Kubernetes 进阶学习指南
本文介绍了 Kubernetes(K8s)的核心运维工具与最佳实践,涵盖以下关键内容: Helm:K8s包管理器,通过Chart打包应用资源,支持一键部署、升级和回滚。 RBAC:基于角色的权限控制,定义用户/服务账号对资源的操作权限。 GitOps/ArgoCD:实现持续交付,通过Git仓库管理配置变更。 可观测性:监控、日志和链路追踪确保系统透明性。 NetworkPolicy:网络隔离策略,
目录
- Helm —— K8s 包管理器
- RBAC 权限控制
- GitOps / ArgoCD 持续交付
- 可观测性:监控 + 日志 + 链路追踪
- NetworkPolicy 网络隔离
- Operator 模式
- 多集群与多租户
- 性能调优与资源管理
- 生产安全加固
- 学习资源与路线图
一、Helm —— K8s 包管理器
1.1 为什么需要 Helm?
部署一个生产级应用往往需要十几个 YAML 文件(Deployment、Service、Ingress、ConfigMap、Secret、HPA……),Helm 将这些打包为一个 Chart,一条命令完成部署。
Helm 是 K8s 的"apt/npm",用 Chart 打包一套完整应用的所有 K8s 资源: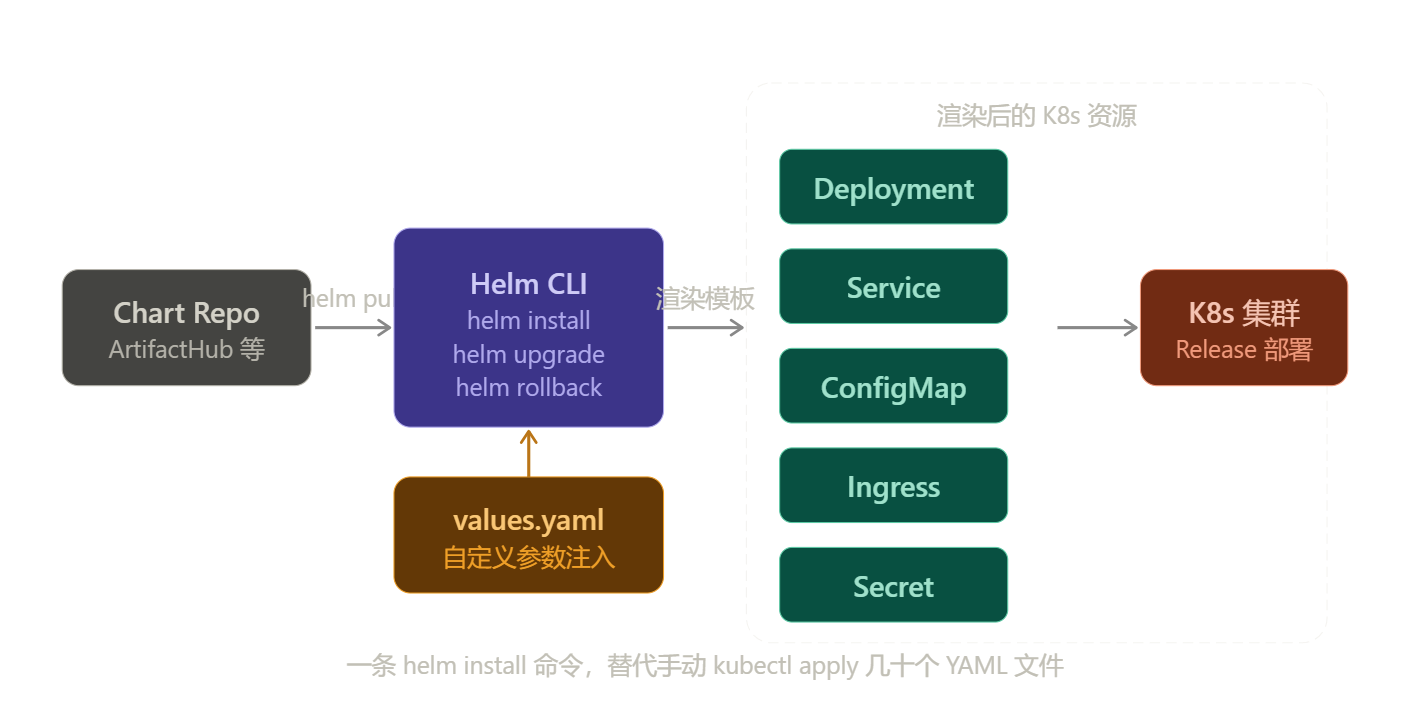
架构流程:
Chart Repo ──helm pull──→ Helm CLI ←── values.yaml(自定义参数)
│
渲染模板(Go Template)
│
┌─────────┴──────────┐
↓ ↓
K8s 资源清单 Release 记录
(Deployment/Service/ (版本历史,
Ingress/ConfigMap…) 支持回滚)
│
kubectl apply
│
K8s 集群
1.2 核心概念
| 概念 | 说明 |
|---|---|
Chart |
应用的打包单元,包含模板 + 默认值 |
Release |
Chart 在集群中的一次部署实例 |
Repository |
存储 Chart 的仓库 |
values.yaml |
默认配置值,可在安装时覆盖 |
1.3 Chart 目录结构
mychart/
├── Chart.yaml # Chart 元数据(名称、版本、描述)
├── values.yaml # 默认参数值
├── templates/ # K8s 资源模板(Go Template 语法)
│ ├── deployment.yaml
│ ├── service.yaml
│ ├── ingress.yaml
│ ├── configmap.yaml
│ └── _helpers.tpl # 模板辅助函数
└── charts/ # 子 Chart(依赖)
1.4 常用命令
# 添加仓库
helm repo add bitnami https://charts.bitnami.com/bitnami
helm repo update
# 搜索 Chart
helm search repo mysql
helm search hub nginx # 搜索 ArtifactHub
# 安装(首次部署)
helm install my-mysql bitnami/mysql \
--namespace database \
--create-namespace \
--set auth.rootPassword=secret \
--set primary.persistence.size=20Gi
# 用自定义 values 文件安装
helm install my-app ./mychart -f values.prod.yaml
# 查看已安装的 Release
helm list -A # 所有 Namespace
# 升级(更新配置或版本)
helm upgrade my-mysql bitnami/mysql --set auth.rootPassword=newpass
# 查看升级历史
helm history my-mysql
# 回滚到上一版本
helm rollback my-mysql 1 # 1 = revision 编号
# 卸载
helm uninstall my-mysql -n database
# 渲染模板(不实际部署,调试用)
helm template my-app ./mychart -f values.yaml
1.5 编写自己的 Chart
# templates/deployment.yaml(Go Template 语法)
apiVersion: apps/v1
kind: Deployment
metadata:
name: {{ .Release.Name }}-web
labels:
app: {{ .Chart.Name }}
spec:
replicas: {{ .Values.replicaCount }}
template:
spec:
containers:
- name: web
image: "{{ .Values.image.repository }}:{{ .Values.image.tag }}"
resources:
{{- toYaml .Values.resources | nindent 12 }}
# values.yaml
replicaCount: 3
image:
repository: myapp
tag: "1.0.0"
resources:
limits:
cpu: 500m
memory: 512Mi
二、RBAC 权限控制
K8s 的权限体系:谁(Subject)能对什么资源(Resource)做什么操作(Verb):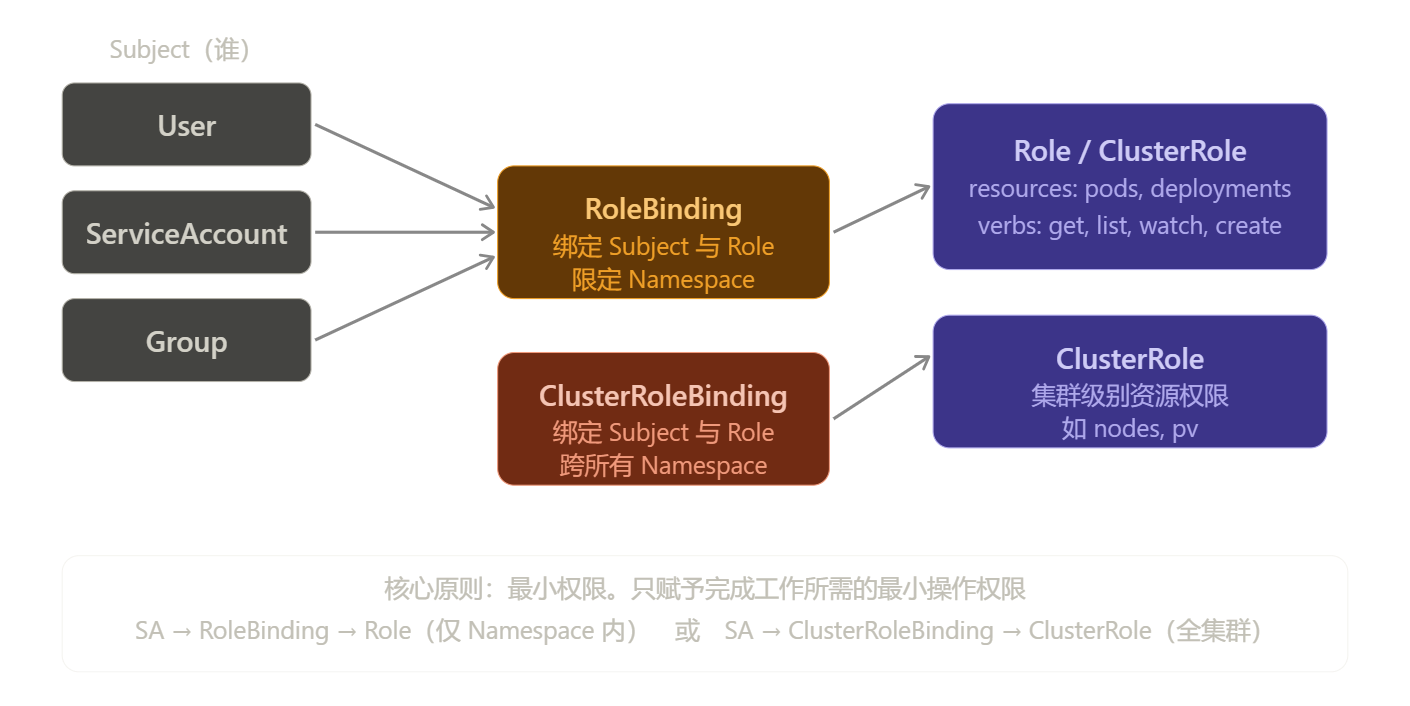
2.1 核心概念
RBAC(Role-Based Access Control)通过"谁能对什么资源做什么操作"来控制权限。
Subject(谁) 绑定关系 权限定义
────────────── ────────────────── ──────────────────────────
User ──→ RoleBinding ──→ Role(Namespace 级别)
ServiceAccount──→ ClusterRoleBinding ──→ ClusterRole(集群级别)
Group
四种资源:
| 资源 | 作用范围 | 说明 |
|---|---|---|
Role |
单个 Namespace | 定义该 Namespace 内的权限 |
ClusterRole |
全集群 | 定义集群级资源或跨 Namespace 权限 |
RoleBinding |
单个 Namespace | 将 Subject 绑定到 Role |
ClusterRoleBinding |
全集群 | 将 Subject 绑定到 ClusterRole |
2.2 YAML 示例
# 1. 创建 ServiceAccount
apiVersion: v1
kind: ServiceAccount
metadata:
name: deploy-bot
namespace: production
---
# 2. 定义 Role(只允许查看和更新 Deployment)
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: deployment-manager
namespace: production
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch", "update", "patch"]
- apiGroups: [""]
resources: ["pods"]
verbs: ["get", "list", "watch"]
---
# 3. 绑定 ServiceAccount 与 Role
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: deploy-bot-binding
namespace: production
subjects:
- kind: ServiceAccount
name: deploy-bot
namespace: production
roleRef:
kind: Role
name: deployment-manager
apiGroup: rbac.authorization.k8s.io
2.3 常用 verbs
get 查看单个资源
list 列出资源列表
watch 监听资源变化
create 创建资源
update 全量更新
patch 部分更新
delete 删除资源
exec 进入容器(pods/exec)
2.4 调试与排查
# 检查某个 ServiceAccount 是否有权限
kubectl auth can-i get pods \
--as=system:serviceaccount:production:deploy-bot \
-n production
# 查看某个用户的所有权限
kubectl auth can-i --list --as=jane -n production
# 查看 RoleBinding
kubectl get rolebindings -n production
kubectl describe rolebinding deploy-bot-binding -n production
最小权限原则: 生产环境中每个服务只授予其运行所需的最小权限,定期审计 ClusterRoleBinding。
三、GitOps / ArgoCD 持续交付
声明式 GitOps:Git 仓库是唯一事实来源,ArgoCD 自动同步集群状态: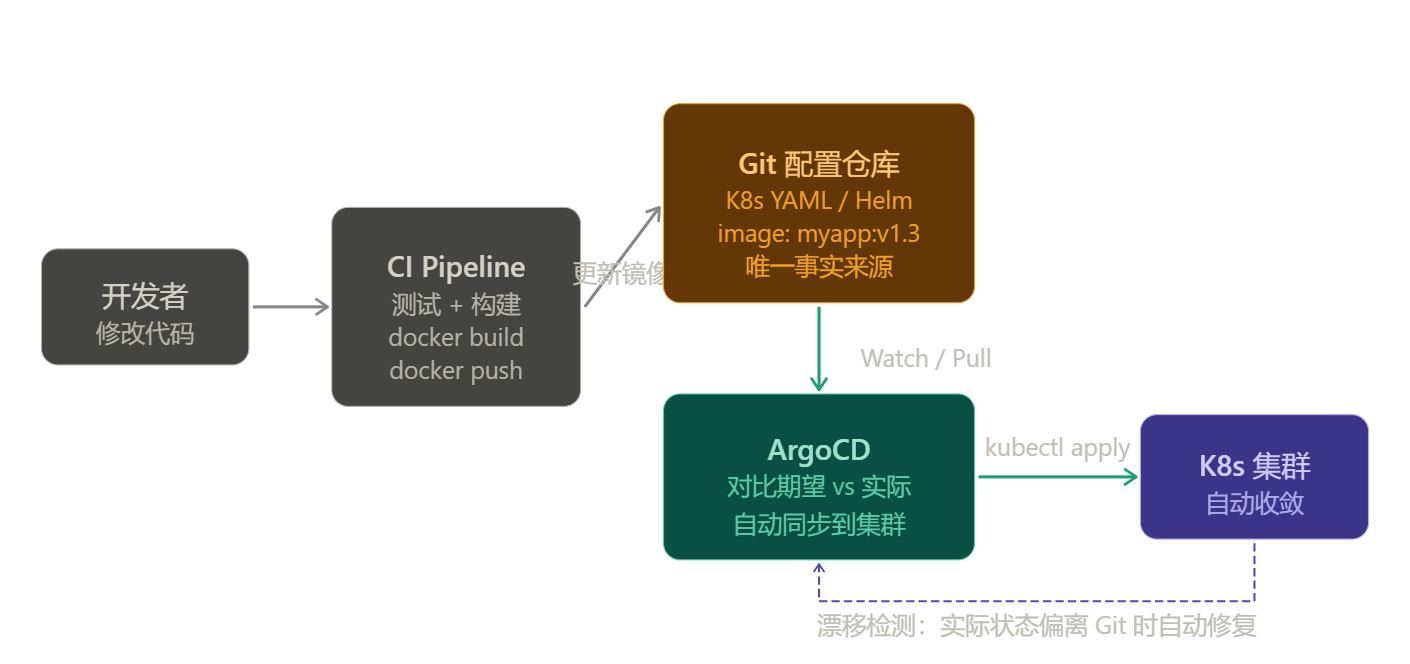
3.1 GitOps 核心理念
传统 CI/CD:
代码变更 → CI 构建 → 直接 kubectl apply 到集群
问题:谁在什么时候改了什么?集群状态无法追溯
GitOps:
代码变更 → CI 构建镜像 → 更新 Git 配置仓库 → ArgoCD 自动同步到集群
优势:Git 是唯一事实来源,所有变更可审计可回滚
完整流程:
开发者 push 代码
│
↓
CI Pipeline(GitHub Actions 等)
├── 运行测试
├── docker build + push(镜像 tag = git commit hash)
└── 更新 Git 配置仓库中的 image tag
│
↓
Git 配置仓库(存放 K8s YAML / Helm Chart)
│
↓ ArgoCD 每隔 3 分钟 Poll(或 Webhook 触发)
↓
ArgoCD 对比期望状态(Git)vs 实际状态(集群)
├── 一致 → 无操作(Synced)
└── 不一致 → 自动同步(kubectl apply)
│
↓
K8s 集群更新完成
3.2 ArgoCD 安装与配置
# 安装 ArgoCD
kubectl create namespace argocd
kubectl apply -n argocd \
-f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
# 获取初始密码
kubectl -n argocd get secret argocd-initial-admin-secret \
-o jsonpath="{.data.password}" | base64 -d
# 端口转发访问 UI
kubectl port-forward svc/argocd-server -n argocd 8080:443
3.3 Application 资源
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-app
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/myorg/k8s-config
targetRevision: main
path: apps/production # 配置文件所在目录
destination:
server: https://kubernetes.default.svc
namespace: production
syncPolicy:
automated:
prune: true # 自动删除 Git 中已移除的资源
selfHeal: true # 漂移时自动修复
syncOptions:
- CreateNamespace=true
3.4 多环境管理(Kustomize)
k8s-config/
├── base/ # 基础配置(所有环境共用)
│ ├── deployment.yaml
│ ├── service.yaml
│ └── kustomization.yaml
├── overlays/
│ ├── staging/ # 测试环境覆盖
│ │ ├── kustomization.yaml
│ │ └── patch-replicas.yaml
│ └── production/ # 生产环境覆盖
│ ├── kustomization.yaml
│ └── patch-resources.yaml
# overlays/production/kustomization.yaml
bases:
- ../../base
patches:
- patch-resources.yaml
images:
- name: myapp
newTag: "v1.3.0" # CI 自动更新此处
四、可观测性:监控 + 日志 + 链路追踪
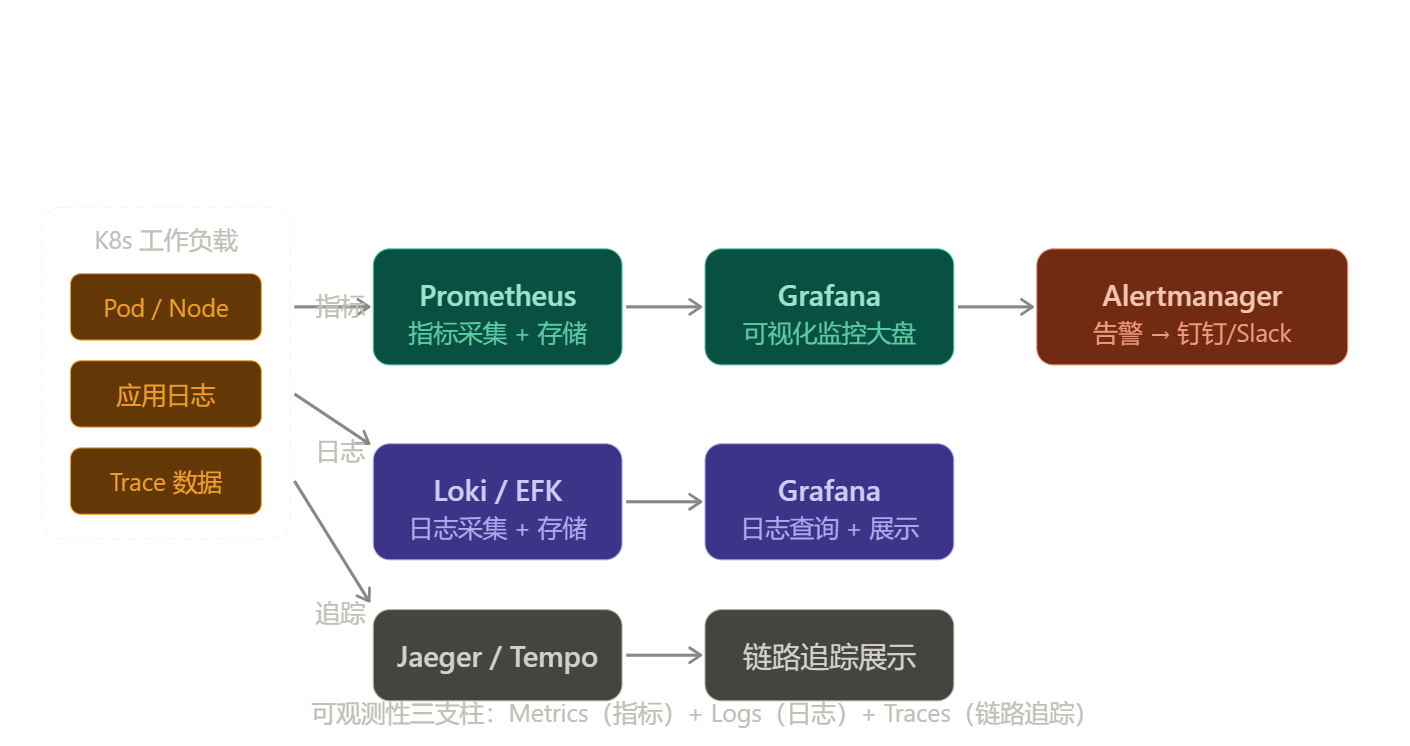
4.1 三大支柱
可观测性三支柱:
Metrics(指标) Logs(日志) Traces(链路追踪)
──────────────── ──────────── ──────────────────
数字化的时序数据 文本事件记录 请求跨服务的完整路径
"CPU 使用率 80%" "Error: DB timeout" "请求在哪个服务耗时最长"
Prometheus + Grafana Loki / EFK Jaeger / Tempo
适合告警和趋势分析 适合定位具体错误 适合微服务问题排查
4.2 Prometheus + Grafana 监控栈
kube-prometheus-stack 一键安装(推荐):
helm repo add prometheus-community \
https://prometheus-community.github.io/helm-charts
helm repo update
helm install kube-prom prometheus-community/kube-prometheus-stack \
--namespace monitoring \
--create-namespace \
--set grafana.adminPassword=admin123
安装后自动包含:Prometheus、Grafana、Alertmanager、Node Exporter、kube-state-metrics。
在应用中暴露自定义指标:
# 在 Pod 上加注解,告诉 Prometheus 来抓取
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "3000"
prometheus.io/path: "/metrics"
常用 PromQL 查询:
# 容器 CPU 使用率(%)
rate(container_cpu_usage_seconds_total[5m]) * 100
# 容器内存使用(MB)
container_memory_usage_bytes / 1024 / 1024
# Pod 重启次数
kube_pod_container_status_restarts_total
# HTTP 请求错误率
rate(http_requests_total{status=~"5.."}[5m])
/ rate(http_requests_total[5m])
4.3 日志方案:Loki + Promtail
# 安装 Loki Stack
helm repo add grafana https://grafana.github.io/helm-charts
helm install loki grafana/loki-stack \
--namespace monitoring \
--set grafana.enabled=false \ # 复用已有 Grafana
--set promtail.enabled=true # 自动采集所有 Pod 日志
应用日志最佳实践:
// 输出结构化 JSON 日志,便于 Loki 查询
{
"level": "error",
"timestamp": "2026-03-16T10:30:00Z",
"service": "payment-api",
"trace_id": "abc123",
"message": "payment failed",
"user_id": "u_456",
"error": "timeout after 5s"
}
4.4 告警规则示例
# PrometheusRule
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: app-alerts
spec:
groups:
- name: app
rules:
- alert: HighErrorRate
expr: |
rate(http_requests_total{status=~"5.."}[5m])
/ rate(http_requests_total[5m]) > 0.05
for: 2m
labels:
severity: critical
annotations:
summary: "错误率超过 5%,当前:{{ $value | humanizePercentage }}"
- alert: PodCrashLooping
expr: rate(kube_pod_container_status_restarts_total[15m]) > 0
for: 5m
labels:
severity: warning
annotations:
summary: "Pod {{ $labels.pod }} 频繁重启"
五、NetworkPolicy 网络隔离
5.1 为什么需要 NetworkPolicy?
默认情况下 K8s 集群内所有 Pod 可以互相访问,存在安全风险。NetworkPolicy 提供精细化的网络访问控制。
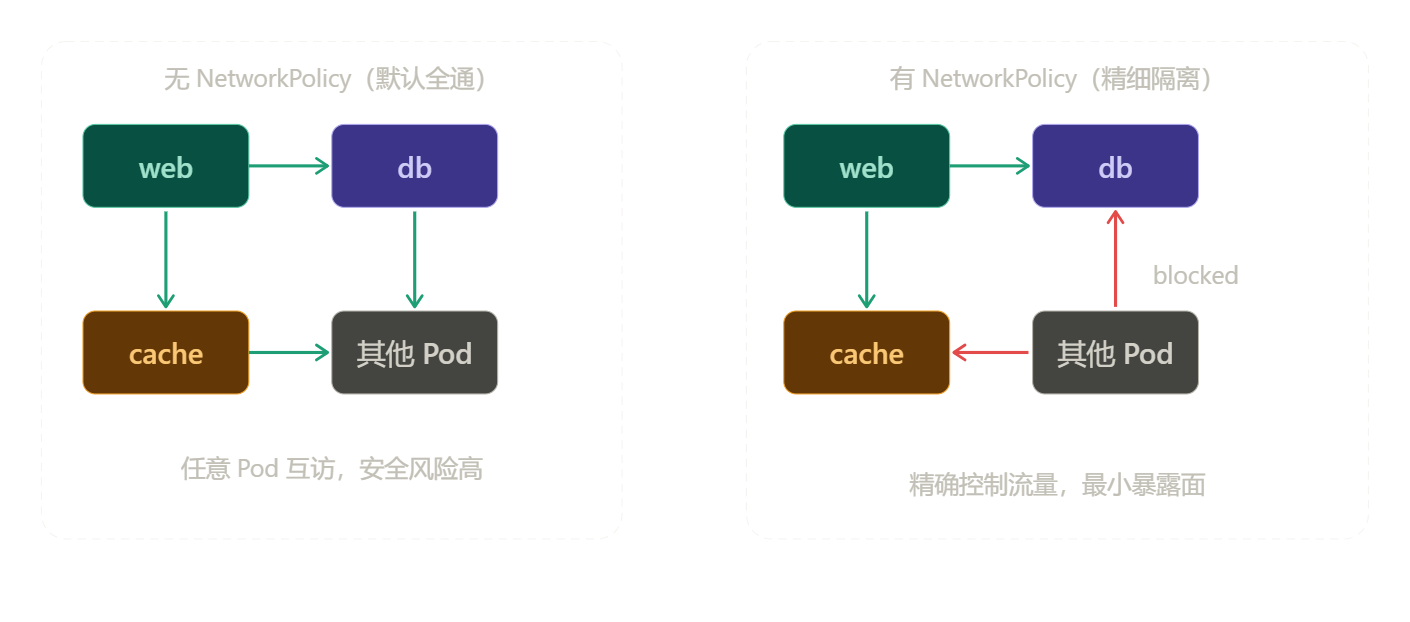
无 NetworkPolicy(默认): 有 NetworkPolicy(精细隔离):
web → db ✓ 允许 web → db ✓ 允许
web → cache ✓ 允许 web → cache ✓ 允许
其他Pod→db ✓ 允许 其他Pod→db ✗ 禁止
其他Pod→cache ✓ 允许 其他Pod→cache ✗ 禁止
5.2 常用策略示例
默认拒绝所有入流量(零信任基线):
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: default-deny-ingress
namespace: production
spec:
podSelector: {} # 匹配所有 Pod
policyTypes:
- Ingress # 拒绝所有入流量
只允许 web 访问 db:
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
name: allow-web-to-db
namespace: production
spec:
podSelector:
matchLabels:
app: db # 保护 db Pod
policyTypes:
- Ingress
ingress:
- from:
- podSelector:
matchLabels:
app: web # 只允许 web Pod 访问
ports:
- protocol: TCP
port: 3306
限制出流量(只允许访问特定外部地址):
spec:
podSelector:
matchLabels:
app: web
policyTypes:
- Egress
egress:
- to:
- podSelector:
matchLabels:
app: db
- ports: # 允许 DNS 解析
- port: 53
protocol: UDP
注意:NetworkPolicy 需要 CNI 插件支持,如 Calico、Cilium、Weave。Flannel 默认不支持。
六、Operator 模式
6.1 什么是 Operator?
Operator = CRD(自定义资源)+ Controller(控制器),用于自动化有状态应用的运维逻辑。
K8s 内置资源: Operator 扩展资源:
Deployment MySQLCluster(自定义)
Service →→→ RedisCluster(自定义)
ConfigMap KafkaTopic(自定义)
……
内置控制器管理内置资源 自定义控制器管理自定义资源
知道如何备份、扩容、故障恢复
Operator 能做什么:
人工运维 MySQL: MySQL Operator:
① 安装 MySQL ① 声明 MySQLCluster CR
② 配置主从复制 ② Operator 自动完成所有步骤
③ 设置备份策略 └── 安装、配置复制、备份
④ 监控并处理故障 ③ 主节点故障 → 自动故障转移
⑤ 版本升级 ④ 声明升级版本 → 自动滚动升级
……需要专业 DBA…… ……Operator 封装了 DBA 的知识……
6.2 常用 Operator
| Operator | 用途 |
|---|---|
postgres-operator(Zalando) |
PostgreSQL 高可用集群 |
mysql-operator(Oracle) |
MySQL InnoDB 集群 |
strimzi-kafka-operator |
Kafka 集群管理 |
elasticsearch-operator(ECK) |
Elasticsearch 集群 |
cert-manager |
TLS 证书自动申请与续签 |
prometheus-operator |
Prometheus 实例管理 |
6.3 自定义 CRD 示例
# 定义自定义资源类型
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: mysqlclusters.db.example.com
spec:
group: db.example.com
names:
kind: MySQLCluster
plural: mysqlclusters
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
replicas:
type: integer
version:
type: string
---
# 使用自定义资源
apiVersion: db.example.com/v1
kind: MySQLCluster
metadata:
name: prod-mysql
spec:
replicas: 3
version: "8.0.32"
backup:
schedule: "0 2 * * *"
storage: s3://my-bucket/mysql-backup
七、多集群与多租户
7.1 Namespace 隔离(软隔离)
Namespace 提供资源逻辑隔离,配合 RBAC + NetworkPolicy + ResourceQuota 实现多租户:
# 为每个团队创建独立 Namespace
kubectl create namespace team-a
kubectl create namespace team-b
# 资源配额(限制每个 Namespace 的资源用量)
kubectl apply -f - <<EOF
apiVersion: v1
kind: ResourceQuota
metadata:
name: team-a-quota
namespace: team-a
spec:
hard:
requests.cpu: "10"
requests.memory: 20Gi
limits.cpu: "20"
limits.memory: 40Gi
pods: "50"
persistentvolumeclaims: "10"
EOF
7.2 LimitRange(Pod 默认资源限制)
# 为 Namespace 内未设置资源限制的 Pod 自动注入默认值
apiVersion: v1
kind: LimitRange
metadata:
name: default-limits
namespace: team-a
spec:
limits:
- type: Container
default:
cpu: 500m
memory: 256Mi
defaultRequest:
cpu: 100m
memory: 128Mi
max:
cpu: "2"
memory: 2Gi
7.3 多集群管理
单集群(适合中小规模): 多集群(适合大规模/多地域):
一个 K8s 集群管理所有应用 每个环境/地域独立集群
工具选型:
Cluster API → 集群生命周期管理(创建/升级/删除集群)
Karmada → 跨集群应用分发和调度
ArgoCD → 多集群 GitOps 部署(一个 ArgoCD 管理多个集群)
Istio → 跨集群服务网格
八、性能调优与资源管理
8.1 资源 requests / limits 最佳实践
resources:
requests: # 调度依据,Scheduler 按此分配节点
cpu: "100m" # 100 毫核 = 0.1 个 CPU
memory: "128Mi"
limits: # 上限,超出 CPU 被限速,超出内存被 OOM Kill
cpu: "500m"
memory: "512Mi"
常见误区:
❌ requests = limits(会导致节点资源浪费,无法超售)
❌ 不设 limits(一个 Pod 可能吃掉全部资源)
❌ limits.cpu 设置过低(导致应用被 throttle,响应变慢)
✅ requests 设为 P50 用量,limits 设为 P99 用量
✅ 用 VPA(垂直 Pod 自动扩缩容)分析历史用量后再设置
8.2 VPA(垂直 Pod 自动扩缩容)
# VPA 自动推荐和调整资源配置
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: web-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web
updatePolicy:
updateMode: "Auto" # Off=只推荐,Initial=只在新建时设置,Auto=自动调整
8.3 节点亲和性与反亲和性
spec:
affinity:
# Pod 反亲和:同一应用的 Pod 分散到不同节点(高可用)
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app: web
topologyKey: kubernetes.io/hostname
# 节点亲和:调度到 SSD 节点
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: disk-type
operator: In
values: ["ssd"]
8.4 PodDisruptionBudget(中断预算)
# 保证滚动更新或节点维护时最少有 2 个 Pod 在运行
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-pdb
spec:
minAvailable: 2 # 或用 maxUnavailable: 1
selector:
matchLabels:
app: web
九、生产安全加固
9.1 Pod Security Standards
# 在 Namespace 上强制执行安全标准
apiVersion: v1
kind: Namespace
metadata:
name: production
labels:
pod-security.kubernetes.io/enforce: restricted # 强制执行
pod-security.kubernetes.io/warn: restricted # 仅警告
三个安全级别:
| 级别 | 说明 |
|---|---|
privileged |
无限制(仅系统组件使用) |
baseline |
防止常见特权提升,适合通用工作负载 |
restricted |
最严格,要求非 root、只读文件系统等 |
9.2 容器安全上下文
spec:
securityContext:
runAsNonRoot: true # 禁止以 root 运行
runAsUser: 1000
fsGroup: 2000
seccompProfile:
type: RuntimeDefault # 启用 seccomp 过滤系统调用
containers:
- name: web
securityContext:
allowPrivilegeEscalation: false # 禁止提权
readOnlyRootFilesystem: true # 只读文件系统
capabilities:
drop: ["ALL"] # 删除所有 Linux capabilities
add: ["NET_BIND_SERVICE"] # 只添加必要的
9.3 镜像安全
# 1. 使用 Trivy 扫描镜像漏洞
trivy image --severity HIGH,CRITICAL myapp:v1.0
# 2. 配置 ImagePolicyWebhook,禁止未经扫描的镜像部署
# 3. 只允许从私有仓库拉取镜像(配置 imagePullPolicy + imagePullSecrets)
# 4. 使用镜像摘要而非 tag(tag 可以被覆盖,digest 不可变)
image: myapp@sha256:abc123def456...
9.4 Secrets 加密
# K8s Secret 默认只做 base64 编码,不加密
# 开启静态加密(At-rest encryption)
# /etc/kubernetes/encryption-config.yaml
# 推荐使用外部密钥管理系统
# Sealed Secrets(Bitnami):加密后可以提交到 Git
kubeseal --format yaml < secret.yaml > sealed-secret.yaml
# External Secrets Operator:从 AWS/GCP/Vault 自动同步密钥
十、学习资源与路线图
10.1 进阶学习路线
| 阶段 | 目标 | 关键工具 |
|---|---|---|
| 进阶 1 | 包管理与多环境 | Helm、Kustomize |
| 进阶 2 | 权限与安全 | RBAC、NetworkPolicy、Pod Security |
| 进阶 3 | 持续交付 | ArgoCD、GitOps、Kustomize |
| 进阶 4 | 可观测性 | Prometheus、Grafana、Loki、Jaeger |
| 进阶 5 | 有状态应用 | Operator、StatefulSet 深入 |
| 进阶 6 | 性能与大规模 | VPA、Cluster Autoscaler、多集群 |
10.2 推荐资源
官方文档:
- K8s 官方:kubernetes.io/docs
- Helm 官方:helm.sh/docs
- ArgoCD 官方:argo-cd.readthedocs.io
实战练习:
- killercoda.com — 免费在线 K8s 环境,大量实验场景
- killer.sh — CKA/CKAD 模拟考试环境
工具推荐:
k9s # 终端 UI,极大提升日常操作效率
kubectx # 快速切换集群上下文
kubens # 快速切换 Namespace
stern # 多 Pod 日志聚合查看
kubectl-neat # 清理 kubectl get -o yaml 的噪音字段
kube-score # YAML 最佳实践检查
popeye # 集群健康检查

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)