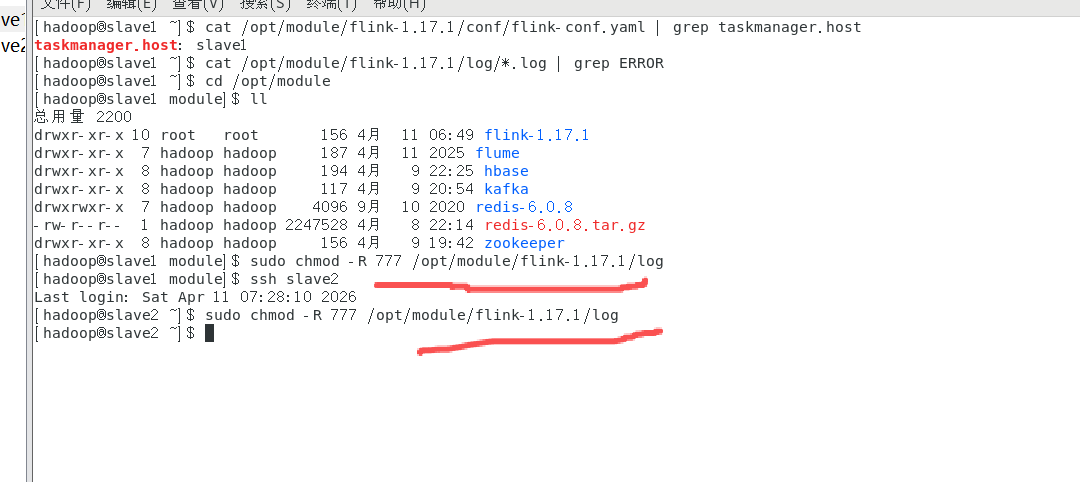
2.(可选)为确保所有节点权限一致,master节点也执行上述授权命令。
3.重启集群: stop-cluster.sh和start-cluster.sh
结果:启动成功,slave1、slave2节点jps能看到TaskManagerRunner,且常驻不退出。
步骤6:还原原版配置,验证可用性(补充排查,确认环境正常)
解决问题后,还原为老师的初始配置,验证环境是否完全正常:
1.修改所有节点的workers文件,恢复为:
master
slave1
slave2
2.修改master节点的flink-conf.yaml,取消taskmanager.host: master的注释:
taskmanager.host: master # 取消注释
3.重启集群,执行jps验证:start-cluster.sh
# 分别在master、slave1、slave2执行jps
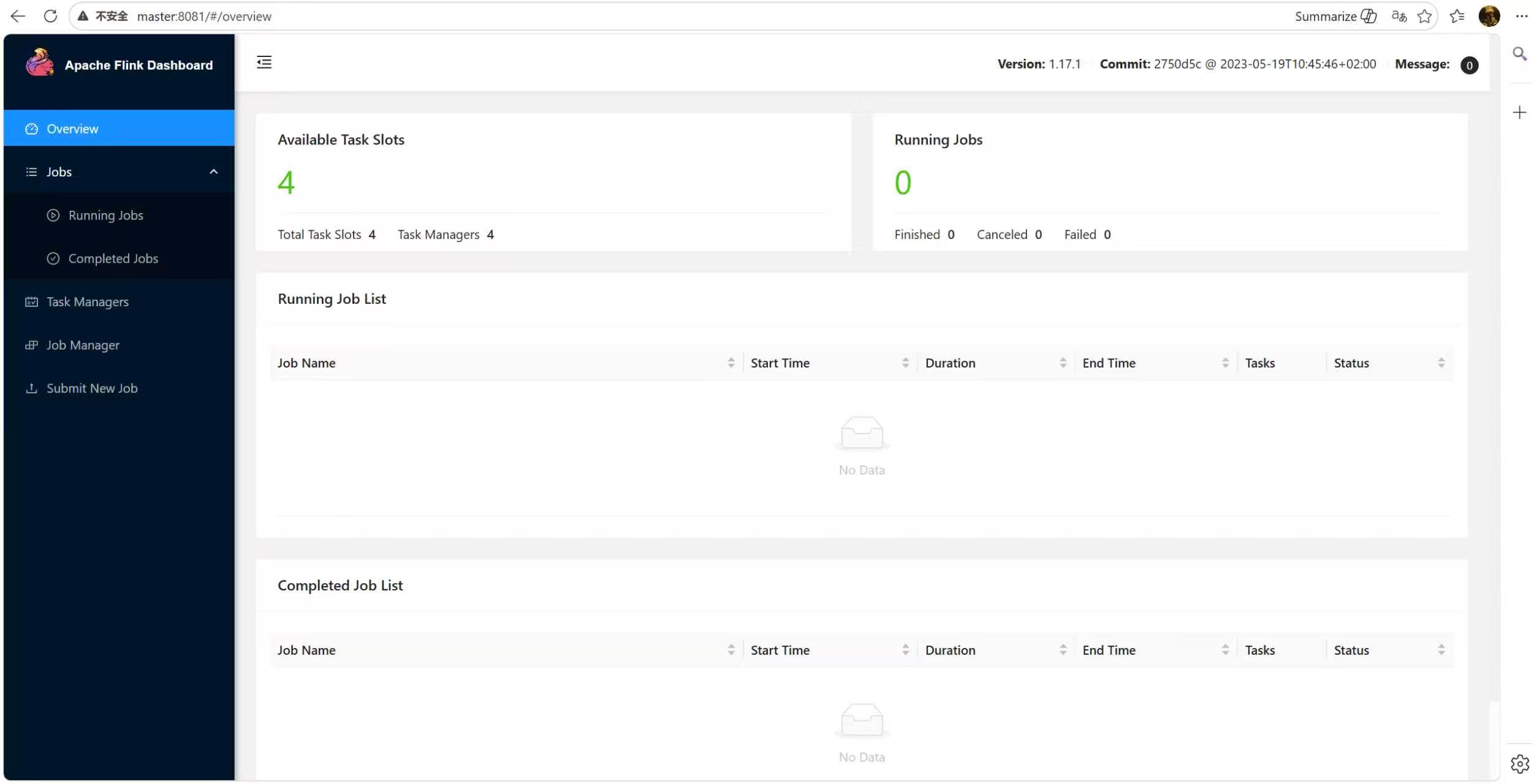
结果:所有节点均正常启动——master有JobManager+2个TaskManager,slave1、slave2各有1个TaskManager,原版配置也能完美运行最后发现web也可以访问
三、排查总结与根因分析
1. 核心根因
本次Flink集群启动失败的唯一原因:/opt/module/flink-1.17.1/log目录权限不足,hadoop用户无法创建日志文件,导致TaskManager启动后因无法写入日志而立即退出。
2. 所有排查结论(含踩坑)
•配置文件无错误(masters、workers、flink-conf.yaml同步正常,无拼写、端口错误);
•网络、SSH、hosts映射、防火墙均正常(排除远程连接问题);
•Java环境正常(本地、远程均能正常识别,排除环境变量失效问题);
•老师的“master兼任JobManager+TaskManager”架构本身无错误,仅因权限问题导致之前无法运行;
•“master仅当JobManager,slave仅当TaskManager”的架构更稳定,适合自建集群,且配置逻辑正确;
•权限问题解决后,两种架构(老师配置、自建配置)均能正常运行。
3. 最终解决方案
给Flink日志目录授权(所有节点执行,或仅slave节点执行):
chmod -R 755 /opt/module/flink-1.17.1/log
重启集群后,TaskManager即可正常启动并常驻。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)