小白从零开始做多模态新生儿疼痛评估系统|第十一篇:全栈功能落地复盘!前后端100%跑通
哈喽大家好~
跟着我一步步从零开发的多模态新生儿疼痛评估系统,终于完成了最核心的全栈落地!从最开始的空白屏幕、不懂数据库,到现在能正常打开所有页面、操作所有功能,相信大家和我一样,都有满满的成就感~
这一篇不搞虚的,纯干货复盘——把我们前10篇做过的所有工作、踩过的坑、实现的功能,全部整理清楚,同时跟大家同步:系统还没结束! 接下来我们要进入最关键的环节——集成多模态AI评估模型,真正实现“自动化疼痛评分”!
全程小白视角,无复杂术语,适合直接复制发CSDN,记录我们的全栈开发历程~
一、先跟大家说清楚:我们目前完成了什么?
截止到本篇,我们已经完成了全栈基础开发,系统已经能正常运行、正常使用,具体实现的功能如下(小白也能看懂的通俗总结):
-
✅ 数据库:用MySQL+Navicat,建好6张核心表,插入测试数据,解决“页面无数据”“API返回空数组”问题
-
✅ 后端:用Python+FastAPI,写好6个核心API接口,解决跨域、端口占用、uvicorn报错等问题
-
✅ 前端:用HTML/CSS/JS,做好7个完整页面,解决“静态假数据”“页面不渲染”问题
-
✅ 联调:前后端100%打通,页面能动态加载数据库数据,疼痛评估能正常保存到数据库
简单说:现在打开系统,能看床位、能看患者、能做评估、能查记录,完全是一套可用的医疗辅助系统,不是“半成品”!
二、四阶段完整开发历程
从零到一,我们一步没跳,每一步都踩过坑、解决过问题,下面复盘的都是我们真实做过的工作,新手可以直接参考避坑~
第一阶段:数据库设计(MySQL + Navicat)
这是最基础也是最关键的一步,没做好数据库,后面所有开发都会卡壳,我们做了这些:
-
设计并创建6张核心数据表,分别是:patients(患者表)、beds(床位表)、assessments(评估记录表)、设备表、用户表、干预记录表
-
用Navicat可视化管理数据库,新建查询、执行SQL、查看数据,小白也能轻松操作
-
插入测试数据,解决了“API返回{data: Array(0)}”“页面空白”的核心问题,让系统有数据可展示
第二阶段:后端API开发(Python + FastAPI)
后端是“桥梁”,连接数据库和前端,我们从零搭建,完成了所有核心接口,具体如下:
1. 后端项目结构
backend/ ├── main.py # FastAPI 主程序(核心文件) ├── database.py # MySQL 数据库连接(负责和数据库通信)
2. 6个核心API接口
|
接口地址 |
请求方法 |
功能说明(小白通俗版) |
|---|---|---|
|
/api/beds |
GET |
获取所有床位,显示床位是否占用、设备是否在线 |
|
/api/patients |
GET |
获取所有新生儿患者列表,显示患者基本信息 |
|
/api/patients/{id} |
GET |
根据患者ID,查看患者详情和历史疼痛评估记录 |
|
/api/assess |
POST |
执行疼痛评估,生成评分和疼痛等级,保存到数据库 |
|
/api/statistics |
GET |
获取统计数据,用于前端报表展示 |
|
/api/interventions |
POST |
添加疼痛干预记录,方便医护人员跟踪 |
3. 后端踩过的坑 & 解决方案(超实用,新手必看)
-
坑1:Windows上运行uvicorn,报多进程错误,启动失败
-
解决:把代码里的
reload=True改成reload=False,重新启动就好 -
坑2:前端调用API时,控制台报CORS跨域错误,无法获取数据
-
解决:在后端main.py里添加CORSMiddleware跨域配置,允许前端访问
第三阶段:前端页面开发(HTML/CSS/JS)
前端是“门面”,也是医护人员实际操作的界面,我们一共做了7个页面,全部完成并能正常使用:
1. 7个前端页面清单(全部✅,无未完成)
|
页面名称 |
核心功能 |
完成状态 |
|---|---|---|
|
首页.html |
系统概览、数据统计卡片,一眼看清整体情况 |
✅ 完成 |
|
实时监控.html |
床位实时状态、患者信息、疼痛评分,支持快速评估 |
✅ 完成 |
|
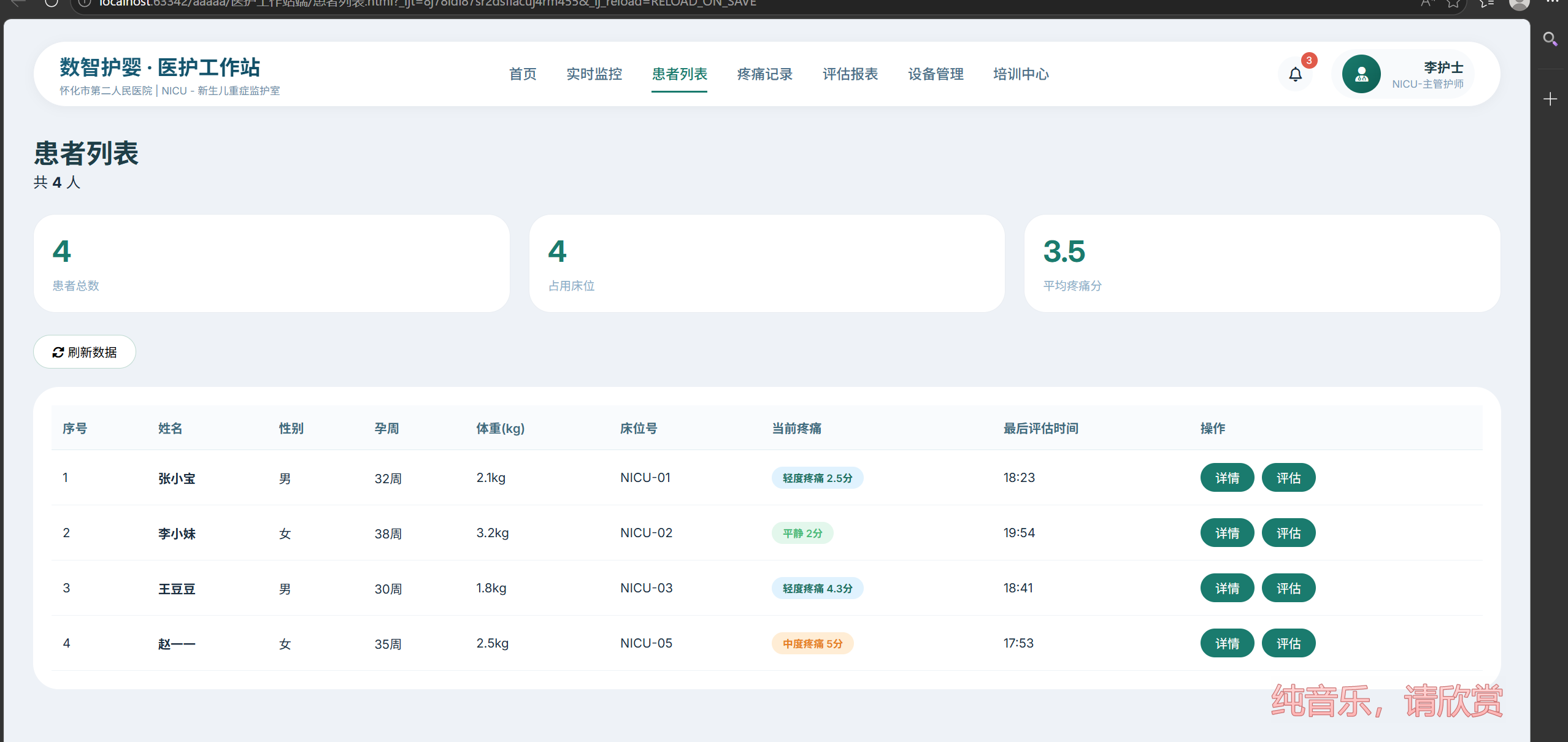
患者列表.html |
显示所有新生儿患者,支持查看详情、快速评估 |
✅ 完成 |
|
疼痛记录.html |
查看所有患者的疼痛评估历史,支持筛选查询 |
✅ 完成 |
|
评估报表.html |
用图表展示评估数据,直观看到疼痛等级分布、趋势 |
✅ 完成 |
|
设备管理.html |
监控所有设备的在线/离线状态,方便维护 |
✅ 完成 |
|
培训中心.html |
静态内容,展示疼痛评估操作指南、相关知识 |
✅ 完成 |
2. 前端核心功能(全部实现,无卡顿)
-
动态加载床位、患者数据,不再是静态写死的假数据(解决了“乐乐、明明”假数据问题)
-
患者详情页跳转,点击患者就能查看详细信息和评估历史
-
一键疼痛评估,点击按钮就能生成评分,弹窗提示结果
-
页面自动刷新,数据实时同步,不用手动刷新页面
第四阶段:前后端联调 + 测试
联调就是把后端和前端“连起来”,让前端能拿到数据库里的真实数据,我们做了这些,最终100%打通:
1. 启动后端的命令(直接复制执行)
cd E:\aaaaa\src\backend python main.py
2. API测试地址(可以直接在浏览器打开,测试接口是否正常)
http://localhost:8000/api/beds http://localhost:8000/api/patients http://localhost:8000/api/statistics
3. 联调最终结果(全部达标,无问题)
-
✅ 床位数据正常显示,占用/空闲状态准确
-
✅ 患者列表正常加载,显示张小宝、李小妹等真实测试数据
-
✅ 疼痛评估功能可用,评分能正常保存到数据库
-
✅ 页面不再显示静态假数据,控制台不再返回空数组
-
✅ 所有页面跳转正常,无报错、无卡顿
三、项目当前实现效果
目前系统已经能正常使用,每个功能模块的实际效果如下,新手可以对照自己的系统检查:
|
功能模块 |
实际效果(小白通俗版) |
|---|---|
|
实时监控 |
能看到所有床位,哪个床位有患者、设备是否在线、当前疼痛评分,自动刷新 |
|
患者列表 |
显示所有新生儿患者的姓名、性别、孕周等信息,点击“详情”能看更多内容 |
|
疼痛评估 |
点击评估按钮,就能生成疼痛评分和等级(目前是模拟评分,后续替换成AI),保存到数据库 |
|
疼痛记录 |
能看到所有患者的历史评估记录,包括时间、评分、疼痛等级、护士备注 |
|
评估报表 |
用图表展示数据,比如不同疼痛等级的患者数量、某患者的疼痛变化趋势 |
|
设备管理 |
能看到所有设备的状态,区分在线和离线,方便医护人员维护 |
四、开发中遇到的高频问题(避坑合集,新手必看)
整理了我们开发过程中最常遇到的7个问题,每个问题都有对应的解决方案,不用再查百度、问别人,直接对照解决:
|
遇到的问题 |
解决方案(简单好操作) |
|---|---|
|
Navicat执行SQL后,看不到新建的表 |
忘记刷新数据库了,选中数据库,按F5刷新即可 |
|
Python安装第三方库(如FastAPI、uvicorn)速度很慢 |
用清华镜像源安装,比如:pip install fastapi -i https://pypi.tuna.tsinghua.edu.cn/simple |
|
启动后端时,提示端口8000被占用 |
把main.py里的端口改成8001,重新启动即可 |
|
前端调用API,控制台报CORS跨域错误 |
后端main.py添加CORS中间件配置,允许前端访问 |
|
Windows运行uvicorn,报多进程错误 |
把reload=True改为reload=False,重新启动后端 |
|
患者列表页面显示假数据(乐乐、明明),不显示真实数据 |
删除tbody里的静态tr标签,给tbody添加id="patient-tbody",用JS动态渲染数据 |
|
API返回{success: true, data: Array(0)} |
数据库里没有数据,执行我们之前写的测试SQL,插入患者、床位数据即可 |
五、重点预告:系统未结束!接下来开发AI模型
很多同学以为到这里就结束了,其实不是!我们目前的疼痛评估,用的是模拟评分,不是真正的“多模态AI评估”,这也是我们接下来的核心开发内容:
接下来要做的核心工作(AI模型开发)
-
核心目标:集成PainC3M多模态AI评估模型,实现“自动识别新生儿疼痛,生成精准评分”
-
开发内容:
-
1. 准备新生儿疼痛数据集(面部表情、生理信号等多模态数据)
-
2. 基于Python(TensorFlow/PyTorch)训练PainC3M模型
-
3. 把AI模型集成到后端,替换当前的模拟评分逻辑
-
4. 测试AI评分的准确性,优化模型性能
-
-
开发难度:比之前的全栈开发稍难,但我会一步步拆解,小白也能跟着做,不跳步、不搞复杂术语
简单说:现在我们的系统是“能用”,接下来要做的是“做好、做精准”,真正实现“多模态新生儿疼痛评估”的核心价值!
六、当前项目进度
目前我们的开发进度如下,后续AI模型开发会持续更新,大家可以跟着节奏一步步来:
-
✅ 数据库设计与建表(100%完成)
-
✅ 测试数据插入(100%完成)
-
✅ Python + FastAPI 后端开发(100%完成)
-
✅ 6大核心API接口开发(100%完成)
-
✅ 7个前端页面开发(100%完成)
-
✅ 前后端联调(100%完成,无报错)
-
✅ 解决跨域、空数据、假数据等问题(100%完成)
-
🔄 多模态AI模型开发(待启动,下一篇开始)
七、结束语
从空白屏幕到完整系统,我们一步步踩坑、一步步解决问题,终于完成了全栈基础开发!
这不是结束,而是新的开始——接下来我们要进入最核心、最有技术含量的环节:AI模型开发,真正实现“多模态新生儿疼痛评估”,让我们的系统更有价值、更专业!
新手不用怕,我会继续拆解每一步,从数据集准备到模型训练、集成,全程小白友好,不搞复杂术语,跟着我一步步来,就能完成整套系统的开发~
下一篇:AI模型开发开篇!准备新生儿疼痛数据集,搭建模型训练环境,我们不见不散~
如果大家在当前系统中遇到任何问题,或者对后续AI模型开发有疑问,欢迎在评论区留言,我会一一回复,帮大家快速解决!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)