python基础语法-1
cf2
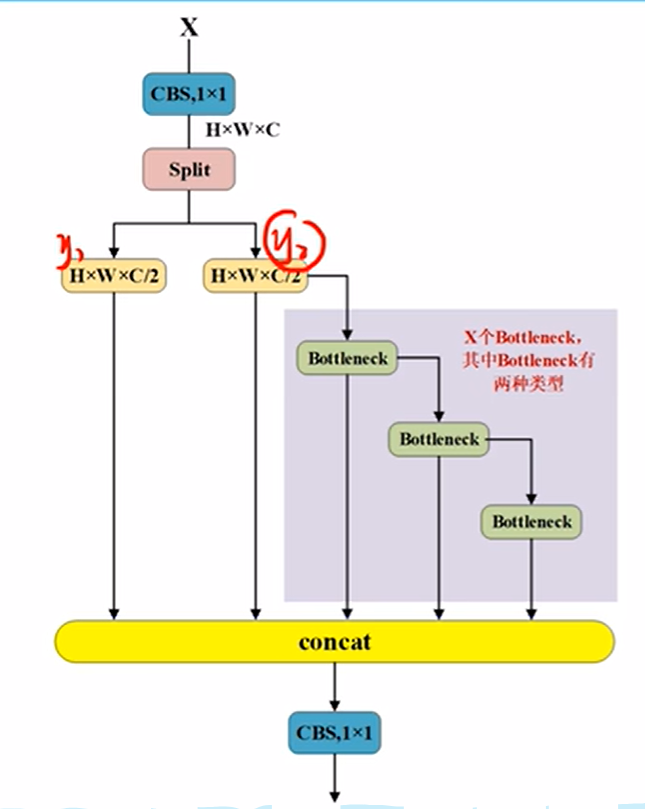
class C2f(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))一、 for _ in range(n)是从0到n-1吗? self.m = nn.ModuleList(Bottleneck(...) for _ in range(n))对象加入nn.ModuleList吗?
==》
1、range(n) 在 Python 中是从 0 开始到 n-1 结束的整数序列,所以这个循环会执行 n 次,最终创建 n 个 Bottleneck 对象;_ 是一个占位符变量,表示我们不关心循环变量的具体值,只需要执行 n 次循环。
2、Bottleneck(...) for _ in range(n) 是一个生成器表达式,会逐个创建 Bottleneck 实例,nn.ModuleList() 会把这些生成的 Bottleneck 对象全部加入到这个列表中。
二、y = list(self.cv1(x).chunk(2, 1)) 讲解一下这里的chunk(2,1)
1)前置条件:self.cv1(x) 输出的张量形状通常是 [batch_size, 2*self.c, height, width](比如 batch=4,2*self.c=128,高宽 = 64,则形状是 [4, 128, 64, 64])。
2)chunk(2, 1) 的含义:
第一个参数 2:表示要把张量均分成 2 份;
第二个参数 1:表示沿着第 1 个维度(通道维度,PyTorch 张量维度索引从 0 开始:0=batch,1=channel,2=height,3=width)切分。
执行结果:
上面的例子中,[4, 128, 64, 64] 会被切成两个张量:[4, 64, 64, 64] 和 [4, 64, 64, 64],再用 list() 转换成列表 y = [张量1, 张量2]。
执行结果:
上面的例子中,[4, 128, 64, 64] 会被切成两个张量:[4, 64, 64, 64] 和 [4, 64, 64, 64],再用 list() 转换成列表 y = [张量1, 张量2]。
三、 y.extend(m(y[-1]) for m in self.m) 这里的extend是指什么意思? m(y[-1])表示什么?
1、extend的含义:
Python 列表的 extend() 方法是把可迭代对象中的元素逐个添加到列表末尾(区别于 append():append 是把整个对象作为一个元素添加)。比如 y = [1,2],y.extend([3,4]) 后 y 变成 [1,2,3,4],而 y.append([3,4]) 会变成 [1,2,[3,4]]。
2、m(y[-1]) 的含义:
self.m 是存放 n 个 Bottleneck 模块的 nn.ModuleList,m 就是其中一个 Bottleneck 实例;
y[-1] 是列表 y 的最后一个元素(也就是前面 chunk 切分后的第二个张量);
m(y[-1]) 就是把 y 的最后一个张量输入到当前这个 Bottleneck 模块中,执行前向传播,得到输出张量。
3、整行代码的效果:
遍历 self.m 中的每一个 Bottleneck,依次用 y 的最后一个元素作为输入,把每个 Bottleneck 的输出逐个添加到 y 列表末尾。比如 n=2 时,初始 y = [张量1, 张量2],执行后会变成 [张量1, 张量2, Bottleneck1(张量2), Bottleneck2(Bottleneck1(张量2))]。
四、torch.cat(y, 1) 这里的y是一个列表,然后按照第1个维度进行拼接吗?
y 是包含多个张量的列表(比如 n=2 时,y 有 4 个张量:初始切分的 2 个 + 2 个 Bottleneck 输出);
第二个参数 1:表示沿着第 1 个维度(通道维度) 拼接(不是 “第一个维度”(注意维度索引从 0 开始)
举例:
假设 y 中的每个张量形状都是 [4, 64, 64, 64],共 4 个张量,拼接后形状变成 [4, 64*4=256, 64, 64],正好匹配后续 self.cv2 的输入通道数 (2 + n) * self.c(n=2 时,(2+2)*64=256)。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)