用四种注意力机制改进YOLOv8实现超99%精度的PCB缺陷检测
四种注意力改进yolov8PCB 缺陷检测 ◆ 一万多张 PCB缺陷数据集 ◆四种注意力机制改进yolov8 ◆训练步骤 缺陷检测精度 99% 以上

在电子制造领域,PCB(Printed Circuit Board)缺陷检测至关重要。今天就来分享一下我如何通过四种注意力机制改进YOLOv8,在一万多张PCB缺陷数据集上实现超99%精度的缺陷检测。
一、一万多张PCB缺陷数据集
数据是模型训练的基石。我收集整理的这一万多张PCB缺陷数据集,涵盖了诸如短路、断路、元件缺失等多种常见缺陷类型。这些图像都经过仔细标注,标注信息精确到每个缺陷的位置与类别,为后续模型的准确训练奠定基础。
二、四种注意力机制改进YOLOv8
1. SENet注意力机制
SENet(Squeeze-and-Excitation Network)通过挤压和激励操作,自适应地调整通道间的特征响应。在YOLOv8代码中添加SENet模块大概是这样:
class SEBlock(nn.Module):
def __init__(self, in_channels, reduction=16):
super(SEBlock, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction, in_channels, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)这里,avg_pool先对输入特征图进行全局平均池化,将空间维度压缩为1,之后通过全连接层和激活函数来计算通道间的注意力权重,最后再将权重乘回原特征图,增强重要通道特征。
2. CBAM注意力机制
CBAM(Convolutional Block Attention Module)同时在通道和空间维度上施加注意力。
class ChannelAttention(nn.Module):
def __init__(self, in_planes, ratio=16):
super(ChannelAttention, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.fc1 = nn.Conv2d(in_planes, in_planes // ratio, 1, bias=False)
self.relu1 = nn.ReLU()
self.fc2 = nn.Conv2d(in_planes // ratio, in_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = self.fc2(self.relu1(self.fc1(self.avg_pool(x))))
max_out = self.fc2(self.relu1(self.fc1(self.max_pool(x))))
out = avg_out + max_out
return self.sigmoid(out)
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.conv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv1(x)
return self.sigmoid(x)
class CBAMBlock(nn.Module):
def __init__(self, in_planes, ratio=16, kernel_size=7):
super(CBAMBlock, self).__init__()
self.ca = ChannelAttention(in_planes, ratio)
self.sa = SpatialAttention(kernel_size)
def forward(self, x):
x = x * self.ca(x)
x = x * self.sa(x)
return x通道注意力模块ChannelAttention通过平均池化和最大池化获取不同的全局特征,经全连接层得到通道注意力权重。空间注意力模块SpatialAttention则是对通道维度进行处理,将平均池化和最大池化后的结果拼接,经卷积得到空间注意力权重。
3. ECA注意力机制
ECA(Efficient Channel Attention)是一种轻量级的通道注意力机制,它通过局部跨通道交互来捕捉通道间的依赖关系。
class ECABlock(nn.Module):
def __init__(self, kernel_size=3):
super(ECABlock, self).__init__()
assert kernel_size % 2 == 1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
y = self.avg_pool(x)
y = self.conv(y.squeeze(-1).transpose(-1, -2)).transpose(-1, -2).unsqueeze(-1)
y = self.sigmoid(y)
return x * y.expand_as(x)这里利用1D卷积在通道维度上进行局部交互,相比于SENet,ECA计算量更小,更高效。
4. SK注意力机制
SK(Selective Kernel)注意力机制让模型能够自适应地选择不同感受野的卷积核。
class SKConv(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, M=2, r=16, L=32):
super(SKConv, self).__init__()
d = max(int(in_channels // r), L)
self.M = M
self.out_channels = out_channels
self.convs = nn.ModuleList()
for i in range(M):
self.convs.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3 + i * 2, stride, 1 + i, groups=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
))
self.global_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(out_channels, d, bias=False),
nn.ReLU(inplace=True),
nn.Linear(d, out_channels * M, bias=False),
nn.Sigmoid()
)
def forward(self, x):
batch_size = x.size(0)
feats = [conv(x) for conv in self.convs]
U = sum(feats)
S = self.global_pool(U).view(batch_size, -1)
a = self.fc(S).view(batch_size, self.M, self.out_channels)
a = torch.split(a, 1, dim=1)
a = list(map(lambda x: x.squeeze(1), a))
V = list(map(lambda x, y: x * y, feats, a))
V = sum(V)
return V它通过多个不同卷积核的分支,再根据注意力权重融合分支结果,让模型能更好地适应不同尺度的目标。
三、训练步骤
- 数据预处理:将收集的PCB图像统一调整大小,并进行归一化处理,以符合YOLOv8输入要求。
- 模型构建:在YOLOv8的基础网络结构中,依据上述代码,合理嵌入四种注意力机制模块。
- 设置训练参数:选择合适的优化器(如Adam),设置学习率、批量大小等参数。
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
batch_size = 16- 开始训练:在训练过程中,模型不断学习PCB图像中的特征,调整自身权重。
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(dataloader):
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()每轮训练后,计算模型在验证集上的精度,观察模型是否过拟合或欠拟合,适时调整参数。
四种注意力改进yolov8PCB 缺陷检测 ◆ 一万多张 PCB缺陷数据集 ◆四种注意力机制改进yolov8 ◆训练步骤 缺陷检测精度 99% 以上
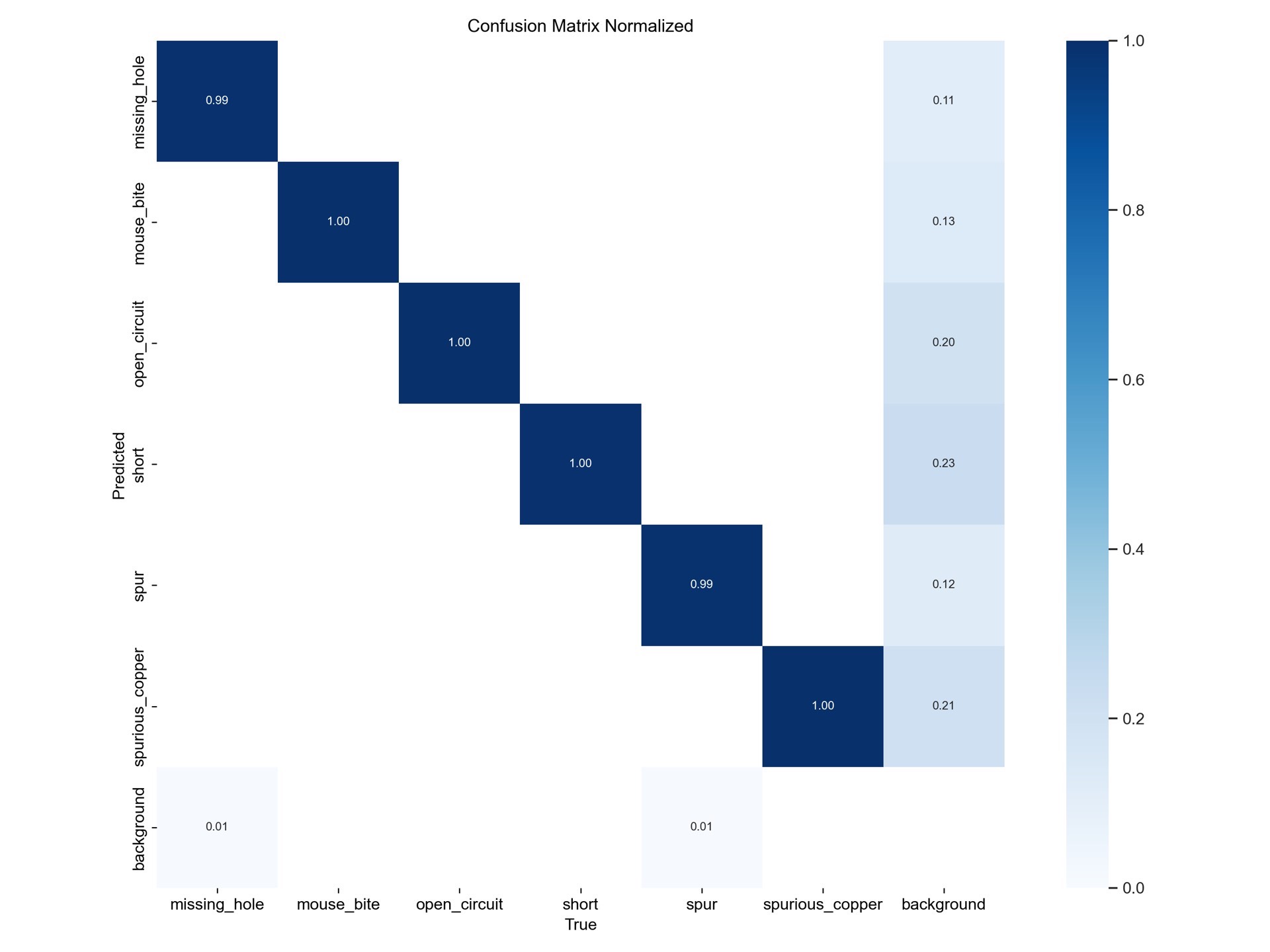
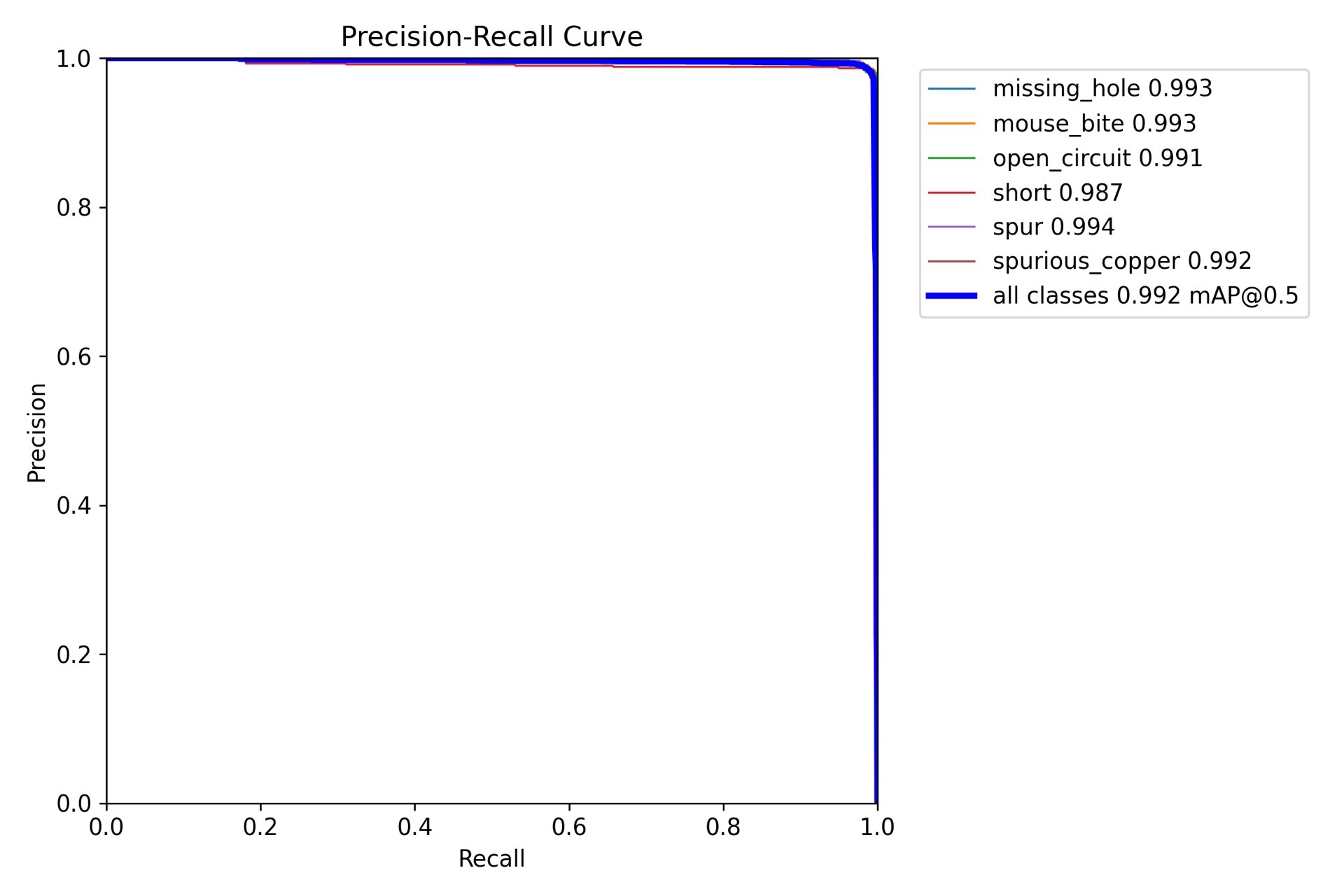
通过上述步骤,最终模型在PCB缺陷检测任务上达到了99%以上的精度,有效地识别出各种PCB缺陷,为实际生产中的质量控制提供了可靠的技术支持。希望我的经验分享能给大家在相关领域的研究和实践带来一些启发。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)