项目一:大数据分布式集群
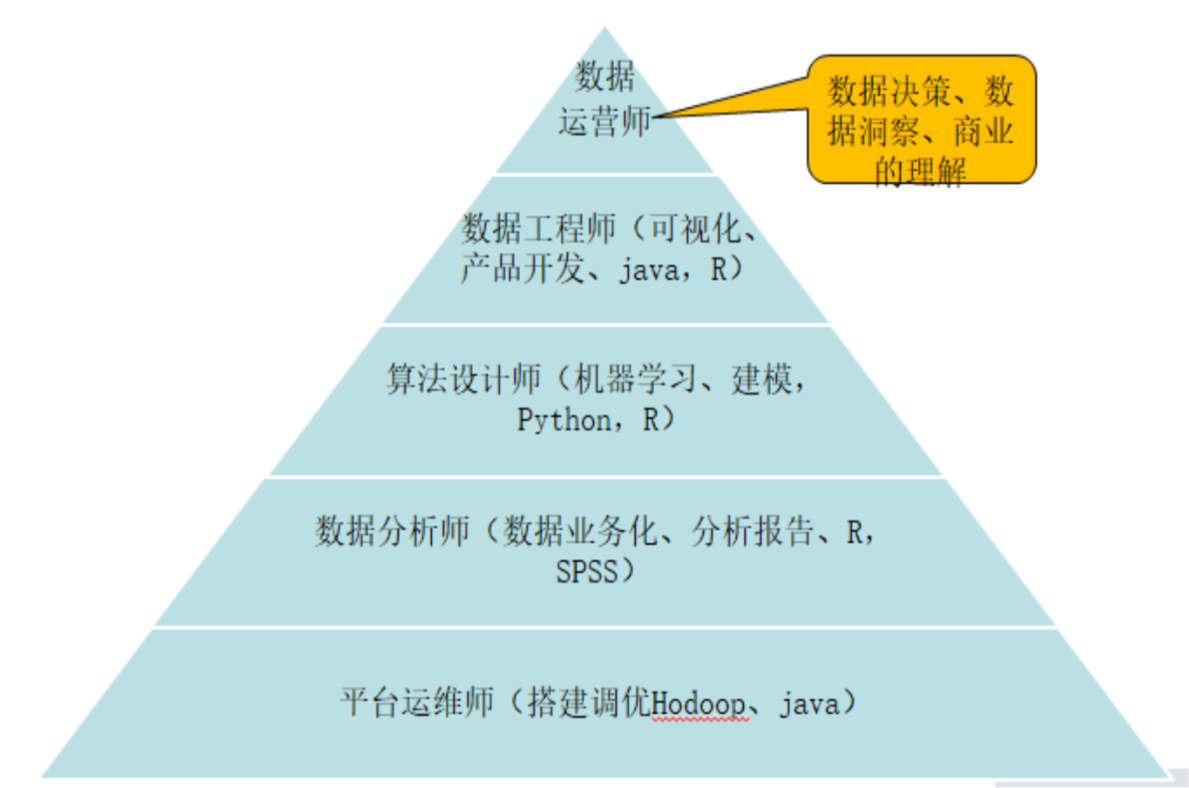
大数据运维的核心目标
大数据运维的核心在于保障数据平台的稳定性、高效性和安全性,需处理海量数据存储、实时计算、资源调度等问题,同时应对高并发和故障恢复。
关键技术领域
分布式系统管理
Hadoop、Spark、Flink等框架的集群部署与监控是关键,需关注节点健康状态、资源利用率(CPU/内存/磁盘)及任务调度优化。
数据存储与处理
HDFS、Kafka、HBase等组件的性能调优,包括数据分片策略、副本机制和压缩算法选择,以平衡吞吐量与延迟。
实时监控与告警
Prometheus、Grafana、Zabbix等工具用于实时采集指标(如延迟、错误率),结合阈值告警和日志分析(ELK Stack)快速定位问题。
常见挑战与解决方案
资源争用
通过YARN或Kubernetes动态分配资源,设置优先级队列避免任务阻塞,定期清理冗余数据释放存储空间。
故障恢复
设计高可用架构(如HDFS NameNode HA),定期备份元数据,自动化故障转移(如ZooKeeper选主机制)。
安全合规
启用Kerberos认证、RBAC权限控制,审计日志记录敏感操作,加密传输(TLS)和静态数据(AES)。
优化实践案例
某电商平台通过调整Spark内存参数和并行度,将ETL作业耗时降低40%;另一案例中,Kafka分区再平衡策略减少了30%的消息堆积。
未来趋势
Serverless架构(如AWS Lambda)和AIOps(异常检测自动化)将逐渐融入大数据运维,减少人工干预成本。
注:具体实施需结合业务场景,建议定期复盘性能指标并迭代运维策略。
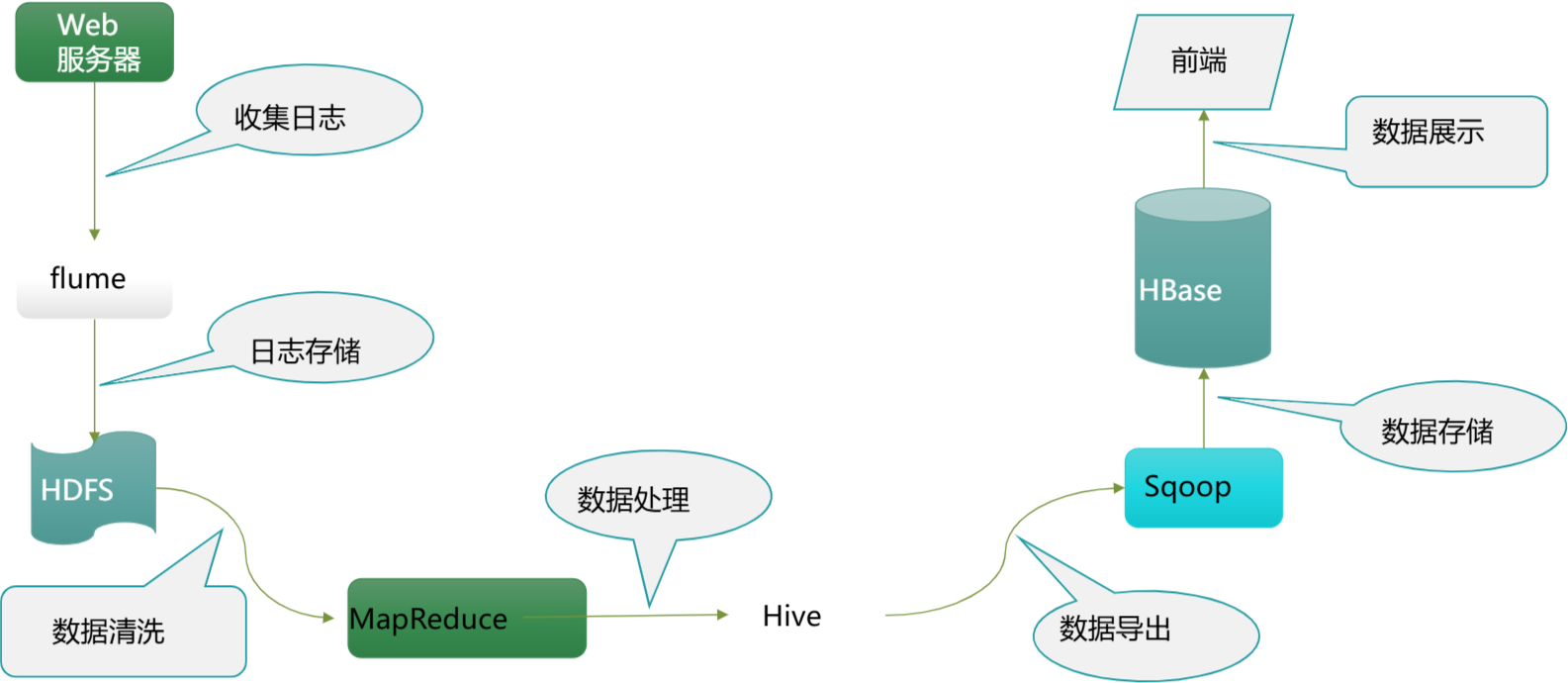
Hadoop的应用场景
Hadoop是一个分布式计算框架,主要用于处理大规模数据集。其核心组件包括HDFS(分布式文件系统)和MapReduce(计算模型),适用于需要高吞吐量、高容错性和横向扩展的场景。
大数据存储与处理
Hadoop的HDFS设计用于存储海量数据,适合需要长期保存且频繁访问的数据。企业可以将日志、交易记录、传感器数据等非结构化或半结构化数据存储在HDFS上,通过MapReduce或Spark进行批量处理。
日志分析与聚合
互联网公司常用Hadoop分析服务器日志,提取用户行为、系统性能等指标。例如,电商平台通过分析点击流日志优化推荐算法,广告平台通过聚合日志计算广告曝光和点击率。
数据导出方法
数据导出通常涉及从数据库、应用程序或文件中提取数据,并将其转换为可共享或存储的格式。以下是几种常见的数据导出方法:
使用数据库管理工具导出数据
大多数数据库管理系统(如MySQL、PostgreSQL、MongoDB)提供导出功能,允许将数据保存为CSV、JSON或SQL格式。例如,在MySQL中可以使用mysqldump命令行工具或通过phpMyAdmin界面导出数据。
通过编程语言实现数据导出
Python、Java等编程语言提供库支持数据导出。例如,Python的pandas库可以轻松将DataFrame导出为CSV、Excel或JSON文件:
import pandas as pd
df = pd.DataFrame({'A': [1, 2], 'B': ['x', 'y']})
df.to_csv('output.csv', index=False)
应用程序内置导出功能
许多软件(如Excel、Tableau)支持直接导出数据。在Excel中,可通过“文件”>“另存为”选择格式(如CSV、XLSX)。Tableau允许将可视化数据导出为图像或底层数据表。
API或ETL工具导出
企业级数据导出可通过ETL工具(如Talend、Informatica)或调用API实现。例如,REST API通常返回JSON数据,可通过代码解析并保存为所需格式。
命令行工具批量导出
Linux环境下,awk、sed等工具可处理文本数据导出。例如,提取日志文件中的特定字段并保存为CSV:
awk '{print $1 "," $2}' access.log > output.csv
大数据分布式集群的核心优势
分布式集群通过多节点并行处理实现高性能计算与存储,具备横向扩展能力,可动态增加节点以应对数据增长。容错机制(如HDFS副本机制)确保单点故障不影响整体服务,资源调度框架(如YARN)优化计算资源分配。
关键技术组件与架构
存储层:HDFS、S3等分布式文件系统支持海量数据存储,采用分块(Block)与副本策略保障数据可靠性。
计算层:MapReduce、Spark等框架实现分布式计算,Spark内存计算显著提升迭代算法效率。
资源管理:YARN或Kubernetes协调CPU、内存资源,支持多任务并发执行。
数据库与工具:HBase、Hive、Flink等组件分别处理实时查询、数据仓库和流式计算需求。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)