医学图像分割还卷不动?试试把Stable Diffusion搬进来,CVPR 2026已收!
在医学图像分割领域,数据稀缺、标注成本高昂以及严重的领域偏移是制约模型临床部署的核心挑战。同时,现有基础模型在面对复杂解剖结构时,往往高度依赖人工空间提示,泛化能力受限。本文解析的两篇前沿论文均以通用基础模型为切入点:第一篇提出SD-FSMIS,通过巧妙适配)模型,利用其丰富的视觉先验攻克小样本分割与跨域难题;第二篇Medical SAM3则对最新大模型进行全面微调,打造出首个纯文本驱动的通用医学
在医学图像分割领域,数据稀缺、标注成本高昂以及严重的领域偏移是制约模型临床部署的核心挑战。同时,现有基础模型在面对复杂解剖结构时,往往高度依赖人工空间提示,泛化能力受限。
本文解析的两篇前沿论文均以通用基础模型为切入点:第一篇提出SD-FSMIS,通过巧妙适配稳定扩散(Stable Diffusion, SD)模型,利用其丰富的视觉先验攻克小样本分割与跨域难题;第二篇Medical SAM3则对最新大模型进行全面微调,打造出首个纯文本驱动的通用医学分割模型,彻底摆脱了对边界框等空间指令的依赖。这两项工作为构建数据高效且高鲁棒性的医学人工智能提供了崭新范式。
我整理了医学图像分割+基础模型相关论文合集,希望能帮到你!
一、论文1:[CVPR 2026] SD-FSMIS: Adapting Stable Diffusion for Few-Shot Medical Image Segmentation
推荐理由:
本文针对小样本和跨域医学图像分割的痛点,首次验证了可以直接利用大型扩散模型中广泛的视觉先验知识来代替从头设计复杂网络。这为应对医疗数据极度匮乏和异构性挑战提供了一条极具潜力且高效的新路径。
方法:
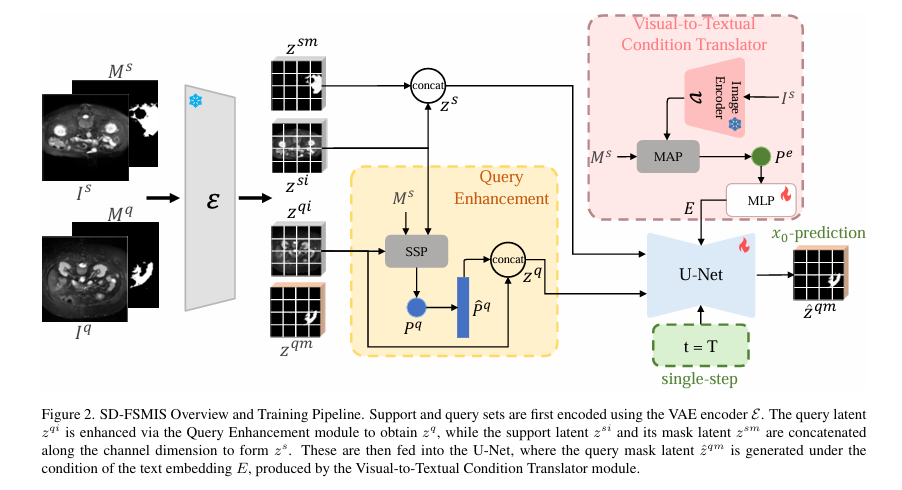
本研究基于冻结的SD模型,设计了两个极简适配模块:
-
支持-查询交互(Support-Query Interaction, SQI):通过修改自注意力层,在潜在空间融合支持集特征与查询集图像。查询特征更新机制的核心公式如下:
-
视觉到文本条件转换器(Visual-to-Textual Condition Translator, VTCT):将支持集的视觉线索转化为扩散模型可理解的隐式文本词嵌入进行精确引导。分割损失不仅对比预测掩码与真实掩码的潜在表示:
创新点:
-
范式创新:打破了构建特定任务匹配网络的传统框架,通过复用大规模文本到图像生成模型的普遍视觉先验来解决医学分割瓶颈。
-
卓越的泛化能力:借助创新的隐式特征与文本协同引导机制,在严苛的零样本跨域(如CT到MRI)测试中,大幅刷新了现有方法的准确率。
-
论文链接:https://arxiv.org/pdf/2604.03134
二、论文2:[中佛罗里达大学] Medical SAM3: A Foundation Model for Universal Prompt-Driven Medical Image Segmentation
推荐理由:
现有的SAM类模型在医学领域大多依赖人工提供的极强几何先验(如边界框),一旦缺失便会产生崩溃。本文直击这一痛点,通过全参数微调和纯语句引导,打造出了真正符合“医生语义思考逻辑”的基石模型,极具真实临床应用价值。
方法:
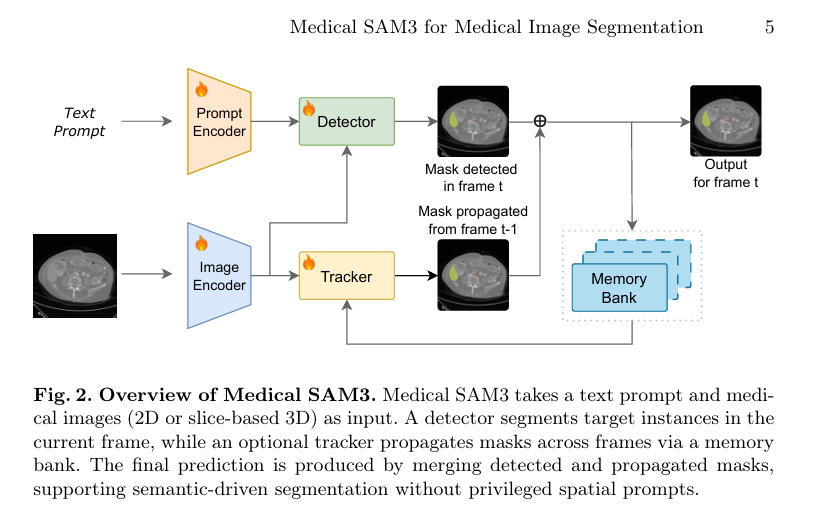
文章摒弃了特定模块微调,对SAM3进行全面的端到端微调,涵盖10种模态的33个医学数据集。摒弃了空间提示,仅利用文本-图像-掩码三元组进行训练。为防止遗忘通用特征,引入了层级学习率衰减(Layer-wise Learning Rate Decay, LLRD):
并采用结合一对一与一对多检测器(One-to-Many, O2M)的多任务集合预测函数进行优化:
创新点:
-
纯文本驱动定位:首次在医学域实现了不依赖特权空间提示(Privileged Spatial Prompts)的通用基础分割模型,直接完成从专业医学术语到像素掩码的语义对齐。
-
跨维度与多模态统一:将来自包含病理与放射等多尺度的2D和3D切片图像统一映射到高分辨率的通用2D特征空间,在严重域迁移下实现同类最优表现。
-
代码链接:https://github.com/AIM-Research-Lab/Medical-SAM3
-
论文链接:https://arxiv.org/pdf/2601.10880

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)